



▒Š┤╬ĘųŽĒīóų„ę¬ĮķĮB░ó└’įŲ╩Ū╚ń║╬įOėŗįŲöĄō■Äņ«aŲĘĄ─╝▄śŗĄ─Ż¼ęį╝░į┌įŲöĄō■Äņ«aŲĘĄ─╝▄śŗįOėŗ▒│║¾Ą─╣╩╩┬ĪŻ▒Š┤╬Ą─ĘųŽĒīó▓╗Ģ■ĘŪ│Ż╔Ņ╚ļ╝╝ągĄūīė╝Ü╣ØŻ¼Č°╩ŪŽŻ═¹═©▀^ĘųŽĒ╩╣Ą├┤¾╝ę┴╦ĮŌį┌╩╣ė├įŲöĄō■ÄņĢræ¬įō╚ń║╬╚źęÄäØŻ¼ęį╝░░ó└’įŲį┌įOėŗįŲöĄō■Äņ«aŲĘĄ─Ģr║“┤µį┌╩▓├┤śėĄ─╦╝┐╝ĪŻ
ę╗ĪóįŲöĄō■ÄņĄ─╩ął÷▒│Š░
ČÓ«aŲĘŅÉą═╗ņ║Ž
į┌╩ął÷╔Ž├µŻ¼┤¾╝ę┐╔ęį┐┤ĄĮŅÉą═ĘŪ│ŻČÓśėĄ─öĄō■Äņ«aŲĘĪŻ╚ń╣¹┤¾╝ęĮ±╠ņ▀Ć╩Ūį┌╩╣ė├Ž±SQL Server╗“š▀MySQL▀@śėå╬¬ÜĄ─ĻPŽĄą═öĄō■ÄņŻ¼─Ū├┤┐╔─▄śIäš╦∙Ė▓╔wĄ─ł÷Š░▀Ć╩Ū▒╚▌^ėąŽ▐Ą─ĪŻČ°═∙═∙į┌ę╗╝ęųąą═╗“š▀▒╚▌^┤¾ą═Ą─╣½╦Š└’├µŻ¼ęčĮøķ_╩╝ė├ĄĮ║▄ČÓ▓╗═¼Ą─öĄō■Äņ«aŲĘ┴╦ĪŻ

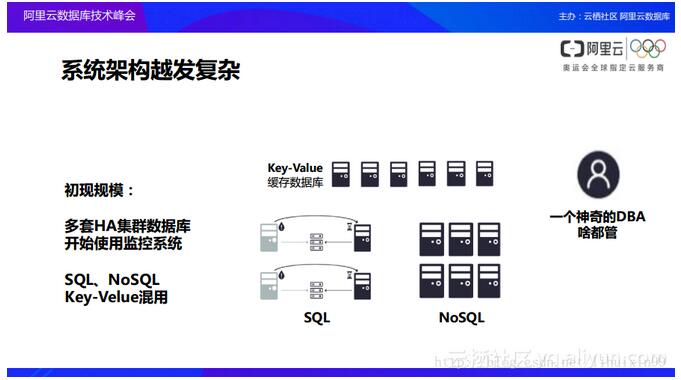
ŽĄĮy╝▄śŗįĮ░lÅ═ļs
╚ń╔ŽłD╦∙╩ŠŻ¼═©│ŻŪķørŽ┬Ż¼į┌śIäšäéķ_╩╝Ą─Ģr║“╩╣ė├Ą─╩Ūę╗éĆSQLöĄō■Äņ╗“š▀NoSQLöĄō■ÄņŻ¼Ą½╩ŪļSų°śIäš┬²┬²Ą─░lš╣Š═Ģ■ė├ĄĮKey-ValueĄ─ŠÅ┤µöĄō■ÄņŻ¼į┘ų«║¾┐╔─▄Š═Ģ■░lš╣ĄĮöĄō■é}ÄņŻ¼═¼Ģrę▓┐╔─▄░lš╣ĄĮ┤¾öĄō■Ą─ŽĄĮyĪŻ
