



ĪĪĪĪ“vėŹśIäš«aŲĘŠĆ▒ŖČÓŻ¼ōĒėą║Ż┴┐Ą─╗Ņ▄Sė├æ¶Ż¼├┐╠ņŠĆ╔Ž«a╔·Ą─öĄō■│¼║§ŽļŽ¾Ż¼▒ž╚╗Ģ■│╔×ķöĄō■┤¾æ¶ĪŻ╠žäe╩ŪļSų°é„ĮyśIäšį÷ķLĘ┼ŠÅŻ¼ęį╝░ęŲäė╗ź┬ōŠWĢr┤·Ą─Š½╝Ü╗»▀\ĀIŻ¼ī”ė┌┤¾öĄō■Ęų╬÷║══┌Š“Ą─ųžęĢ│╠Č╚Ė▀ė┌ęį═∙╚╬║╬Ģr║“Ż¼╚ń║╬Å─┤¾öĄō■ųą½@╚ĪĖ▀ārųĄŻ¼ęčĮø│╔×ķ┤¾╝ęĻPą─Ą─Į╣³cå¢Ņ}ĪŻį┌▀@śėĄ─┤¾▒│Š░Ž┬Ż¼×ķ┴╦╣½╦ŠĖ„śIäš«aŲĘ─▄ē“╩╣ė├Ė³žSĖ╗ā×┘|Ą─öĄō■Ę■䚯¼Į³─Ļ“vėŹ┤¾öĄō■ŲĮ┼_Ą├ĄĮčĖ├═░lš╣ĪŻ
łD 1 ┤¾öĄō■ŲĮ┼_║╦ą──ŻēK
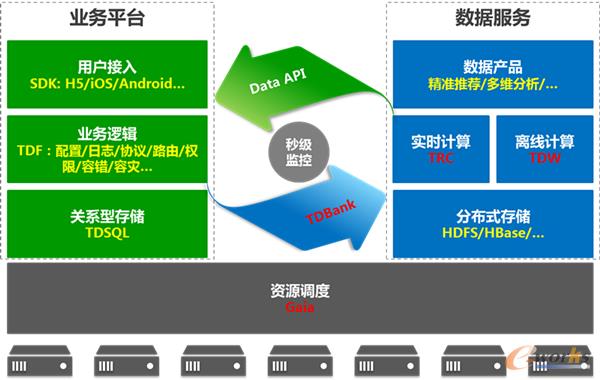
ĪĪĪĪÅ─╔ŽłD┐╔ęį┐┤│÷Ż¼“vėŹ┤¾öĄō■ŲĮ┼_ėą╚ńŽ┬║╦ą──ŻēKŻ║TDWĪóTRCĪóTDBank║═GaiaĪŻ║åå╬üĒšfŻ¼TDWė├üĒū÷┼·┴┐Ą─ļxŠĆėŗ╦ŃŻ¼TRCžōž¤ū÷┴„╩ĮĄ─īŹĢrėŗ╦ŃŻ¼TDBankätū„×ķĮyę╗Ą─öĄō■▓╔╝»╚ļ┐┌Ż¼Č°ĄūīėĄ─Gaiaätžōž¤š¹éĆ╝»╚║Ą─┘Yį┤š{Č╚║═╣▄└ĒĪŻĮėŽ┬üĒŻ¼▒Š╬─Ģ■ßśī”▀@╦─ēKā╚╚▌▀Mąąš¹¾wĮķĮBĪŻ
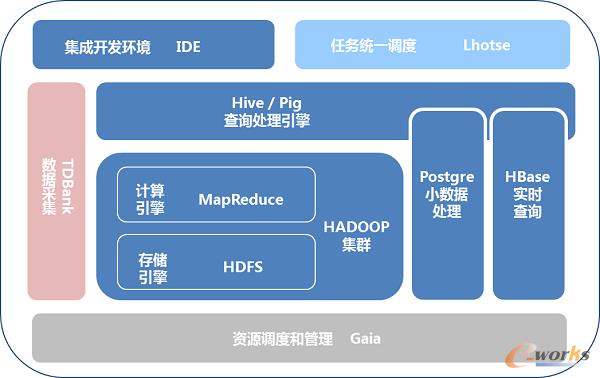
ĪĪĪĪTDW(Tencent distributed Data Warehouse)Ż║“vėŹĘų▓╝╩ĮöĄō■é}ÄņĪŻ╦³ų¦│ų░┘PB╝ēöĄō■Ą─ļxŠĆ┤µā”║═ėŗ╦ŃŻ¼×ķśIäš╠ß╣®║Ż┴┐ĪóĖ▀ą¦ĪóĘĆČ©Ą─┤¾öĄō■ŲĮ┼_ų¦ō╬║═øQ▓▀ų¦│ųĪŻ─┐Ū░Ż¼TDW╝»╚║┐éįOéõ8400┼_Ż¼å╬╝»╚║ūŅ┤¾ęÄ─Ż5600┼_ Ż¼┐é┤µā”öĄō■│¼▀^100PBŻ¼╚šŠ∙ėŗ╦Ń┴┐│¼▀^5PBŻ¼╚šŠ∙JoböĄ▀_ĄĮ100╚féĆĪŻ
łD 2 Ęų▓╝╩ĮöĄō■é}Äņ
ĪĪĪĪ×ķ┴╦ĮĄĄ═ė├æ¶Å─é„Įy╔╠śIöĄō■Äņ▀węŲķTÖæŻ¼TDW╗∙ė┌ķ_į┤Hive▀Mąą┴╦┤¾┴┐Č©ųŲķ_░lĪŻį┌╣”─▄öU│õĘĮ├µŻ¼SQLšZĘ©╝µ╚▌OracleŻ¼īŹ¼F┴╦╗∙ė┌ĮŪ╔½Ą─ÖÓŽ▐╣▄└ĒĪóĘųģ^╣”─▄Īó┤░┐┌║»öĄĪóČÓŠSĘų╬÷╣”─▄Īó╣½ė├▒Ē▒Ē▀_╩Į-CTEĪóDML-update/deleteĪó╚ļÄņöĄō■ąŻ“ץ╚ĪŻį┌ęūė├ąįĘĮ├µŻ¼į÷╝ė┴╦╗∙ė┌PythonĄ─▀^│╠šZčįĮė┐┌Ż¼ęį╝░├³┴Ņąą╣żŠ▀PLClientŻ¼▓ó╠ß╣®┐╔ęĢ╗»Ą─IDE╝»│╔ķ_░lŁhŠ│Ż¼╩╣Ą├ķ_░lą¦┬╩┤¾Ę∙Č╚╠ß╔²ĪŻ┴Ē═ŌŻ¼į┌ąį─▄ā×╗»ĘĮ├µę▓ū÷┴╦┤¾┴┐╣żū„Ż¼░³└©Hash JoinĪó░┤ąąsplitĪóOrder by limitā×╗»Īó▓ķįāėŗäØ▓óąąā×╗»Ą╚Ż¼╠žäe╩Ūßśī”Hiveį¬öĄō■Ą─ųžśŗŻ¼╚źĄ¶┴╦Ą═ą¦Ą─JDOīėŻ¼▓óīŹ¼Fį¬öĄō■╝»╚║╗»Ż¼╩╣ŽĄĮyöUš╣ąį╠ß╔²├„’@ĪŻ
ĪĪĪĪ×ķ┴╦▒M┐╔─▄┤┘▀MöĄō■╣▓ŽĒ║═╠ß╔²ėŗ╦Ń┘Yį┤└¹ė├┬╩Ż¼īŹ╩®śŗĮ©Ė▀ą¦ĘĆČ©Ą─┤¾╝»╚║æ┬įŻ¼TDWßśī”HadoopįŁėą╝▄śŗ▀Mąą┴╦╔ŅČ╚Ė─įņĪŻ╩ūŽ╚Ż¼═©▀^JobTracker/NameNodeĘų╔ó╗»║═╚▌×─Ż¼ĮŌøQ┴╦Masterå╬³cå¢Ņ}Ż¼╩╣Ą├╝»╚║Ą─┐╔öUš╣ąį║═ĘĆČ©ąįĄ├ĄĮ┤¾Ę∙Č╚╠ß╔²ĪŻŲõ┤╬Ż¼ā×╗»╣½ŲĮ┘Yį┤š{Č╚▓▀┬įŻ¼ęįų¦ō╬╔ŽŪ¦▓ó░ljob(¼FŠW3k+)═¼Ģr▀\ąąŻ¼▓óŪęÜwī┘▓╗═¼śI䚥─╚╬äšų«ķg▓╗Ģ■╗źŽÓė░ĒæĪŻ═¼ĢrŻ¼Ė∙ō■öĄō■╩╣ė├Ņl┬╩īŹ╩®▓Ņ«É╗»ē║┐s▓▀┬įŻ¼▒╚╚ń¤ßöĄō■lzoĪó£žöĄō■gzĪó└õöĄō■gz+hdfs raidŻ¼┐éē║┐s┬╩ŽÓī”╬─▒Š┐╔ęį▀_ĄĮ10-20▒ČĪŻ
