



1 å¢Ņ}Ą─╠ß│÷
ČÓŲĘĘNąĪ┼·┴┐╔·«aęįŲõ╚ßąįĖ▀Īó▀mæ¬ąįÅŖĄ─╠ž³c│╔×ķ«öŪ░ųŲįņŲ¾śIĄ─ę╗ĘNųžę¬╔·«a─Ż╩ĮĪŻį┌▀@ĘN╔·«a─Ż╩ĮŽ┬Ż¼┴Ń▓┐╝■ĮĶė├▌^ČÓŻ¼╣ż│╠ūāĖ³ŽÓī”ŅlĘ▒Ż╗═¼śėę╗ĮM┴Ń╝■┐╔─▄ę“×ķčb┼õĄž³cĪóą═╠¢╗“┐═æ¶Ą╚Ą─▓╗═¼Č°│╔×ķ▓╗═¼▓┐╝■╗“«aŲĘŻ╗Č°═¼Ģrę╗ĘN▓┐╝■ļm╚╗į┌ā╚┤µųąų╗─▄ėąę╗ĘN╬’┴ŽŪÕå╬(Bill of MaterialŻ¼BOM)čb┼õĮYśŗŻ¼Ą½Ųõ┤µā”─Żą═ģs┐╔─▄┤µį┌ČÓéĆ▓╗═¼░µ▒Š╗“ėąą¦Ų┌Ż¼Č°Ūęį┌«aŲĘ╔·├³ų▄Ų┌Ą─▓╗═¼ļAČ╬ėųĢ■ę“▓┐ķT┬Ü─▄Ą─▓╗═¼Č°┤µį┌įOėŗBOMęĢłDĪó╣ż╦ćBOMęĢłD║═ųŲįņBOMęĢłDĄ╚▓╗═¼ęĢłDĪŻę“┤╦Ż¼īŹļH╔ŽBOMĄ─┤µā”─Żą═▓╗═¼ė┌ā╚┤µųąśõą╬ĮYśŗĄ─BoMī”Ž¾Ż¼╦³╩Ūę╗ĘNĪ░łDą╬ĮYśŗĪ▒ĪŻČ°é„ĮyĄ─BOM─Żą═ę╗░Ńīó┴Ń▓┐╝■ą┼Žó┼cčb┼õĮYśŗą┼Žó±Ņ║Žį┌ę╗Ų▀Mąą┤µā”Ż¼ī¦ų┬═©ė├╝■Ż»ĮĶė├╝■Ą╚öĄō■Ą─╚▀ėÓČ╚▌^Ė▀Ż¼Ūę¤oĘ©ņ`╗Ņ▒Ē▀_BOMĄ─łDą╬ĮYśŗŻ¼Ė³ļyęįų¦│ųBOMČÓęĢłD▐DōQ╝░╣ż│╠ūāĖ³Ą─ūįäėīŹ¼FĪŻ╬─½I▓╔ė├╝ē┬ōŠÄ┤aĄ─öĄō■śŗįņĘĮĘ©Ż¼╠ßĖ▀┴╦BOMöĄō■Ą─ł╠ąąą¦┬╩Ż¼Ą½╩Ūį┌┴Ń▓┐╝■ĮĶė├ĻPŽĄĄ─▒Ē▀_╔Ž▓╗ē“ņ`╗ŅŻ¼öĄō■┤µā”╚▀ėÓČ╚▀^Ė▀Ż╗╬─½I┐╝æ]ĄĮŲĮ║ŌBOMöĄō■┤µā”║═śŗĮ©Ą─ą¦┬╩Ż¼╗∙ė┌░ļĮYśŗ╗»öĄō■─Żą═śŗĮ©┐╔ųžė├śŗ╝■ÄņüĒ▀Mąąčb┼õĮYśŗĄ─Ų┤čbŻ¼Ą½╩Ūįō─Żą═╚į╩Ūīó▓┐╝■┼cĮYśŗ±Ņ║Žį┌ę╗ŲŻ¼▓╗▀mė┌▒Ē▀_▓┐╝■┼cĮYśŗĄ─ČÓī”ČÓĻPŽĄĪŻ
╬─½Iīó┴Ń▓┐╝■Ą─čb┼õĻPŽĄČ©┴x×ķ╚²į¬ĮMSR=