ĮėŽ┬üĒ×ķ┤¾╝ęĮķĮBę╗╝ę╣½╦ŠÅ─ąĪą═Ų¾śIų▓Į│╔ķL×ķ┤¾ą═Ų¾śIĄ─▀^│╠ųąĄ─öĄō■Äņ╝▄śŗįOėŗĄ─░lš╣▓Į¾Eęį╝░į┌▀\ū„▀^│╠ųą├┐éĆļAČ╬Ą─öĄō■Äņč▌╗»ŪķørĪŻ╚ńŽ┬łD╦∙╩ŠŻ¼į┌│§╩╝ļAČ╬Ż¼š¹éĆöĄō■Äņ╝▄śŗĄ─ĮYśŗ╩Ū▒╚▌^║åå╬Ą─Ż¼łDųąāHėą3┼_Ę■äšŲ„Ż¼▀@ęŌ╬Čų°╣½╦Šį┌äéäéķ_╩╝Ą─Ģr║“┐╔─▄ų╗ėąÄū┼_öĄō■ÄņĘ■äšŲ„Ż¼╦³éā┐╔─▄╩ŪSQLĄ─ŽĄĮyŻ¼ę▓┐╔─▄╩ŪNoSQLĄ─ŽĄĮyĪŻ┤╦ĢrDBAęį╝░╣▄└Ē╚╦åT▓╗ąĶę¬╚źū÷▀^ČÓĄ─ĮYśŗ╩╣ė├Ęų╬÷ĪŻ╚╗Č°Ż¼į┌▀Mąą╣▄└ĒĄ─▀^│╠ųąŻ¼DBA═∙═∙Ģ■╔Ē╝µČÓ┬ÜŻ¼į┌▀@éĆĢr║“Ą─DBA┐╔─▄į┌╣▄└ĒöĄō■ÄņĄ─═¼Ģrę▓į┌ū÷ķ_░lęį╝░ī”ė┌▓┘ū„ŽĄĮyĄ─▀\ŠS╣żū„ĪŻ

Ė³▀Mę╗▓ĮŻ¼«öŲ¾śI░lš╣ĄĮ│§Š▀ęÄ─ŻĄ─Ģr║“Ż¼öĄō■Äņ═∙═∙Š═▓╗─▄ē“ęįå╬╣سcĄ─ĘĮ╩Į╚ź▀\ąą┴╦Ż¼┤╦Ģr═∙═∙ąĶę¬┼õ║Žę╗ą®╝»╚║ęį╝░ę╗ą®Ųõ╦¹Ą─öĄō■ÄņĪŻ└²╚ńį┌äéäéķ_╩╝Ą─Ģr║“Ż¼ų╗ė├ĄĮ┴╦å╬¬ÜĄ─SQLöĄō■Äņęį╝░NoSQLöĄō■ÄņŻ¼Ą½╩Ūį┌ŽĄĮy│§Š▀ęÄ─ŻĄ─Ģr║“Ż¼┐╔─▄ā╔ĘĮ├µĄ─öĄō■ÄņČ╝Ģ■ė├ĄĮŻ¼═¼Ģr▀Ć┐╔─▄Ģ■ė├ĄĮŽ±Key-ValueŠÅ┤µöĄō■ÄņĄ╚▀Mąą╗ņ║ŽüĒīŹ¼Fš¹¾wĄ─öĄō■ÄņśIäšą¦╣¹ĪŻį┌▀@éĆ▀^│╠ų«ųąŻ¼DBA░ńč▌ų°ĘŪ│Ż╔±ŲµĄ─ĮŪ╔