



ÖCŲ„īW┴Ģ╦ŃĘ©╠½ČÓ┴╦Ż¼ĘųŅÉĪó╗žÜwĪóŠ█ŅÉĪó═Ų╦]ĪółDŽ±ūRäeŅIė“Ą╚Ą╚Ż¼ę¬ŽļšęĄĮę╗éĆ║Ž▀m╦ŃĘ©šµĄ─▓╗╚▌ęūŻ¼╦∙ęįį┌īŹļHæ¬ė├ųąŻ¼╬ęéāę╗░ŃČ╝╩Ū▓╔ė├åó░l╩ĮīW┴ĢĘĮ╩ĮüĒīŹ“×ĪŻ═©│ŻūŅķ_╩╝╬ęéāČ╝Ģ■▀xō±┤¾╝ęŲš▒ķšJ═¼Ą─╦ŃĘ©Ż¼ųT╚ńSVMŻ¼GBDTŻ¼AdaboostŻ¼¼Fį┌╔ŅČ╚īW┴Ģ║▄╗¤ßŻ¼╔±ĮøŠWĮję▓╩Ūę╗éĆ▓╗ÕeĄ─▀xō±ĪŻ╝┘╚ń─Ńį┌║§Š½Č╚Ż©accuracyŻ®Ą─įÆŻ¼ūŅ║├Ą─ĘĮĘ©Š═╩Ū═©▀^Į╗▓µ“×ūCŻ©cross-validationŻ®ī”Ė„éĆ╦ŃĘ©ę╗éĆéĆĄž▀Mąą£yįćŻ¼▀Mąą▒╚▌^Ż¼╚╗║¾š{š¹ģóöĄ┤_▒Ż├┐éĆ╦ŃĘ©▀_ĄĮūŅā×ĮŌŻ¼ūŅ║¾▀xō±ūŅ║├Ą─ę╗éĆĪŻĄ½╩Ū╚ń╣¹─Ńų╗╩Ūį┌īżšęę╗éĆ“ūŃē“║├”Ą─╦ŃĘ©üĒĮŌøQ─ŃĄ─å¢Ņ}Ż¼╗“š▀▀@└’ėąą®╝╝Ū╔┐╔ęįģó┐╝Ż¼Ž┬├µüĒĘų╬÷Ž┬Ė„éĆ╦ŃĘ©Ą─ā×╚▒³cŻ¼╗∙ė┌╦ŃĘ©Ą─ā×╚▒³cŻ¼Ė³ęūė┌╬ęéā╚ź▀xō±╦³ĪŻ
Ų½▓Ņ&ĘĮ▓Ņ
į┌ĮyėŗīWųąŻ¼ę╗éĆ─Żą═║├ē─Ż¼╩ŪĖ∙ō■Ų½▓Ņ║═ĘĮ▓ŅüĒ║Ō┴┐Ą─Ż¼╦∙ęį╬ęéāŽ╚üĒŲš╝░ę╗Ž┬Ų½▓Ņ║═ĘĮ▓ŅŻ║
Ų½▓ŅŻ║├Ķ╩÷Ą─╩ŪŅA£yųĄŻ©╣└ėŗųĄŻ®Ą─Ų┌═¹E’┼cšµīŹųĄYų«ķgĄ─▓ŅŠÓĪŻŲ½▓ŅįĮ┤¾Ż¼įĮŲ½ļxšµīŹöĄō■ĪŻ
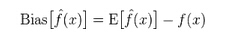
ĘĮ▓ŅŻ║├Ķ╩÷Ą─╩ŪŅA£yųĄPĄ─ūā╗»ĘČć·Ż¼ļx╔ó│╠Č╚Ż¼╩ŪŅA£yųĄĄ─ĘĮ▓ŅŻ¼ę▓Š═╩ŪļxŲõŲ┌═¹ųĄEĄ─ŠÓļxĪŻĘĮ▓ŅįĮ┤¾Ż¼öĄō■Ą─Ęų▓╝įĮĘų╔óĪŻ
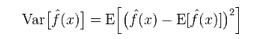
─Żą═Ą─šµīŹš`▓Ņ╩Ūā╔š▀ų«║═Ż¼╚ńŽ┬łDŻ║
╚ń╣¹╩ŪąĪė¢ŠÜ╝»Ż¼Ė▀Ų½▓Ņ/Ą═ĘĮ▓ŅĄ─ĘųŅÉŲ„Ż©└²╚ńŻ¼śŃ╦žžÉ╚~╦╣NBŻ®ę¬▒╚Ą═Ų½▓Ņ/Ė▀ĘĮ▓Ņ┤¾ĘųŅÉĄ─ā×ä▌┤¾Ż©└²╚ńŻ¼KNNŻ®Ż¼ę“×ķ║¾š▀Ģ■▀^öM║ŽĪŻĄ½╩ŪŻ¼ļSų°─Ńė¢ŠÜ╝»Ą─į÷ķLŻ¼─Żą═ī”ė┌įŁöĄō■Ą─ŅA£y─▄┴”Š═įĮ║├Ż¼Ų½▓ŅŠ═Ģ■ĮĄĄ═Ż¼┤╦ĢrĄ═Ų½▓Ņ/Ė▀ĘĮ▓ŅĘųŅÉŲ„Š═Ģ■ØuØuĄ─▒Ē¼FŲõā×ä▌Ż©ę“×ķ╦³éāėą▌^Ą═Ą─ØuĮ³š`▓ŅŻ®Ż¼┤╦ĢrĖ▀Ų½▓ŅĘųŅÉŲ„┤╦ĢręčĮø▓╗ūŃęį╠ß╣®£╩┤_Ą──Żą═┴╦ĪŻ
