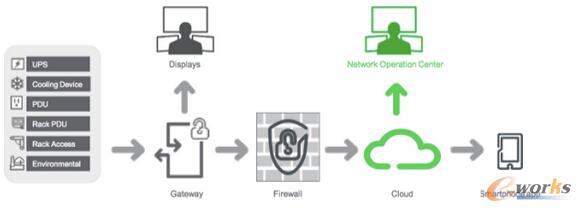
UPYUN äōśIė┌2005 ─ĻŻ¼«öĢrĘ■äšŲ„╩╣ė├Ą─ŠW┐©▀Ć╩ŪMarvellĄ─ąŠŲ¼Ż¼ę¬═©▀^ūįČ©┴xā╚║╦║═“īäėį┤┤·┤aū÷ŠÄūg▓┼─▄“īäėŲüĒĪŻČ°╩«─Ļ║¾į┌▀\ŠSĘĮ├µęčĮø«a╔·┴╦ĘŁ╠ņĖ▓ĄžĄ─ūā╗»Ż¼▒Š╬─ŽĄĮyĄž┐éĮY┴╦ UPYUN Ą─įŲ▀\ŠSĄ─ę░ąU│╔ķLĪó▓╚▀^Ą─┐ėęį╝░¼FļAČ╬Ą─ĀŅørĪŻ
▀\ŠSĄ─╦ćąg
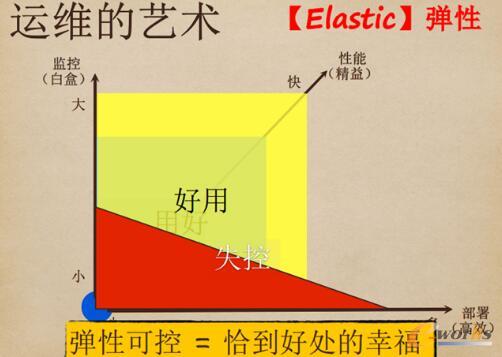
▀\ŠSĄ─╦ćąg╩ŪÅŚąįĪŻ╩ūŽ╚Ż¼Å─¤oĄĮėąŻ¼▀@ĘŪ│Żųžę¬ĪŻ¤ošō▀\ŠSū÷Ą├ČÓģ¢║”Ż¼ų╗╩ŪŪ░├µĄ─“1”ų«║¾Ż¼╝ė╔ŽČÓ╔┘“0”Č°ęčĪŻÅ─¤oĄĮėą║▄└¦ļyŻ¼Ą½╦³╩Ū┐╔ęįīŹ¼FĄ─Ż¼╚½┴”ęįĖ░╚źū÷Ż¼į÷ķLĢ■║▄čĖ├═ĪŻ
▀\ŠS┐é╣▓ėąÄūŚlŠĆ─žŻ┐
- ę╗╩Ū▓┐╩ĪŻė╔╔┘ĄĮČÓŻ¼▀@╩Ūę╗ĘNÖCŲ„Ą─┐žųŲĘĮĘ©Ż╗
- Č■╩ŪÅ─ąĪĄĮ┤¾ĪŻ«öĘ■äšŲ„Ą─öĄ┴┐▀_ĄĮėąČÓ╔┘Ų┴Č╝┐┤▓╗╚½Ą─Ģr║“Ż¼▒O┐žĄ─╩ųČ╬Š═ūāĄ├ĘŪ│Żųžę¬ĪŻ▀@Ģr║“ėąę╗ĘNĘĮĘ©╩Ū░ū║ą▀\ŠSŻ╗
- ╚²╩Ūąį─▄Ż¼Š½ęµ▀\ŠSĪŻ
ę╗╝ę╣½╦ŠÅ─ąĪĄĮ┤¾Ż¼▓╗┐╔─▄ę╗┐┌│į│╔┼ųūėĪŻĄ┌ę╗ļAČ╬Ą─ųž³c╩Ū┐╔ė├Ż¼Ą┌Č■ļAČ╬ų°ųž░č¼FėąĄ─╝╝ągė├║├Ż¼Ą┌╚²ļAČ╬Š═ę¬ūī╦³ūāĄ├Ė³║├ė├ĪŻ
ļSų°śIäšį÷ķLįĮüĒįĮ┐ņŻ¼┐═æ¶Ą─ę¬Ū¾įĮüĒįĮĖ▀ĪŻį┌UPYUN Ą─╝▄śŗ└’├µėą┴╦ĘŪ│Ż╔Ņ╚ļĄ─æ¬ė├Ż¼ū÷┴╦Č■┤╬ķ_░lĪŻ«öĘ■äšŲ„öĄ┴┐įĮüĒįĮČÓŻ¼▀\ŠSūįäė╗»įĮüĒįĮ┐ņĄ─Ģr║“Ż¼╚ń╣¹▒O┐žū÷▓╗╔Ž╚źŻ¼║▄╚▌ęū╩¦┐žĪŻę“┤╦▀\ŠSĄ─╝╝ągÅŚąį┐╔┐žŻ¼╩Ū║▄║├Ą─ĘĮ╩ĮĪŻ