½Ż¼┤╦ĢrĄ─DBA▓╗ų╗ąĶę¬╚źū÷Ųš═©Ą─SQLŽĄĮy╣▄└ĒŻ¼Č°Ūę▀ĆąĶę¬╣▄└ĒNoSQLęį╝░Key-ValueöĄō■ÄņŻ¼Č°Ūę║▄ČÓĢr║“š¹¾wŽĄĮy▒O┐žęį╝░ŽĄĮyŠSūoČ╝ąĶę¬ė╔DBA▀Mąą═Ļš¹Ąžų¦ō╬Ż¼┤╦ĢrĄ─DBA┐╔ęįĘQų«×ķ“╔±ŲµĄ─DBA”Ż¼ę“×ķ╦¹╩▓├┤Č╝ąĶę¬╣▄ĪŻ
«öśIäš▀Mę╗▓Į░lš╣ĄĮŽ┬ę╗éĆļAČ╬ĢrėųĢ■╩Ū╩▓├┤Ūķør─žŻ┐ŲõīŹ║▄ČÓ╣½╦Šį┌äéäéŲ▓ĮĢr═∙═∙ų╗ėąę╗éĆĒŚ─┐Ż¼«ö╣½╦ŠĄ─śIäš░lš╣ĄĮę╗Č©ęÄ─ŻĄ─Ģr║“Ż¼ĒŚ─┐ę▓Ģ■ų▓ĮĄžį÷╝ėĪŻę“┤╦Ż¼├┐ę╗éĆĒŚ─┐Č╝īóĢ■╩╣ė├ę╗š¹╠ūöĄō■ÄņĮYśŗŻ¼Č°į┌▀@éĆĢr║“ĒŚ─┐ę▓Ģ■▓╗öÓĄž╠ß╔²║═į÷ķLŻ¼├┐éĆĒŚ─┐Ģ■╩╣ė├å╬¬Üš¹¾wöĄō■ÄņĮYśŗŻ¼▀@Ģr║“Ą─öĄō■Äņ╣▄└ĒåTDBAŠ═▓╗į┘╩Ūå╬éĆ╚╦┴╦Ż¼═∙═∙Ģ■ėą2ĄĮ3éĆDBAŻ¼Č°Ūę╦¹éā├┐éĆ╚╦æ¬įōČ╝─▄ē“¬Ü«öę╗├µŻ¼▓óŪęæ¬įōŠ▀ėą═Ļš¹Ą─╝▄śŗĮø“×ĪŻš²╩Ūį┌▀@éĆĢr║“▓┼╩Ūī”ė┌Ų¾śIĄ─▒╚▌^┤¾Ą─╠¶æŻ¼┤¾╝ęČ╝ų¬Ą└į┌╝╝ąg╚╦åTĄ─┬ÜśI░lš╣╔·č─«öųąŻ¼╝╝ąg╚╦åTČ╝╩ŪŽŻ═¹─▄ē“│ą▌dĖ³ČÓĄ─╣żū„╗“š▀ūīūį╝║Ą─┬ÜśI╔·č─½@Ą├Ė³┤¾Ą─░lš╣Ż¼╦∙ęįį┌▀@éĆ▀^│╠ų«ųą═∙═∙─▄ē“ą╬│╔Ų¾śI┼c╝╝ąg╚╦åT▒Š╔Ēų«ķgšJų¬▓Ņ«ÉĄ─▓®▐─ĪŻ║▄ČÓĢr║“╚ń╣¹Ų¾śI░lš╣Ą─╦┘Č╚Ė·▓╗╔Ž╝╝ąg╚╦åTĄ─╝╝ąg│╔ķL╦┘Č╚Ż¼╝╝ąg╚╦åTŠ═║▄┐╔─▄ćLįć╠°▓█╗“š▀īżšęŲõ╦¹Ą─╣żū„Ż¼«ö╝╝ągīŻ╝ęļxķ_Ų¾śIĄ─Ģr║“Ż¼Š═Ģ■╩╣Ą├Ų¾śIĄ─▀Mę╗▓Į░lš╣╩▄ĄĮūĶĄKĪŻ
öĄō■Äņ╚▌×─Ż║ā╔ĄžNųąą─
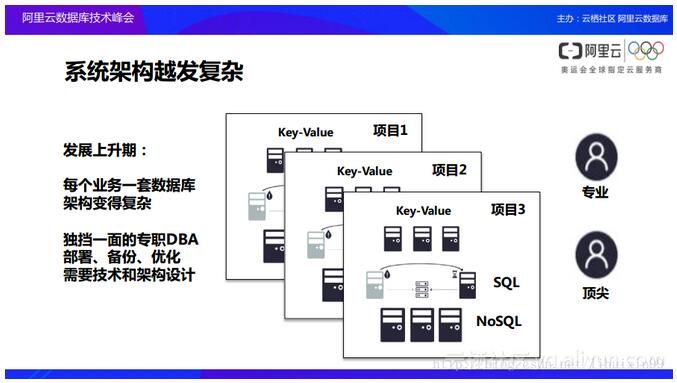
į┌ŽĄĮy╝▄śŗįĮ░lÅ═ļsĄ─ŪķørŽ┬Ż¼Ų¾śI╦∙ė÷ĄĮĄ─▓╗āH╩Ū╚╦åTĄ─å¢Ņ}Ż¼į┌▀MąąöĄō■Äņ╝▄śŗ░lš╣č▌ūāĄ─▀^│╠«öųąŻ¼Ų¾śI▀ĆĢ■ė÷ĄĮ┴Ē═ŌĄ─ę╗éĆå¢Ņ}Ż║į┌śIäš░lš╣ĄĮę╗Č©ļAČ╬ų«║¾Ż¼═∙═∙ąĶꬫa╔·Ė³ČÓĄ─öĄō■╝▄śŗĄ─▀ē▌ŗŻ¼░³└©į┌śIäšę¬Ū¾ų«Ž┬ęį╝░į┌▒O╣▄▓┐ķTĄ─ę¬Ū¾ų«Ž┬Ż¼┐╔─▄ąĶę¬īŹ¼FŽ±ā╔Ąž╚²ųąą─Ą╚Ą╚ę╗ŽĄ┴ąÅ═ļsĄ─╝▄śŗŻ¼▀@ę▓Ģ■╩╣Ą├śI䚥─▀\ąą│╔▒Š│╔▒ČĄž╠ßĖ▀ĪŻę“×ķį┌å╬¬ÜĄ─ÖCĘ┐ų«Ž┬▀MąąöĄō■Äņ╝»╚║Ą─┤ŅĮ©Ģ■╩Ū▒╚▌^ĘĮ▒ŃĄ─Ż¼Č°į┌īŹ¼FŽ±ā╔Ąž╚²ųąą─▀@śėĄ─╝▄śŗĄ─Ģr║“Ż¼▀ĆąĶę¬╚ź┘Å┘I═¼│Ū╣Ō└węį╝░«ÉĄž╣Ō└wĄ╚Ą╚╗∙ĄAįO╩®Ż¼▀@▓┐Ęų┤¾┴┐Ą─┘Mė├ę▓═∙═∙╩╣Ą├║▄ČÓĄ─Ų¾śIį┌▀@śėĄ─╬╗ų├╔Ž╠Äė┌═Ż▓ĮĀŅæBĪŻ
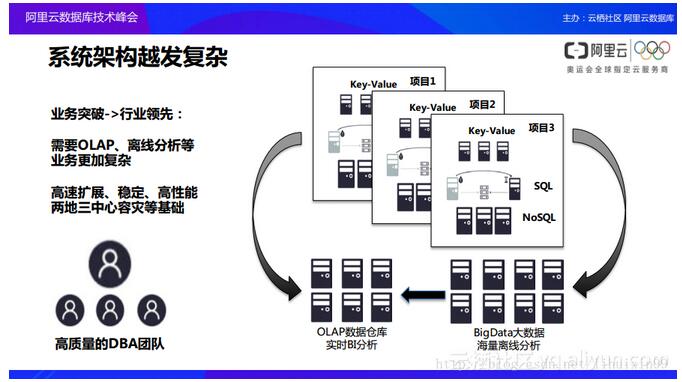