«ö╚╗Ż¼─Ńę▓┐╔ęįšJ×ķ▀@╩Ū╔·│╔─Żą═Ż©NBŻ®┼c┼ąäe─Żą═Ż©KNNŻ®Ą─ę╗éĆģ^äeĪŻ
×ķ╩▓├┤šfśŃ╦žžÉ╚~╦╣╩ŪĖ▀Ų½▓ŅĄ═ĘĮ▓ŅŻ┐
ęįŽ┬ā╚╚▌ę²ūįų¬║§Ż║
╩ūŽ╚Ż¼╝┘įO─Ńų¬Ą└ė¢ŠÜ╝»║═£yįć╝»Ą─ĻPŽĄĪŻ║åå╬üĒųv╩Ū╬ęéāę¬į┌ė¢ŠÜ╝»╔ŽīW┴Ģę╗éĆ─Żą═Ż¼╚╗║¾─├ĄĮ£yįć╝»╚źė├Ż¼ą¦╣¹║├▓╗║├ę¬Ė∙ō■£yįć╝»Ą─Õeš`┬╩üĒ║Ō┴┐ĪŻĄ½║▄ČÓĢr║“Ż¼╬ęéāų╗─▄╝┘įO£yįć╝»║═ė¢ŠÜ╝»Ą─╩ŪĘ¹║Ž═¼ę╗éĆöĄō■Ęų▓╝Ą─Ż¼Ą½ģs─├▓╗ĄĮšµš²Ą─£yįćöĄō■ĪŻ▀@Ģr║“į§├┤į┌ų╗┐┤ĄĮė¢ŠÜÕeš`┬╩Ą─ŪķørŽ┬Ż¼╚ź║Ō┴┐£yįćÕeš`┬╩─žŻ┐
ė╔ė┌ė¢ŠÜśė▒Š║▄╔┘Ż©ų┴╔┘▓╗ūŃē“ČÓŻ®Ż¼╦∙ęį═©▀^ė¢ŠÜ╝»Ą├ĄĮĄ──Żą═Ż¼┐é▓╗╩Ūšµš²š²┤_Ą─ĪŻŻ©Š═╦Ńį┌ė¢ŠÜ╝»╔Žš²┤_┬╩100%Ż¼ę▓▓╗─▄šf├„╦³┐╠«ŗ┴╦šµīŹĄ─öĄō■Ęų▓╝Ż¼ę¬ų¬Ą└┐╠«ŗšµīŹĄ─öĄō■Ęų▓╝▓┼╩Ū╬ęéāĄ──┐Ą─Ż¼Č°▓╗╩Ūų╗┐╠«ŗė¢ŠÜ╝»Ą─ėąŽ▐Ą─öĄō■³cŻ®ĪŻČ°ŪęŻ¼īŹļHųąŻ¼ė¢ŠÜśė▒Š═∙═∙▀Ćėąę╗Č©Ą─įļ궚`▓ŅŻ¼╦∙ęį╚ń╣¹╠½ūĘŪ¾į┌ė¢ŠÜ╝»╔ŽĄ─═Ļ├└Č°▓╔ė├ę╗éĆ║▄Å═ļsĄ──Żą═Ż¼Ģ■╩╣Ą├─Żą═░čė¢ŠÜ╝»└’├µĄ─š`▓ŅČ╝«ö│╔┴╦šµīŹĄ─öĄō■Ęų▓╝╠žš„Ż¼Å─Č°Ą├ĄĮÕeš`Ą─öĄō■Ęų▓╝╣└ėŗĪŻ▀@śėĄ─įÆŻ¼ĄĮ┴╦šµš²Ą─£yįć╝»╔ŽŠ═ÕeĄ─ę╗╦·║²═┐┴╦Ż©▀@ĘN¼FŽ¾Įą▀^öM║ŽŻ®ĪŻĄ½╩Ūę▓▓╗─▄ė├╠½║åå╬Ą──Żą═Ż¼Ę±ätį┌öĄō■Ęų▓╝▒╚▌^Å═ļsĄ─Ģr║“Ż¼─Żą═Š═▓╗ūŃęį┐╠«ŗöĄō■Ęų▓╝┴╦Ż©¾w¼F×ķ▀Bį┌ė¢ŠÜ╝»╔ŽĄ─Õeš`┬╩Č╝║▄Ė▀Ż¼▀@ĘN¼FŽ¾▌^ŪĘöM║ŽŻ®ĪŻ▀^öM║Ž▒Ē├„▓╔ė├Ą──Żą═▒╚šµīŹĄ─öĄō■Ęų▓╝Ė³Å═ļsŻ¼Č°ŪĘöM║Ž▒Ē╩Š▓╔ė├Ą──Żą═▒╚šµīŹĄ─öĄō■Ęų▓╝ę¬║åå╬ĪŻ
į┌ĮyėŗīW┴Ģ┐“╝▄Ž┬Ż¼┤¾╝ę┐╠«ŗ─Żą═Å═ļsČ╚Ą─Ģr║“Ż¼ėą▀@├┤éĆė^³cŻ¼šJ×ķError = Bias + VarianceĪŻ▀@└’Ą─Error┤¾Ė┼┐╔ęį└ĒĮŌ×ķ─Żą═Ą─ŅA£yÕeš`┬╩Ż¼╩Ūėąā╔▓┐ĘųĮM│╔Ą─Ż¼ę╗▓┐Ęų╩Ūė╔ė┌─Żą═╠½║åå╬ȰĦüĒĄ─╣└ėŗ▓╗£╩┤_Ą─▓┐ĘųŻ©BiasŻ®Ż¼┴Ēę╗▓┐Ęų╩Ūė╔ė┌─Żą═╠½Å═ļsȰĦüĒĄ─Ė³┤¾Ą─ūā╗»┐šķg║═▓╗┤_Č©ąįŻ©VarianceŻ®ĪŻ