╝▄śŗ╩ŪėŗäØ│÷üĒĄ─Ż¼▓╗╩ŪįOėŗ│÷üĒĄ─Ż¼į┌▓╗═¼Ą─Ģrķg║═ļAČ╬Ż¼ę¬ė├▓╗═¼Ą─ĘĮĘ©īŹ¼F─┐ś╦ĪŻ▓ó▓╗╩Ū░lš╣Ą├įĮ┐ņįĮ║├Ż¼Č°╩Ūę¬ĮėĄžÜŌĪŻ
▀\ŠSĄ─Ę©īÜ

▀\ŠSĄ─Ę©īÜ╩Ū╚²╬╗ę╗¾wĪŻŲõę╗╩Ū▀\ŠSūįäė╗»║═┴„│╠╗»Ż¼ĘĮĘ©ėą║▄ČÓĘNĪŻįŁüĒ╬ęū÷Ą─╩Ū▄ć▌dŻ¼╝╚╚╗ę¬ū÷ĄĮ12šūŻ¼└’├µ▓╗┐╔─▄ėą┼─özŻ¼ę╗éĆ┼─özĄ─░³ø]╚²Īó╦─╩«šūū÷▓╗ĄĮĪŻ─┐ś╦╩Ūę╗śėĄ─Ż¼ę╗Č©ę¬Ģ■ė├╣żŠ▀Ż¼░č╚▌ęū│÷ÕeĄ─╩┬Ūķė├─_▒ŠęÄĘČ║├ĪŻ
ŲõČ■╩Ū▒O┐ž│ŻæB╗»Ż¼╝░Ģrł¾Š»╝░Ė¶ļxŻ¼ė|░lčaŠ╚┤ļ╩®ĪŻ╩┬╣╩▓╗┐╔─▄¤oŠē¤o╣╩Ą─░l╔·Ż¼┐ŽČ©╩Ūų«Ū░Ą─╣żū„┴¶Ž┬┴╦╩▓├┤ļ[╗╝Ż¼ąĶę¬╝░Ģr▓ķŪÕĪŻę¬ī”«É│Ż▓╔╚Ī╝░ĢrĄ─╠Ä└ĒŻ¼UPYUN ╩╣ė├Ą┌ę╗╚╦ĘQĄ──_▒Šū÷▒O┐žŻ¼░l╔·«É│ŻĀŅør╦³Š═Ģ■│÷üĒģRł¾ĪŻ
ūŅ├„’@Ą─╩ŪDDos╣źō¶Ż¼┐é╩Ū╩┬║¾▓┼░l¼FŻ¼ę“×ķ┴„┴┐┤“▀^üĒŻ¼ūŅŽ╚Ėąų¬Ą─æ¬įō╩ŪŠW┐©ĪŻßśī”▀@³cŻ¼UPYUNė├─_▒Š▓ČūĮŠW┐©Ą─«É│Ż╔Ž╔²┴„┴┐Ż¼┐╔ęįĮė╩šĄĮ╦³“┼R╦└Ū░”░l│÷Ą─Š»ł¾Ż¼▀\ŠS╚╦åTŠ═┐╔ęįĖ∙ō■▀@éĆ╝░Ģr░č╩▄╣źō¶Ą─╣سcš¬Ą¶ĪŻ
