



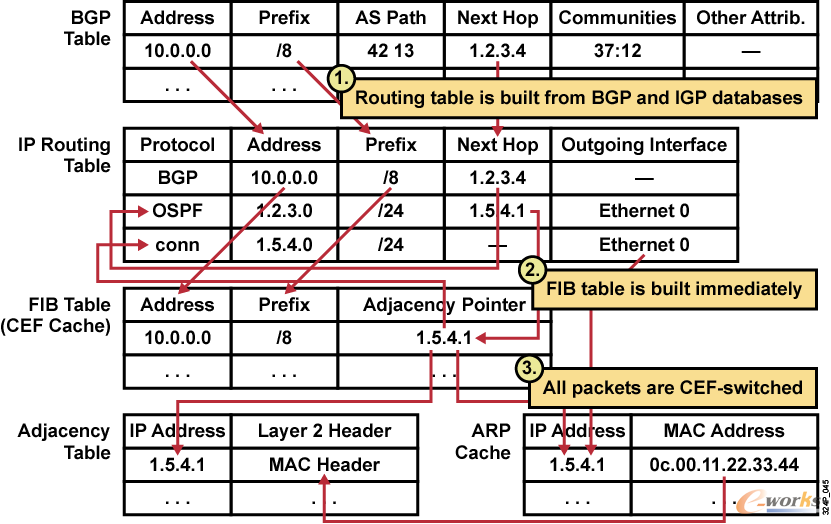
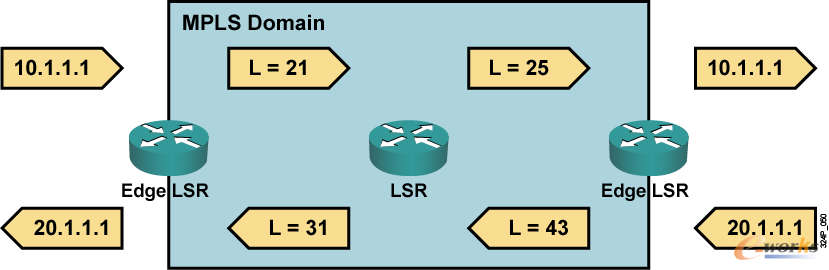
▒Š╬─╩ŪĪČ┬■šäįŲėŗ╦ŃŠWĮjĪĘŽĄ┴ąĄ─Ą┌ę╗Ų¬Ż¼▒ŠŽĄ┴ą╬─š┬├µŽ“Ą─ī”Ž¾×ķŠWĮj╣ż│╠Ĥ║═ī”ŠWĮj╝╝ągĖą┼d╚żĄ─═»ą¼ĪŻū„š▀Å─įŲėŗ╦ŃŠWĮj╝╝ągĮķĮBŻ¼įŲėŗ╦ŃŠWĮjĄ─╝▄śŗ─Ż╩Įęį╝░į┌Ų¾śIīŹ█`SDN/NFVĮŌøQĘĮ░ĖĄ─Įø“×┐éĮY╚²éĆŠSČ╚▀MąąĘųŽĒĪŻ
ę╗ĪóöĄō■ųąą─ŠWĮj╝╝ągĄ─ūāĖ’
öĄō■ųąą─Ą─ŠWĮj╝▄śŗ║═╝╝ągį┌įŲėŗ╦ŃšQ╔·║¾Ż¼┼cöĄō■ųąą─Ą─ėŗ╦Ń╝░┤µā”ę╗ŲČ╝į┌░l╔·ų°ūā╗»ĪŻŲ│§öĄō■ųąą─ŠWĮjĘų×ķā╚▓┐┼c═Ō▓┐Ż¼öĄō■ųąą─═Ō▓┐ŠWĮjųĖĄ─═©│Ż╩Ū╚²īėŠWĮjŻ¼ę▓Š═╩Ū╬ęéāūŅķ_╩╝╦∙šJų¬╦∙īW┴ĢĄ─ųT╚ńŻ║BGPĪóIS-ISĪóOSPFĄ╚╚²īė┬Ęė╔ģfūhĄ─╩╣ė├┼c╚²īėŠWĮj╝▄śŗĄ─įOėŗŻ¼į§├┤▓┼─▄ęÄäØ┬Ęė╔Ż¼į§├┤▓┼─▄╩╣Ą├┴„┴┐░┤šš┬Ęė╔Ą─ęÄäØ▀xųĘūŅāץ─┬ĘÅĮ╠ß╣®│÷╚źŻ¼╚ń╣¹šföĄō■ųąą─═Ō▓┐ŠWĮjĻPūóĖ³ČÓĄ─╩Ū╠ß╔²ė├æ¶Ą─¾w“ׯ¼─Ū├┤öĄō■ųąą─ā╚▓┐ŠWĮjŠ═╩Ū▀\ŠSąųĄ▄ĻPūóĄ─ųž³cų«ę╗Ż¼╠ß╔²ŠWĮjŽĄĮyĄ─ą¦┬╩ĪŻöĄō■ųąą─ā╚▓┐ŠWĮj╩ŪįŲėŗ╦Ńę²╚ļ║¾░lš╣ĘŪ│ŻčĖ╦┘Ą─ę╗éĆŅIė“Ż¼ę▓╩ŪĖ³ą┬Ą³┤·ūŅ┐ņĄ─ŅIė“ĪŻūŅķ_╩╝╬ęéāšJų¬Ą─öĄō■ųąą─ŠWĮjŠųŽ▐į┌═¼ę╗éĆ╬’└ĒöĄō■ųąą─ā╚▓┐Ż¼ļSų°įŲėŗ╦ŃĄ─░lš╣Ż¼öĄō■ųąą─ŠWĮjųØu▀M╗»×ķ═¼Ąžė“ČÓ╬’└ĒöĄō■ųąą─Ą─ŠWĮj▒╗│ķŽ¾│╔ę╗éĆ╠ōöM╗»Ą─ā╚▓┐ŠWĮjŻ¼ĄĮ¼Fį┌▓╗═¼Ąžė“─╦ų┴╚½Ū“ĘČć·Ą─╬’└ĒöĄō■ųąą─ŠWĮjČ╝┐╔ęį╗źŽÓČ■īė┤“═©Ą─įŲ╗»ŠWĮjĪŻ
ą┬Ą─ś╦£╩Īóą┬Ą─╝▄śŗĪóą┬Ą─«aŲĘīė│÷▓╗ĖFŻ¼┐╔čė└mĪó┐╔öUš╣ĪóĖ▀ņ`╗ŅĪóĘĆČ©Ą─Ė▀Č╚š¹║Ž╩ŪįĮüĒįĮČÓĄ─ųąą─╦∙ūĘŪ¾Ą─ę╗éĆą┬Ą─ŠWĮj¾wŽĄ╝▄śŗĪŻ┤¾Č■īėŠWĮj╩Ūį┌įŲėŗ╦Ńę²╚ļ▀MüĒęį║¾ę²╚ļĄ─ę╗éĆą┬Ą─Ė┼─ŅŻ¼į°Įø▒╗Č©┴x×ķŽ┬ę╗┤·öĄō■ųąą─ŠWĮjŻ¼įŁėąĄ─ŠWĮj╝▄śŗė╔ė┌ø]ėą┐╝æ]Č■īėŠWĮjÖMŽ“öUš╣┼cĮ╗ōQįŁ└ĒĄ─šQ╔·Ģr▓óø]ėą┐╝æ]ĄĮČ■īėŠWĮjĢ■ėąĮ±╠ņ╚ń┤╦ų«┤¾Ą─ąĶŪ¾Ż¼Č■īėŠWĮjĄ─└¦Š│ųØuĄ─¾w¼F│÷üĒŻ¼▓╗šō╩Ū╣½ėąįŲ▀Ć╩Ū╦ĮėąįŲ═¼śėČ╝├µī”┴╦═¼ę╗éĆå¢Ņ}Ż¼Š═╩Ūé„ĮyČ■īėŠWĮjå¢Ņ}Ż¼Ųõųą░³└©┴╦Č■īėŠWĮjĄ─ÅV▓ź’L▒®ĪóĄ═čė▀tĪóSTP╔·│╔śõģfūhĄ─Ž▐ųŲĪóČ■īėŠWĮj▀ģĮńųØuöU┤¾ĪóvlanĄ─öĄ┴┐å¢Ņ}Īóvlan tagĄ─▐DōQĪóČÓūŌæ¶ų«ķgĄ─╦ĮėąŠWĮjĄ─ņ`╗Ņąįå¢Ņ}Ų╚╩╣š¹éĆöĄō■ųąą─ŠWĮjį┌Į±╠ņĄ─įŲĢr┤·Ž┬ęčĮø░l╔·┴╦ĘŁ╠ņĖ▓ĄžĄ─ūā╗»ĪŻŽ┬├µ╩Ū╣Pš▀╗∙ė┌ūį╝║Ą─└ĒĮŌŻ¼ī”įŲėŗ╦ŃŠWĮjųąĄ─╝╝ągæ¬ė├▀MąąĄ─š¹└Ē║═┐éĮY
1.1 Overlay
ļSų°ŠWĮjūā╗»įĮüĒįĮ┤¾Ż¼ąĶŪ¾▓╗öÓĖ─ūāŻ¼é„ĮyĄ─ŠWĮjįOėŗ╦╝┬ĘĄ─ŠųŽ▐ąįųØu═╣’@Ż¼Č°ŪęöĄō■ųąą─ų«ķgĄ─═©ą┼▒Š┘|▀Ć╩Ūę└┘ć▀\ĀI╔╠╠ß╣®Ą─┘Yį┤Ż¼╚ń╣¹ėąÕX┐╔ęį▀xō±┬Ń╣Ō└wŻ¼Ą½╩ŪIT▒Š╔ĒŠ═╩Ū×ķ┴╦śIäšĖ³║├Ė³┐ņĄž░lš╣╦∙╠ß╣®Ą─ę╗ĘNĖ▀ą¦╣żŠ▀Ż¼─Ū├┤Ė³ČÓĄ─öĄō■ųąą─ŠWĮjŲõīŹ▀Ć╩Ūę└┘ć▀\ĀI╔╠Ą─ŠWĮjŻ¼į┌▀@éĆŠWĮjų«╔Ž▀Mąą»B╝ė╝ėęį└¹ė├Ż¼╗“š▀ūŌė├▀\ĀI╔╠╠ß╣®Ą─ŠWĮj┘Yį┤Ż¼ļSų°įĮüĒįĮČÓąĶꬻB╝ėĄ─▀ē▌ŗŠWĮjĄ─ąĶŪ¾▓╗öÓė┐│÷Ż¼Ž┬├µ╬ęéāŽ╚üĒ╗žŅÖę╗Ž┬ŠWĮj╩└Įń└’▓╗Ą├▓╗╠߯¼ę▓╩Ū├┐ę╗éĆŠWĮjÅ─śIš▀╦∙ąĶę¬┴╦ĮŌĄ─ę╗éĆŠWĮj╝╝ągų¬ūR-OverlayĪŻ
OverlayĄ─▒Š┘|└Ē─ŅŠ═╩Ū»B╝ėŻ¼į┌įŁėąĄ─é„ĮyŠWĮj╔Ž╠ōöM│÷╗“š▀»B╝ė│÷ę╗éĆ▀ē▌ŗŠWĮjüĒŻ¼é„ĮyŠWĮj▓╗ąĶę¬ū÷╚╬║╬Ė─ūāŻ¼Š═┐╔ęįīóą┬Ą─ŠWĮj═©ą┼ģfūhį┌Ųõ╔Žš╣ķ_Ż¼Ųõų„ę¬╝╝ąg┬ĘŠĆŻ¼Š═╩Ūī”öĄō■ųąą─ŠWĮjĄ─Į©įO─Ż╩Į▀Mąą┴╦═Ļ╚½Ą─ŅŹĖ▓Ż¼įŁėąĄ─Įė╚ļīėĪóģRŠ█īėĪó║╦ą─īėĄ─╚²īėįOėŗ╝▄śŗųØuč▌ūā×ķČ■īėģRŠ█┼c╚²īėŠWĻPĄ─╚~╝╣╝▄śŗĪŻ