╦∙ęįŻ¼▀@śėŠ═╚▌ęūĘų╬÷śŃ╦žžÉ╚~╦╣┴╦ĪŻ╦³║åå╬Ą─╝┘įO┴╦Ė„éĆöĄō■ų«ķg╩Ū¤oĻPĄ─Ż¼╩Ūę╗éĆ▒╗ć└ųž║å╗»┴╦Ą──Żą═ĪŻ╦∙ęįŻ¼ī”ė┌▀@śėę╗éĆ║åå╬─Żą═Ż¼┤¾▓┐Ęųł÷║ŽČ╝Ģ■Bias▓┐Ęų┤¾ė┌Variance▓┐ĘųŻ¼ę▓Š═╩ŪšfĖ▀Ų½▓ŅČ°Ą═ĘĮ▓ŅĪŻ
į┌īŹļHųąŻ¼×ķ┴╦ūīError▒M┴┐ąĪŻ¼╬ęéāį┌▀xō±─Żą═Ą─Ģr║“ąĶę¬ŲĮ║ŌBias║═Variance╦∙š╝Ą─▒╚└²Ż¼ę▓Š═╩ŪŲĮ║Ōover-fitting║═under-fittingĪŻ
Ų½▓Ņ║═ĘĮ▓Ņ┼c─Żą═Å═ļsČ╚Ą─ĻPŽĄ╩╣ė├Ž┬łDĖ³╝ė├„┴╦Ż║
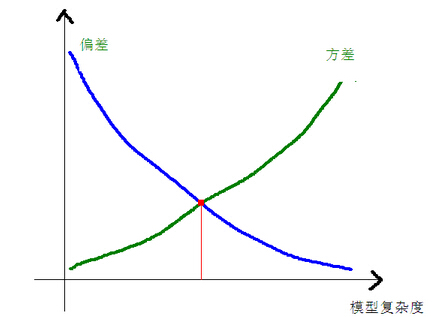
«ö─Żą═Å═ļsČ╚╔Ž╔²Ą─Ģr║“Ż¼Ų½▓ŅĢ■ųØuūāąĪŻ¼Č°ĘĮ▓ŅĢ■ųØuūā┤¾ĪŻ
│ŻęŖ╦ŃĘ©ā×╚▒³c
1.śŃ╦žžÉ╚~╦╣
śŃ╦žžÉ╚~╦╣ī┘ė┌╔·│╔╩Į─Żą═Ż©ĻPė┌╔·│╔─Żą═║═┼ąäe╩Į─Żą═Ż¼ų„ę¬▀Ć╩Ūį┌ė┌╩Ūʱ╩Ūę¬Ū¾┬ō║ŽĘų▓╝Ż®Ż¼ĘŪ│Ż║åå╬Ż¼─Ńų╗╩Ūū÷┴╦ę╗ČčėŗöĄĪŻ╚ń╣¹ūóėąŚl╝■¬Ü┴óąį╝┘įOŻ©ę╗éĆ▒╚▌^ć└Ė±Ą─Śl╝■Ż®Ż¼śŃ╦žžÉ╚~╦╣ĘųŅÉŲ„Ą─╩šö┐╦┘Č╚īó┐ņė┌┼ąäe─Żą═Ż¼╚ń▀ē▌ŗ╗žÜwŻ¼╦∙ęį─Ńų╗ąĶę¬▌^╔┘Ą─ė¢ŠÜöĄō■╝┤┐╔ĪŻ╝┤╩╣NBŚl╝■¬Ü┴ó╝┘įO▓╗│╔┴óŻ¼NBĘųŅÉŲ„į┌īŹ█`ųą╚į╚╗▒Ē¼FĄ─║▄│÷╔½ĪŻ╦³Ą─ų„ę¬╚▒³c╩Ū╦³▓╗─▄īW┴Ģ╠žš„ķgĄ─ŽÓ╗źū„ė├Ż¼ė├mRMRųąRüĒųvŻ¼Š═╩Ū╠žš„╚▀ėÓĪŻę²ė├ę╗éĆ▒╚▌^ĮøĄõĄ─└²ūėŻ¼▒╚╚ńŻ¼ļm╚╗─ŃŽ▓ÜgBrad Pitt║═Tom CruiseĄ─ļŖė░Ż¼Ą½╩Ū╦³▓╗─▄īW┴Ģ│÷─Ń▓╗Ž▓Üg╦¹éāį┌ę╗Ųč▌Ą─ļŖė░ĪŻ
ā׳cŻ║
śŃ╦žžÉ╚~╦╣─Żą═░lį┤ė┌╣┼ĄõöĄīW└ĒšōŻ¼ėąų°łįīŹĄ─öĄīW╗∙ĄAŻ¼ęį╝░ĘĆČ©Ą─ĘųŅÉą¦┬╩ĪŻ
ī”ąĪęÄ─ŻĄ─öĄō■▒Ē¼F║▄║├Ż¼─▄éĆ╠Ä└ĒČÓĘųŅÉ╚╬䚯¼▀m║Žį÷┴┐╩Įė¢ŠÜŻ╗
ī”╚▒╩¦öĄō■▓╗╠½├¶ĖąŻ¼╦ŃĘ©ę▓▒╚▌^║åå╬Ż¼│Żė├ė┌╬─▒ŠĘųŅÉĪŻ
╚▒³cŻ║
ąĶę¬ėŗ╦ŃŽ╚“×Ė┼┬╩Ż╗
ĘųŅÉøQ▓▀┤µį┌Õeš`┬╩Ż╗
ī”▌ö╚ļöĄō■Ą─▒Ē▀_ą╬╩Į║▄├¶ĖąĪŻ
2.Logistic RegressionŻ©▀ē▌ŗ╗žÜwŻ®