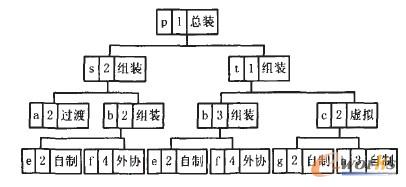
łD1ę╗éĆśõą╬«aŲĘBOMīŹ└²
2 ųŲįņ╬’┴ŽŪÕå╬čb┼õĮYśŗĄ─Č©┴x
«aŲĘĄ─ųŲįņBOMą┼Žóų„ę¬ėąā╔ŅÉŻ║ó┘ų╗┼c┴Ń▓┐╝■(╬’┴Ž)ūį╔ĒŽÓĻPĄ─ī┘ąįą┼ŽóŻ¼ę╗░Ńė╔├¹ĘQĪóŠÄ╠¢Īó░µ▒ŠĪóŅ~Č©╣żĢrĄ╚ūųČ╬ĮM│╔Ż¼╩Ūę╗éĆ║åå╬Ą─ę╗ŠSöĄō■▒ĒŻ╗ó┌▒Ē▀_┴Ń▓┐╝■ų«ķgčb┼õĻPŽĄĄ─ą┼ŽóŻ¼╝┤čb┼õĮYśŗĪŻčb┼õĮYśŗę╗░Ń├Ķ╩÷×ķ┴Ń▓┐╝■ų«ķgĄ─ĖĖūėĻPŽĄ║═čb┼õöĄ┴┐Ą─╝»║ŽĪŻį┌īŹļH╣ż│╠æ¬ė├ųąŻ¼BOMĄ─čb┼õĮYśŗį┌┤µā”╔Žę╗░Ń╩Ūę╗ĘNłDą╬öĄō■ĮYśŗĪŻ
▒Š╬─ųąĪ░ĖĖ╝■Ī▒╩ŪųĖė╔ŲõĪ░ūė╝■Ī▒čb┼õČ°│╔Ą─▓┐╝■Ż¼╚ńłD2aųą▓┐╝■aė╔ę╗ĮM┴Ń▓┐╝■(c1Ż¼c2Ż¼...Ż¼c10)čb┼õČ°│╔Ż¼ätĘQ▓┐╝■a×ķ▀@ĮM┴Ń▓┐╝■Ą─ĖĖ╝■Ż¼▀@ĮM┴Ń▓┐╝■ųą╦∙ėąéĆ¾wČ╝╩Ū▓┐╝■aĄ─ūė╝■Ż╗Ī░čb┼õĮYśŗĪ▒(║åĘQĪ░ĮYśŗĪ▒)ät╩ŪųĖĖĖ╝■┼cūė╝■ų«ķgčb┼õĻPŽĄĄ─╝»║ŽĪŻé„Įy─Żą═ųąę╗░Ńė├Ī░ĖĖ╝■ę╗ūė╝■Ī▒üĒ▒Ē▀_čb┼õĻPŽĄŻ¼Ą½Ųõ╚▀ėÓČ╚▌^Ė▀Ūę▓╗ęū▒Ē▀_Š▀ėąČÓĘNčb┼õĮYśŗĄ─▓┐╝■ĪŻ╚ńłD2aųąa║═gŠ▀ėąŽÓ═¼Ą─ę╗ĮMūė╝■(c1Ż¼c2Ż¼...Ż¼c10)Ģré„ĮyĄ─Ī░ĖĖ╝■ę╗ūė╝■Ī▒▒Ē╩ŠĢ■ėą├„’@Ą─ųžÅ═Ż¼Č°Ūęę▓▓╗ęūģ^ĘųaĄ─ā╔ĘN▓╗═¼čb┼õĮYśŗĪ░aę╗(c1Ż¼c2Ż¼...Ż¼c10)Ż¼║═Ī░a-(eŻ¼f)ĪŻ
łD2 BOMčb┼õĮYśŗĄ─é„Įy─Żą═┼c▒Š╬──Ż└ńĄ─▒╚▌^