╚ń╣¹Ų¾śIŽŻ═¹─▄ē“▀Mę╗▓ĮĄž═╗ŲŲ░lš╣Ų┐Ņi═∙═∙▀ĆąĶę¬╩╣ė├Ė³ČÓĄ─öĄō■Äņ╝▄śŗŻ¼└²╚ńąĶę¬╩╣ė├ĄĮOLAPĄ─öĄō■Äņé}Äņęį╝░┤¾öĄō■Ą─║Ż┴┐Ęų╬÷Ą╚ĪŻį┌▀@śėĄ─ŪķørŽ┬Ż¼DBAłFĻĀęį╝░š¹¾wŽĄĮyĄ─śŗĮ©│╔▒ŠČ╝īóĢ■Ė³┤¾Ąž╠ß╔²ĪŻ
░ó└’įŲ įŲöĄō■ÄņŻ║«aŲĘ└Ē─Ņ
Ū░├µ×ķ┤¾╝ęĮķĮB┴╦ę╗éĆŲ¾śIÅ─ąĪą═ĄĮųąą═╗“š▀šf╩ŪĄĮ▀_▒¼░lŲ┌ęį╝░Ė³▀Mę╗▓ĮĄ─╔Ž╔²Ų┌Ą─▀^│╠ų«ųąŻ¼ī”ė┌öĄō■Äņ┐╔─▄Ģ■│÷¼F╩▓├┤śėĄ─ę¬Ū¾ĪŻĮėŽ┬üĒ×ķ┤¾╝ęĘųŽĒį┌░ó└’įŲĄ─įŲöĄō■ÄņųąŽŻ═¹×ķ┤¾╝ę╠ß╣®╩▓├┤śėĄ─«aŲĘ└Ē─ŅĪŻ
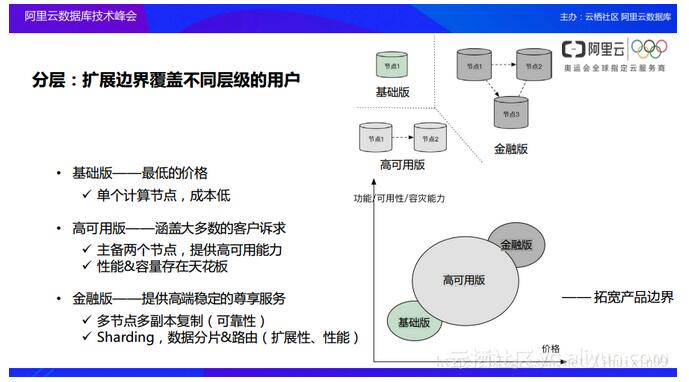
╩ūŽ╚Ż¼┤¾╝ę┐╔ęį┐┤ĄĮį┌śIäšĖ„éĆ▓╗═¼Ą─░lš╣▀^│╠«öųąąĶę¬╩╣ė├ĄĮ▓╗═¼Ą─öĄō■ÄņĪóöĄō■ÄņĄ─ĮM║Žęį╝░▓╗═¼Ą─öĄō■Äņ«aŲĘĄ─īė╝ēŻ¼ę“┤╦░ó└’įŲĢ■įOėŗūį╝║Ą─öĄō■Äņ«aŲĘūī▓╗═¼Ą─īė╝ēČ╝┐╔ęį▀mė├ĪŻ
Ą┌Č■³cŻ¼░ó└’įŲĢ■▒M┐╔─▄Ąž╚źÄ═ų·Ų¾śI╠ßĖ▀ūį╔ĒĄ─░lš╣ą¦┬╩Ż¼ę▓Š═╩ŪūīŲ¾śIĘŪ│ŻĘĮ▒ŃĄžöUš╣ūį╝║Ą─┘Yį┤Ż¼ūī▀@ą®┘Yį┤×ķė├æ¶ų▒Įė╠ß╔²╔·«aą¦┬╩ĪŻ