ī┘ė┌┼ąäe╩Į─Żą═Ż¼ėą║▄ČÓš²ät╗»─Żą═Ą─ĘĮĘ©Ż©L0Ż¼ L1Ż¼L2Ż¼etcŻ®Ż¼Č°Ūę─Ń▓╗▒žŽ±į┌ė├śŃ╦žžÉ╚~╦╣─Ūśėō·ą──ŃĄ─╠žš„╩ŪʱŽÓĻPĪŻ┼cøQ▓▀śõ┼cSVMÖCŽÓ▒╚Ż¼─Ń▀ĆĢ■Ą├ĄĮę╗éĆ▓╗ÕeĄ─Ė┼┬╩ĮŌßīŻ¼─Ń╔§ų┴┐╔ęį▌p╦╔Ąž└¹ė├ą┬öĄō■üĒĖ³ą┬─Żą═Ż©╩╣ė├į┌ŠĆ╠▌Č╚Ž┬ĮĄ╦ŃĘ©Ż¼online gradient descentŻ®ĪŻ╚ń╣¹─ŃąĶę¬ę╗éĆĖ┼┬╩╝▄śŗŻ©▒╚╚ńŻ¼║åå╬Ąžš{╣ØĘųŅÉķōųĄŻ¼ųĖ├„▓╗┤_Č©ąįŻ¼╗“š▀╩Ūę¬½@Ą├ų├ą┼ģ^ķgŻ®Ż¼╗“š▀─ŃŽŻ═¹ęį║¾īóĖ³ČÓĄ─ė¢ŠÜöĄō■┐ņ╦┘š¹║ŽĄĮ─Żą═ųą╚źŻ¼─Ū├┤╩╣ė├╦³░╔ĪŻ
Sigmoid║»öĄŻ║
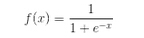
ā׳cŻ║
īŹ¼F║åå╬Ż¼ÅVĘ║Ą─æ¬ė├ė┌╣żśIå¢Ņ}╔ŽŻ╗
ĘųŅÉĢrėŗ╦Ń┴┐ĘŪ│ŻąĪŻ¼╦┘Č╚║▄┐ņŻ¼┤µā”┘Yį┤Ą═Ż╗
▒Ń└¹Ą─ė^£yśė▒ŠĖ┼┬╩ĘųöĄŻ╗
ī”▀ē▌ŗ╗žÜwČ°čįŻ¼ČÓųž╣▓ŠĆąį▓ó▓╗╩Ūå¢Ņ}Ż¼╦³┐╔ęįĮY║ŽL2š²ät╗»üĒĮŌøQįōå¢Ņ}Ż╗
╚▒³cŻ║
«ö╠žš„┐šķg║▄┤¾ĢrŻ¼▀ē▌ŗ╗žÜwĄ─ąį─▄▓╗╩Ū║▄║├Ż╗
╚▌ęūŪĘöM║ŽŻ¼ę╗░Ń£╩┤_Č╚▓╗╠½Ė▀
▓╗─▄║▄║├Ąž╠Ä└Ē┤¾┴┐ČÓŅÉ╠žš„╗“ūā┴┐Ż╗
ų╗─▄╠Ä└Ēā╔ĘųŅÉå¢Ņ}Ż©į┌┤╦╗∙ĄA╔Žč▄╔·│÷üĒĄ─softmax┐╔ęįė├ė┌ČÓĘųŅÉŻ®Ż¼Ūę▒žĒÜŠĆąį┐╔ĘųŻ╗
ī”ė┌ĘŪŠĆąį╠žš„Ż¼ąĶę¬▀Mąą▐DōQŻ╗
3.ŠĆąį╗žÜw
ŠĆąį╗žÜw╩Ūė├ė┌╗žÜwĄ─Ż¼Č°▓╗Ž±Logistic╗žÜw╩Ūė├ė┌ĘųŅÉŻ¼Ųõ╗∙▒Š╦╝Žļ╩Ūė├╠▌Č╚Ž┬ĮĄĘ©ī”ūŅąĪČ■│╦Ę©ą╬╩ĮĄ─š`▓Ņ║»öĄ▀Mąąā×╗»Ż¼«ö╚╗ę▓┐╔ęįė├normal equationų▒ĮėŪ¾Ą├ģóöĄĄ─ĮŌŻ¼ĮY╣¹×ķŻ║
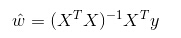
Č°į┌LWLRŻ©Šų▓┐╝ėÖÓŠĆąį╗žÜwŻ®ųąŻ¼ģóöĄĄ─ėŗ╦Ń▒Ē▀_╩Į×ķŻ║
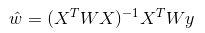
ė╔┤╦┐╔ęŖLWLR┼cLR▓╗═¼Ż¼LWLR╩Ūę╗éĆĘŪģóöĄ─Żą═Ż¼ę“×ķ├┐┤╬▀Mąą╗žÜwėŗ╦ŃČ╝ę¬▒ķÜvė¢ŠÜśė▒Šų┴╔┘ę╗┤╬ĪŻ
ā׳cŻ║ īŹ¼F║åå╬Ż¼ėŗ╦Ń║åå╬Ż╗
╚▒³cŻ║ ▓╗─▄öM║ŽĘŪŠĆąįöĄō■.