Ī░ĖĖ╝■ę╗ĮYśŗĪ▒▒Ē╩Š▓┐╝■Š▀ėą─│ĘNčb┼õĮYśŗŻ¼╚ńłD2bųąĪ░aĪ¬sĪ▒▒Ē╩Š▓┐╝■aŠ▀ėąčb┼õĮYśŗs(Ħ╚”ūų─Ė▒Ē╩ŠĪ░ĮYśŗĪ▒)Ż╗Ī░ĮYśŗę╗ūė╝■Ī▒▒Ē╩Š─│éĆčb┼õĮYśŗųą║¼ėą─│éĆ┴Ń▓┐╝■Ż¼╚ńĪ░sĪ¬C01Ī▒ĪŻ▀@śėŠ══©▀^BOM─Żą═ųąčb┼õĮYśŗĄ─¬Ü┴óŻ¼╩╣Ī░ĖĖ╝■ę╗ĮYśŗĪ▒║═Ī░ĮYśŗę╗ūė╝■Ī▒ā╔īėĻPŽĄĘųļxŻ¼Å─Č°Ė³▀mė┌▒Ē▀_Å═ļsĄ─BOM▓ó£p╔┘╚▀ėÓĪŻ╚ńłD2bųąčb┼õĮYśŗsĄ─┤µį┌╩╣Ą├Ī░aĪ¬sĪ▒┼cĪ░sĪ¬cĪ▒ŽÓ╗ź¬Ü┴óŻ¼▒▄├Ō┴╦a║═gŽÓ═¼čb┼õĮYśŗĄ─ųžÅ═ąį▒Ē╩ŠŻ¼═¼ĢraĄ─ā╔ĘN▓╗═¼ĮYśŗs║═tĄ├ęį├„┤_Ąž▒Ē▀_ĪŻ×ķ£╩┤_▒Ē▀_╔Ž╩÷BOM─Żą═Ż¼Ž┬├µė├öĄīW╝»║ŽĄ─ĘĮĘ©▀Mąąą╬╩Į╗»├Ķ╩÷Ż║
(1)Č©┴x╬’┴ŽŻ«rĄ─╝»║ŽX=(x1Ż¼x2Ż¼...)Ż╗Č©┴xĮYśŗsĄ─╝»║ŽS={s1Ż¼szŻ¼...}Ż¼Ųõųąs=


3 ĮY║Ž┐╔öUš╣ś╦ėøšZčįĄ─ą┬ą═┤µā”─Żą═
─┐Ū░BOMĄ─┤µā”ę╗░Ń▓╔ė├ĻPŽĄ─Żą═Ż¼Č°ā╚┤µųąĄ─BOMę╗░Ń×ķśõą╬ĮYśŗĄ─ī”Ž¾─Żą═Ż¼─┐Ū░ė╔┤µā”Ą─BOMöĄō■üĒśŗĮ©ā╚┤µųąĄ─BOMī”Ž¾ę╗░Ńėą¹ÉĘNĘĮĘ©Ż║ó┘░┤ššBOMĄ─īė┤╬ĮYśŗ▀Mąą▀fÜw▓ķįāŻ¼▓óę└┤╬śŗĮ©ī”Ž¾ĪŻ▀@ĘNĘĮĘ©īŹ¼FŲüĒ▌^×ķ║åå╬Ż¼Ą½╦┘Č╚║▄┬²Ż╗ó┌═©▀^SQL─_▒ŠüĒīŹ¼F▀fÜw▒ķÜvīó┴Ń▓┐╝■╠Ē╝ėĄĮ┼RĢr▒ĒųąŻ¼╚╗║¾ī”┼RĢr▒Ē▀Mąą▀fÜwŻ¼į┌ā╚┤µųąśŗĮ©śõą╬BOMī”Ž¾Ż©äōĮ©═Ļ│╔║¾äh│²┼RĢr▒Ē)Ż¼▀@ĘNĘĮĘ©Ą─╦┘Č╚┬įėą╠ßĖ▀Ą½ī”ė┌Å═ļsĄ─«aŲĘĮYśŗ╚į¤oĘ©ØMūŃę¬Ū¾ĪŻ▀@ā╔ĘNĘĮĘ©├┐┤╬▓ķįāČ╝ąĶę¬īóBOMöĄō■Å─ĻPŽĄ─Żą═▐DōQĄĮśõą╬ĮYśŗĄ─ī”Ž¾─Żą═Ż¼Č°▀@ĘN«Éśŗ─Żą═ų«ķgĄ─öĄō■▐DōQ╩Ūī¦ų┬BOMūx╚Īą¦┬╩Ą═Ž┬Ą─ų„ę¬įŁę“ĪŻė╔┤╦Ż¼▒Š╬─╠ß│÷īó┼RĢr▒ĒųąĄ─▓ķįāĮY╣¹ų▒Įėęįśõą╬ĮYśŗį┌öĄō■