ĪĪĪĪ┴Ē═ŌŻ¼×ķ┴╦ÅøčaHadoop╠ņ╚╗į┌update/delete▓┘ū„╔ŽĄ─▓╗ūŃŻ¼TDWę²╚ļPostgreSQLū„×ķ▌oų·Ż¼▀mė├ė┌▌^ąĪöĄō■╝»Ą─Ė▀ą¦Ęų╬÷ĪŻ«öŪ░Ż¼TDWš²į┌Ž“ų°īŹĢr╗»░lš╣Ż¼═©▀^ę²╚ļHBase╠ß╣®┴╦Ū¦ā|╝ēīŹĢr▓ķįāĘ■䚯¼▓óķ_╩╝═Č╚ļSparkčą░l×ķ┤¾öĄō■Ęų╬÷╝ė╦┘ĪŻ
ĪĪĪĪTDBank(Tencent Data Bank)Ż║öĄō■īŹĢr╩š╝»┼cĘų░lŲĮ┼_ĪŻśŗĮ©öĄō■į┤║═öĄō■╠Ä└ĒŽĄĮyķgĄ─ś“┴║Ż¼īóöĄō■╠Ä└ĒŽĄĮy═¼öĄō■į┤ĮŌ±ŅŻ¼×ķļxŠĆėŗ╦ŃTDW║═į┌ŠĆėŗ╦ŃTRCŲĮ┼_╠ß╣®öĄō■ų¦│ųĪŻ

łD 3 öĄō■īŹĢr╩š╝»┼cĘų░lŲĮ┼_
ĪĪĪĪÅ─╝▄śŗ╔ŽüĒ┐┤Ż¼TBank┐╔ęįäØĘų×ķŪ░Č╦▓╔╝»Ī󎹎óĮė╚ļĪ󎹎ó┤µā”║═Ž¹ŽóĘųÆ■Ą╚─ŻēKĪŻŪ░Č╦─ŻēKų„ę¬ßśī”Ė„ĘNöĄō■ą╬╩Į(Ųš═©╬─╝■Ż¼DBį÷┴┐/╚½┴┐Ż¼SocketŽ¹ŽóŻ¼╣▓ŽĒā╚┤µĄ╚)╠ß╣®īŹĢr▓╔╝»ĮM╝■Ż¼╠ß╣®┴╦ų„äėŪęīŹĢrĄ─öĄō■½@╚ĪĘĮ╩ĮĪŻųąķg─ŻēKät╩ŪŠ▀éõ╚šĮė╚ļ┴┐╚fā|╝ēĄ─╗∙ė┌“░l▓╝-ėåķå”─Żą═Ą─Ęų▓╝╩ĮŽ¹Žóųąķg╝■Ż¼╦³ŲĄĮ┴╦║▄║├Ą─ŠÅ┤µ║═ŠÅø_ū„ė├Ż¼▒▄├Ō┴╦ę“║¾Č╦ŽĄĮyĘ▒├”╗“╣╩šŽÅ─Č°ī¦ų┬Ą─╠Ä└ĒūĶ╚¹╗“Ž¹ŽóüG╩¦ĪŻßśī”▓╗═¼æ¬ė├ł÷Š░Ż¼TDBank╠ß╣®öĄō■Ą─ų„äėėåķå─Ż╩ĮŻ¼ęį╝░▓╗═¼Ą─öĄō■Ęų░lų¦│ų(Ęų░lĄĮTDWöĄō■é}ÄņŻ¼╬─╝■Ż¼DBŻ¼HBaseŻ¼SocketĄ╚)ĪŻš¹éĆöĄō■═©┬Ę═Ė├„╗»Ż¼ų╗ąĶ║åå╬┼õų├Ż¼╝┤┐╔īŹ¼Fę╗³cĮė╚ļŻ¼š¹éĆ┤¾öĄō■ŲĮ┼_┐╔ė├ĪŻ