łD1 Overlay
Overlay¤oĀŅæBŠWĮj╝╝ągę▓╩Ū╬┤üĒöĄō■ųąą─ŠWĮj░lš╣Ą─ę╗éĆųžę¬ĮM│╔▓┐ĘųĪŻŲõų„ę¬ęŌ┴xŠ═╩Ū»B╝ėŻ¼═©▀^ŲõČ©┴xĄ─▀ē▌ŗŠWĮjŻ¼īŹ¼FśIäš╦∙ąĶꬥ─▀ē▌ŗŠWĮjŻ¼Å─Č°ĮŌøQöĄō■ųąą─įŲ╗»Ą─ŠWĮjå¢Ņ}Ż¼śO┤¾Ąž╣Ø╩Ī┴╦é„ĮyĄ─IT═Č┘Y│╔▒ŠŻ¼Overlayę▓╩Ūę╗ĘNīó(śI䚥─) Č■īėŠWĮjśŗ╝▄į┌(é„ĮyŠWĮjĄ─)╚²īė/╦─īėł¾╬─ųą▀Mąąé„▀fĄ─ŠWĮj╝╝ągĪŻ▀@śėĄ─╝╝ągīŹļH╔ŽŠ═╩Ūę╗ĘN╦ĒĄ└ĘŌčb╝╝ągĪŻūŅĻPµIĄ─śIäš─Żą═Š═╩Ūę¬īŹ¼Fę╗ĘN¤oĀŅæBĄ─ŠWĮj─Żą═Ż¼╝┤╩╣┐ńįĮ▀\ĀI╔╠┘Yį┤Ż¼ę▓┐╔ęįīŹ¼FČÓéĆöĄō■ųąą─╗źįLŻ¼╔§ų┴╠ōöMÖC▀węŲČ╝┐╔ęį¤oĖąų¬Ąžį┌▀@Åł▀ē▌ŗŠWĮj╔Ž▀\ąąŻ¼═¼Ģrī”╔Žīėæ¬ė├╠ß╣®¤oĖąų¬Ą─ŠWĮjĘ■äšĪŻ
1.2 MPLS VPN
ŲõīŹį┌ŠWĮj╝╝ąg└’ęčĮøėą┴╦▓╗╔┘Ą─ĘŌčb╝╝ągŻ¼MPLS VPNŠ═╩ŪŲõĄõą═┤·▒Ēų«ę╗Ż¼į┌90─Ļ┤·│§Ų┌Ż¼«öĢr┬Ęė╔Ų„ė╔ė┌▐D░lą¦┬╩Ą═Ž┬Ż¼¤oĘ©▒ŻūC═Ļš¹Ą─QOSįOėŗĄ╚įŁę“Ż¼Ųõ░lš╣▀h▀h┬õ║¾ė┌ŠWĮjŻ¼«öĢrĄ─┬Ęė╔▓ķšę╦ŃĘ©▒žĒÜę└┘ć▄ø╝■▓ķšęŻ¼┬Ęė╔Ų„ąį─▄ę▓Ģ■ę“┤╦╩▄ĄĮė░ĒæŻ¼ŠWĮj╠Äė┌▓╗ųžęĢĮY╣¹Ą─▒M┴”Č°×ķĄ─└¦Š│Ż¼ATMŠWĮjļS║¾šQ╔·Ż¼═¼ĢrIPŠWĮjųąĄ─MPLSę▓šQ╔·│÷üĒĪŻ
MPLSŻ©multi-protocollabelswitchŻ®╩ŪInternet║╦ą─ČÓīėĮ╗ōQėŗ╦ŃĄ─ūŅą┬░lš╣ĪŻMPLSīó▐D░l▓┐ĘųĄ─ś╦ėøĮ╗ōQ║═┐žųŲ▓┐ĘųĄ─IP┬Ęė╔ĮM║Žį┌ę╗ŲŻ¼╝ė┐ņ┴╦▐D░l╦┘Č╚ĪŻČ°ŪęŻ¼MPLS┐╔ęį▀\ąąį┌╚╬║╬µ£Įėīė╝╝ągų«╔ŽŻ¼Å─Č°║å╗»┴╦Ž“╗∙ė┌SONET/WDM║═IP/WDMĮYśŗĄ─Ž┬ę╗┤·╣ŌInternetĄ─▐D╗»ĪŻMPLS┼cµ£┬Ęīėģ^Ęųķ_üĒŻ¼Č©┴x×ķ2.5īėģfūhŻ¼┐╔ęįį┌ŲõŠWĮjĮYśŗ╔Ž│ą▌dŲõ╦¹ł¾╬─Ż¼┼c1997─Ļš²╩Į├³├¹×ķMPLSĪŻ
═©│ŻŻ¼MPLS░³Ņ^ėą32BitŻ¼ŲõųąėąŻ║
- 20Bitė├ū„ś╦║ׯ©LabelŻ®ś╦║×ų╗ėą▒ŠĄžėąęŌ┴x▓╗Ģ■╚▒╔┘
- 3éĆBitĄ─EXPŻ¼ ģfūhųąø]ėą├„┤_Ż¼═©│Żė├ū„COS
- 1éĆBitĄ─SŻ¼ė├ė┌ś╦ūR╩Ūʱ╩ŪŚŻĄūŻ¼▒Ē├„MPLSĄ─ś╦║×┐╔ęįŪČ╠ū
- 8éĆBitĄ─TTL

łD2 Mpls░³Ņ^ĮYśŗ
ś╦║ׯ©LableŻ®Ż║╩Ūę╗éĆ▒╚▌^Č╠Ą─Ż¼Č©ķLĄ─Ż¼═©│Żų╗Š▀ėąŠų▓┐ęŌ┴xĄ─ś╦ūRŻ¼▀@ą®ś╦║×═©│Ż╬╗ė┌öĄō■µ£┬ĘīėĄ─öĄō■µ£┬ĘīėĘŌčbŅ^║═╚²īėöĄō■░³ų«ķgŻ¼ś╦║×═©▀^ĮēČ©▀^│╠═¼FECŽÓė│╔õĪŻ
FECŻ©Forwarding Equivalence ClassŻ¼▐D░lĄ╚ārŅÉŻ®Ż║╩Ūį┌▐D░l▀^│╠ųąęįĄ╚ārĄ─ĘĮ╩Į╠Ä└ĒĄ─ę╗ĮMöĄō■ĘųĮMŻ¼ MPLS▒ŠüĒęÄČ©Ż║┐╔ęį═©▀^ĄžųĘĪó╦ĒĄ└ĪóCOSĄ╚üĒś╦ūRäōĮ©FECŻ¼¼Fį┌┐┤ĄĮĄ─MPLSųąų╗╩Ūę╗Śl┬Ęė╔ī”æ¬ę╗éĆFEC:═©│Żį┌ę╗┼_įOéõ╔ŽŻ¼ī”ę╗éĆFECĘų┼õŽÓ═¼Ą─ś╦║×ĪŻŻ©ę╗ĮM▓╗═¼öĄō■Å─ŽÓ═¼Ą─Įė┐┌▀MüĒŽÓ═¼Ą─Įė┐┌│÷╚źŻ®
LSPŻ©ś╦║×Į╗ōQ═©Ą└Ż®Ż║ę╗éĆFECĄ─öĄō■┴„Ż¼į┌▓╗═¼Ą─╣سc▒╗┘xėĶ┤_Č©Ą─ś╦║ׯ¼öĄō■▐D░l░┤šš▀@ą®ś╦║×▀MąąĪŻöĄō■┴„╦∙ū▀Ą─┬ĘÅĮŠ═╩ŪLSPĪŻ
LSRŻ©Label Switching RouterŻ®Ż║ LSR╩ŪMPLSĄ─ŠWĮjĄ─║╦ą─Į╗ōQÖCŻ¼╦³╠ß╣®ś╦║×Į╗ōQ║═ś╦║×Ęų░l╣”─▄ĪŻ
LERŻ©Label Switching Edge RouterŻ®Ż║į┌MPLSĄ─ŠWĮj▀ģŠēŻ¼▀M╚ļĄĮMPLSŠWĮjĄ─┴„┴┐ė╔LERĘų×ķ▓╗═¼Ą─FECŻ¼▓ó×ķ▀@ą®FECšłŪ¾ŽÓæ¬Ą─ś╦║×ĪŻ╦³╠ß╣®┴„┴┐ĘųŅÉ║═ś╦║ץ─ė│╔õĪóś╦║ץ─ęŲ│²╣”─▄ĪŻŻ©ūāIP▐D░l×ķś╦║×▐D░lŻ®
MPLS VPNīŻśIągšZŻ║
PE┬Ęė╔Ų„Ż║ėųĘQū„╠ß╣®╔╠▀ģŠē┬Ęė╔Ų„ĪŻįō┬Ęė╔Ų„žōž¤ė├æ¶Č╦ŠWĮjĄĮ╠ß╣®╔╠ŠWĮjĄ─Įė╚ļĪŻ
P┬Ęė╔Ų„Ż║ėųĘQ╠ß╣®╔╠┬Ęė╔Ų„ĪŻP┬Ęė╔Ų„╩Ū╠ß╣®╔╠ŠWĮjųą▓╗▀BĮė╚╬║╬CEįOéõĄ─┬Ęė╔Ų„ĪŻ
CE┬Ęė╔Ų„Ż║ėųĘQė├æ¶▀ģŠēįOéõĪŻCE┬Ęė╔Ų„═©▀^▀BĮėų┴ę╗éĆ╗“ČÓéĆ╠ß╣®╔╠▀ģŠēŻ©PEŻ®┬Ęė╔Ų„Ą─öĄō■µ£┬Ę×ķė├æ¶╠ß╣®ī”Ę■äš╠ß╣®╔╠Ą─Įė╚ļĪŻ
**VPN-IPV4ĄžųĘŻ║**VPNė├æ¶═©│Ż╩╣ė├╦ĮėąĄžųĘüĒęÄäØūį╝║Ą─ŠWĮjĪŻ«ö▓╗═¼Ą─VPNė├æ¶╩╣ė├ŽÓ═¼Ą─╦ĮėąĄžųĘęÄäØĢrŠ═Ģ■│÷¼F┬Ęė╔▓ķšęå¢Ņ}ĪŻ
┬Ęė╔ģ^ĘųĘ¹RDŻ║┬Ęė╔ģ^ĘųĘ¹RD╝┤VPN-Ipv4ĄžųĘĄ─Ū░8ūų╣ØŻ¼ė├üĒģ^Ęų▓╗═¼VPNųąĄ─ŽÓ═¼╦ĮŠWĄžųĘĪŻ
┬Ęė╔─┐ś╦RTŻ║RT×ķMP-BGPųąĄ─öUš╣╣▓═¼¾wī┘ąįų«ę╗ĪŻ┬Ęė╔─┐ś╦ī┘ąįČ©┴x┴╦PE┬Ęė╔Ų„░l▓╝┬Ęė╔Ą─ę╗ĮMšŠ³cŻ©VRFŻ®Ą─╝»║ŽĪŻPE┬Ęė╔Ų„╩╣ė├▀@ę╗ī┘ąįüĒī”▌ö╚ļ▀hČ╦┬Ęė╔ĄĮŲõVRF▀Mąą╝s╩°ĪŻ
VPN┬Ęė╔▐D░l▒ĒŻ©VRFŻ®Ż║├┐éĆPE┬Ęė╔Ų„×ķŲõų▒▀BĄ─šŠ³cŠS│ųę╗éĆVRFĪŻ├┐éĆė├涵£Įė▒╗ė│╔õų┴ę╗éĆ╠žČ©Ą─VRFĪŻ├┐éĆVRF┼cPE┬Ęė╔Ų„Ą─ę╗éĆČ╦┐┌ŽÓĻP┬ōĪŻ
łD3 öĄō■ĮYśŗ
LDPĘĮ╩Įé„▀fŻ║
łD4 Mpls domin LDPś╦║×Į╗ōQ
LSR┐žųŲŲĮ├µŻ║

łD5 ┐žųŲŲĮ├µ
Edge LSR┐žųŲŲĮ├µŻ║

łD6 ▀ģŠēįOéõ┐žųŲŲĮ├µ
1.3 MPLS VPN-VPLS
╠ōöMīŻė├Šųė“ŠWśIäšVPLSŻ©Virtual Private LAN ServiceŻ®╩Ū╣½ė├ŠWĮjųą╠ß╣®Ą─ę╗ĘN³cĄĮČÓ³cĄ─L2VPNŻ©Layer 2 virtual private networkŻ®śI䚯¼╩╣Ąžė“╔ŽĖ¶ļxĄ─ė├涚Š³c─▄═©▀^MAN/WANŻ©Metropolitan Area Network/Wide Area NetworkŻ®ŽÓ▀BŻ¼▓óŪę╩╣Ė„éĆšŠ³cķgĄ─▀BĮėą¦╣¹Ž±į┌ę╗éĆLANŻ©Local Area NetworkŻ®ųąę╗śėĪŻ╦³╩Ūę╗ĘN╗∙ė┌MPLSŻ©MultiProtocol Label SwitchingŻ®ŠWĮjĄ─Č■īėVPN╝╝ągŻ¼ę▓▒╗ĘQ×ķ═Ė├„Šųė“ŠWśIäšTLSŻ©Transparent LAN ServiceŻ®ĪŻĄõą═Ą─VPLSĮMŠW╚ńŽ┬Ż║╠Äė┌▓╗═¼╬’└Ē╬╗ų├Ą─ė├æ¶═©▀^Įė╚ļ▓╗═¼Ą─PEįOéõŻ¼īŹ¼Fė├æ¶ų«ķgĄ─╗źŽÓ═©ą┼ĪŻÅ─ė├æ¶Ą─ĮŪČ╚üĒ┐┤Ż¼š¹éĆVPLSŠWĮjŠ═╩Ūę╗éĆČ■īėĮ╗ōQŠWŻ¼ė├æ¶ų«ķgŠ═Ž±ų▒Įė═©▀^LAN╗ź▀Bį┌ę╗Ųę╗śėĪŻ
─┐Ū░Ż¼ļSų°Ų¾śIĄ─Ęų▓╝ĘČć·╚šęµöU┤¾ęį╝░╣½╦ŠåT╣żĄ─ęŲäėąį▓╗öÓį÷╝ėŻ¼Ų¾śIųąVoIPĪó╝┤ĢrŽ¹ŽóĪóŠWĮjĢ■ūhĄ─æ¬ė├įĮüĒįĮÅVĘ║Ż¼ę“┤╦▀@ą®æ¬ė├ī”Č╦ĄĮČ╦Ą─öĄō■═©ą┼╝╝ągėą┴╦Ė³Ė▀Ą─ę¬Ū¾ĪŻČ╦ĄĮČ╦öĄō■═©ą┼╣”─▄Ą─īŹ¼Fę└┘ćė┌ę╗éĆ─▄ē“ų¦│ųČÓ³cśI䚥─ŠWĮjĪŻ
é„ĮyĄ─ATMŻ©Asynchronous Transfer ModeŻ®ĪóFRŻ©Frame RelayŻ®╝╝ągų╗─▄īŹ¼FČ■īė³cĄĮ³c╗ź▀BŻ¼Č°ŪęŠ▀ėąŠWĮjĮ©įO│╔▒ŠĖ▀Īó╦┘┬╩▌^┬²Īó▓┐╩Å═ļsĄ╚╚▒³cĪŻļSų°IP╝╝ągĄ─░lš╣Ż¼ę╗ĘNį┌IPŻ©Internet ProtocolŻ®ŠWĮj╔Ž╠ß╣®VPNŻ©Virtual Private NetworkŻ®Ę■äšĪó┐╔ĘĮ▒ŃįOČ©╦┘┬╩Īó┼õų├║åå╬Ą─╝╝ągļSų««a╔·Ż¼▀@ĘN╝╝ąg╝┤MPLS VPN╝╝ągĪŻ╗∙ė┌MPLSĄ─VPN╝╝ągėąā╔ĘNŻ¼Ęųäe╩ŪMPLS L2VPN║═MPLS L3VPNŻ║
é„ĮyVLLŻ©Virtual Leased LineŻ®ĘĮ╩ĮĄ─MPLS L2VPN╩Ūį┌╣½ŠWųą╠ß╣®ę╗ĘN³cĄĮ³cĄ─L2VPNśI䚯¼▓╗─▄ų▒Įėį┌Ę■äš╠ß╣®š▀╠Ä▀MąąČÓ³cķgĄ─Į╗ōQĪŻ
MPLS L3VPNŠWĮjļm┐╔╠ß╣®ČÓ³cśI䚯¼Ą½PEįOéõĢ■Ėąų¬╦ĮŠW┬Ęė╔Ż¼įņ│╔įOéõĄ─┬Ęė╔- ą┼Žó▀^ė┌²ŗ┤¾Ż¼ī”PEįOéõĄ─┬Ęė╔┐žųŲąį─▄ę¬Ū¾▌^Ė▀ĪŻ
ßśī”ęį╔Žå¢Ņ}Ż¼VPLSį┌é„ĮyMPLS L2VPNĘĮ░ĖĄ─╗∙ĄA╔Ž░lš╣Č°│╔Ż¼╩Ūę╗ĘN╗∙ė┌ęį╠½ŠW║═MPLSś╦║×Į╗ōQĄ─╝╝ągŻ║
ė╔ė┌ęį╠½ŠW▒Š╔ĒŠ═Š▀ėąų¦│ųČÓ³c═©ą┼╠ž³cŻ¼╩╣Ą├VPLS╝╝ąg┐╔ęįīŹ¼FČÓ³c═©ą┼Ą─ę¬Ū¾ĪŻ
═¼ĢrVPLS╩Ūę╗ĘNČ■īėś╦║×Į╗ōQ╝╝ągŻ¼Å─ė├æ¶é╚üĒ┐┤Ż¼š¹éĆMPLS IP╣ŪĖ╔ŠW╩Ūę╗éĆČ■īėĮ╗ōQįOéõŻ¼PEįOéõ▓╗ąĶę¬Ėąų¬╦ĮŠW┬Ęė╔ĪŻ
ę“┤╦Ż¼VPLS╝╝ąg×ķŲ¾śI╠ß╣®┴╦ę╗ĘNĖ³╝ė═ĻéõĄ─ČÓ³cśIäšĮŌøQĘĮ░ĖĪŻ╦³ĮY║Ž┴╦ęį╠½ŠW╝╝ąg║═MPLS╝╝ągĄ─ā×ä▌Ż¼╩Ūī”é„ĮyLAN╚½▓┐╣”─▄Ą─Ę┬šµŻ¼Ųõų„ę¬─┐Ą─╩Ū═©▀^▀\ĀI╔╠╠ß╣®Ą─IP/MPLSŠWĮj▀BĮėĄžė“╔ŽĖ¶ļxĄ─ČÓéĆė╔ęį╠½ŠWśŗ│╔Ą─LANŻ¼╩╣╦³éāŽ±ę╗éĆLAN─Ūśė╣żū„ĪŻ
VPLS pwūįäė▓┐╩