Ųõ╚²╩Ūąį─▄┐╔ęĢ╗»Ż¼▀\ŠSę¬ī”ūį╝║Ą─śIäšžōž¤Ż¼╠ß╣®▀B└mĄ─ĮĪ┐ĄČ╚ł¾▒ĒŻ¼ęįĀÄ╚Ī┘Yį┤ĪŻę“×ķ▀\ŠSąĶę¬─├ĄĮÖCŲ„╗“ūŃē“Ą─ė▓╝■Ż¼Ę±ät╣żū„║▄ļy▀MąąĪŻ«ö▀\ŠS║═└Ž░Õ╗“╩Ū╔Ž╝ēųv╝╝ąg³cĢrŻ¼╚ń╣¹╦¹éā┬Ā▓╗Č«Ż¼Š═┐╔ęį░čł¾▒Ē─├Įo╦¹éā┐┤ĪŻ▀@Š═╩Ūąį─▄┐╔ęĢ╗»Ą─ę╗éĆųžę¬Ą─ęŌ┴xĪŻ
ĘĮŽ“▒╚┼¼┴”Ė³ųžę¬Ż¼┴„│╠▒╚ča╬╗Ė³ųžę¬Ż¼ĘĮĘ©▒╚Ų┤├³Ė³ųžę¬ĪŻį┌2015─ĻŻ¼UPYUN Č╝į┌ū÷┴„│╠Ą─Ė─▀MŻ¼ų«Ū░╠½┤ųĘ┼┴╦ĪŻ
▓┐╩ūįäė╗»
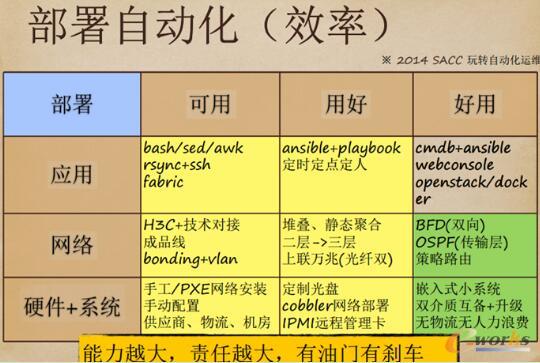
▓┐╩ūįäė╗»Ą─╚²éĆę¬╦žŻ║æ¬ė├ĪóŠWĮjĪóė▓╝■+ŽĄĮyĪŻĄ┌ę╗Ų┌ĢrUPYUNė├awkĪósedĪóbashŻ¼Ą┌Č■Ų┌ōQ│╔┴╦Ansible+playbookŻ¼Ą┌╚²Ų┌ķ_╩╝╩╣ė├cmdb+AnsibleĪŻ░l▓╝┴„│╠ų«Ū░║▄▓╗ęÄĘČĪŻ▒╚╚ń▀\ŠSąĶę¬cmdb+AnsibleĄ─ĮY║ŽŻ¼Ą½░l¼F▀Ćø]ū÷Ż¼į§├┤▐k─žŻ┐Š═┐╔ęįė├Č©ĢrČ©³cĄ─ĘĮ╩ĮęÄČ©║├ąŪŲ┌╚²ū÷░l▓╝ĪóąŪŲ┌Č■ū÷£yįćĪŻī├Ģr┤¾╝ę╚źę╗éĆĢ■ūh╩ęŻ¼╩┬Ž╚įOČ©║├Ż¼ī├Ģrķ_╩╝ė^▓ņĪŻąŪŲ┌╬Õ└^└mė^▓ņŻ¼░l¼Fėąå¢Ņ}Š═╗ž═╦ĪŻ
▀@ą®ų╗╩Ūųąķg▀^│╠Ż¼ę“×ķ▀\ŠSų¬Ą└╬ęę¬ū÷╩▓├┤ĪŻČ©Ž┬─┐ś╦ų«║¾Ż¼ųąķgĄ─▀^│╠Š═┐╔ęį║▄║├Ą─┐žųŲĪŻŲ│§UPYUN║═H3Cū÷ī”ĮėŻ¼┘Å┘I╦³Ą─įOéõŻ¼╦³╠ß╣®╝╝ągĮŌøQĘĮ░ĖĪŻ¼Fį┌ū÷ĄĮBFDŻ¼ėąČÓéĆöĄō■ųąą─Ż¼┐╔ęįė├╣Ō└wū÷╗ź═©ĪŻ