ĪĪĪĪ┴Ē═ŌŻ¼×ķ┴╦£p╔┘┤¾┴┐öĄō■▀Mąą┐ń│ŪŠWĮjé„▌öŻ¼TDBankį┌öĄō■é„▌öĄ─▀^│╠ųą▀MąąöĄō■ē║┐sŻ¼▓ó╠ß╣®╣½ŠW/ā╚ŠWūįäėūRäe─Ż╩ĮŻ¼śO┤¾Ą─ĮĄĄ═┴╦īŻŠĆĦīÆ│╔▒ŠĪŻ×ķ┴╦▒ŻšŽöĄō■Ą─═Ļš¹ąįŻ¼TDBank╠ß╣®Č©ųŲ╗»Ą─╩¦öĪųž░l║═×VųžÖCųŲŻ¼▒ŻšŽį┌Å═ļsŠWĮjŪķørŽ┬öĄō■Ą─Ė▀┐╔ė├ĪŻTDBank╗∙ė┌┴„╩ĮĄ─öĄō■╠Ä└Ē▀^│╠Ż¼▒ŻšŽ┴╦öĄō■Ą─īŹĢrąįŻ¼×ķTRCīŹĢrėŗ╦ŃŲĮ┼_╠ß╣®īŹĢrĄ─öĄō■ų¦│ųĪŻ─┐Ū░Ż¼TDBankīŹĢr▓╔╝»Ą─öĄō■│¼▀^150+TB/╚š(╝s5000+ā|Śl/╚š)Ż¼▀@éĆöĄūųę╗ų▒į┌│ų└mį÷ķLųąŻ¼ŅAėŗ─ĻĄūīó│¼▀^2╚fā|Śl/╚šĪŻ
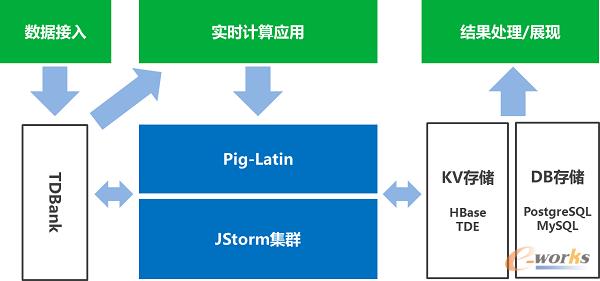
ĪĪĪĪTRC(Tencent Real-time Computing)Ż║“vėŹīŹĢrėŗ╦ŃŲĮ┼_ĪŻū„×ķ║Ż┴┐öĄō■╠Ä└ĒĄ─┴Ēę╗└¹Ų„Ż¼īŻķT×ķī”Ģrķgčė├¶ĖąĄ─śIäš╠ß╣®║Ż┴┐öĄō■īŹĢr╠Ä└ĒĘ■äšĪŻ═©▀^║Ż┴┐öĄō■Ą─īŹĢr▓╔╝»ĪóīŹĢrėŗ╦ŃŻ¼īŹĢrĖąų¬═ŌĮńūā╗»Ż¼Å─╩┬╝■░l╔·ĪóĄĮĖąų¬ūā╗»ĪóĄĮ▌ö│÷ėŗ╦ŃĮY╣¹Ż¼š¹éĆ▀^│╠ųą├ļ╝ē═Ļ│╔ĪŻ
łD 4 īŹĢrėŗ╦ŃŲĮ┼_
ĪĪĪĪTRC╩Ū╗∙ė┌ķ_į┤Ą─Storm╔ŅČ╚Č©ųŲĄ─┴„╩Į╠Ä└Ēę²ŪµŻ¼ė├Javaųžīæ┴╦StormĄ─║╦ą─┤·┤aĪŻ×ķ┴╦ĮŌøQ┴╦┘Yį┤└¹ė├┬╩║═╝»╚║ęÄ─ŻĄ─å¢Ņ}Ż¼ųžśŗ┴╦Ąūīėš{Č╚─ŻēKŻ¼īŹ¼F┴╦╚╬äš╝ēäeĄ─ÖÓŽ▐╣▄└ĒĪó┘Yį┤Ęų┼õĪó┘Yį┤Ė¶ļxŻ¼═©▀^║═Gaia▀@śėĄ─┘Yį┤╣▄└Ē┐“╝▄ŽÓĮY║ŽŻ¼ū÷ĄĮ┴╦Ė∙ō■ŠĆ╔ŽśIäšīŹļH└¹ė├┘Yį┤Ą─ĀŅørŻ¼äėæBöU╚▌&┐s╚▌Ż¼å╬╝»╚║▌p╦╔│¼▀^1000┼_ęÄ─ŻĪŻ×ķ┴╦╠ßĖ▀ŲĮ┼_Ą─ęūė├ąį║═┐╔▀\ŠSąįŻ¼╠ß╣®┴╦ŅÉSQL║═Pig Latin▀@śėĄ─▀^│╠╗»šZčįöUš╣Ż¼ĘĮ▒Ńė├æ¶╠ßĮ╗śI䚯¼╠ß╔²Įė╚ļą¦┬╩Ż¼═¼Ģr╠ß╣®ŽĄĮy╝ēĄ─ųĖś╦Č╚┴┐Ż¼ų¦│ųė├æ¶┤·┤aī”ŲõöUš╣Ż¼īŹĢr▒O┐žš¹éĆŽĄĮy▀\ĀIŁh╣ØĪŻ┴Ē═ŌīóTRCĄ─╣”─▄Ę■äš╗»Ż¼═©▀^REST