łDŲ¼7 VPLS pwūįäė▓┐╩
BGP AD VPLS PWĄ─ūįäė▓┐╩▀^│╠įö╝Ü├Ķ╩÷╚ńŽ┬Ż║
ā╔┼_PE╔Žī┘ė┌ŽÓ═¼VPLSė“Ą─VSIĖ∙ō■ĄĮ▀hČ╦Ż©BGP ADųąĄ─Next HopŻ®Ą─LDPĢ■įÆĀŅæBŽÓ╗ź░lŲLDP MappingŻ©FEC 129Ż®ą┼┴ŅŻ¼ŲõųąöyĦAGIĪóSAIIĪóTAII║═ś╦║ץ╚ą┼ŽóĪŻ
BGP AD VPLSį┌│╔åT░l¼F║¾Ż¼▓╔ė├ų„äėė|░lLDPģfūhäōĮ©LDPĢ■įÆĄ─ĘĮ╩ĮŻ¼╩╣LDP─▄ē“░┤ššśI䚥─ąĶŪ¾üĒĮ©┴óĢ■įÆĪŻ«öVPLSśIäš│ĘõNŻ¼▓╗į┘╩╣ė├įōLDPĢ■įÆĢrŻ¼į┘ų„äėė|░lLDPģfūh▓│²LDPĢ■įÆĪŻ▀@śė╝╚─▄£p╔┘LDPĢ■įÆ═žōõĄ─ŠSūo╣żū„┴┐Ż¼ėų─▄╠ßĖ▀ŽĄĮy┘Yį┤Ą─└¹ė├┬╩Ż¼£p╔┘ŠWĮj┘Yį┤Ą─ķ_õNŻ¼╠ß╔²ŠWĮjąį─▄ĪŻ
PEĮė╩šĄĮ▀hČ╦Ą─LDP MappingŻ©FEC 129Ż®ą┼┴Ņ║¾Ż¼ĮŌ╬÷½@╚ĪVPLS-IDĪóPW TypeĪóMTUĪóTAIIĄ╚ą┼ŽóŻ¼īó▀@ą®ą┼Žó┼c▒ŠĄžVSI▒╚▌^Ż¼╚ń╣¹ģf╔╠═©▀^Ż¼▓óŪęØMūŃĮ©┴óPWĄ─Śl╝■ĢrŻ¼äōĮ©ĄĮī”Č╦Ą─PWĪŻ
ę╗éĆVPLS▐D░līŹ└²Ż║

łD8 VPLS▐D░l
VPLSŽ▐ųŲŻ║VPLSį┌▀^╚źmpls┤¾ęÄ─Ż░lš╣▀^│╠«öųąŻ¼ļm╚╗ĮŌøQ┴╦┐ńšŠ³cķgĄ─2īė═©ėŹå¢Ņ}Ż¼Ą½╩Ū═¼śėī”ė┌▀\ŠS╚╦åTüĒšfŠ═╩Ūę╗ł÷ž¼ē¶Ż¼╩ūŽ╚╬ęéāąĶę¬ĮMĮ©ūį╝║Ą─ę╗š¹ÅłMPLS VPNĄ─ŠWĮjŻ¼▀@└’├µŠ═╔µ╝░ĄĮ┴╦┘Yį┤Ą─┘Å┘IŻ¼╗“š▀ų▒ĮėūŌ┘UĄ┌╚²ĘĮĄ─MPLS VPNŠWĮjŻ¼Ą½╩ŪūŌė├ŠWĮj║¾Ż¼╬ęéā▀\ąąVPLSŻ¼Š═ąĶę¬▀\ŠS╚╦åT├┐╠ņČ╝╚źŠSūo▓╗═¼Ą─pwŻ¼▓óŪęę¬į┌ŠSūoę╗Åł┬Ęė╔▒ĒĄ─═¼Ģr▀ĆąĶꬊSūoę╗ÅłFwording TableŻ©ś╦║×▐D░lą┼ŽóÄņŻ®Ż¼│²┤╦ų«═ŌŻ¼▀ĆąĶę¬▀\ŠS╚╦åTŠSūo▓╗═¼Ą─Č■īėŠWĮjĪŻVPLSļmšfę╗ĢrĮŌøQ┴╦Č■īė┐ńšŠ³c═©ą┼Ą─å¢Ņ}Ż¼Ą½╩Ū═¼śė╦³Ą─╚▒Ž▌ę▓╩Ū’@Č°ęūęŖĄ─Ż¼╩ūŽ╚VPLS╗∙ė┌vlanĄ─ŪķørŽ┬Ż¼ÅV▓źŻ¼arpŻ¼╔·│╔śõģfūhę└╚╗┤µį┌Ż╗├┐éĆvlanĄ─▐D░lę└╚╗╩Ūå╬▀ģū▀Ž“┬ĘÅĮŻ¼╚▀ėÓµ£┬Ę▓ó▓╗─▄╝░Ģr└¹ė├Ż¼įņ│╔µ£┬ĘĄ─└╦┘MŻ╗▀^ČÓĄ─ŠWĮj┘Yį┤īŹļH╩Ūę└┘ć▀\ĀI╔╠Ą─ŠWĮj┘Yį┤Ż¼▀\ĀI╔╠Ą─ŠWĮj┘Yį┤╬ęŽļ├┐ę╗éĆöĄō■ųąą─Č╝╔Ņėą¾wĢ■Ż╗═¼ĢrŻ¼▀\ŠS╚╦åT▀Ćę¬├µī”MPLS VPN «öųą┼õų├Ą─Å═ļsąįŻ¼ī”ė┌š¹éĆ▀\ŠSłFĻĀį┌ŠSūoöĄō■ųąą─ŠWĮjĄ─═¼Ģrėųį÷╝ė┴╦ę╗éĆ▓╗ąĪĄ─╠¶æĪŻ
1.4 LISP
LISPŻ©Locator/Identifier Separarion Protocal——╬╗ų├/╔ĒĘ▌ĘųļxģfūhŻ®╩Ū×ķ┴╦Ė─ūāė╔ė┌įŲėŗ╦ŃĄĮüĒįņ│╔öĄō■ųąą─Ą─┘Yį┤Ąž└Ē╬╗ų├Ą─▓╗┤_Č©ąįĄ─═©ą┼å¢Ņ}Ą─ę╗ĘNćLįć╩ųČ╬Ż¼Å─IPīėģfūh▀MąąĮķ╚ļŻ¼ĮŌøQöĄō■ŠWĮjį┌įŲėŗ╦Ń┤¾ęÄ─ŻĄĮüĒĢrĄ─ŠWĮjŲ┐ŅiĄ─ę╗ĘNćLįćąįŠWĮj╝╝ągĪŻ╩Ūę╗ĘN╠Ē╝ė┴╦┐žųŲŲĮ├µĄ─IPsec VPNĘ■䚯¼▓óŪę┐╔ęį▌p╦╔æ¬ī”é„Įyvpn³cĄĮ³c┼c³cĄĮČÓ³cĄ─śIäšąĶŪ¾─Żą═ĪŻ
LISPį┌é„ĮyIPŠWĮjīėųą╠Ē╝ė┴╦ā╔éĆųžę¬Ą─ą┬Ą─ŠWĮjį¬╦žŻ║
ITRŻ©Ingress Tunnel Router—-╚ļŽ“╦ĒĄ└┬Ęė╔Ų„Ż®
ETRŻ©Egress Tunnel Router—-│÷Ž“╦ĒĄ└┬Ęė╔Ų„Ż®
Ųõ▐D░lĄ─╗∙▒ŠįŁ└Ē×ķŻ║▓┐╩į┌LISPŠWĮj▀ģĮńĄ─ITR┬Ęė╔Ų„Įė╩▄ĘŪLISPšŠ³c░lüĒĄ─öĄō■░³Ż¼▓ó╠Ē╝ė╔Žą┬Ą─ROLC░³Ņ^ū„×ķį┤░³Ņ^Ż¼ę└ō■LISPųąROLCĄ─▐D░lęÄät▀Mąą┬Ęė╔▓ķ▒Ē▐D░lŻ¼ĄĮ▀_╬╗ė┌LISPöĄō■┬ĘÅĮĄ─ūŅ║¾ę╗šŠĄ─ETR┬Ęė╔Ų„Ż¼▀ĆįŁįŁ╩╝Ųš═©IPöĄō■░³Ż¼▓ó▐D░lĮoé„ĮyĘŪLISPšŠ³c▀MąąĮŌĘŌčbįŁ╩╝öĄō■░³ĪŻ
ŽÓ▌^ė┌é„ĮyĄ─IPöĄō■░³Ż¼LISPūŅ┤¾Ą─ūā╗»ų«ę╗Š═╩ŪīóIPöĄō■░³Ęų×ķ┴╦═Ōīė┼cā╚īėā╔īėöĄō■░³Ņ^Ż¼═Ōīė×ķLISP═©ą┼Ą─RLOCsŻ¼═©│Ż×ķę╗éĆETR╬╗ų├Ż¼ā╚┤µöyĦĄ─EIDą┼Žó╩Ūę╗éĆĘŪLISP│ŻęÄšŠ³cą┼ŽóĪŻ

łD9 LISP░³Ņ^ą┼Žó
1.5 Fabric-Path
LISP▀Ćī┘ė┌Ąõą═Ą─öĄō■ųąą─═Ō▓┐ŠWĮjįOėŗ╝╝ągĘĮ░ĖŻ¼Č°öĄō■ųąą─ā╚▓┐ŠWĮjŲĮ┼_▓┼╩ŪīóįŲėŗ╦ŃĖ„éĆŽĄĮyų«ķg┤«┬ōĄ─ĻPµIŠWĮj╝╝ągŲĮ┼_ĪŻ
ļSų°╠ōöM╗»╝╝ągĄ─│÷¼FŻ¼öĄō■ųąą─ŠWĮjųØu░l╔·Ė─ūāŻ¼¼Fį┌Ą─öĄō■ųąą─ąĶꬓę╗éĆ┤¾Č■īė”ŠWĮjØMūŃČÓūŌæ¶ā╚ŠW┼c╠ōÖC▀węŲŻ¼═¼Ģrų╗ėąņ`╗ŅĄ─Č■īėŠWĮj▓┼─▄īŹ¼F╝┤▓Õ╝┤ė├Ą─╠ž╩ŌģfūhĄ─æ¬ė├ąĶŪ¾ĪŻĄ½╩Ūé„ĮyŠWĮjųą×ķ┴╦▒▄├ŌČ■īėŁh┬Ę╦∙│÷¼FĄ─Č■īė╠žąįSTPŻ©Spaning TreeŻ®ģfūh╦∙śŗĮ©Ą─ŠWĮj┼c¼Fį┌öĄō■ųąą─╦∙ąĶꬥ─ŠWĮj─Żą═┤_╩Ū▒│Ą└Č°±YŻ¼╝┤╩╣╩Ū┐ņ╦┘╔·│╔śõģfūhĄ─30├ļĮMŠW╦┘Č╚ę▓▓╗─▄ØMūŃ¼Fį┌öĄō■ųąą─ŠWĮj╦∙ąĶŻ¼═¼ĢrSTPģfūhĦüĒūŅ┤¾Ą─å¢Ņ}Š═╩ŪĦīÆĄ─└╦┘M┼cĖ∙ś“śīæī¦ų┬ŠWĮjųąöÓĄ─å¢Ņ}ĪŻ
╠ž³cŻ║
ą┬į÷ę╗éĆČ■īėļŅ^Ż©įŁĄžųĘĪó─┐Ą─ĄžųĘĪóTTLŻ®Ż║
į┤ĄžųĘ║═─┐Ą─ĄžųĘŻ║ą┬Č©┴xSwitch IDĄ─╚½ą┬├³├¹┐šķgŻ¼ūŅ×ķ╬©ę╗Ą─ś╦ūRŻ¼▀Mąą┬Ęė╔īżųĘĪŻ
į÷╝ėę╗╠ū║å╗»Ą─IS-IS┬Ęė╔ģfūhŻ║
ę²╚ļIS-IS┬Ęė╔ģfūhū„×ķ┐žųŲīė├µĄ─ę└ō■Ż¼µ£┬ĘĀŅæB┬Ęė╔ģfūhŻ¼ŽÓ▒╚MACĄžųĘīżųĘ▀@śėĄ─ŠÓļx╩Ė┴┐┬Ęė╔ģfūhüĒšfŻ¼µ£┬ĘĀŅæB┬Ęė╔ģfūh┐╔ęįį┌š¹ŠW«öųąĖ³ą┬ę╗š¹Åł┬Ęė╔═žōõĮYśŗŻ¼ą┬į÷╝ėĄ─╣سc┼cļSĢrĖ³ą┬š¹éƵ£┬ĘĀŅæBöĄō■ÄņŻ¼Å─Č°▀_ĄĮÅ─ūŅČ╠Ą─ŠÓļx╔Ž╚ź▐D░löĄō■░³ĪŻ
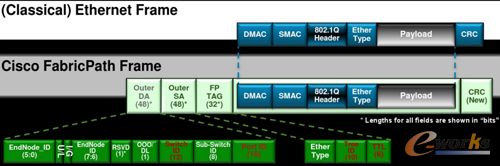
Cisco FabricPath╝╝ąg╩Ūę╗ĘNČ■īėĮ╗ōQ╝╝ąg┼c╚²īė┬Ęė╔╝╝ągĄ─╚┌║Ž¾wŻ¼╦³╝╚ōĒėąČ■īėĮ╗ōQ╝╝ągĄ─ęūė┌┼õų├Ż¼╝┤▓Õ╝┤ė├║═┐ņ╦┘▓┐╩Ą─ā×ä▌ĪŻ▀ĆōĒėą┬Ęė╔╝╝ąg╦∙¬ÜėąĄ─ČÓµ£┬Ęžō▌dŠ∙║ŌŻ¼┐ņ╦┘╩šö┐║═Ė▀öUš╣ąįĄ─╠ž³cĪŻ╩Ūę╗ĘNšµš²ęŌ┴x╔ŽČ■╚²īė╝╝ąg╚┌║ŽĄ─«a╬’ĪŻš¹éĆFabric-PathĮ╗ōQŠWĮjĄ─ĮM│╔┐╔ęį┐┤ū÷╩Ūę╗éĆ┤¾Ą─Į╗ōQÖCę▓Š═╩Ūę╗éĆš¹¾wĄ─Č■īėĮ╗ōQė“Ż¼Ą½╩ŪŲõ┐žųŲŲĮ├µ▓╔ė├┴╦╚²īė┬Ęė╔ģfūhIS-ISŻ¼├┐┼_Fabric-PathĮ╗ōQÖC═©▀^Switch IDüĒ▀MąąĮMŠWŻ¼Switch IDŠ═Ž±ęį╠½ŠWųąĄ─IPĄžųĘę╗śėŻ¼╩Ū╦∙ėąFabricPathĮ╗ōQÖCĄ─╬©ę╗ś╦╩ŠŻ¼īŹ¼F┴╦Č■īėŠWĮjį┌µ£┬ĘĀŅæB┬Ęė╔ģfūh╔ŽĄ─▐D░lŻ¼├Ō╚ź┴╦įŁėąČ■īėŠWĮjįOėŗĄ─śõĀŅĘĮ╩ĮĄ─▓╗▒ŃĮ▌ąįŻ¼═¼ĢrīŹ¼F┴╦Č■īėFULL-MESH╝▄śŗĪŻ
łD10 öĄō■░³ĮYśŗ