¼Fį┌UPYUN ▓╗āHėąā╔Ė∙┬Ń└wŻ¼▀Ćėą░╦éĆ┐┌ĪŻUPYUNÅ─▒▒Š®Īóųą╔ĮĄ╚öĄō■ųąą─ū÷ūŅĮ³┬ĘÅĮĄ─▀xō±ĪŻć°ā╚Ą─ųą▐DÖCĘ┐Ż¼Ž±ļŖą┼Īó┬ō═©║═ęŲäėŻ¼ī”ė┌ČčĄ³ĪóņoæBŠ█║ŽŻ¼įŲ┤µā”╩Ūā╚ŠWū÷└õ┤µā”Ż¼╣½╦ŠĖ·Į╗ōQÖCū÷ČčĄ³Ż¼ę“Č°═╠═┬┴┐ėą▒ŻūCŻ¼Į╗ōQÖCę▓┐╔ęįéõĘ▌ĪŻ
ļSų°¾w┴┐įĮüĒįĮ┤¾Ż¼UPYUNÅ─IDC─├ĄĮĄ─╗I┤aę▓Š═Ė³┤¾Ż¼▒╚╚ń2GĄ─▒ŻĄū┴┐Ż¼╦¹éāĮoUPYUNŲ╚²īėŻ¼¤ošōį┌┐╣╣źō¶─▄┴”ĪóŠWĮj═žōõĮYśŗ╔ŽŻ¼ėąĖ³┤¾Ą─ņ`╗ŅČ╚ĪŻ─├ĄĮ A ▌å╚┌┘Yęį║¾Ż¼UPYUNĄ─Ą┌ę╗╝■╩┬Ż¼Š═╩Ū░čŠWĮjįOéõ╔²╝ē│╔╚fšūĮ╗ōQÖCĪŻę“×ķŪ░├µėąLOVSŻ¼┐╔ęįū÷öUš╣öU╚▌ĪŻČ°╚ń╣¹ŠWĮj¤oĘ©öU╚▌Ż¼ę¬öU▀@éĆ³cĄ─įÆŻ¼śI䚊═▒žĒÜŪąĄ¶ĪŻę“┤╦Ė·ÖCĘ┐šäę╗éĆ╚fšū┐┌╔§ų┴╩Ūā╔éĆ╚fšū┐┌ĢrŻ¼▒žĒÜŠWĮjŽ╚ąąĪŻė▓╝■ų▒Įė╠°ĄĮŪČ╚ļ╩ĮąĪŽĄĮyŻ¼«öÖCŲ„ų╗ėąę╗ēK▒PĄ─Ģr║“Ż¼░č╦³Å─╬ÕūāĄĮ┴∙Ż¼ÖCŲ„Š═▒žĒÜŽ┬╝▄ĪŻ
╚ń╣¹ė├ąĪŽĄĮyŠ═Ģ■░l¼FŻ¼▀@└’ėąā╔ĘNĮķ┘|Ż║U▒P║═┤┼▒PĪŻ╚ń╣¹ę¬╔²╝ēŽĄĮyŻ¼UPYUN┐╔ęį░莥ĮyŪąĄĮąĪŽĄĮyŻ¼ī”┤┼▒Pū÷▓┘ū„ŽĄĮyĄ─īæ╚ļŻ¼Ū░║¾▓╗│¼▀^╚²ĘųńŖĪŻUPYUN ¼Fį┌┐╔ęįū÷ĄĮ╔ŽŪ¦┼_Ą─ÖCŲ„Å─üĒ▓╗į┌╣½╦Š│÷¼FŻ¼ų▒Įė░莥Įy╝─ĄĮ╔·«aŠĆŻ¼į┌╔·«aŠĆ╔Ž░čU▒P▓Õ╔Ž╚źŻ¼Å─╔·«aŠĆ▀BĮėĄĮÖCĘ┐Ż¼ÖCĘ┐╚╦åT▓ÕŠĆ║¾Ż¼UPYUN Ą─▀\ŠSłFĻĀŠ═┐╔ęį▀Mąą▀h│╠┐žųŲĪŻ