API╠ß╣®PaaS╝ēäeĄ─ķ_Ę┼Ż¼ė├涤oąĶ┴╦ĮŌĄūīėīŹ¼F╝Ü╣ØŠ═─▄ĘĮ▒ŃĄ─╔ĻšłÖÓŽ▐Ż¼┘Yį┤║═╠ßĮ╗╚╬äšĪŻ
ĪĪĪĪ─┐Ū░Ż¼TRC╚šėŗ╦Ń┤╬öĄ│¼▀^2╚fā|┤╬Ż¼į┌“vėŹęčĮøėą║▄ČÓśIäšš²į┌╩╣ė├TRC╠ß╣®Ą─īŹĢröĄō■╠Ä└ĒĘ■äšĪŻ▒╚╚ńŻ¼ī”ė┌ÅV³c═©ÅVĖµ═Ų╦]Č°čįŻ¼ė├æ¶į┌╗ź┬ōŠW╔ŽĄ─ąą×ķ─▄īŹĢrĄ─ė░ĒæŲõÅVĖµ═Ų╦═ā╚╚▌Ż¼į┌ė├涎┬ę╗┤╬╦óą┬Ēō├µĢrŻ¼Š═╠ß╣®Įoė├涊½£╩Ą─ÅVĖµ;ī”ė┌į┌ŠĆęĢŅlŻ¼ą┬┬äČ°čįŻ¼ė├æ¶Ą─├┐ę╗┤╬╩š▓žĪó³cō¶Īó×gė[ąą×ķŻ¼Č╝─▄▒╗┐ņ╦┘Ą─Üw╚ļ╦¹Ą─éĆ╚╦─Żą═ųąŻ¼┴ó┐╠ą▐š²ęĢŅl║═ą┬┬ä═Ų╦]ĪŻ
ĪĪĪĪGaiaŻ║Įyę╗┘Yį┤š{Č╚ŲĮ┼_ĪŻGaiaŻ¼ŽŻ┼D╔±įÆųąĄ─┤¾Ąžų«╔±Ż¼╩Ū▒Ŗ╔±ų«─ĖŻ¼╚Ī├¹įóęŌĖ„ĘNśIäšŅÉą═║═ėŗ╦Ń┐“╝▄Č╝─▄ų▓Ė∙ė┌“┤¾Ąž”ų«╔ŽĪŻ╦³─▄ē“ūīæ¬ė├ķ_░lš▀Ž±╩╣ė├ę╗┼_│¼╝ēėŗ╦ŃÖCę╗śė╩╣ė├š¹éĆ╝»╚║Ż¼śO┤¾Ąž║å╗»┴╦ķ_░lš▀Ą─┘Yį┤╣▄└Ē▀ē▌ŗĪŻGaia╠ß╣®Ė▀▓ó░l╚╬äšš{Č╚║═┘Yį┤╣▄└ĒŻ¼īŹ¼F╝»╚║┘Yį┤╣▓ŽĒŻ¼Š▀ėą║▄Ė▀Ą─┐╔╔ņ┐sąį║═┐╔┐┐ąįŻ¼╦³▓╗āHų¦│ųMRĄ╚ļxŠĆśI䚯¼▀Ć┐╔ęįų¦│ųīŹĢrėŗ╦ŃŻ¼╔§ų┴į┌ŠĆserviceśIäšĪŻ
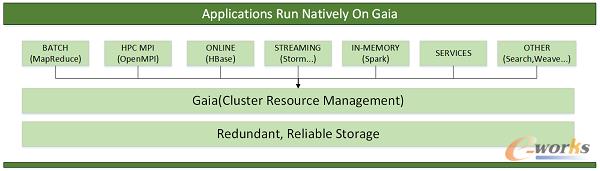