Ą┌╚²³cŻ¼░ó└’įŲĢ■ų▒ĮėĮĄĄ═š¹éĆ╝▄śŗĄ─śŗĮ©ķTÖæŻ¼į┌é„ĮyŲ¾śI╝▄śŗų«Ž┬Ż¼Å─å╬éĆÖCĘ┐ūāĄĮČÓéĆÖCĘ┐╗“š▀Å─å╬éĆĘ■äšŲ„ūā×ķČÓéĆĘ■äšŲ„Ą─Ģr║“Ż¼Ģ■┤µį┌║▄ČÓ╝╝ągęį╝░╔·«a│╔▒ŠĄ─ķTÖæŽ▐ųŲŻ¼░ó└’įŲŽŻ═¹─▄ē“═©▀^įŲöĄō■Äņš¹¾wĄ─Ąūīė╝▄śŗŻ¼░³└©’w╠ņ╝▄śŗīó▀@ą®ķTÖæĮĄĄĮūŅĄ═ĪŻ
ūŅ║¾ę¬╠ߥĮĄ─ę▓╩Ū▒Š┤╬ųąūŅŽŻ═¹ĘųŽĒĄ─ę╗³cŠ═╩ŪŻ║į┌įŲöĄō■Äņų«╔ŽŻ¼░ó└’įŲ╦∙ŽŻ═¹▀_ĄĮĄ─ĮKśO─┐ś╦╩ŪĮŌĘ┼DBAĪŻŲõīŹ═©│ŻŪķørŽ┬į┌ę╗╝ę╣½╦Š└’├µŻ¼DBA║▄ČÓĢr║“═∙═∙▓╗Ģ■╩▄ĄĮ║▄┤¾Ą─ųžęĢŻ¼ę“×ķį┌Ų¾śIųąDBA╚š│Ż╦∙ū÷Ą─╣żū„═∙═∙╩ŪŽ±▓┐╩ĪóéõĘ▌Ą╚Ą╚ę╗ŽĄ┴ą▀\ŠS╣żū„Ż¼Č°▀@ą®╣żū„īóĢ■š╝ō■DBA 50%ĄĮ60%Ą─ĢrķgŻ¼Č°▀@ą®╣żū„ģsø]ėą▐kĘ©╚ź×ķŲ¾śIĦüĒų▒ĮėĄ─╔·«aą¦┬╩ĪŻČ°į┌įŲöĄō■Äņ╔Ž├µŻ¼═©▀^įŲ╝▄śŗĄ─ūįäė╗»╣▄└ĒüĒ═Ļ│╔╦∙ėąĄ─▀\ŠS╣żū„Ż¼DBA┐╔ęįīóūį╝║Ė³ČÓĄ─Ģrķg═Č╚ļĄĮśIäš╝▄śŗĄ─ā×╗»ų«ųąĪŻ╩▓├┤╩ŪśIäš╝▄śŗĄ─ā×╗»─žŻ┐▒╚╚ń▒ĒĮYśŗįOėŗĄ─▓╗║Ž└ĒąĶę¬▀Mąąā×╗»Ż¼ę╗ą®SQL┤µį┌ąį─▄å¢Ņ}ąĶę¬ā×╗»Ż¼ęį╝░─│ą®įOėŗį┌śIäš░lš╣Ą─▀^│╠ųąęčĮø▓╗║ŽĢrę╦ąĶę¬ā×╗»Ż¼╦∙ėąĄ─▀@ą®ā×╗»Č╝╩ŪDBAæ¬įō╚źū÷Ą─ĪŻČ°DBAę▓╩ŪūŅ╚▌ęū░lš╣│╔×ķŲ¾śI║╦ą─╝▄śŗĤĄ─ę╗╚║╚╦Ż¼╦¹éāĄ─╣żū„æ¬įōĖ³ČÓĄž×ķŲ¾śIšµš²Ąž«a─▄ęį╝░╝╝ąg─▄┴”Ą─▌ö│÷░lō]žĢ½IŻ¼Č°▓╗╩Ū╚ź▀^ČÓĄžĻPūó├┐ę╗╠ņĄ─▓┐╩ĪóéõĘ▌▀@śėĘ▒¼ŹĄ─▀\ŠS╣żū„ĪŻ