▀@╩ŪūŅ╗∙▒ŠĄ─ŽĄĮyŻ¼╦³▓╗Ģ■īóUPYUNĄ─├¶ĖąöĄō■Ħ▀M╚źĪŻĘ±ätĄ─įÆŻ¼▀@├┤ČÓCDNÖCŲ„░lĄĮ╣½╦ŠŻ¼ę¬ĮŌ░³Īó░▓čbŽĄĮyĪó£yįćĄ╚Ż¼▀\ŠSĢ■├”▓╗▀^üĒĄ─ĪŻį┌▓┐╩ūįäė╗»ĘĮ├µŻ¼UPYUNėą═Ļ╔ŲĄ─╣żŠ▀║═┴„│╠ĪŻ
╚ńĮ±Ż¼║▄ČÓ┤¾Ģ■Č╝į┌šä▀\ŠSūįäė╗»Ż¼▀@Ė·Ų¾śIĄ─ŽĄĮy╝▄śŗįOėŗŠo├▄ŽÓĻPĪŻ«ö▀\ŠSį┌╝▄śŗ╔Ž▒ŻūCĮĄ╝ē║¾Ż¼║▄ČÓ╩┬ŪķąĶę¬═Ųäėķ_░lüĒū÷Ż¼ķ_░l▓┐ķTę¬┼õ║Ž─ŃĮĄĄ═ŠSČ╚ĪŻ▓╗Š├ų«Ū░Ż¼UPYUN Š═į°Įøū÷▀^ę╗┤╬ĮĄ╝ēŻ¼▀Ć╩ŪŽÓ«ö│╔╣”Ą─ĪŻ
▒O┐ž│ŻæB╗»

▒O┐ž│ŻæB╗»Ż¼▀@Ųõųą░³║¼┴╦║▄ČÓĄ─Įø“×Į╠ė¢ĪŻ▒O┐žę¬╦ž▓╗╚½├µŻ¼▒O┐žąį─▄Ė·▓╗╔Ž╩Ū▒╚▌^┤¾Ą─å¢Ņ}ĪŻ═©▀^┐éĮYĮø“ׯ¼UPYUN░l¼Fzabbix«ö▓╔╝»┴╦1000+ČÓ┼_Ę■äšŲ„Ą─Ė„ĘN▒O┐žųĖś╦║¾Ż¼ąį─▄Š═Ė·▓╗╔Ž┴╦ĪŻ
▒O┐žę¬ĘųĄ╚╝ēĪŻ100┼_┐╔ęį┐┐╚Ōč█▒O┐žŻ¼100ų┴1000┼_Š═ąĶę¬ė├Zabbix ║═Ą┌ę╗╚╦ĘQł¾Š»ĪŻUPYUN ėąūį╝║Ą─śIäš▒O┐žŻ¼▀Ćėą╚½ć°╣سcĘų▓╝łDŻ¼UPYUN ėą┤¾╝s3000ČÓ┼_Ę■äšŲ„Ż¼Š═░čöĄō■ū÷ģR┐éŻ¼▀MąąöĄō■┐╔ęĢ╗»Ą─╠Ä└ĒŻ¼│╔╣”īŹ¼FĦīÆ┘|┴┐łDĪóELKöĄō■Ęų╬÷ĪóąĪ├ū▒O┐žĪŻUPYUN ī”ąĪ├ū▒O┐žĄ─▓┐Ęų╣”─▄▀Mąą┴╦Č■┤╬ķ_░lŻ¼¼Fį┌╦³Ą─š¹¾wąį─▄ę¬▒╚Zabbix║├║▄ČÓĪŻ