4.ūŅĮ³ŅI╦ŃĘ©——KNN
KNN╝┤ūŅĮ³ÓÅ╦ŃĘ©Ż¼Ųõų„ę¬▀^│╠×ķŻ║
1.ėŗ╦Ńė¢ŠÜśė▒Š║═£yįćśė▒Šųą├┐éĆśė▒Š³cĄ─ŠÓļxŻ©│ŻęŖĄ─ŠÓļxČ╚┴┐ėąÜW╩ĮŠÓļxŻ¼±R╩ŽŠÓļxĄ╚Ż®Ż╗2.ī”╔Ž├µ╦∙ėąĄ─ŠÓļxųĄ▀Mąą┼┼ą“Ż╗3.▀xŪ░kéĆūŅąĪŠÓļxĄ─śė▒ŠŻ╗4.Ė∙ō■▀@kéĆśė▒ŠĄ─ś╦║×▀Mąą═ČŲ▒Ż¼Ą├ĄĮūŅ║¾Ą─ĘųŅÉŅÉäeŻ╗
╚ń║╬▀xō±ę╗éĆūŅ╝čĄ─KųĄŻ¼▀@╚ĪøQė┌öĄō■ĪŻę╗░ŃŪķørŽ┬Ż¼į┌ĘųŅÉĢr▌^┤¾Ą─KųĄ─▄ē“£pąĪįļ┬ĢĄ─ė░ĒæĪŻĄ½Ģ■╩╣ŅÉäeų«ķgĄ─ĮńŽ▐ūāĄ├─Ż║²ĪŻę╗éĆ▌^║├Ą─KųĄ┐╔═©▀^Ė„ĘNåó░l╩Į╝╝ągüĒ½@╚ĪŻ¼▒╚╚ńŻ¼Į╗▓µ“×ūCĪŻ┴Ē═Ōįļ┬Ģ║═ĘŪŽÓĻPąį╠žš„Ž“┴┐Ą─┤µį┌Ģ■╩╣KĮ³ÓÅ╦ŃĘ©Ą─£╩┤_ąį£pąĪĪŻ
Į³ÓÅ╦ŃĘ©Š▀ėą▌^ÅŖĄ─ę╗ų┬ąįĮY╣¹ĪŻļSų°öĄō■┌ģė┌¤oŽ▐Ż¼╦ŃĘ©▒ŻūCÕeš`┬╩▓╗Ģ■│¼▀^žÉ╚~╦╣╦ŃĘ©Õeš`┬╩Ą─ā╔▒ČĪŻī”ė┌ę╗ą®║├Ą─KųĄŻ¼KĮ³ÓÅ▒ŻūCÕeš`┬╩▓╗Ģ■│¼▀^žÉ╚~╦╣└Ēšōš`▓Ņ┬╩ĪŻ
KNN╦ŃĘ©Ą─ā׳c
└Ēšō│╔╩ņŻ¼╦╝Žļ║åå╬Ż¼╝╚┐╔ęįė├üĒū÷ĘųŅÉę▓┐╔ęįė├üĒū÷╗žÜwŻ╗
┐╔ė├ė┌ĘŪŠĆąįĘųŅÉŻ╗
ė¢ŠÜĢrķgÅ═ļsČ╚×ķO(n)Ż╗
ī”öĄō■ø]ėą╝┘įOŻ¼£╩┤_Č╚Ė▀Ż¼ī”outlier▓╗├¶ĖąŻ╗
╚▒³c
ėŗ╦Ń┴┐┤¾Ż╗
śė▒Š▓╗ŲĮ║Ōå¢Ņ}Ż©╝┤ėąą®ŅÉäeĄ─śė▒ŠöĄ┴┐║▄ČÓŻ¼Č°Ųõ╦³śė▒ŠĄ─öĄ┴┐║▄╔┘Ż®Ż╗
ąĶę¬┤¾┴┐Ą─ā╚┤µŻ╗
5.øQ▓▀śõ
ęūė┌ĮŌßīĪŻ╦³┐╔ęį║┴¤oē║┴”Ąž╠Ä└Ē╠žš„ķgĄ─Į╗╗źĻPŽĄ▓óŪę╩ŪĘŪģóöĄ╗»Ą─Ż¼ę“┤╦─Ń▓╗▒žō·ą─«É│ŻųĄ╗“š▀öĄō■╩ŪʱŠĆąį┐╔ĘųŻ©┼eéĆ└²ūėŻ¼øQ▓▀śõ─▄▌p╦╔╠Ä└Ē║├ŅÉäeAį┌─│éĆ╠žš„ŠSČ╚xĄ──®Č╦Ż¼ŅÉäeBį┌ųąķgŻ¼╚╗║¾ŅÉäeAėų│÷¼Fį┌╠žš„ŠSČ╚xŪ░Č╦Ą─ŪķørŻ®ĪŻ╦³Ą─╚▒³cų«ę╗Š═╩Ū▓╗ų¦│ųį┌ŠĆīW┴ĢŻ¼ė┌╩Ūį┌ą┬śė▒ŠĄĮüĒ║¾Ż¼øQ▓▀śõąĶę¬╚½▓┐ųžĮ©ĪŻ┴Ēę╗éĆ╚▒³cŠ═╩Ū╚▌ęū│÷¼F▀^öM║ŽŻ¼Ą½▀@ę▓Š═╩ŪųT╚ńļSÖC╔Ł┴ųRFŻ©╗“╠ß╔²śõboosted treeŻ®ų«ŅÉĄ─╝»│╔ĘĮĘ©Ą─Ūą╚ļ³cĪŻ┴Ē═ŌŻ¼ļSÖC╔Ł┴ųĮø│Ż╩Ū║▄ČÓĘųŅÉå¢Ņ}Ą─┌A╝ꯩ═©│Ż▒╚ų¦│ųŽ“┴┐ÖC║├╔Ž─Ū├┤ę╗ČĪ³cŻ®Ż¼╦³ė¢ŠÜ┐ņ╦┘▓óŪę┐╔š{Ż¼═¼Ģr─ѤoĒÜō·ą─ꬎ±ų¦│ųŽ“┴┐ÖC─Ūśėš{ę╗┤¾ČčģóöĄŻ¼╦∙ęįį┌ęįŪ░Č╝ę╗ų▒║▄╩▄ÜgėŁĪŻ
øQ▓▀śõųą║▄ųžę¬Ą─ę╗³cŠ═╩Ū▀xō±ę╗éĆī┘ąį▀MąąĘųų”Ż¼ę“┤╦ę¬ūóęŌę╗Ž┬ą┼Žóį÷굥─ėŗ╦Ń╣½╩ĮŻ¼▓ó╔Ņ╚ļ└ĒĮŌ╦³ĪŻ