łD11 ĮMŠW═žōõ
1.6 Trill
é„ĮyČ■īėŠWĮjū„×ķę╗ĘNį┤ė┌Šųė“ŠW╗ź┬ō╝╝ągŻ¼ę╗░Ń▓╔ė├xSTPģfūhĘ└ų╣ÅV▓ź’L▒®Ż¼Š▀ėą║åå╬ęūė┌ŠSūoĄ╚╠ž³cŻ¼į┌öĄō■ųąą─Ą├ĄĮ┴╦ÅVĘ║æ¬ė├ĪŻį┌─┐Ū░ļAČ╬Ż¼ęÄ─Ż╗»Īó╠ōöM╗»ĪóįŲėŗ╦Ńęč│╔×ķöĄō■ųąą─Ą─░lš╣ĘĮŽ“ĪŻė╔ė┌įŲėŗ╦ŃöĄō■ųąą─ī”▐D░lĦīÆĄ─ąĶŪ¾ĘŪ│Ż┤¾Ż¼Č°Ūęé„ĮyĄ─xSTP×ķ┴╦▒▄├ŌŁh┬ĘĢ■ūĶ╚¹─│éĆČ╦┐┌ī¦ų┬▓┐ĘųĦīÆĄ─└╦┘MŻ¼ę“┤╦╚²īėIP▐D░lū„×ķę╗ĘN▀^Č╔╝╝ągę▓▒╗æ¬ė├į┌öĄō■ųąą─ĪŻī”ė┌ę╗ą®▌^┤¾Ą─öĄō■ųąą─╠ß╣®╔╠Ż¼ę╗éĆöĄō■ųąą─Ą─Ę■äšŲ„╚▌┴┐ęčĮø▓╗─▄ØMūŃ╦¹éāĄ─ąĶŪ¾Ż¼│÷ė┌öU╚▌║═×─éõā╔ĘĮ├µĄ──┐Ą─Ż¼┤¾ą═ÅS╔╠═©│ŻĢ■┐╝æ]Į©┴óČÓéĆöĄō■ųąą─ĪŻį┌öU╚▌ĢrŻ¼ąĶę¬└¹ė├╠ōöMÖC▀węŲ╝╝ąg▀MąąöĄō■ųąą─Ą─Į©įO▓┐╩ĪŻ
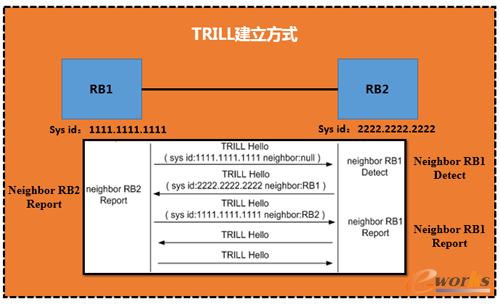
ļSų°öĄō■ųąą─Ą─ęÄ─Ż▓╗öÓöUÅłŻ¼śIäšąĶŪ¾Ą─▓╗öÓį÷┤¾Ż¼Ę■äšŲ„ęį╝░Įė╚ļĮ╗ōQÖCČ╝┤¾ęÄ─Żį÷╝ėŻ¼▓╗╣▄╩Ūé„ĮyĄ─Č■īėŠWĮj▀Ć╩Ūū„×ķ▀^Č╔Ą─╚²īėIP▐D░lČ╝▓╗─▄║▄║├ĄžØMūŃöĄō■ųąą─Ą─ąĶŪ¾ĪŻ┼cTRILLģfūhŽÓ▒╚Ż¼xSTPģfūhÅ─▀mė├Ą─ĮMŠWĪóŠWĮjęÄ─Ż╝░ĦīÆ└¹ė├┬╩Ą╚ĘĮ├µČ╝▓╗Š▀éõā×ä▌ĪŻ┴Ē═ŌŻ¼į┌é„ĮyĄ─IPv4║═IPv6ŠWĮjųąŻ¼ė╔ė┌įOéõĄ─Įė┐┌ąĶę¬┼õų├IPĄžųĘŻ¼įņ│╔IPŠWĮjĄ─┼õų├Å═ļsĪŻČ°«öę╗éĆĮė┐┌ė╔ę╗éĆūėŠWŪąōQĄĮ┴Ēę╗éĆūėŠWĢrŻ¼▒žĒÜę¬Ė─ūā╦³Ą─IPĄžųĘŻ¼▀@ę▓Įo╠ōöMÖCĄ─▀węŲį÷┤¾┴╦╣▄└Ē│╔▒ŠĪŻČ°ŪęŻ¼×ķ┴╦▒▄├ŌĄžųĘĄ─└╦┘MŻ¼IPĄžųĘĄ─╣▄└Ēę▓ąĶ꬚╝ė├┤¾┴┐Ą─╚╦┴”┘Yį┤ĪŻę“┤╦Ż¼╚²īėIP╝╝ągĄ─▀@ą®å¢Ņ}ī¦ų┬╦³į┌Č■īėŠWĮjųą▒Ē¼F▓ó▓╗ā×įĮĪŻTRILLū„×ķ┤¾Č■īėĄ─┐žųŲģfūhŻ¼═©▀^öUš╣IS-IS┬Ęė╔ģfūhŻ¼░čČ■īė┼õų├Ą─ņ`╗Ņąį┼c╚²īėĄ─┤¾ęÄ─Żąįėąą¦ĮY║Žį┌ę╗ŲŻ¼▓┐╩ĘĮ▒ŃĪŻ
2.6.1 TrillįŁ└Ē├Ķ╩÷Ż║
TRILLŠWĮjųąĄ─įOéõ├¹ĘQŻ║
RBŻ©Router BridgeŻ®Ż║ųĖ▀\ąąTRILLģfūhĄ─Č■īėĮ╗ōQÖCĪŻ
DRBŻ©Designated Router BridgeŻ®:ųĖį┌TRILLŠWĮjųąū„×ķųąķgįOéõ▒╗ųĖČ©│ąō·─│ą®╠ž╩Ō╚╬䚥─RBĪŻį┌TRILLÅV▓źŠWųąŻ¼ā╔┼_RB╚ń╣¹╠Äė┌═¼ę╗éĆVLANŻ©Virtual Local Area NetworkŻ®Ż¼į┌Į©┴óÓÅŠėĻPŽĄĢrąĶę¬Ė∙ō■Įė┐┌Ą─DRBā׎╚╝ē╗“š▀MACĄžųĘĄ─┤¾ąĪüĒ▀x┼eDRBŻ¼DRBžōž¤┼cŠWĮjųą├┐┼_įOéõ▀Mąą═©ą┼Ż¼ūŅĮK╩╣š¹éĆVLANĄ─LSDBŻ©Link State DataBaseŻ®▀_ĄĮę╗ų┬ĀŅæBŻ¼£p╔┘┴╦ČÓ┼_įOéõā╔ā╔═©ą┼ĦüĒĄ─Š▐┤¾ķ_õNĪŻ
TRILLųąĄ─VLAN-
Carrier VLANŻ║
VLAN╩Ūīóę╗éĆ╬’└ĒĄ─LANį┌▀ē▌ŗ╔ŽäØĘų│╔ČÓéĆÅV▓źė“Ą─╝╝ągĪŻ═¼ę╗VLANā╚Ą─įOéõų«ķg┐╔ęįų▒Įė═©ą┼Ż¼Č°▓╗═¼VLANų«ķgĄ─įOéõ▓╗─▄ų▒Įė═©ą┼Ż¼▀@śėŻ¼ÅV▓źł¾╬─▒╗Ž▐ųŲį┌ę╗éĆVLANā╚Ż¼▒ŻūC┴╦Šųė“ŠWĄ─░▓╚½ąįĪŻ
Carrier VLANė├ė┌│ą▌dTRILLöĄō■║═╩š░lģfūhł¾╬─Ż¼▓╗│ą▌dŲš═©ETHöĄō■ł¾╬─Ż¼ę╗┼_RBūŅČÓ┐╔┼õų├╚²éĆ▓╗═¼Ą─Carrier VLANĪŻ
CE VLANŻ║
CE VLANę▓Įąū÷Įė╚ļVLANŻ¼ė├ęįĮė╚ļTRILLŠWĮjŻ¼ų╗žōž¤│ą▌dŲš═©ETHöĄō■ł¾╬─ĪŻ
Designated VLANŻ║
ųĖČ©VLANŻ¼į┌TRILLŠWĮjųąąĶę¬ųĖČ©─│éĆCarrier VLAN×ķ▐D░löĄō■┴„┴┐╝░TRILL┐žųŲł¾╬─Ą─VLANŻ¼įōųĖČ©Ą─TRILL VLAN▒╗ĘQ×ķDesignated VLANŻ¼ęįŽ┬║åĘQ×ķDVLANĪŻ
NicknameŻ║
NicknameŽÓ«öė┌IPĄžųĘŻ¼ė├üĒ╬©ę╗ś╦ūRę╗┼_Į╗ōQÖCĪŻę╗┼_RBāHų¦│ų┼õų├ę╗éĆnicknameŻ¼ŪęĒÜ▒ŻūCnickname╚½ŠW╬©ę╗ĪŻ
TRILLģfūhĄžųĘĮYśŗ
┼cIS-ISģfūhŅÉ╦ŲŻ¼TRILLģfūh▓╔ė├NSAPŻ©Network Service Access PointŻ®ĄžųĘĮYśŗŻ¼╚ń00.1234.5678.9abc.00Ż¼┐╔ęį┐┤ū„ė╔ęįŽ┬╚²▓┐ĘųĮM│╔Ż║
Area IDŻ║ģ^ė“ĄžųĘė├üĒś╦ūRģ^ė“ĪŻ┼cIS-IS▓╗═¼Ą─╩ŪŻ¼TRILLĄ─ģ^ė“ĄžųĘęÄČ©×ķ“00”ĪŻ
System IDŻ║ŽĄĮyIDė├üĒ╬©ę╗ś╦ūRę╗┼_ų„ÖC╗“Į╗ōQÖCŻ¼į┌įOéõĄ─īŹ¼FųąŻ¼╦³Ą─ķLČ╚╣╠Č©×ķ48 BitĪŻ
īŹļHæ¬ė├ųąŻ¼System ID┐╔ęįūįäė╔·│╔ę▓┐╔ęį═©▀^┼õų├Ą├ĄĮĪŻūįäė╔·│╔Ą─System ID┼cRBĄ─ś“MACĄžųĘŽÓ═¼Ż¼╚ń╣¹╩ųäė┼õų├Ą─įÆŻ¼ąĶę¬▒ŻūC╚½ŠW╬©ę╗ĪŻ
SELŻ©SelectorŻ®Ż║ū„ė├ŅÉ╦ŲIPųąĄ─“ģfūhś╦ūRĘ¹”Ż¼▓╗═¼Ą─é„▌öģfūhī”æ¬▓╗═¼Ą─SELĪŻTRILLģfūhĄ─SEL×ķ“00”ĪŻ
NET
ŠWĮjīŹ¾w├¹ĘQNETŻ©Network Entity TitleŻ®ųĖĄ─╩ŪĮ╗ōQÖC▒Š╔ĒĄ─ŠWĮjīėą┼ŽóŻ¼┐╔ęį┐┤ū„╩Ūę╗ŅÉ╠ž╩ŌĄ─NSAPĪŻ└²╚ńėąNET×ķŻ║00.1234.5678.9abc.00Ż¼ätŲõųąģ^ė“ĄžųĘ×ķ00Ż¼System ID×ķ1234.5678.9abcŻ¼SEL×ķ00ĪŻ
łD12 TRILLĮ©┴óĘĮ╩Į