ĪĪĪĪ×ķ┴╦ų¦ō╬å╬╝»╚║8800┼_╔§ų┴Ė³┤¾ęÄ─ŻŻ¼Gaia╗∙ė┌ķ_į┤╔ńģ^Yarnų«╔ŽūįčąSfair (Scalable fair scheduler)š{Č╚Ų„Ż¼ā×╗»š{Č╚▀ē▌ŗŻ¼╠ß╣®Ė³║├Ą─┐╔öUš╣ąįŻ¼▓ó▀Mę╗▓Įį÷ÅŖš{Č╚Ą─╣½ŲĮąįŻ¼╠ß╔²┐╔Č©ųŲ╗»Ż¼īóš{Č╚═╠═┬╠ß╔²10▒Čęį╔ŽĪŻ×ķ┴╦ØMūŃ╔ŽīėČÓśė╗»Ą─ėŗ╦Ń┐“╝▄ĘĆČ©▀\ąąŻ¼Gaia│²┴╦CPUĪóMemĄ─┘Yį┤╣▄└Ēų«═ŌŻ¼ą┬į÷┴╦Network IOŻ¼Disk spaceŻ¼Disk IOĄ╚┘Yį┤╣▄└ĒŠSČ╚Ż¼╠ßĖ▀┴╦Ė¶ļxąįŻ¼×ķśIäš╠ß╣®┴╦Ė³║├Ą─┘Yį┤▒ŻūC║═Ė¶ļxĪŻ═¼ĢrŻ¼Gaiaķ_░l┴╦ūį╝║Ą─ā╚║╦░µ▒ŠŻ¼š{š¹║═ā×╗»CPUĪóMem┘Yį┤╣▄└Ē▓▀┬įŻ¼į┌╝µ╚▌ŠĆ│╠▒O┐žĄ─Ū░╠ߎ┬Ż¼└¹ė├cgroupsŻ¼īŹ¼F┴╦hardlimit+softlimitĮY║ŽĄ─ĘĮ╩ĮŻ¼│õĘų└¹ė├š¹ÖC┘Yį┤Ż¼īócontainer oom killÖC┬╩┤¾Ę∙ĮĄĄ═ĪŻ┴Ē═ŌŻ¼žSĖ╗Ą─APIę▓×ķśIäš╠ß╣®┴╦Ė³▒ŃĮ▌Ą─╚▌×─ĪóöU╚▌Īó┐s╚▌Īó╔²╝ēĄ╚ĘĮ╩ĮĪŻ
ĪĪĪĪ╗∙ė┌ęį╔ŽÄū┤¾╗∙ĄAŲĮ┼_Ą─ĮM║Ž┬ōäėŻ¼┐╔ęį┤“įņ│÷┴╦║▄ČÓĄ─öĄō■«aŲĘ╝░Ę■䚯¼╚ń╔Ž├µ╠ߥĮĄ─Š½£╩═Ų╦]Š═╩ŪŲõųąų«ę╗Ż¼┴Ē═Ō▀ĆėąųT╚ńīŹĢrČÓŠSĘų╬÷Īó├ļ╝ē▒O┐žĪó“vėŹĘų╬÷Īóą┼°ØĄ╚Ą╚ĪŻ│²┴╦ę╗ą®ŽÓī”│╔╩ņĄ─ŲĮ┼_ų«═ŌŻ¼╬ęéā▀Ćį┌▀Mąą▓╗öÓĄ─ćLįćŻ¼ßśī”ą┬Ą─ąĶŪ¾▀MąąĖ³║Ž└ĒĄ─╝╝ąg╠Į╦„Ż¼╚ńĖ³┐ņ╦┘Ą─Į╗╗ź╩ĮĘų╬÷Īóßśī”Å═ļsĻPŽĄµ£Ą─łD╩Įėŗ╦ŃĪŻ┤╦═ŌŻ¼“vėŹ┤¾öĄō■ŲĮ┼_Ą─Ė„ĘN─▄┴”╝░Ę■䚯¼▀Ćīó═©▀^TOD(Tencent Open Data)«aŲĘķ_Ę┼Įo═Ō▓┐Ą┌╚²ĘĮķ_░lš▀ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║“vėŹ┤¾öĄō■ŲĮ┼_╠ĮŠ┐
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839316116.html






