Äņųą┤µā”Ž┬üĒŻ¼į┌ęį║¾ł╠ąą═¼ę╗▓ķįāĢrų▒Įėė╔öĄō■ÄņųąĄ─śõą╬ĮYśŗų▒Įėė│╔õĄĮā╚┤µųąŻ¼Å─Č°▒▄├Ō┴╦├┐┤╬Č╝ī”ĻPŽĄ─Żą═öĄō■▀MąąĄ═ą¦┬╩Ą─▓ķįāĪŻ▀@ą®BOM▓ķįāĮY╣¹┤µā”į┌öĄō■ÄņųąŻ¼ŲĄĮ┴╦öĄō■ŠÅ┤µĄ─ū„ė├Ż¼▒Š╬─ĘQŲõ×ķBOMŠÅ┤µĪŻ
┐╔öUš╣ś╦ėøšZčį(eXtensible Markup LanguageŻ¼XML)ū„×ķę╗ĘN░ļĮYśŗ╗»öĄō■Š▀ėąūį├Ķ╩÷─▄┴”Ż¼Ųõ╠ņ╚╗Ą─śõą╬ĮYśŗĘŪ│Ż▀mė┌▒Ē▀_BOMĄ─īė┤╬ĮYśŗŻ¼┼cā╚┤µųąĄ─BOMī”Ž¾Š▀ėąöĄō■ĮYśŗ╔ŽĄ─═¼śŗąįĪŻ─┐Ū░š¼ę¬Ą─╔╠śIöĄō■ÄņČ╝ęčų¦│ųXMIĪŻöĄō■ŅÉą═Ż¼Č°Ūęį┌öĄō■▓ķįāĘĮ├µŻ¼XQueryšZčįęčĮø│╔×ķ╚fŠSŠW┬ō├╦(W3C)Ą─═Ų╦]ś╦£╩ĪŻĄ½XMLį┌öĄō■Ė³ą┬ĘĮ├µĄ─ś╦£╩╚į▓╗│╔╩ņŻ¼Ė„ĘN╔╠śI▄ø╝■Ą─ęÄĘČę▓▓╗Įyę╗Ż¼Č°Ūę─┐Ū░ČÓöĄą┼ŽóŽĄĮy╚įų„ę¬ų¦│ųĻPŽĄ─Żą═Ż¼ę“┤╦▒Š╬─╠ß│÷ę╗ĘNĻPŽĄ─Żą═┼cXML─Żą═ŽÓĮY║ŽĄ─ą┬ą═┤µā”─Żą═ĪŻįō─Żą═į┌öĄō■ūx╚ĪĘĮ├µ╠ß╣®┴╦╗∙ė┌XML─Żą═Ą─BOMŠÅ┤µęį½@Ą├Ė▀ą¦┬╩Ż¼═¼Ģr╚į▒Ż┴¶┴╦ĻPŽĄ─Żą═Ą─öĄō■ūx╚ĪŻ»ūāĖ³Įė┐┌Ż¼ęį▒ŻūC┴╝║├Ą─╝µ╚▌ąįĪŻ
╚ńłD3╦∙╩ŠŻ¼į┌ą┬ą═─Żą═ųą▓ķįāBOMöĄō■ĢrŻ¼┐╔ęįų▒ĮėÅ─XMLŠÅ┤µųąūx╚ĪęįŪ░┤µā”Ą─BOM▓ķįāĮY╣¹Ż╗╚¶×ķ╩ū┤╬ūx╚ĪŻ¼ät欎╚ī”ĻPŽĄ─Żą═▀Mąą▓ķįā▓óīóĄ├ĄĮĄ─┼RĢr▒Ē╔·│╔śõą╬BOMöĄō■║¾┤µā”ĄĮXMLŠÅ┤µŻ¼╚╗║¾īóŲõūx╚ļā╚┤µĪŻį┌ā╚┤µųąBOMöĄō■░l╔·ūāĖ³ĢrĪŻīóų▒Įėī”┤µā”ųąĄ─ĻPŽĄ─Żą═▓┐Ęų▀Mąą▓Õ╚ļĪóĖ³ą┬╗“äh│²Ą╚öĄō■ūāĖ³▓┘ū„Ż╗į┌