łD13 TRILLł¾╬─Ė±╩Į
Trillļm╚╗╩Ū┤¾Č■īėŠWĮjĄ─ę╗éĆą┬ą═Ą─öUš╣ģfūhŻ¼ī”ė┌öĄō■ųąą─ā╚▓┐Ą─ĮMŠWüĒšfŻ¼ąĪęÄ─Ż▓┐╩▀Ć╩Ūø]ėąå¢Ņ}Ą─Ż¼Ą½╩Ūī”ė┌öĄō■ųąą─╬┤üĒĄ─░lš╣Ż¼éĆ╚╦šJ×ķŲõ▓ó▓╗╩ŪūŅ└ĒŽļĄ─ŠWĮj╝▄śŗ─Żą═Ż¼╩ūŽ╚trillĮŌøQ┴╦Č■īėŠWĮjŁh┬Ę┼c╔·│╔śõĄ─Ž▐ųŲąįå¢Ņ}Ż¼Ą½╩ŪŲõį┌ę╗éĆĮM▓źĮMŽ┬╦∙ĮMĮ©Ą─vlanīŹ└²öĄ┴┐╩ŪėąŽ▐Ą─Ż¼▓óŪętrill▓óø]ėąšµš²ĮŌøQČ■īėŠWĮj«öųąvlan▓╗ūŃĄ─å¢Ņ}Ż¼═¼Ģr¤oĘ©į┌é„ĮyŠWĮj╔Ž▀Mąą»B╝ėŻ¼ę▓Š═╩ŪįOéõ▀xą═▒žĒÜĮyę╗Ż¼Č°Ūę▓╗─▄┐ńįĮ╚╬║╬▀\ĀI╔╠ŠWĮjŻ¼ę▓Š═╩Ū▓╗─▄▀_ĄĮČÓšŠ³cķgŠWĮj▓┐╩Ą─ęÄäØŻ¼─Ū├┤ī”ė┌įŲėŗ╦ŃüĒšfŻ¼trill▀@ĘNŠWĮjģfūh▓╗─▄ļSų°Ģr┤·▀M▓ĮČ°╠µ┤·¼FėąŠWĮj╝▄śŗŻ¼Ųõę▓▓óø]ėąĮŌøQvlan tag▐DōQĄ─å¢Ņ}ĪŻ─Ū├┤ČÓéĆöĄō■ųąą─ų▒Įėvlan domain╚į╚╗═¼ī┘ę╗éĆvlan domain┐šķgĪŻ
1.7 OTV
VPLSĄ─ĄĮüĒŲõīŹę¬įńė┌įŲėŗ╦ŃĄ─ĄĮüĒŻ¼ūŅ│§Ą─VPLSĄĮüĒų╗╩Ū×ķ┴╦į÷╠ĒIPģfūh┼cATMų«ķgĄ─ę╗ł÷ĀÄŖZæŻ¼VPLS▒Š╔Ē┐╔ęįĮ©┴óČ■īėŠWĮjį┌╚²īėŠWĮj╔ŽĄ─é„▀fŻ¼Ą½╩Ūė╔ė┌Ųõę└═ąė┌MPLS VPNī”ė┌Ų¾śIüĒšf▓╗╣▄Å─╝╝ąg▓┐╩┼c▀\ŠSīė├µŻ¼▀Ć╩ŪÅ─ŠWĮj┘Yį┤ĘĮ├µČ╝╩Ūę╗éĆ▓╗ąĪĄ─╠¶æŻ¼ÅV▓źĪóload-balanceĪóstpĪóARP▀@ą®Ž▐ųŲąįå¢Ņ}ę└╚╗┤µį┌Ż¼║¾üĒĄ─LISPĪóFabric-PathĪóTtillĄ╚ą┬ŲĄ─┤¾Č■īėŠWĮjģfūhę▓Č╝╩Ūī┘ė┌ę╗éĆöĄō■ųąą─ā╚▓┐Ą─Č■īėŠWĮjģfūhŻ¼Ą½╩Ū«öįŲėŗ╦ŃĄĮüĒĄ─Į±╠ņŻ¼įĮüĒįĮČÓĄ─öĄō■ųąą─▓╗į┘ŠųŽ▐į┌å╬éĆÖCĘ┐ā╚▓┐╗“š▀╠ōöM┘Yį┤│žĄ─ęÄ─Żę▓▓╗Ģ■ų╗╩Ūī┘ė┌å╬ę╗Ą─öĄō■ųąą─Ż¼įĮüĒįĮČÓĄ─ąĶŪ¾ė╔å╬öĄō■ųąą─ųØuĄ─ę²╔ĻĄĮČÓöĄō■ųąą─ĮMŠWŻ¼Č■īėŠWĮję▓Ģ■ļSų«čė╔ņų┴╚½Ąžė“Ż¼ī”ė┌öĄō■ųąą─Č■īėŠWĮjĄ─ąĶŪ¾ī”ė┌ų«ķgĄ─ģfūhę▓Š═ĦüĒ┴╦ą┬Ą─╠¶æĪŻ

łD14 OTV
OTV╩Ūcisco2010─Ļį┌ŲõöĄō■ųąą─Nexus 7000╔Ž░l▓╝Ą─ę╗ĒŚ▄ø╝■╠žąįŻ¼OTVīŹļH╩Ūę╗ĘNVPN╦ĒĄ└╝╝ągŻ¼║å╗»┴╦öĄō■ŲĮ├µÖCųŲŻ¼▓╗ė├į┘Ž±VPLSę╗śėŠSūo▒ŖČÓ╬▓└wŻ©PWŻ®Ż¼╩Ūę╗ĘN╗∙ė┌IS-ISū„×ķ┐žųŲīė├µĄ─ī”MACĄžųĘ▀MąąīżųĘĄ─VPNģfūhĪŻ┐╔ęįū„×ķTRILL╗“š▀Fabric-PathĄ─│Ūė“ŠW░µ▒ŠĄ─ģfūhĪŻ┬Ęė╔▒ĒųąīóMACĄžųĘąĶę¬═©▀^──éĆOTV╣سc▀Mąą▒ĒĒŚ╗»Ż¼MACīżųĘĖ³Ž±┬Ęė╔ģfūhŻ¼├┐éĆOTV╣سcĄ─┬Ęė╔ą┼Žóį┌Ą┌ę╗éĆöĄō■░³░l╦═│÷╚ź║¾Š═ęčĮø▀Mąą┴╦ą┼Žó═¼▓ĮŻ¼═¼Fabric-Path║═TRILLŻ¼╩Ūę╗ĘNŅÉ╦Ųµ£┬ĘĀŅæB┬Ęė╔ģfūhŻ¼▒Š┘|╩Ūį┌ÅVė“ŠWµ£┬Ę╝▄śŗ┴╦ę╗éĆOverlayĄ─»B╝ėŠWĮjĪŻ
OTV┐žųŲŲĮ├µę└ō■Helloł¾╬─▀Mąąµ£┬Ęą┼Žó═¼▓ĮŻ¼═¼Ģrų¦│ųā╔ĘN┐žųŲŲĮ├µé„▌ö─Ż╩ĮŻ¼ę╗ĘN×ķĮM▓ź─Ż╩ĮŻ¼ę╗ĘN×ķå╬▓ź─Ż╩ĮŻ¼ģ^äeį┌ė┌«ö▀\ĀI╔╠ŠWĮjų¦│ųĮM▓źŻ¼├┐éĆOTV╣سc░l╦═ę╗éĆHelloł¾╬─Š═┐╔ęįīóš¹éĆOTVŠWĮją┼Žó▀Mąą═¼▓ĮŻ¼├┐éĆOTV╣سcČ╝Ģ■ļ┬ĀĄĮŽÓ═¼Ą─ĮM▓źĄžųĘ╦∙░l▓╝Ą─HelloŽ¹ŽóĪŻå╬▓ź─Ż╩ĮŪķørŽ┬Ż¼─Ū├┤ąĶę¬OTV╣سcę╗ī”ę╗Ą─▀MąąHelloł¾╬─Ą─é„▀fŻ¼ų▒ų┴╦∙ėą╣سcČ╝░l╦══Ļ«ģŻ¼▓┼Į©┴óę╗Åłš¹¾wOTV▀ē▌ŗŠWĮjĪŻ═¼ĢrOTV┐╔ęį╗∙ė┌vlan▀MąąÅVė“ŠW┴„┴┐žō▌dŠ∙║ŌŻ¼▒╚╚ń╗∙ė┌ŲµöĄvlan┼c┼╝öĄvlanĘųäe▀Mąąload-balanceĪŻ

łD15 ų¦│ųĮM▓źĄ─įŁ└ĒłD

łD16 āHų¦│ųå╬▓ź┴„┴┐Ą─ÅVė“ŠW
OTVį┌«öĢr╩Ūę╗┐ŅĘŪ│Ż▓╗ÕeĄ─┐ńšŠ³cĄ─ŠWĮjģfūhŻ¼į┌┐ńįĮ▀\ĀI╔╠ŠWĮjĄ─═¼ĢrŻ¼╣Ø╩Ī░║┘FĄ─īŻŠĆ┘Mė├ĪŻĄ½╩Ūė╔ė┌ŲõģfūhĄ─ī┘ąįī┘ė┌╦ĮėąģfūhŻ¼ī”ė┌ę╗░ŃĄ─ųąąĪŲ¾śI┐╔─▄ļyęįų¦│ųŲõ░║┘FĄ─ārĖ±Ż¼Ą½╩Ū▓╗┐╔ʱšJŻ¼OTVį┌ī”ė┌Ė▀├▄Č╚│÷┐┌Į╗ōQÖC«öųąĄ─ę╗éĆ═Ļš¹ĮŌøQ╝▄śŗŻ¼┤_īŹ╩Ūę╗éĆĘŪ│Ż▓╗ÕeĄ─╝▄śŗĘĮ╩ĮĪŻį┌▀\ĀIĖ▀├▄Č╚Į╗ōQÖCĢrŻ¼┐╔ęįīóįŲėŗ╦ŃĄūīė╠ōöM╗»┴„┴┐╚½▓┐ģRŠ█ĄĮSpineīėĮ╗ōQÖC╔ŽŻ¼│ą▌d┴╦┤¾┴┐Ą─Č■īė┴„┴┐Ż¼═¼Ģr┐╔ęįī”═ŌBGPĄ─ĘĮ╩Į┼c▀\ĀI╔╠ī”ĮėŻ¼╝╚┐╔ęį│ą▌d│÷┐┌┴„┴┐Ż¼ę▓┐╔ęį│ą▌döĄō■ųąą─ā╚▓┐┤®įĮSITEĄ─Č■īėā╚▓┐┴„┴┐Ż¼ī”ė┌¢|╬„Ž“┴„┴┐ÖMŽ“öUš╣üĒšfŻ¼Š▀ėąÜv╩ĘąįĄ─ęŌ┴xĪŻ

łD17 ▀\ĀI╔╠╣ŪĖ╔ŠW
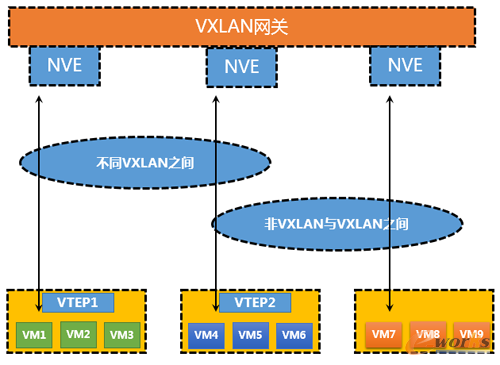
1.8 Vxlan
Vxlan╩Ūė╔CiscoĪóVMwareĪóBroadcomĄ╚ÅS╝ꎓIETF╠ß│÷ę╗ĒŚįŲėŗ╦ŃŁhŠ│Ž┬Ż¼┤¾Č■īėŠWĮjĮŌøQĘĮ░ĖĄ─ę╗ĒŚ▓▌░ĖŻ¼╚½ĘQVirtual eXtensible Local Area NetworkŻ¼╝┤╠ōöMöUš╣▒ŠĄžŠWĮjĪŻ╠ōöM╗»╝╝ąg┤¾ęÄ─Ż▓┐╩Ą─ĄĮüĒŻ¼╩╣Ą├įŁėąĄ─▄ø╝■Ę■äš═¼╬’└Ēė▓╝■Ą─ĘųļxŻ¼å╬éĆ│╠ą“╗“š▀å╬éĆŽĄĮy▓╗ė├į┌å╬ę╗Ą─ė▓╝■╬’└ĒĘ■äšŲ„╔Ž▀\ąąŻ¼═¼ĢrīŹ¼F┴╦ė▓╝■Ę■äšŲ„Ą─┘Yį┤│ž╗»Ż¼▒ŻūC┴╦śI䚥─▀B└mąįĪŻę╗éĆ═Ļš¹Ą─æ¬ė├ŽĄĮyėąų°Ė³┤¾Ą─░lš╣Ż¼ŠWĮjĪó┤µā”Īó░▓╚½Ą╚å¢Ņ}ųØuĄ─│÷¼Fį┌š¹éĆ┘Yį┤│ž«öųąŻ¼Č°ž×┤®▀@ą®┬ōŽĄĄ─ę“╦žų«ę╗Š═╩ŪŠWĮjŻ¼╚½╚fšūŠWĮjĄ─╝▄śŗĘĮ╩ĮĖ─ūā┴╦įŁėąĄ─Ą═čė▀tå¢Ņ}Ż¼Ą½╩ŪŲõ▒Š┘|▀Ć╩Ūī┘ė┌╬’└Ē╝▄śŗĄ─ĘĮ╩ĮŻ¼ā╚▓┐Ė„éĆ▀ē▌ŗŠWĮjĄ─Į©┴óČ╝ęįūŌæ¶Ą─ą╬╩Į¾w¼F│÷üĒŻ¼├┐éĆūŌæ¶Ą─Ė¶ļxŻ¼├┐éĆ╠ōöMŠWĮjĄ─Ė¶ļxŻ¼├┐éĆśI䚥─Ė¶ļxŻ¼Č╝Ģ■║─┘M┤¾┴┐Ą─vlanŻ¼ļSų°vlan Ą─▓╗ūŃŻ¼öĄō■ųąą─ęÄ─ŻļSų«ųØuöU┤¾Ż¼ČÓSITEĄ─ąĶŪ¾ųØu’@¼FŻ¼─Ū├┤├┐ę╗éĆSITEų«ķgĄ─VLan domain▓╗æ¬įōį┘░┤ššįŁėąĄ─ŠWĮj▓┐╩─Ż╩Į╚źęÄäØŻ¼╝┤═¼ī┘ė┌ę╗éĆŠWĮjvlan domainā╚ĪŻįŁüĒø]ėąĄ─ŅIė“ķ_╩╝┴╦ųØuĄ─ūā╗»Ż¼ęčĖ³║├Ą─×ķ«öŽ┬įŲėŗ╦Ń¾wŽĄĘ■䚯¼▓╗╣▄öĄō■ųąą─╗“š▀▀\ĀI╔╠Č╝╩Ū╚ń┤╦Ż¼öĄō■ŠWĮjĄ─ūā╗»Š═╩ŪŲõę╗ĪŻ