ęį╔ŽŠ═╩Ūį┌įOėŗįŲöĄō■Äņ▀^│╠ųąŻ¼┤¾╝ę╦∙┐┤ĄĮĄ─╩ął÷ąĶŪ¾Ūķøręį╝░░ó└’įŲĄ─įŲöĄō■Äņ«aŲĘįOėŗ└Ē─ŅĪŻ
Č■Īóė└║Ń▓╗ūāĄ─įÆŅ}Ż║ąĶŪ¾
ŲõīŹŪ░├µ╦∙ųvĄ─ķLŲ¬╣╩╩┬Č╝╩ŪąĶŪ¾Ż¼├┐ę╗éĆąĶŪ¾Č╝ąĶꬥ├ĄĮØMūŃĪŻ─Ū├┤├µī”▀@ą®ąĶŪ¾Ż¼░ó└’įŲĄ─įŲöĄō■Äņ╩Ū╚ń║╬ę╗▓Įę╗▓ĮĮŌøQĄ──žŻ┐
ĘųīėŻ║öUš╣▀ģĮńĖ▓╔w▓╗═¼īė╝ēĄ─ė├æ¶
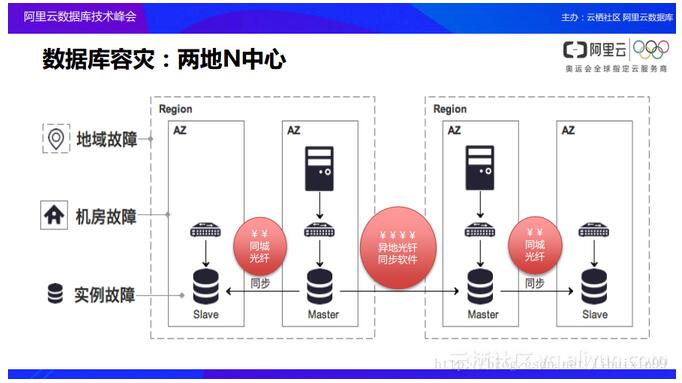
Ą┌ę╗▓ĮŠ═╩Ū▀MąąĘųīėĪŻų«Ū░╩╣ė├▀^░ó└’įŲöĄō■ÄņĄ─┼¾ėč┐╔─▄Ģ■ėąėĪŽ¾Ż¼░ó└’įŲūŅ│§═Ų│÷Ą─öĄō■Äņ░µ▒ŠĮąū÷Ė▀┐╔ė├░µ▒ŠŻ¼▀@æ¬įōę▓╩Ū«öŪ░░ó└’įŲöĄō■Äņ└’├µ╩╣ė├┴┐ūŅČÓĄ─░µ▒ŠĪŻį┌▀@éĆ░µ▒Š└’├µĢ■ėąā╔éĆöĄō■ÄņĘ■äšŲ„Ż¼ę╗ų„ę╗éõŻ¼╦¹éā╠ß╣®┴╦ĘŪ│Ż║├Ą─ąį─▄▓óŪę─▄ē“┐ņ╦┘Ąž▀MąąŪąōQŻ¼╚╗Č°į┌▀@śėĄ─╝▄śŗų«Ž┬Ż¼│╔▒ŠīŹļH╔ŽĘŁ┴╦ę╗▒ČĪŻ║▄ČÓĄ─ė├æ¶Ż¼╠žäe╩Ū╚ļķT╝ēäeĄ─äéķ_╩╝╩╣ė├įŲöĄō■ÄņĄ─ė├æ¶Ż¼═∙═∙▓╗ąĶę¬ų„éõĄ─öĄō■ÄņŽĄĮyŻ¼Č°╩ŪŽŻ═¹═Č╚ļĖ³Ą═Ą─│╔▒ŠŻ¼