┤╦═ŌŻ¼▀ĆėąUPYUNūįąąķ_░lĄ─“╣Ęč█”▒O┐žŽĄĮyĪŻ╦³─▄ē“▒O£yĄĮ├┐ę╗éĆūėŽĄĮyĄ─Ēææ¬╦┘Č╚ĪŻ░³║¼╚½ć°╣سcĦīÆłDŻ¼╦³ė├╝t╔½ĪóŠG╔½Īó╦{╔½▀MąąĀŅæBś╦ėøŻ¼▀Ć┐╔ęį’@╩ŠĖ„╣سcĄ─Ę■äšŲ„öĄ┴┐ĪŻUPYUN“ļp╩«ę╗”╚ļ±v─ó╣ĮĮųĢrŻ¼Š═┐╔ęį═©▀^įōŽĄĮy┐┤ĄĮ╦∙ėąÖCĘ┐Ą─īŹĢröĄō■▒O┐žĪŻŲõīŹŻ¼▒O┐ž▓▀┬į║▄║åå╬Ż║├┐╠ņČó╚²éĆūŅ┬²Ą─ÖCĘ┐Ż¼ųéĆ┼┼▓ķįŁę“Ż¼▀@╩Ūū÷SLAĄ─▒ŻūCĪŻ
Į±─Ļ╔Ž░ļ─ĻŻ¼▀\ŠSłFĻĀĄ─┐┌╠¢╩Ū“░l¼Få¢Ņ}▒╚┐═æ¶╝░Ģr”Ż¼Ą½┐╔Ž¦ę╗ų▒ū÷▓╗ĄĮĪŻ▀@╩Ūę“×ķ┐═æ¶╩Ū24ąĪĢrį┌ŠĆ╔ŽŻ¼├┐┤╬Č╝╩Ū┐═æ¶▒╚╬ęéā┐ņŻ¼▀@ūī╚╦║▄┐ÓÉ└ĪŻČ°į┌ė├┴╦ELKĄ─╚šųŠ┤¾öĄō■Ęų╬÷║¾Ż¼UPYUN ║▄ČÓĢr║“Š═┐╔ęįū÷ĄĮŽ╚ė┌┐═æ¶░l¼F┴╦ĪŻ
ąį─▄┐╔ęĢ╗»
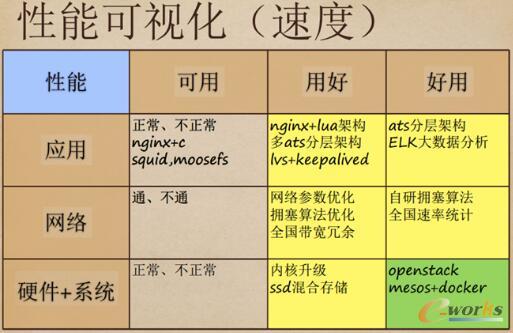
ĻPė┌ąį─▄┐╔ęĢ╗»Ż¼¼Fį┌┐╔ęįū÷ĄĮį┌ŠÅ┤µ▄ø╝■╔Žū÷Nginx+luaĪŻ╬ęéā═¼Ģrė├ā╔éĆŻ¼Ųõųąę╗éĆžōž¤SSDŻ¼ATS┐╔ęįū÷ĄĮ├ļ╝ēųžåóŻ¼╔Ž├µėąLVSū÷žō▌dŠ∙║ŌĪŻ▀\ŠS▓╗─▄▒ŻūC▀@éĆ╝»╚║└’ATS═¼ę╗Ģrķg┤µ╚ĪŻ¼Ą½╚ń╣¹ā╚╚▌ą╣┬Č▀^ČÓŻ¼Š═Ą├ÅŖųŲųžåóĪŻę“┤╦UPYUN ¼Fį┌šą┴╦ā╔éĆīŻ┬Ü╚╦åT蹊┐ATSį┤┤·┤aĪŻ┴Ē═ŌŻ¼UPYUN ūįčą┴╦ōĒ╚¹╦ŃĘ©ĪŻĄ┌╚²ĘĮ╠ß╣®Ą─╦ŃĘ©┐╔ė├ąį║▄Ą═Ż¼Ą½╩Ū╦³éāĄ─ā╚║╦į┌UPYUN╔²╝ē║▄┐ņŻ¼LinuxĄ─┤·└Ē╔²╝ēę¬┼cæ¬ė├│╠ą“ę╗śė┐ņŻ¼Č°ā╚║╦Ą─╔²╝ēĢ■╠ß╔²ąį─▄ĪŻ