ĻPŽĄ─Żą══Ļ│╔ūāĖ³ų«║¾Ż¼į┘Ė∙ō■Ą┌2š┬ųąĄ─ĮYśŗėąą¦ąį┼ąöÓ╩Į▀Mąą┼ąöÓĪŻ╚¶░l╔·ūāĖ³Ą─BOMĮYśŗį┌«öŪ░Ģr┐╠ėąą¦Ż¼ätæ¬┴ó╝┤äh│²ŠÅ┤µųąįŁėąĄ─BOMöĄō■Ż¼▓ó┤µā”ūāĖ³║¾Ą─BOMöĄō■Ż╗╚¶«öŪ░Ģr┐╠¤oą¦Ż¼ätį┌╔·ą¦Ģrūįäė╠Ä└ĒĪŻ┴Ē═ŌŻ¼ī”ė┌▓╗ų¦│ųXMLūx╚ĪĮė┐┌Ą─é„ĮyŽĄĮyŻ¼įō┤µā”─Żą═╚įų¦│ųī”ĻPŽĄ─Żą═Ą─ų▒Įėūx╚ĪĪŻ
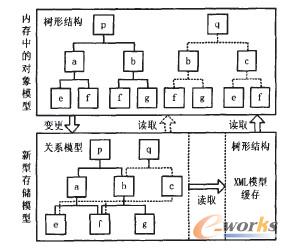
łD3 ĮY║ŽXMLĄ─ą┬ą═┤µā”─Żą═╝░īŹ¼F
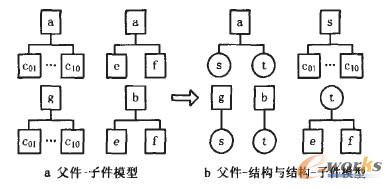
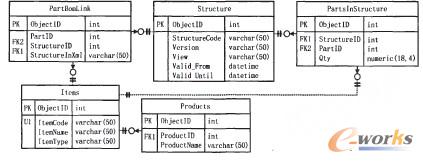
╔Ž╩÷ą┬ą═BOM┤µā”─Żą═Ą─īŹ¾wĻPŽĄłD╚ńłD4╦∙╩ŠŻ¼░³└©Products(«aŲĘ)ĪóItems(╬’┴Ž)ĪóPartBomLink(ĖĖ╝■ę╗ĮYśŗĻPŽĄ)ĪóStructure(ĮYśŗ)ĪóPartsln-Structure(ĮYśŗę╗ūė╝■ĻPŽĄ)╬ÕéĆöĄō■▒ĒĪŻŲõųąŻ║PK×ķĖ„▒ĒĄ─ų„µIŻ╗FKl║═FK2×ķ═ŌµI╝s╩°Ż╗U1×ķ╬©ę╗ąį╝s╩°Ż╗Items▒ĒųąĄ─ItemTypeūųČ╬ė├üĒ┤µā”╬’┴ŽĄ─ŅÉą═Ż¼ėą┐éčbĪóĮMčbĪóūįųŲĪó═ŌģfĪó▓╔┘ÅĪó╠ōöMĪó▀^Č╔║═├½┼„Ą╚Ż╗į┌PartBomLink▒ĒųąįOėŗ┴╦XMLöĄō■ŅÉą═Ą─StructurelnXmlūųČ╬ū„×ķBOMŠÅ┤µĪŻStructurelnXmlūųČ╬┤µā”Ą─XMLöĄō■═Ļš¹ĄžČ©┴x┴╦┴Ń▓┐╝■Ą─š¹éĆBoMĮYśŗöĄō■Ż¼įōūųČ╬Ą─XML╝▄śŗ┐╔ęį║åå╬Ąž╚ńłD5▒Ē╩ŠŻ¼ParentPartį¬╦ž×ķĖ∙╣سcĪŻ×ķ├„┤_▒Ē▀_čb┼õĻPŽĄŻ¼Partį¬╦žæ¬ų┴╔┘░³║¼ī┘ąįPartlD║═Qty(łDųą╩Ī╚ź┴╦▓┐Ęųī┘ąį)Ūę┐╔ęįūį╔ĒŪČ╠ūĪŻ