ą┼ŽóņžĄ─ėŗ╦Ń╣½╩Į╚ńŽ┬Ż║
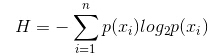
ŲõųąĄ─n┤·▒ĒėąnéĆĘųŅÉŅÉäeŻ©▒╚╚ń╝┘įO╩Ū2ŅÉå¢Ņ}Ż¼─Ū├┤n=2Ż®ĪŻĘųäeėŗ╦Ń▀@2ŅÉśė▒Šį┌┐éśė▒Šųą│÷¼FĄ─Ė┼┬╩p1║═p2Ż¼▀@śėŠ═┐╔ęįėŗ╦Ń│÷╬┤▀xųąī┘ąįĘųų”Ū░Ą─ą┼ŽóņžĪŻ
¼Fį┌▀xųąę╗éĆī┘ąįxixiė├üĒ▀MąąĘųų”Ż¼┤╦ĢrĘųų”ęÄät╩ŪŻ║╚ń╣¹xi=vxi=vĄ─įÆŻ¼īóśė▒ŠĘųĄĮśõĄ─ę╗éĆĘųų¦Ż╗╚ń╣¹▓╗ŽÓĄ╚ät▀M╚ļ┴Ēę╗éĆĘųų¦ĪŻ║▄’@╚╗Ż¼Ęųų¦ųąĄ─śė▒Š║▄ėą┐╔─▄░³└©2éĆŅÉäeŻ¼Ęųäeėŗ╦Ń▀@2éĆĘųų¦Ą─ņžH1║═H2Ż¼ėŗ╦Ń│÷Ęųų”║¾Ą─┐éą┼ŽóņžH’ =p1 H1+p2H2Ż¼ät┤╦ĢrĄ─ą┼Žóį÷ęµΔH = H – H’ĪŻęįą┼Žóį÷ęµ×ķįŁätŻ¼░č╦∙ėąĄ─ī┘ąįČ╝£yįćę╗▀ģŻ¼▀xō±ę╗éĆ╩╣į÷ęµūŅ┤¾Ą─ī┘ąįū„×ķ▒Š┤╬Ęųų”ī┘ąįĪŻ
øQ▓▀śõūį╔ĒĄ─ā׳c
ėŗ╦Ń║åå╬Ż¼ęūė┌└ĒĮŌŻ¼┐╔ĮŌßīąįÅŖŻ╗
▒╚▌^▀m║Ž╠Ä└Ēėą╚▒╩¦ī┘ąįĄ─śė▒ŠŻ╗
─▄ē“╠Ä└Ē▓╗ŽÓĻPĄ─╠žš„Ż╗
į┌ŽÓī”Č╠Ą─Ģrķgā╚─▄ē“ī”┤¾ą═öĄō■į┤ū÷│÷┐╔ąąŪ깦╣¹┴╝║├Ą─ĮY╣¹ĪŻ
╚▒³c
╚▌ęū░l╔·▀^öM║ŽŻ©ļSÖC╔Ł┴ų┐╔ęį║▄┤¾│╠Č╚╔Ž£p╔┘▀^öM║ŽŻ®Ż╗
║÷┬į┴╦öĄō■ų«ķgĄ─ŽÓĻPąįŻ╗
ī”ė┌─Ūą®Ė„ŅÉäeśė▒ŠöĄ┴┐▓╗ę╗ų┬Ą─öĄō■Ż¼į┌øQ▓▀śõ«öųąŻ¼ą┼Žóį÷굥─ĮY╣¹Ų½Ž“ė┌─Ūą®Š▀ėąĖ³ČÓöĄųĄĄ─╠žš„Ż©ų╗ę¬╩Ū╩╣ė├┴╦ą┼Žóį÷굯¼Č╝ėą▀@éĆ╚▒³cŻ¼╚ńRFŻ®ĪŻ
5.1 Adaboosting
Adaboost╩Ūę╗ĘN╝ė║═─Żą═Ż¼├┐éĆ─Żą═Č╝╩Ū╗∙ė┌╔Žę╗┤╬─Żą═Ą─Õeš`┬╩üĒĮ©┴óĄ─Ż¼▀^ĘųĻPūóĘųÕeĄ─śė▒ŠŻ¼Č°ī”š²┤_ĘųŅÉĄ─śė▒Š£p╔┘ĻPūóČ╚Ż¼ų┤╬Ą³┤·ų«║¾Ż¼┐╔ęįĄ├ĄĮę╗éĆŽÓī”▌^║├Ą──Żą═ĪŻ╩Ūę╗ĘNĄõą═Ą─boosting╦ŃĘ©ĪŻŽ┬├µ╩Ū┐éĮYŽ┬╦³Ą─ā×╚▒³cĪŻ
ā׳c
adaboost╩Ūę╗ĘNėą║▄Ė▀Š½Č╚Ą─ĘųŅÉŲ„ĪŻ
┐╔ęį╩╣ė├Ė„ĘNĘĮĘ©śŗĮ©ūėĘųŅÉŲ„Ż¼Adaboost╦ŃĘ©╠ß╣®Ą─╩Ū┐“╝▄ĪŻ
«ö╩╣ė├║åå╬ĘųŅÉŲ„ĢrŻ¼ėŗ╦Ń│÷Ą─ĮY╣¹╩Ū┐╔ęį└ĒĮŌĄ─Ż¼▓óŪę╚§ĘųŅÉŲ„Ą─śŗįņśOŲõ║åå╬ĪŻ
║åå╬Ż¼▓╗ė├ū÷╠žš„║Y▀xĪŻ
▓╗╚▌ęū░l╔·overfittingĪŻ
ĻPė┌ļSÖC╔Ł┴ų║═GBDTĄ╚ĮM║Ž╦ŃĘ©Ż¼ģó┐╝▀@Ų¬╬─š┬Ż║ÖCŲ„īW┴Ģ-ĮM║Ž╦ŃĘ©┐éĮY
╚▒³cŻ║ī”outlier▒╚▌^├¶Ėą