2015─Ļ5į┬Ę▌ū¾ėęŻ¼UPYUN ķ_╩╝ĻPūóMesos+DockerŻ¼ų«Ū░ę╗ų▒▀xō±OpenStackų„ę¬╩Ū│÷ė┌╣Ø╝s│╔▒ŠĄ─┐╝æ]ĪŻČ°į┌░l¼FDocker║▄║├ė├║¾Ż¼łFĻĀķ_╩╝╝»ųąŠ½┴”蹊┐DockerĪŻELK┐╔ęįū÷║▄ČÓ╩┬ŪķŻ¼┐╔ęį┐┤ĄĮĄ═ė┌100║┴├ļĪó300║┴├ļĪó500║┴├ļĪó1000║┴├ļŻ¼ėą4xxĪó5xxĄ─▒╚└²Ż¼öĄō■ł¾▒Ēę╗³c³cąĪ▓©äėČ╝┐╔ęį┐┤ĄĮ▓Ņ«ÉĪŻUPYUNį°Įøū÷▀^£yįćŻ¼ø]╩╣ė├ā×╗»ā╚║╦╦ŃĘ©║═╩╣ė├┴╦ą┬Ą─hyblaōĒ╚¹╦ŃĘ©Ż¼Å─3.18Ą─ā╚║╦╔²ĄĮ4.1Ą─ā╚║╦Ż¼öĄō■Ģ■ėą╠ß╔²ĪŻKernelę¬ūį╝║░č╬šŻ¼3.18ĄĮ4.1Ą─Ģr║“Ż¼╬ęéāį°Įøė÷ĄĮ▀^ę╗éĆå¢Ņ}Ż║ā╚ŠWū÷TCPĄ─Ģr║“ū÷┤¾░³š{š¹║▄╦¼ĪŻĄ½Ę┼ĄĮ═Ōć·CDNĄ─Ģr║“Ż¼4.0│÷¼F┴╦BugĪŻ4.0Ą─ā╚║╦į┌ę“╠žĀ¢1000Ą─ŠW┐©ļpŽ“ĮM║ŽĄ─Ģr║“Ģ■¤oĒææ¬Ż¼Č°3.18Ą─ā╚║╦Įė╚ļŠ═ø]å¢Ņ}ĪŻ╦³Ą─║├╠Ä’@Č°ęūęŖŻ¼Ą½ę╗Č©ę¬░č╬šČ╚ĪŻ
▀\ŠSĄ─¤®É└

ū„×ķ▀\ŠS╚╦åTŻ¼Ģ■ėą║▄ČÓ¤®É└ĪŻĄ┌ę╗³cŻ¼▀\ŠS║▄ČÓĢr║“Č╝ę¬░ńč▌“Įė▒Péb”║═“▒│Õüéb”Ą─ĮŪ╔½Ż¼ę“×ķ╣½╦Šę¬ėąę╗éĆ╚╦│÷üĒ│ąō·ž¤╚╬ĪŻ╚ń╣¹▀\ŠS─▄ē“į┌▀@éĆē║┴”Ž┬ĮŌøQå¢Ņ}Ż¼½@Ą├└Ž░ÕšJ┐╔Ż¼─Ū─ŃŠ═╩Ū║ŽĖ±Ą─ĪŻ
┴Ēę╗³c╩ŪŅlĘ▒╔Ļšł║═Ė³ōQ┘Yį┤ĪŻ¼Fį┌OpenStack║═DockerČ╝ėą▀@ĘĮ├µąĶŪ¾ĪŻAnsible║═Mesosę▓║▄īŹė├Ż¼¼Fį┌ÄūŪ¦┼_Ę■äšŲ„Č╝ėąDockerĪŻĄ┌╚²╩Ū▒O┐ž▓╗ĄĮ╬╗Ż¼▀@³c┐╔ęįė├ELK║═HadoopüĒĮŌøQĪŻĄ┌╦─╩ŪŽ¹│²å╬³cŻ¼▀@