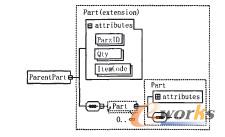
╗∙ė┌ęį╔ŽXML╝▄śŗ▒Ē╩ŠĢrŻ¼łD1ųąBOMīŹ└²Ą─XML┤·┤a╚ńŽ┬Ż║

4 ╬’┴ŽŪÕå╬ŠÅ┤µĄ─śŗĮ©╝░▓ķįā
BOMŠÅ┤µę╗░Ńį┌╩ū┤╬▓ķįā«aŲĘ╗“▓┐╝■Ą─BOMĮYśŗĢräōĮ©Ż¼ė╔ĮoČ©Ą─╬’┴ŽIDųĄproductID(ī”æ¬Items▒ĒųąĄ─ObjectlD)ī”ĻPŽĄ─Żą═▓┐Ęų▀Mąą▓ķįā▓óäōĮ©┼RĢr▒ĒŻ¼╚╗║¾▐DōQ×ķ╗∙ė┌XMLĄ─śõą╬BOMöĄō■Ż¼Š▀¾w▓Į¾E╚ńŽ┬Ż║
▓Į¾E1 äōĮ©┼RĢr▒ĒTempBOMŻ¼╠Ē╝ėūųČ╬ParentPartIDŻ¼ChildPartIDŻ¼ActualQtyŻ¼LevelŻ╗┼RĢrČ茯▒ĒTempPartsŻ¼╠Ē╝ėūųČ╬ChildPartIDŻ¼LevelŻ╗┼RĢr▒ĒTempStructureXmlŻ¼╠Ē╝ėParentPartlD║═XMLŅÉą═ūųČ╬PartStructureŻ╗┼RĢrūā┴┐level-0Ż╗į┌TempPartsųą╠Ē╝ėę╗ąąą┬╝oõø(productIDŻ¼leve1)ĪŻ
▓Į¾E2╚¶levelĪ▌0Ż¼ätīóTempParts╩ūąąėøõøųąParentPartIDūųČ╬Ą─ųĄ┘xĮoparentPartIDŻ¼äh│²įōąąėøõøŻ¼▐D▓Į¾E3Ż╗╚¶level ▓Į¾E3 ═©▀^parentPartlDšęĄĮį┌PartBom-Link▒ĒųąĄ─ĻP┬ōėøõøŻ¼╚¶StructureInXmlūųČ╬▓╗×ķNULLŻ¼ätīóparentPartID║═StructureXmlūųČ╬öĄō■╠Ē╝ėĄĮTempStructureXml▒ĒųąŻ¼level=level-1Ż¼▐D▓Į¾E2Ż╗╚¶StructureInXmlūųČ╬×ķNULLĪŻŪę┤µį┌└ĒéĆStructureID▓╗×ķNULLŻ¼ät▐D▓Į¾E4ĪŻ ▓Į¾E4 šęĄĮ╦∙ėąnéĆStructureID╦∙ĻP┬ōStructure╝»║ŽŻ¼Ė∙ō■ĮYśŗėąą¦ąį┼ąöÓ╩ĮĄ├ĄĮėąą¦ĮYśŗsvŻ¼½@╚ĪsvĄ─ObjectlDŻ¼╚╗║¾▐D▓Į¾E5Ż╗╚¶ø]ėąėąą¦ĮYśŗŻ¼ät▐D▓Į¾E2Ż¼level=level-1ĪŻ ▓Į¾E5 levelĪ¬level+1Ż╗ė╔▓Į¾E4½@╚ĪĄ─StructureIDį┌PartslnStructure▒Ēųą▓ķįāĄ├ĄĮ╦∙ėąĻP┬ōėøõøĄ─PartlDųĄĪóQtyųĄŻ¼▓Į¾E3ųąĄ─parent-PartIDęį╝░levelę╗▓ó╠Ē╝ėĄĮTempBOMųąŽÓæ¬Ą─ChildPartIDŻ¼ActualQtyŻ¼ParentPartID║═LevelūųČ╬Ż¼▓óīó╦∙ėąėøõøĄ─PartIDųĄ║═levelę╗▓ó╠Ē╝ėĄĮTempParts▒ĒųąĄ─ŽÓæ¬ūųČ╬Ż╗▐D▓Į¾E2ĪŻ▓Į ╔Ž╩÷▓Į¾EīŹ¼F┴╦ĻPŽĄ─Żą═öĄō■Ž“śõą╬ĮYśŗ─Żą═Ą─▐DōQŻ¼▀^│╠▌^×ķÅ═ļsĪŻī”ė┌ø]ėąŠÅ┤µĄ─é„Įy┤µā”─Żą═Ż¼├┐┤╬▓ķįāBOMöĄō■Č╝ąĶꬳ╠ąąŅÉ╦Ų▐DōQ▀^│╠Ż¼ę“┤╦ł╠ąą╦┘Č╚▌^┬²ĪŻČ°į┌įOėŗ┴╦ŠÅ┤µĄ─ą┬ą═┤µā”─Żą═ųąŻ¼ų╗ėą╩ū┤╬▓ķįāĢr▓┼Ģ■ł╠ąąįō▐DōQ▀^│╠ĪŻśŗĮ©BOMŠÅ┤µų«║¾Ż¼į┌Microsoft SQL Server2005öĄō■Äņųą▓ķįāłDlųąīŹ└²Ą─▓┐╝■8Ą─BOMĮYśŗĢr┐╔ł╠ąą╚ńŽ┬Ą─SQIĪŻ▓ķįāšZŠõ(įōSQLšZŠõųąā╚ŪČ┴╦xQuery▓ķįāšZŠõ)ĪŻ į┌śŗĮ©ā╚┤µųąĄ─BOMī”Ž¾ĢrŻ¼ų╗ąĶ▒ķÜvęį╔ŽXMLöĄō■Ą─śõą╬ĮYśŗŻ¼īó├┐éĆPartį¬╦žė│╔õ×ķę╗éĆPartī”Ž¾(īóPartį¬╦žĄ─ī┘ąįųĄ┘xĮoPartī”Ž¾Ą─═¼├¹ī┘ąį)Ż¼▓ó╠Ē╝ėĄĮŲõĖĖ╝ēī”Ž¾Ą─ūė╝■µ£▒Ēųą╝┤┐╔ĪŻ 5 ĮY╩°šZ ųŲįņBOM╩ŪųŲįņŲ¾śIīŹ╩®╔·«a╣▄└ĒŽĄĮyĄ─ĻPµI╗∙ĄAöĄō■Ż¼╚ń║╬£p╔┘BOM┤µā”─Żą═Ą─╚▀ėÓėų╝µŅÖ▀\ąąą¦┬╩ę╗ų▒╩ŪBOM─Żą═įOėŗųąĄ─ļy³cĪŻė╔ė┌ųŲįņBOMĄ─öĄō■Ąß╚ĪŅl┬╩▀hĖ▀ė┌öĄō■ūāĖ³Ą─Ņl┬╩Ż¼į┌▒M┴┐▒▄├Ō¤