łD18 įŲėŗ╦Ń
├µī”▀@ą®å¢Ņ}Ż¼╬ęéā▓╗Ą├▓╗╚ź├µī”Ż¼ę▓▓╗Ą├▓╗╚źĮŌøQŻ¼ę¬┐ń▀^vlanĪóÅV▓źĪó╔·│╔śõ▀@ą®Ą╚Ą╚é„ĮyĄ─Ž▐ųŲå¢Ņ}Ż¼ŠWĮj▒žĒÜ▀MąąĖ─Ė’Ż¼OverlayĄ─╝╝ągųØu¾w¼F│÷üĒŻ¼VxlanīŹļH╔Ž└¹ė├Ą─įŁ└ĒĖ·OTVīŹ¼FĄ─ĘĮ╩Į▓Ņ▓╗ČÓŻ¼Ą½╩ŪĖ³ČÓĄ├╩ŪVxlanĄ─ų¦│ų┴”Č╚ģsę¬▀h▀h┤¾ė┌OTVĄ─ų¦ō╬┴”Č╚ĪŻ
VxlanīŹļH╔ŽČ©┴x┴╦ę╗éĆVtepĄ─īŹ¾wŻ©VXLAN Tunnel End Point—╠ōöMöUš╣▒ŠĄžŠWĮj╦ĒĄ└ĮKśO╣سcŻ®Ż¼īó╠ōöM╗»«a╔·Ą─┴„┴┐ė╔įŁėąĄ─vlanĘŌčb─Ż╩Į═Ļ╚½ūā×ķvxlanĄ─ĘŌčb─Ż╩ĮŻ¼īó«a╔·Ą─öĄō■░³▐Dūā×ķUDPĄ─░³Ņ^Å─ā╚▓┐░l│÷Ż¼╠ōöM╗»▒Š╔ĒĄ─MACĄžųĘĄ╚Č■īėą┼ŽóätĢ■ĘŌčbį┌ā╚īė░³Ņ^ā╚Ż¼VtepĄ─ĘŌčb╣żū„┐╔ęį╩Ū╠ōöM╗»īė╗“š▀ė▓╝■īė├µŻ¼Ą½╩ŪŲõŽ¹║─Ą─ąį─▄ųĖś╦╩Ū╬ęéāąĶę¬┐╝æ]Ą─ę╗ĒŚę“╦žĪŻ╚ń╣¹į┌╠ōöM╗»īė├µīŹ¼FVtepĄ─ĘŌčb╣żū„Ż¼─Ū├┤Ąūīė╠ōöM╗»┴„┴┐į┌ĄĮ▀_ÖCĒöĮ╗ōQÖCĄ─Ģr║“Ż¼Š═ęčĮø▒╗┤“╔Ž┴╦VtepĄ─ś╦║ׯ¼ōQŠõįÆšfŻ¼Ąūīė┴„┴┐ī”ė┌╔ŽīėŠWĮjĄ─╬©ę╗ąĶŪ¾Š═╩Ū╚²īė┐╔▀_Ż¼─Ū├┤ī”ė┌įŲėŗ╦Ń▀@éĆŽĄĮyā╚▓┐Ż¼╚¶▐Dūā│╔╚²īėģfūh▀Mąą▐D░lŻ¼─Ū├┤Š═╗žÜwĄĮ┴╦é„ĮyĄ─┬Ęė╔ģfūh└’├µŻ¼▀@śėĄ─ŠWĮj▐D░lĄ─ą¦┬╩┼c░▓╚½ąįŠ═Ģ■┤¾┤¾į÷╝ėŻ¼įŁėąĄ─STPĄ╚Ž▐ųŲąįę“╦žŠ═ųØu▒╗┤“ŲŲ┴╦ĪŻ
╠ōöMÖC▒Š╔ĒĄ─ą┼Žóī”═ŌęčĮø▓╗┐╔ęŖŻ¼ī”═Ō┐┤ĄĮĄ─ų╗╩Ūę╗éĆé„ĮyĄ─IPöĄō■░³Ż¼Vxlan═©▀^ą┬Ą├ŠWĮjś╦ūRVNIüĒī”├┐ę╗éĆūŌæ¶Ą─ŠWĮj▀MąąĖ¶ļxŻ¼VNI╚Ī┤·┴╦įŁėąĄ─vlan tagś╦ūRŻ¼VNI╩Ūę╗éĆ24 bitĄ─Č■▀MųŲś╦ūRŻ¼é„ĮyĄ─4096éĆvlanĄ─╔ŽŽ▐Ż¼VNIīó┐╔ęį▀_ĄĮ16╚f7Ū¦VXLANŠWĮjČ╬Ż¼Å─Č°ĮŌøQvlan ▓╗ūŃĪóvlan tagĄ─▐DōQå¢Ņ}Ż¼═¼ĢrĮŌøQ┴╦ČÓšŠ³cķg═¼ī┘ė┌ę╗éĆvlan domainĄ─└¦Š│ĪŻ
UDP░³Ņ^Ż║
─┐Ą─Č╦┐┌╩╣ė├4798Ż¼Ą½╩Ū┐╔ęįĖ∙ō■ąĶę¬▀Mąąą▐Ė─ĪŻUDPĄ─ąŻ“×║═▒žĒÜįOų├│╔╚½0ĪŻ
IPŅ^Ż©═ŌīėĄ─ą┬╚²īėŅ^Ż®Ż║
═ŌīėŅ^Ą─IPĄžųĘ▓╗į┘╩ŪįŁėąĄ─╠ōöMÖC═©ą┼ļpĘĮĄ─ĄžųĘŻ¼Č°╩Ū╦ĒĄ└ā╔Č╦Ą─ŠWĮjĄžųĘŻ¼╠ōöM╗»īė├µüĒšfę▓Š═╩Ū▄ø╝■Ę■äšŲ„Ą─ĄžųĘŠW┐©IPĄžųĘŻ¼─┐Ą─IPĄžųĘ┐╔ęį╩Ūå╬▓źĄžųĘŻ¼ę▓┐╔ęį╩ŪČÓ▓źĄžųĘĪŻå╬▓źŪķørŽ┬Ż¼─┐Ą─IPĄžųĘ╩ŪVxlan Tunnel End Point(VTEP)Ą─IPĄžųĘĪŻį┌ČÓ▓źŪķørŽ┬ę²╚ļVXLAN╣▄└ĒīėŻ¼└¹ė├VNI║═IPČÓ▓źĮMĄ─ė│╔õüĒ┤_Č©VTEPsĪŻ
protocolŻ║įOų├ųĄ×ķ0x11Ż¼’@╩Ššf├„▀@╩ŪUDPöĄō■░³
Source ip: į┤vTEP_IP;
Destination ip: ─┐Ą─VTEP IPĪŻ
═ŌīėČ■īėŅ^Ż║
▓╗į┘╩ŪįŁėąĄ─šµīŹMACĄžųĘŻ¼Č°╩Ū╠ōöM╗»▄ø╝■Ę■äšŲ„Ą─MACĄžųĘ╗“š▀╬’└ĒĮ╗ōQÖCĘŌčbVtep╦ĒĄ└Ą─Įė┐┌MACĄžųĘŻ¼▀@śė═Ļ╚½Š═Į©┴óę╗éĆą┬Ą─Č■īėŅ^▓┐Ż¼Č°ā╚īėšµīŹĄ─Ņ^▓┐į┌ĄĮ▀_╦ĒĄ└ĮK³cīóĢ■ūįäė▀MąąĮŌĘŌčbŻ¼ųžą┬ĘŌčbįŁėąöĄō■░³Ż¼īŹ¼F┴╦┐ńįĮ╚²īėé„▀fČ■īėą┼ŽóĄ─╝╝ągĪŻ

łD19 ą┬Ą─VXLANļŅ^
VxlanöĄō■ŲĮ├µŻ║
VTEP×ķ╠ōöMÖCĄ─öĄō■░³╝ė╔Ž┴╦īė░³Ņ^Ż¼▀@ą®ą┬Ą─ł¾Ņ^ų«ėąį┌öĄō■ĄĮ▀_─┐Ą─VTEP║¾▓┼Ģ■▒╗╚źĄ¶ĪŻųąķg┬ĘÅĮĄ─ŠWĮjįOéõų╗Ģ■Ė∙ō■═Ōīė░³Ņ^ā╚Ą──┐Ą─ĄžųĘ▀MąąöĄō■▐D░lŻ¼ī”ė┌▐D░l┬ĘÅĮ╔ŽĄ─ŠWĮjüĒšfŻ¼ę╗éĆVxlanöĄō■░³Ė·ę╗éĆŲš═©IP░³ŽÓ▒╚Ż¼│÷┴╦éĆŅ^┤¾ę╗³c═Ōø]ėąģ^äeĪŻ
ė╔ė┌VXLANĄ─öĄō■░³į┌š¹éĆ▐D░l▀^│╠ųą▒Ż│ų┴╦ā╚▓┐öĄō■Ą─═Ļš¹Ż¼ę“┤╦VXLANĄ─öĄō■ŲĮ├µ╩Ūę╗éĆ╗∙ė┌╦ĒĄ└Ą─öĄō■ŲĮ├µĪŻ
▓┐╩ł÷Š░Ż║
╝āvxlanł÷Š░Ż║▀@ĘNł÷Š░═Ļ╚½┐╔ęį░┤ššé„ĮyĄ─▓┐╩ĘĮ╩Į╚ź▓┐╩vxlanŠWĮjŻ¼į┌╠ōöM╗»īė╠ōÖCų▒Įė┤“╔ŽvxlanĄ─ś╦║×ĪŻ
Vxlan┼cvlanĄ─╗ņ║Ž─Ż╩ĮŻ║ī”ė┌▀@ĘN▓┐╩ł÷Š░Ż¼ąĶę¬ę╗éĆĮąū÷Č■īėvxlan gateway▓┼┐╔ęįīóvlan┼cvxlanų«ķg▀Mąąī”æ¬Ż¼▓óŪęīŹ¼FČ■īė═©ą┼Ż¼«öČ■īė┴„┴┐ģRŠ█ĄĮ╚²īėŠWĻPĢrŻ¼é„ĮySVIĮė┐┌│ą▌dĄ─╩Ūvlan─Ż╩ĮĄ─trunk┴„┴┐Ż¼─Ū├┤ī”ė┌vxlanĄ─ĮŌøQĘĮ╩ĮŻ¼╬ęéā┐╔ęįĮĶė├vxlanŠWĻP▀MąąČ■īė┴„┴┐Ą─ĮKĮYŻ¼┬Ęė╔ĄĮ▀\ĀI╔╠ŠWĮj│÷ŠWĪŻ
łD20 Vxlan┼cvlanĄ─╗ņ║Ž─Ż╩Į
1.9 EVI
ī”ė┌VxlanüĒšfŻ¼ę▓įSī”ė┌é„ĮyüĒšf┐╔─▄╩Ūę╗ĘN▀xō±ĪŻĄ½╩Ūī”ė┌┐ńįĮ▀\ĀI╔╠Ą─ŠWĮjŻ¼ė╚Ųõ╩Ū▀\ū„┤¾ą═öĄō■ųąą─ŠWĮjŻ¼╚ńIDCŻ¼įŲĘ■äš╠ß╣®╔╠üĒšfŻ¼Žļę¬Į©┴óę╗Åł═Ļš¹Ą─┐ńĄžė“┤¾Č■īėŠWĮjŻ¼āHāHę└┐┐Vxlan╝╝ąg╩Ū▓╗ūŃĄ─Ż¼evi╝╝ąg┐╔ęįšf╩Ū╗∙ė┌mplsĄ─ę╗éĆš¹¾wČ■īė▀ē▌ŗŠWĮjŻ¼┐╔ęį┐ńė“▀\ĀI╔╠ŠWĮjĄ─═¼ĢrŻ¼▓╗ė├ę└┐┐mplsŠ═┐╔ęįĮ©┴ó▀hČ╦ÓÅŠėŻ¼īóĮyę╗┴„┴┐Įė╚ļŽÓ═¼EVIŠ═┐╔ęįīŹ¼F┐ńĄžė“╔§ų┴┐ńįĮ╚½Ū“Ą─╦ĮėąŠWĮjĮ©įOĪŻėą╚╦Ģ■šfŻ¼VXLANę▓┐╔ęįīŹ¼FŅÉ╦ŲĄ─╦ĒĄ└ÖCųŲŻ¼Ą½╩ŪļSų°įŲėŗ╦ŃĄ─ĄĮüĒŻ¼╬ęéā║÷ęĢmacĄžųĘöĄ┴┐Ż¼PBB-EVPNĄ─╝╝ąg┐╔ęįīŹ¼Fį┌▀ģŠēįOéõ▀MąąMACĄžųĘģRŠ█Ż¼▀@śėį┌Į©įO╚½Ū“ąį╦Įėą▀ē▌ŗŠWĮjĄ─Ģr║“Ż¼Š═─▄ē“ī”╠ōöMįŲų„ÖCĄ─MACĄžųĘ▀MąąģR┐é▓óą¹Ėµ│÷╚źŻ¼Įø▀^╦ĒĄ└é„▀fĄ─łDųąŻ¼▓╗ė├ō·ą─ŅÉ╦ŲMACĄžųĘĄ─ūĘ█ÖŻ¼▒®┬Čūį╝║╦ĮėąMACĄžųĘĄ─ąą×ķĪŻ▒ŻūC┴╦š¹¾wöĄō■ųąą─Ą─╦Įėą░▓╚½ąįå¢Ņ}ĪŻ