ę╗ēK┐╔ęįĮĶų·LVS+HaproxyĪŻį┌ė▓╝■ĘĮ├µŻ¼ļpļŖį┤ĪóļpļŖ┴”ĪóČÓ▀\ĀI╔╠ĪóļpĮ╗ōQÖCĪóļpÖC╣±ĪóČÓÖCĘ┐▀@ą®┼õų├Ż¼ąĶę¬Ė∙ō■śIäš▓╗═¼Ą─░lš╣ļAČ╬ū÷ÖÓ║ŌŻ¼üĒ▀Mąą▀xō±ĪŻ
▀\ŠSĄ─ųĖī¦╦╝┬Ę

▀\ŠSĄ─ųĖī¦╦╝┬ĘĪŻ╩ūŽ╚╩Ū┼c╚╦¤oĻPŻ║ę¬īóÖCŲ„žō▌dŠ∙║Ōū÷Ą├ØL╣ŽĀĆ╩ņĪŻė├─_▒ŠĪóPlaybookū÷ÖCŲ„╔·│╔Ż¼Ė·╚╦¤oĻPĪŻŲõČ■╩Ū┼c╝║¤oĻPŻ║ę¬╔ߥ├░č¢|╬„Į╗│÷╚źĮoŽ┬ī┘ū÷Ż¼ūį╝║▓╗öÓīW┴Ģą┬Ą─¢|╬„ĪŻĄ┌╚²╩Ū┼cĀŅæB¤oĻPŻ║▀\ŠSę¬ū÷¤oĀŅæB║═öUš╣ąįŻ¼ėąą®│╠ą“åT║▄Ž▓ÜgėąĀŅæBŻ¼▀@Š═ę¬┐╝“×─ŃĪó╣ż│╠Ĥ║═CTOĄ──▄┴”Ż¼═Ųäė│╠ą“åT╚źū÷ĪŻūŅ║¾ę╗³c╩Ū┼cöĄ┴┐¤oĻPŻ║ę¬ū÷▓┐╩Ą─║ŃČ©Ż¼▀\ŠSįÆšZÖÓĄ─į÷ķLŻ¼║▄ČÓĢr║“╩Ūį┌śIäš═╗’w├═▀MĢrŻ¼▀\ŠS│╔▒Š╚į▒Ż│ų▓╗ūāŻ¼ūį╝║į┌└Ž░Õą─ųąĄ─═■ą┼Š═Ģ■╠ß╔²ĪŻ
▀\ŠSĄ─ą▐¤Æ

ĻPė┌▀\ŠSĄ─ą▐¤ÆĪŻ╩ūŽ╚╩Ūę¬ķeŽ┬üĒŻ¼ČÓšŲ╬š╝╝ągŻ╗Ųõ┤╬╩Ūū▀│÷╚źŻ¼ČÓģó╝ė╗ŅäėŻ¼ČÓ╗źŽÓīW┴ĢĪóĮ╗▓µĘųŽĒŻ╗Ą┌╚²╩ŪČÓå¢×ķ╩▓├┤Ż¼īW╦╝ĮY║ŽŻ¼šŲ╬šĖ³ČÓą┼ŽóŻ¼īWęįų┬ė├ĪŻČ°ūį╝║ųvĄ─¢|╬„ę¬╔Ņ╚ļ£\│÷Ż¼╦∙ėą╚╦Č╝┬ĀĄ├Č«ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║įŲ▀\ŠSĄ─åó╩Š┼c╝▄śŗįOėŗ
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839720014.html