6.SVMų¦│ųŽ“┴┐ÖC
Ė▀£╩┤_┬╩Ż¼×ķ▒▄├Ō▀^öM║Ž╠ß╣®┴╦║▄║├Ą─└Ēšō▒ŻūCŻ¼Č°ŪęŠ═╦ŃöĄō■į┌įŁ╠žš„┐šķgŠĆąį▓╗┐╔ĘųŻ¼ų╗ę¬ĮoéĆ║Ž▀mĄ─║╦║»öĄŻ¼╦³Š═─▄▀\ąąĄ├║▄║├ĪŻį┌äė▌m│¼Ė▀ŠSĄ─╬─▒ŠĘųŅÉå¢Ņ}ųą╠žäe╩▄ÜgėŁĪŻ┐╔Ž¦ā╚┤µŽ¹║─┤¾Ż¼ļyęįĮŌßīŻ¼▀\ąą║═š{ģóę▓ėąą®¤®╚╦Ż¼Č°ļSÖC╔Ł┴ųģsäé║├▒▄ķ_┴╦▀@ą®╚▒³cŻ¼▒╚▌^īŹė├ĪŻ
ā׳c
┐╔ęįĮŌøQĖ▀ŠSå¢Ņ}Ż¼╝┤┤¾ą═╠žš„┐šķgŻ╗
─▄ē“╠Ä└ĒĘŪŠĆąį╠žš„Ą─ŽÓ╗źū„ė├Ż╗
¤oąĶę└┘ćš¹éĆöĄō■Ż╗
┐╔ęį╠ßĖ▀Ę║╗»─▄┴”Ż╗
╚▒³c
«öė^£yśė▒Š║▄ČÓĢrŻ¼ą¦┬╩▓ó▓╗╩Ū║▄Ė▀Ż╗
ī”ĘŪŠĆąįå¢Ņ}ø]ėą═©ė├ĮŌøQĘĮ░ĖŻ¼ėąĢr║“║▄ļyšęĄĮę╗éĆ║Ž▀mĄ─║╦║»öĄŻ╗
ī”╚▒╩¦öĄō■├¶ĖąŻ╗
ī”ė┌║╦Ą─▀xō±ę▓╩Ūėą╝╝Ū╔Ą─Ż©libsvmųąūįĦ┴╦╦─ĘN║╦║»öĄŻ║ŠĆąį║╦ĪóČÓĒŚ╩Į║╦ĪóRBFęį╝░sigmoid║╦Ż®Ż║
Ą┌ę╗Ż¼╚ń╣¹śė▒ŠöĄ┴┐ąĪė┌╠žš„öĄŻ¼─Ū├┤Š═ø]▒žę¬▀xō±ĘŪŠĆąį║╦Ż¼║åå╬Ą─╩╣ė├ŠĆąį║╦Š═┐╔ęį┴╦Ż╗
Ą┌Č■Ż¼╚ń╣¹śė▒ŠöĄ┴┐┤¾ė┌╠žš„öĄ─┐Ż¼▀@Ģr┐╔ęį╩╣ė├ĘŪŠĆąį║╦Ż¼īóśė▒Šė│╔õĄĮĖ³Ė▀ŠSČ╚Ż¼ę╗░Ń┐╔ęįĄ├ĄĮĖ³║├Ą─ĮY╣¹Ż╗
Ą┌╚²Ż¼╚ń╣¹śė▒ŠöĄ─┐║═╠žš„öĄ─┐ŽÓĄ╚Ż¼įōŪķør┐╔ęį╩╣ė├ĘŪŠĆąį║╦Ż¼įŁ└Ē║═Ą┌Č■ĘNę╗śėĪŻ
ī”ė┌Ą┌ę╗ĘNŪķørŻ¼ę▓┐╔ęįŽ╚ī”öĄō■▀MąąĮĄŠSŻ¼╚╗║¾╩╣ė├ĘŪŠĆąį║╦Ż¼▀@ę▓╩Ūę╗ĘNĘĮĘ©ĪŻ
7. ╚╦╣ż╔±ĮøŠWĮjĄ─ā×╚▒³c
╚╦╣ż╔±ĮøŠWĮjĄ─ā׳cŻ║
ĘųŅÉĄ─£╩┤_Č╚Ė▀Ż╗
▓óąąĘų▓╝╠Ä└Ē─▄┴”ÅŖŻ¼Ęų▓╝┤µā”╝░īW┴Ģ─▄┴”ÅŖŻ¼
ī”įļ┬Ģ╔±Įøėą▌^ÅŖĄ─¶ö░¶ąį║═╚▌Õe─▄┴”Ż¼─▄│õĘų▒ŲĮ³Å═ļsĄ─ĘŪŠĆąįĻPŽĄŻ╗
Š▀éõ┬ōŽļėøæøĄ─╣”─▄ĪŻ
╚╦╣ż╔±ĮøŠWĮjĄ─╚▒³cŻ║
╔±ĮøŠWĮjąĶę¬┤¾┴┐Ą─ģóöĄŻ¼╚ńŠWĮj═žōõĮYśŗĪóÖÓųĄ║═ķōųĄĄ─│§╩╝ųĄŻ╗
▓╗─▄ė^▓ņų«ķgĄ─īW┴Ģ▀^│╠Ż¼▌ö│÷ĮY╣¹ļyęįĮŌßīŻ¼Ģ■ė░ĒæĄĮĮY╣¹Ą─┐╔ą┼Č╚║═┐╔Įė╩▄│╠Č╚Ż╗
īW┴ĢĢrķg▀^ķLŻ¼╔§ų┴┐╔─▄▀_▓╗ĄĮīW┴ĢĄ──┐Ą─ĪŻ
8ĪóK-MeansŠ█ŅÉ
ų«Ū░īæ▀^ę╗Ų¬ĻPė┌K-MeansŠ█ŅÉĄ─╬─š┬Ż¼▓®╬─µ£ĮėŻ║ÖCŲ„īW┴Ģ╦ŃĘ©-K-meansŠ█ŅÉĪŻĻPė┌K-MeansĄ─═Ųī¦Ż¼└’├µėąų°║▄ÅŖ┤¾Ą─EM╦╝ŽļĪŻ
ā׳c
╦ŃĘ©║åå╬Ż¼╚▌ęūīŹ¼F Ż╗