oęµ╚▀ėÓ(╚ńłD2aųąa║═gŽÓ═¼ūė╝■Ą─ųžÅ═▒Ē╩Š)Ą─═¼ĢrŻ¼ī”ė┌─▄ē“├„’@Ė─╔ŲBOMūx╚Īą¦┬╩Ą─╚▀ėÓŻ¼æ¬▀m«ö▒Ż┴¶╔§╚½ąĶę¬īŻķTįOėŗĪŻ▒Š╬──Żą═ųąXMIĪŻŠÅ┤µ▓┐ĘųŽÓī”ė┌ĻPŽĄ─Żą═▓┐Ęųļm╚╗ę▓┤µį┌ę╗Č©╚▀ėÓŻ¼Ą½Ųõų╗╩Ūīó«öŪ░ėąą¦Ą─▓┐ĘųBOMĮYśŗ┴Ēąą┤µā”Ż¼Ņ~═Ōš╝ė├Ą─┐šķg▌^╔┘Ż¼ģs┐╔ęį┤¾Ę∙Č╚╠ß╔²BOM┤µā”─Żą═Ą─š¹¾wąį─▄ĪŻįō─Żą═ė├ė┌CAXAųŲįņ▀^│╠╣▄└ĒŽĄĮy║¾░l¼FŻ¼į┌┴Ń▓┐╝■╣سcįĮČÓĪóčb┼õīė╝ēįĮČÓĢrŻ¼ī”ą¦┬╩Ą─╠ßĖ▀ą¦╣¹įĮ├„’@ĪŻęįśŗĮ©ėą1065éĆ┴Ń▓┐╝■╣سcĪóūŅ╔Ņčb┼õīė╝ē×ķ11īėĄ─BOM×ķ└²Ż¼▀Mąą┴╦10┤╬īŹ“×┼cé„Įy─Żą═▀Mąą▒╚▌^║¾░l¼FŻ║╩ū┤╬ė├Ģré„Įy─Żą═×ķ6.173 sŻ¼▒Š╬──Żą═×ķ6.270 sŻ╗Ą┌2Ī½10┤╬ŲĮŠ∙ė├Ģré„Įy─Żą═×ķ6.156sŻ¼▒Š╬──Żą═×ķ0.078 sĪŻĮY╣¹▒Ē├„Ż¼│²╩ū┤╬ūx╚ĪĢrė╔ė┌śŗĮ©BOMŠÅ┤µČ°ė├Ģr╔įķLų«═ŌŻ¼▒Š╬──Żą═Š▀ėą├„’@Ą─╦┘Č╚ā×ä▌ĪŻ ║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
¾E6 ė╔TempBOM║═PartStructure▒Ē┐╔ęį═©▀^▀fÜw½@Ą├╗∙ė┌XML─Żą═▒Ē╩ŠĄ─BOMöĄō■Ż¼╚╗║¾īóŲõ┤µā”ĄĮPartBomLink▒ĒųąproductIDī”æ¬Ą─StructurelnXmiūųČ╬ųąŻ¼ęįīŹ¼FBOMŠÅ┤µĄ─äōĮ©╗“ūāĖ³ĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║ę╗ĘNą┬Ą─ųŲįņBOM┤µā”─Żą═
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/1082053635.html






