łD21 EVIįŁ└ĒłD
╚ńłDŻ¼Įė╚ļČ╦Ż©ACŻ®Įė╚ļŻ¼╩ūŽ╚Į©┴óEDGE BD ×ķ├┐ŚlACŻ¼Ęų┼õę╗éĆI-SIDŠÄ╠¢Ż¼═©▀^Į©┴óCORE BD ▓óŪę┼c EDGE BDŽÓ╗źĻP┬ōŻ¼ģRŠ█│╔×ķę╗éĆEVIŻ¼├┐éĆeviŽÓ«öė┌ę╗éĆvpnīŹ└²Ż¼īóĘŌčbį┌▓╗═¼vlanĄ─ūėČ╦┐┌Ż¼ś“ĮėĄĮę╗éĆEVI«öųąŻ¼┬Ęė╔Ų„ī”öĄō■░³▀Mąąųžą┬ĘŌčbŻ¼┐╔ęį▀Mąą▓╗═¼vlanķgĄ─2īė═©ėŹŻ¼į┌3īėŠWĮj╔ŽŻ¼ē║╚ļś╦║×▀Mąą▐D░lé„▀fų„ÖCą┼ŽóŻ¼Å─Č°▀_ĄĮ┐ńįĮöĄō■ųąą─Ą─ų„ÖC▀Mąą2īė═©ėŹĪŻ

łD22 MacĄžųĘīW┴Ģ

łD23 ČÓ╚▀ėÓÖCųŲ

łD24 žō▌dŠ∙║ŌÖCųŲ
Č■Īóī”SDN/NFVĄ─└ĒĮŌ
SDNŻ║ SDNŻ©software Defind NetworkingŻ¼▄ø╝■Č©┴xŠWĮjŻ®╩Ūę╗ĘNė╔įŲėŗ╦ŃĄ─░lš╣ȰĦüĒĄ─öĄō■ųąą─ŠWĮj╝▄śŗĄ─╔²╝ēŻ¼ūŅ┤¾Ą─╠ž³cŠ═╩ŪŲõŠ▀ėą╦╔±Ņ║ŽĄ─┐žųŲŲĮ├µ┼cöĄō■ŲĮ├µĪóų¦│ų╝»ųą╗»Ą─ŠWĮjĀŅæB┐žųŲŻ¼īŹ¼F┴╦ĄūīėŠWĮjī”ė┌╔Žīėæ¬ė├Ą─═Ė├„Ż¼Š▀ėąņ`╗ŅĄ─ŠWĮjŠÄ│╠─▄┴”Ż¼╩╣Ą├ŠWĮjūįäė╗»╣▄└Ē┼c┐žųŲ─▄┴”½@Ą├┴╦┐šŪ░Ą─╠ß╔²Ż¼─▄ē“ėąą¦ĄžĮŌøQ«öŪ░ŠWĮjŽĄĮy╦∙├µ┼RĄ─┘Yį┤ęÄ─ŻöUš╣╩▄Ž▐Ż¼ŠWĮj┼cśIäšļyęį▀MąąŠo├▄ĮY║ŽĄ─ąĶŪ¾Ą╚å¢Ņ}ĪŻ

łD24 SDN/NFVĘų╬÷
NFVŻ║ NFVŻ©Network Function VirtualizationŻ®╩ŪETSI┼c2012─Ļ11į┬│╔┴ó┴╦īŻķTė├ė┌ėæšōNFV╝▄śŗ║═╝╝ągĄ─ISG(Industry Specification GroupŻ¼ąąśIęÄĘČĮM)Ż¼Ųõ─┐ś╦╩Ū╗∙ė┌▄ø╝■īŹ¼FŠWĮj╣”─▄▓ó╩╣ų«▀\ąąį┌ĘNŅÉÅVĘ║Ą─śIĮńś╦£╩įOéõ╔ŽŻ¼NFV─┐Ū░Ą─ųž³c╩Ūī”ŠWĮj╣”─▄▀Mąą╠ōöM╗»īŹ¼FŻ¼╦³Ė³ČÓĄ─īŹ¼F╩Ūį┌OSI 4ų┴7īėĄ─śIäšæ¬ė├Ż¼NFV╝▄śŗīó┐žųŲīė├µ▀Mąą┴╦Ė³╝Üų┬Ą─äØĘųŻ¼╠ß│÷┴╦Č╬ĄĮČ╬Ż©End to EndŻ¼E2EŻ®Ą─ŠWĮj┐žųŲīėŻ¼─▄ē“ī”ČÓéĆöĄō■ųąą─╗“š▀▀\ĀI╔╠īŹ¼F▓╗═¼╝╝ągŻ¼░┤ąĶ╣®ĮoŠWĮj─Żą═ĪŻ═¼Ģrę▓╩ŪīŹ¼FSDN└Ē─ŅĄ─ę╗ĒŚīŻķT╝╝ągĘĮ░ĖĪŻ
SDNīŹ¼F┴╦╝»ųą┐žųŲŻ¼ķ_Ę┼Įė┐┌Ż¼ŠWĮj╠ōöM╗»╚²┤¾╠žąįĪŻ
╝»ųą┐žųŲŻ║
▀ē▌ŗ╔ŽĄ─╝»ųą┐žųŲ╩ŪŠWĮj┘Yį┤Ą─╚½Šųą┼Žó┐╔ęįĖ∙ō■śIäšąĶę¬▀MąąĮyę╗Ą─┘Yį┤│ž╗»║═š{┼õŻ¼└²╚ńŻ║╚½Šųžō▌dŠ∙║ŌĪó╚½ŠųĄ─┴„┴┐╣ż│╠Ą╚ĪŻ═¼Ģr╝»ųą┐žųŲ╩╣Ą├š¹éĆŠWĮj┐╔ęį┐┤ę╗éĆš¹¾wŻ¼¤oąĶŽ“é„ĮyŠWĮję╗śėų„ęŌĄ─ī”å╬¬ÜĄ─įOéõ▀MąąCLIĄ─HOP by HOPĄ─┼õų├Ż¼£p╔┘┴╦įŁėąĄ─┼õų├Å═ļsąįļyŅ}ĪŻ
ķ_Ę┼Įė┐┌Ż║
═¼śŗķ_Ę┼Ą──Ž▒▒Ž“Įė┐┌Ż¼īŹ¼FŠWĮj║═æ¬ė├Ą─¤o┐p┬ōŽĄŻ¼╩╣Ą├æ¬ė├į┌ąĶę¬Ģrų▒Įė┐╔ęįūįČ©┴xī┘ė┌╦ĮėąĄ─▀ē▌ŗŠWĮjŻ¼¼FėąĄ─ŠWĮj┐╔ęį│ą▌d│╔░┘╔ŽŪ¦Ą─▀ē▌ŗŠWĮjĪŻŠWĮj┐╔ęįīŹ¼F░┤ąĶ½@╚ĪŻ¼░┤ąĶĘų┼õĄ─ÖCųŲĪŻ
ŠWĮj╣”─▄╠ōöM╗»Ż║
═©▀^─ŽŽ“Įė┐┌Ż¼Ų┴▒╬Ąūīė╬’└Ēė▓╝■įOéõŻ¼īŹ¼F╔Žīėī”ė┌Ąūīė═Ļ╚½¤oĖąų¬Ż¼▓óŪęį┌ąĶꬥ─Ģr║“┐╔ęį═©▀^ųąčļ┐žųŲŲ„½@Ą├ŠWĮjŽÓæ¬Ą─Ę■äš╣”─▄Ż¼░³└©╠ōöMĘ└╗ē”Ż¼╠ōöM┬Ęė╔Ų„Ż¼╠ōöMžō▌dŠ∙║ŌŲ„Ą╚Ą╚é„Įyė▓╝■įOéõ╦∙īŹ¼FĄ─╣”─▄ĪŻ═¼Ģr▓╗į┘╩▄Š▀¾wįOéõĄ─╬’└Ē╬╗ų├Ą─Ž▐ųŲŻ¼▀ē▌ŗŠWĮjų¦│ųČÓūŌæ¶╣▓ŽĒŻ¼ų¦│ųČÓūŌæ¶Ą─Č©ųŲĄ╚ąĶŪ¾ĪŻ
SDN─┐Ū░ų¦│ųĄ─ų„┴„╣”─▄ĘĮ├µę▓╩Ū╗∙ė┌OverlayĄ─╝╝ągįOėŗŻ¼▀MąąŽÓĻPŠWĮj╣”─▄Ą─īŹ¼FĪŻįōįOėŗ╦╝Žļų„ę¬╩ŪĮŌ±ŅĪó¬Ü┴óĪó┐žųŲ╚²éĆĘĮ├µĪŻ
ĮŌ±ŅŻ║╩ŪųĖīóŠWĮjĄ─┐žųŲÅ─╬’└ĒŠWĮj«öųą├ōļx│÷üĒŻ¼┐╔ęįęįplug-inĄ╚ĘĮ╩Į╚┌╚ļĄĮ╠ōöM╗»īė├µŻ¼═©▀^╠ōöM╗»īė├µĄ─Įyę╗š{Č╚Ż¼┐žųŲĄūīėė▓╝■įOéõŻ¼é„ĮyĄ─Ąūīėė▓╝■įOéõ╠Äė┌═Ļ╚½Ą─öĄō■ŲĮ├µ▀Mąą▐D░lŽÓæ¬Ą─┴„┴┐╝┤┐╔ĪŻØMūŃė├æ¶ī”ŠWĮj┘Yį┤Ą─░┤ąĶĮ╗ĖČĄ─ąĶŪ¾ĪŻ
¬Ü┴óŻ║╩ŪųĖįōŅÉĘĮ░Ė│ą▌dIPŠWĮjų«╔ŽŻ¼ų╗ę¬IP┐╔▀_Ż¼▒Ń┐╔ī”ŽÓæ¬Ą─╠ōöM╗»ŠWĮj▀Mąą▓┐╩Ż¼Č°¤oąĶī”įŁėąĄ─╬’└ĒŠWĮj╝▄śŗ▀Mąą╚╬║╬Ė─ūāŻ¼▒ŃĮ▌Ąžį┌¼FėąŠWĮj╔Ž▓┐╩║═īŹ╩®ĪŻ
┐žųŲ»B╝ėŻ║▀ē▌ŗŠWĮj└²╚ńVxlanŠWĮj═©▀^▄ø╝■ŠÄ│╠Ą─ĘĮ╩Į▀MąąĮyę╗┐žųŲŻ¼ŠWĮj┘Yį┤Īóėŗ╦Ń┘Yį┤Īó┤µā”┘Yį┤Ą╚┘Yį┤Ģ■▒╗Įyę╗š{Č╚┼c┐žųŲ▓ó─▄Ė∙ō■╔ŽīėąĶę¬▀Mąą░┤ąĶĮ╗ĖČŻ¼ę▓┐╔ęįīŹ¼F╠ōöM╗»ŠWĮj┼c╬’└ĒŠWĮjįOéõ▀Mąąģf═¼╣żū„Ż¼Å─Č°īŹ¼FŠWĮj═Ļ╚½Ą─ūįäė╗»ÖCųŲŻ¼═©▀^į┌╣سcķg░┤ąĶ┤ŅĮ©╠ōöMŠWĮjŻ¼īŹ¼FŠWĮj┘Yį┤Ą─╠ōöM╗»ĪŻ
Openstack╩ŪśIĮńų¬├¹Ą─ķ_į┤įŲėŗ╦Ń╣▄└ĒŲĮ┼_Ż¼╦³╠ß╣®┴╦žSĖ╗Ą─╣▄└Ē─▄┴”Ż¼ęčĮø▒╗▒ŖČÓįŲėŗ╦ŃąĶŪ¾š▀╦∙Įė╩▄ĪŻį┌ŲõįOėŗ┼cīŹ¼FųąŻ¼┼cśIĮńŅIŽ╚Ą─AWS▀Mąą┴╦ī”ś╦Ż¼«öŪ░Ą─OpenstackęčĮøŠ▀ėąĘŪ│Ż═ĻéõĄ─Ę■äš¾wŽĄŻ¼ų„ę¬ė╔computeĪóGlanceĪóSwiftĪóNeutronĪóDashboardĪóKeystoneĄ╚ĮM╝■ĮM│╔Ż¼ŲõųąNeutronū„×ķ║╦ą─ĮM╝■Ż¼ęčĮøīŹ¼F┴╦SDNĄ─╗∙▒ŠįOėŗ└Ē─ŅŻ¼▓óŪęī”ė┌ŽÓĻPų„┴„ŠWĮj╝╝ągīŹ¼FŠWĮj╣”─▄Ą─╠ōöM╗»Ż¼īóæ¬ė├┼cŠWĮj▀Mąą┴╦Šo├▄Ą─ĮY║ŽĪŻ
NeutronŻ║Neutron╗∙ė┌ę╗éĆ┐╔▓Õ░╬Ą─╝▄śŗŻ¼╠ß╣®╗∙ė┌ūŌæ¶Ė¶ļxĄ─Å─Č■īėĄĮŲ▀īėĄ─╠ōöM╗»ŠWĮjĘ■䚯¼╦³ū„×ķę╗éĆ┐“╝▄╠ß╣®┴╦Įyę╗Ą─ŠWĮj┘Yį┤─Żą═Ż¼Č°Ė„éĆŠWĮjÅS╔╠╗“š▀▓╗═¼Ą─ŠWĮjĘĮ░Ė┐╔ęį╗∙ė┌▀@éĆĮyę╗Ą──Żą═üĒū÷Š▀¾wĄ─īŹ¼FŻ¼Š═╩ŪNeutronųąĄ─▓Õ╝■Ż¼▒╚╚ńL2 agent╗“š▀L3 agentĪódhcp agentĄ╚Ż¼▓óŪęneutron▀Ć×ķé„ĮyĄ─Č■īėĄĮŲ▀īėĄ─ŠWĮjĘ■äš╠ß╣®┴╦Įyę╗Ą─▒▒Ž“ŠÄ│╠Įė┐┌Ż¼▓óŪę×ķČ■īėĄĮŲ▀īėĄ─ŠWĮjĘųäeīŹ¼F┴╦┐╔öUš╣Ą─▓Õ╝■ĮYśŗŻ¼╚ńų¦│ųČ■īėŠWĮjĄ─ML2▓Õ╝■Ż¼ų¦│ų╚²īėŠWĮjĄ─║╦ą─ĮM╝■Ż¼īŹ¼FĖ▀╝ēŠWĮjĘ■䚯¼└²╚ńžō▌dŠ∙║ŌŲ„ĪóĘ└╗ē”ĪóVPNĘ■äšĪó┬Ęė╔ģfūhĄ╚Ė▀╝ēŠWĮj╠žąįĪŻ╚ńĮ±Ż¼NeutronęčĮø│╔×ķOpenstackųąŠWĮj╠ōöM╗»Ą─║╦ą─ĒŚ─┐Ż¼Ė„╝ęÅS╔╠┐╔ęįīŹ¼F╦¹éāūį╝║Ą─“īäėüĒų¦│ų╦¹éāūį╝║Ą─ŠWĮjįOéõŻ¼╔§ų┴┐╔ęįīó═Ļš¹Ą─SDN«aŲĘ┼cOpenStack╝»│╔ŲüĒĪŻ
SDN═¼Ųõ╦¹ŠWĮj╝╝ąg▓╗═¼Ż¼╦³▓ó▓╗╩Ūßśī”─│éĆĒŚ─┐Ą─Š▀¾w╝╝ągĄ─Ė’ą┬Ż¼Č°╩Ū╚źŅŹĖ▓¼FėąĮMŠWĄ─ĘĮ╩Į┼cįOėŗ└Ē─ŅŻ¼▒╚╚ńŻ║OpenFlowĄ─ārųĄŻ║“▓╗į┌ė┌FlowŻ¼Č°į┌ė┌Open”Ż¼ķ_į┤Ą─Š½╦Ķę▓Š═╩Ūį┌ė┌ķ_Ę┼Ż¼║├▒╚Neutronę╗śėĪŻ
╬ęéā┐╔ęį╚źĢ│ŽļSDN─Ż╩ĮŽ┬Ą─ŠWĮj╝▄śŗŻ¼┐╔─▄Ģ■ŅÉ╦ŲĮ±╠ņĄ─╩ųÖCĪóė▓╝■ÅS╔╠ų╗╠ß╣®┴╦ę╗éĆ╗∙ĄAŲĮ┼_Ż¼╚ń╣¹ąĶę¬╚╬║╬Ę■äš╣”─▄Ż¼╬ęéāČ╝┐╔ęį╚źŽÓæ¬Ą─╔╠ĄĻ╚źŽ┬▌dŻ¼Č°▓╗Ģ■╩▄ųŲė┌╩ųÖC▒Š╔ĒŲĮ┼_Ą─Ž▐ųŲĪŻ
SDNĄ─šµš²╩╣├³ŲõīŹ╩Ū┤ŅĮ©ę╗éĆ═Ļ╚½ķ_Ę┼Ż¼ūįų„┐╔┐žŻ¼░┤ąĶ╦∙╚ĪĄ├Ė▀ņ`╗ŅąįŻ¼Ė▀┐╔┐┐ąįĄ─ŠWĮjŲĮ┼_ĪŻ
OpenFlow┤·▒Ē┴╦ę╗▓©ŠWĮj│▒┴„Ą─Ę└ŠĆŻ¼Č°╬šų°ūŅÅVĘ║Ą─ąąśI┘Yį┤║═┐═æ¶ĻPŽĄĄ─é„ĮyŠWĮjÅS╔╠Ą─ų¦│ų¤oę╔Ģ■╝ė┐ņOpenflowĄ─│╔╩ņŻ¼é„ĮyÅS╔╠Ą─▀xō±┐╔─▄│╔Š═╦³éāŽ┬ę╗éĆ╩«─ĻĄ─▌x╗═Ż¼Ą½╩ŪŻ¼į┌ķ_į┤ų„ī¦ę╗ŪąĄ─Ģr┤·Ž┬Ż¼ī”ė┌é„Įy┐╔─▄ę▓╩Ū╦źöĪĄ─ķ_╩╝ĪŻ
╚²Īó╬┤üĒöĄō■ųąą─ŠWĮj┼c▀\ĀI╔╠ŠWĮjĄ─░lš╣ĘĮŽ“
į┌«öŽ┬įŲėŗ╦Ń┐ņ╦┘░lš╣Ą─Ģr┤·Ż¼ė╚Ųõ╩Ū▀\ĀI╔╠║═Ų¾śIŻ¼ŲõöĄō■ųąą─įĮüĒįĮČÓĄžķ_╩╝Ž“įŲ╗»ŠWĮj╝▄śŗ░lš╣ĪŻé„ĮyĄ─ŠWĮj░lš╣ĘĮŽ“Īóé„ĮyĄ─ŠWĮj╦╝ŽļĪóé„ĮyĄ─ŠWĮj╣ż│╠Ĥę¬├┤▐Dą═Ż¼ę¬├┤Š═Ģ■Õe▀^▀@ł÷Š½▓╩Ą─ūāĖ’ĪŻ▒ŖČÓć°ā╚═Ō▀\ĀI╔╠ŅAėŗīóĢ■į┌2020─ĻĄĮüĒų«ļH═Ļ│╔ŠWĮj▐Dą═Ż¼Ų¾śIöĄō■ųąą─┼c▀\ĀI╔╠Ą─ŠWĮj─Żą═īóĢ■ėą75%╩Ūė╔▄ø╝■┐žųŲ║═╣▄└ĒŻ¼įĮüĒįĮČÓĄ─┐žųŲå╬į¬īóĢ■═©▀^SDN║═NFVĘ┼╚ļĄĮįŲ╗“š▀ūŅĮKė├æ¶╩ųųąŻ¼ŠWĮj╣ż│╠ĤĄ─╣żū„─Ż╩Įę▓Ģ■▐DūāĪŻ▀\ĀI╔╠Ą─ĖéĀÄī”╩ų┐╔─▄╩Ū▓╗ų╣▀\ĀI╔╠ų«ķgŻ¼įĮüĒįĮČÓĄ─ĖéĀÄī”╩ųĢ■ūā│╔Ž±üå±R▀dĪóGoogleįŲĘ■äš╣½╦ŠĪŻGoogleį°ĮøšfŻ¼╦³▓ó▓╗╩Ū╣Ō└wŠWĮjŻ¼Č°╩Ūę╗ĘN┐╔╠ß╣®“╔Ē¾w╦∙ąĶĄ─ė├ęįŠS│ų╗ŅąįĪó─▄┴”║═äė┴””Ą─┐╔╩│ė├ŠS╔·╦žĪŻ├µī”įĮüĒįĮČÓĄ─╗ź┬ōŠWĘ■äš╣½╦ŠĄ─śIäš“┐ńĮń”Ż¼▀\ĀI╔╠▓╗Ą├▓╗╚źš{š¹śIäš║═╝╝ągĘĮŽ“╚źū÷╩ął÷ĖéĀÄĪŻ
═©▀^╠ōöM╗»ĪóĘųĮŌ┼cųžĮMŻ¼╩╣öĄō■ųąą─┼c▀\ĀI╔╠Ą─ŽĄĮyĖ³╝ėņ`╗ŅĪó┐╔┐┐Īó░▓╚½║═Ė▀ą¦Ż¼═©▀^ųØuĮė╩▄ķ_į┤ŲĮ┼_Ż¼╩╣Ą├IDC┼c▀\ĀI╔╠┐╔ęįņ`╗Ņ┼õų├║═ķ_░l▄ø╝■Č©┴xĘ■䚯¼Č°▓╗ė├į┘╚ź╣═é“┤¾┴┐▀\ŠS╚╦åT╚źŠSūo▀@ę╗ŪąŻ¼ĄūīėīóĢ■═Ļ╚½═Ė├„Īó¤oĖąų¬Ą─▀\ąąŻ¼╝ė╦┘š¹éĆįŲĄ─╔·æBŽĄĮy│╔ķLĪŻ
öĄō■ųąą─┼c▀\ĀI╔╠Ą╚é„ĮyŠWĮjŲ¾śI┐╩═¹▐Dą═Ż¼╚╗Č°▀@ę╗Ūą▓ó▓╗╚▌ęūŻ¼ėŁĮėą┬╝╝ągĪóą┬Ą─Ę■äš─Żą═Īó╬ęéāŠ═▒žĒÜī”¼FėąĄ─åT╣ż┼c╝╝ąg╚╦åTę╗Ų┼Óė¢Īóʱätę╗ŪąČ╝╩Ū┐šŽļŻ¼╚¶▓╗Įė╩▄ķ_į┤▄ø╝■Ż¼īóĢ■▒╗▀@éĆĢr┤·╦∙╠į╠ŁŻ¼Å─Č°Õe▀^┴╦ę╗ł÷Üv╩ĘąįĄ─ITūāĖ’ĪŻ
¼Fį┌╚╦éā├┐╠ņ├µī”Ą─Č╝╩ŪĖ„ĘNįŲėŗ╦Ń╗ź┬ōŠW╣½╦ŠŻ¼╚ń╣¹é„ĮyöĄō■ųąą─┼c▀\ĀI╔╠▓╗į┘▐Dą═Ż¼īó▓╗Ą├▓╗├µ┼R▒╗ÅžĄū╣▄Ą└╗»Īó┴«ār╗»║═▀ģŠē╗»Ą─├³▀\ĪŻ▀^╚źĮKŠ┐Ģ■▀^╚źŻ¼▀^╚źĄ─ĶŁĶ▓▓╗┤·▒ĒīóüĒĄ─╩šęµŻ¼▀^╚źęčĮø▀^╚źŻ¼įŲĄ─└’│╠▒«▓╗į┘┐╠ėąį°ĮøĄ─├¹ūųĪŻ
╦─Īóę╗éĆŠWĮj╣ż│╠Ĥī”╬┤üĒĄ─Ģ│Žļ
ČÓ─ĻęįŪ░Ż¼ŠWĮj╗“š▀═©ą┼╣ż│╠ĤéāŻ¼Č╝╩ŪīóĖ„ĘNļŖŠĆ▓Õ╚ļĮ╗ōQ░Õ┐©Ż¼Č°¼Fį┌Č╝╩Ūį┌īóĖ„ĘN╣Ō└w▓Õ╚ļĖ„ĘN░Õ┐©«öųąŻ¼īóļŖįÆā╔Ņ^ĮėŲüĒŻ¼Š═┐╔ęį▀Mąą═©ą┼Ż¼ę╗éĆęįė▓╝■×ķų„ī¦Ą─╚½ė▓╝■Ģr┤·ęč╚╗üĒ┼RĪŻĮ±║¾Ż¼ļSų°öĄō■ųą╗»═©ą┼Ģr┤·Ą─ĄĮüĒŻ¼╦∙ėą═©ą┼ė▓╝■įOéõČ╝īóūó╚ļĦėąĖ„ĘN╠žąįĄ─▄ø╝■ĪŻĄ½╩ŪŻ¼ļSų°ąŠŲ¼╝╝ągĄ─░lš╣Ż¼Š¦¾w╣▄įĮüĒįĮČÓŻ¼═©ą┼įOéõ▓óø]ėąĖ·╔ŽĖ▀╦┘░lš╣Ą─ėŗ╦ŃÖCĢr┤·Ż¼ė╔ė┌ų«Ū░╬ęéāČ╝▀^ė┌ę└┘ćė▓╝■Ż¼├┐éĆįOéõ╣”─▄¾w¼FČ╝▓╗═¼Ż¼ę▓Š═╩Ū├┐éĆ═©ą┼įOéõĄ─╣”─▄┼cąį─▄Č╝▒╚▌^å╬š{Ż¼ļSų°įŲėŗ╦ŃĄ─ĄĮüĒŻ¼╗ź┬ōŠWĖ▀╦┘░lš╣Ż¼═©ą┼ŠWĮję▓ųØu├µ┼Rę╗ł÷īŹ¼F╚f╬’╗ź┬ōĄ─įOŽļŻ¼Č°ė▓╝■įOéõĄ─╦Įėą╗»Ż¼ė▓ni ne╝■╝▄śŗįOėŗĄ─╣╠ėą╦╝ŽļŻ¼īóų▓Į┬õ║¾ė┌Ģr┤·Ą─░lš╣ĪŻ
¼Fį┌Ż¼╬ęéā┐╔ęį═©▀^╠ōöM╗»Ż¼īóé„Įyė▓╝■▐Dūā×ķ▄ø╝■Ż¼═©▀^▄ø╝■īŹ¼Fé„Įyė▓╝■╦∙š╣¼FĄ─╣”─▄Ż¼▓óīóĖ„╣”─▄─ŻēK▀MąąųžĮMŻ¼ųžą┬╚┌╚ļĄĮįŲėŗ╦ŃųąŻ¼▀@ę▓įSęŌ╬Čų°Ż¼ą▐Ė──│éĆ┼õų├ĪóīŹ¼F─│éĆ╣”─▄Ż¼ų╗ąĶę¬Äūąą┤·┤aę▓įSŠ═┐╔ęįĖŃČ©Ż¼╚ń╣¹╬ęéā▓╗Įė╩▄▀@ę╗ŪąŻ¼öĄō■ųąą─┼c▀\ĀI╔╠īó¤oĘ©│¼įĮ╗ź┬ōŠWĢr┤·┐ņ╦┘Ę┤æ¬╩ął÷Ą─ūā╗»Ż¼ų▒ų┬┬²┬²ĄŁ│÷▀@éĆ╩└ĮńŻ¼┬õ─»Ąžųx─╗ĪŻ
ŠWĮjīó├µ┼Rę╗ł÷Ū░╦∙╬┤ėąĄ─ūāĖ’Ģr┤·Ż¼ą┬Ą─ŠWĮj─Żą═īóĢ■╚źĘų╬÷┤¾┴┐öĄō■┼cą┼ŽóŻ¼▓óŪęį┌ŽÓæ¬Ģrķgā╚ū÷│÷┐ņ╦┘Ę┤æ¬Ż¼╗∙ė┌┤¾öĄō■ŲĮ┼_┴┐╔ĒČ©ųŲĄ─śIäš═ČĘ┼Ż¼┐ņ╦┘╩Ķī¦ųŪ─▄Į╗ōQĄ╚═©ą┼ŽĄĮyĪŻ
└ĒŽļ╩ŪžSØMĄ─Ż¼Č°¼FīŹ┐é╩Ū╣ŪĖąŻ¼╚ń╣¹╚▒Ę”äōą┬Ż¼╚▒Ę”Įė╩▄įŲėŗ╦ŃĄĮüĒĄ─īW┴Ģą─æBŻ¼╚▒Ę”Įė╩▄¼FīŹĄ─ė┬ÜŌŻ¼╚▒Ę”ī”ė┌ą┬╝╝ągĄ─╩╣ė├┼cŠSūo─▄┴”Ż¼▒M╣▄ī”ė▓╝■▓┘ū„ė╬╚ąėąėÓŻ¼Ą½╩Ūį┌├µī”║Ż┴┐öĄō■Īó│╠ą“╗»Ą─╩└ĮńŻ¼┤¾öĄō■ĪóįŲėŗ╦ŃĄ╚ą┬Ą─Ė┼─Ņ═Ļ╚½▒¼░lĄ─Ģr║“Ż¼ę¬├┤Įė╩▄Ż¼ę¬├┤Õe▀^ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║┬■šäįŲėŗ╦ŃŠWĮjŻ║įŲėŗ╦ŃŠWĮj╝╝ągĮķĮB(ę╗)
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839719311.html






