ī”╠Ä└Ē┤¾öĄō■╝»Ż¼įō╦ŃĘ©╩ŪŽÓī”┐╔╔ņ┐sĄ─║═Ė▀ą¦┬╩Ą─Ż¼ę“×ķ╦³Ą─Å═ļsČ╚┤¾╝s╩ŪO(nkt)Ż¼Ųõųąn╩Ū╦∙ėąī”Ž¾Ą─öĄ─┐Ż¼k╩Ū┤žĄ─öĄ─┐Ż¼t╩ŪĄ³┤·Ą─┤╬öĄĪŻ═©│Żk< ╦ŃĘ©ćLįćšę│÷╩╣ŲĮĘĮš`▓Ņ║»öĄųĄūŅąĪĄ─kéĆäØĘųĪŻ«ö┤ž╩Ū├▄╝»Ą─ĪóŪ“ĀŅ╗“łFĀŅĄ─Ż¼Ūę┤ž┼c┤žų«ķgģ^äe├„’@ĢrŻ¼Š█ŅÉą¦╣¹▌^║├ĪŻ
╚▒³c
ī”öĄō■ŅÉą═ę¬Ū¾▌^Ė▀Ż¼▀m║ŽöĄųĄą═öĄō■Ż╗
┐╔─▄╩šö┐ĄĮŠų▓┐ūŅąĪųĄŻ¼į┌┤¾ęÄ─ŻöĄō■╔Ž╩šö┐▌^┬²
KųĄ▒╚▌^ļyęį▀x╚ĪŻ╗
ī”│§ųĄĄ─┤žą─ųĄ├¶ĖąŻ¼ī”ė┌▓╗═¼Ą─│§╩╝ųĄŻ¼┐╔─▄Ģ■ī¦ų┬▓╗═¼Ą─Š█ŅÉĮY╣¹Ż╗
▓╗▀m║Žė┌░l¼FĘŪ═╣├µą╬ĀŅĄ─┤žŻ¼╗“š▀┤¾ąĪ▓Ņäe║▄┤¾Ą─┤žĪŻ
ī”ė┌”įļ┬Ģ”║═╣┬┴ó³cöĄō■├¶ĖąŻ¼╔┘┴┐Ą─įōŅÉöĄō■─▄ē“ī”ŲĮŠ∙ųĄ«a╔·śO┤¾ė░ĒæĪŻ
╦ŃĘ©▀xō±ģó┐╝
ų«Ū░ĘŁūg▀^ę╗ą®ć°═ŌĄ─╬─š┬Ż¼ėąę╗Ų¬╬─š┬ųąĮo│÷┴╦ę╗éĆ║åå╬Ą─╦ŃĘ©▀xō±╝╝Ū╔Ż║
╩ū«öŲõø_æ¬įō▀xō±Ą─Š═╩Ū▀ē▌ŗ╗žÜwŻ¼╚ń╣¹╦³Ą─ą¦╣¹▓╗į§├┤śėŻ¼─Ū├┤┐╔ęįīó╦³Ą─ĮY╣¹ū„×ķ╗∙£╩üĒģó┐╝Ż¼į┌╗∙ĄA╔Ž┼cŲõ╦¹╦ŃĘ©▀Mąą▒╚▌^Ż╗
╚╗║¾įćįćøQ▓▀śõŻ©ļSÖC╔Ł┴ųŻ®┐┤┐┤╩Ūʱ┐╔ęį┤¾Ę∙Č╚╠ß╔²─ŃĄ──Żą═ąį─▄ĪŻ╝┤▒ŃūŅ║¾─Ń▓óø]ėą░č╦³«öū÷×ķūŅĮK─Żą═Ż¼─Ńę▓┐╔ęį╩╣ė├ļSÖC╔Ł┴ųüĒęŲ│²įļ┬Ģūā┴┐Ż¼ū÷╠žš„▀xō±Ż╗
╚ń╣¹╠žš„Ą─öĄ┴┐║═ė^£yśė▒Š╠žäeČÓŻ¼─Ū├┤«ö┘Yį┤║═Ģrķg│õūŃĢrŻ©▀@éĆŪ░╠ß║▄ųžę¬Ż®Ż¼╩╣ė├SVM▓╗╩¦×ķę╗ĘN▀xō±ĪŻ
═©│ŻŪķørŽ┬Ż║ĪŠGBDT>=SVM>=RF>=Adaboost>=Other…Ī┐Ż¼¼Fį┌╔ŅČ╚īW┴Ģ║▄¤ßķTŻ¼║▄ČÓŅIė“Č╝ė├ĄĮŻ¼╦³╩Ūęį╔±ĮøŠWĮj×ķ╗∙ĄAĄ─Ż¼─┐Ū░╬ęūį╝║ę▓į┌īW┴ĢŻ¼ų╗╩Ū└Ēšōų¬ūR▓╗╩Ū║▄║±īŹŻ¼└ĒĮŌĄ─▓╗ē“╔ŅŻ¼▀@└’Š═▓╗ū÷ĮķĮB┴╦ĪŻ
╦ŃĘ©╣╠╚╗ųžę¬Ż¼Ą½║├Ą─öĄō■ģsę¬ā×ė┌║├Ą─╦ŃĘ©Ż¼įOėŗā×┴╝╠žš„╩Ū┤¾ėą±į굥─ĪŻ╝┘╚ń─Ńėąę╗éĆ│¼┤¾öĄō■╝»Ż¼─Ū├┤¤ošō─Ń╩╣ė├──ĘN╦ŃĘ©┐╔─▄ī”ĘųŅÉąį─▄Č╝ø]╠½┤¾ė░ĒæŻ©┤╦ĢrŠ═┐╔ęįĖ∙ō■╦┘Č╚║═ęūė├ąįüĒ▀MąąŠ±ō±Ż®ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║▒P³c│ŻęŖÖCŲ„īW┴Ģ╦ŃĘ©╝░▒╚▌^
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839319634.html






