▀@éĆĢr║“░ó└’įŲŠ══Ų│÷┴╦įŲöĄō■ÄņĄ─╗∙ĄA░µĪŻ╗∙ĄA░µĄ─╝▄śŗų╗ėąå╬éĆ╣سcŻ¼╗∙ĄA░µĄ─═Ų│÷╩╣Ą├ė├æ¶Ą─│╔▒ŠĄ├ęįĮĄĄ═ĪŻ═¼ĢrąĶę¬ūóęŌĄ─ę╗³cŠ═╩ŪŻ║į┌å╬╣سc╗“š▀šf╩Ū╗∙ĄA░µų«Ž┬Ż¼Ė▀┐╔ė├ĄĮĄū╩Ū╚ń║╬▒ŻšŽĄ─ĪŻŲõīŹ┤¾╝ę┐╔ęįĘ┼ą─Ż¼į┌╗∙ĄA░µų«Ž┬Ż¼░ó└’įŲ═¼śė╠ß╣®┴╦Ė▀┐╔ė├Ą─▒ŻšŽŻ¼ų╗▓╗▀^ø]ėąā╔éĆ╣سcĄ─▒ŻšŽČ°╩Ūīóš¹éĆöĄō■Äņ▀\ąąį┌’w╠ņ╝▄śŗų«╔ŽŻ¼╚ń╣¹öĄō■Äņ│÷¼Få¢Ņ}╗“š▀öĄō■Äņ╦∙į┌Ą─ų„ÖC│÷¼F┴╦å¢Ņ}Ż¼’w╠ņŽĄĮyĢ■ūįäėīżšęą┬Ą─ų„ÖCĪóą┬Ą─╣سcīóš¹éĆŽĄĮy▀\ąąŲüĒŻ¼ų╗▓╗▀^ŪąōQĢrķgĢ■╔į╬óķLę╗ą®Ż¼Ą½╩Ū▓╗Ģ■│÷¼FŽ±ŽĄĮyķLŲ┌öÓķ_Ą─ŪķørĪŻ
į┘▀Mę╗▓ĮŻ¼║▄ČÓĖ▀╝ēė├æ¶Ż¼╠žäe╩Ūį┌Į╚┌ĮńųąĄ─ė├æ¶╦∙ę¬Ū¾Ą─öĄō■ĘĆČ©ąįęį╝░ī”ė┌öĄō■╣╩šŽĢrĄ─RPOČ╝Ģ■ėąĖ³Ė▀Ą─ę¬Ū¾Ż¼▀@Ģr║“░ó└’įŲŠ═╠ß╣®┴╦Į╚┌░µöĄō■ÄņĪŻį┌ā╔╣سcĄ─╗∙ĄAų«╔Ž┐╔─▄Ģ■öUš╣ĄĮ╚²╣سc╔§ų┴Ė³ČÓ╣سcĄ─╝»╚║Ą─æ¬ė├ĪŻį┌ū÷┴╦▀@śėĄ─╣żū„ų«║¾Ż¼░ó└’įŲīŹļH╔Ž╩Ū═žš╣┴╦įŲöĄō■Äņ«aŲĘĄ─▀ģĮńŻ¼Å─äéķ_╩╝░ó└’įŲöĄō■Äņų╗ėąĖ▀┐╔ė├ļp╣سc░µ▒ŠŻ¼öUš╣ĄĮå╬╣سcĄ─╗∙ĄA░µęį╝░ČÓ╣سcĄ─Į╚┌░µŻ¼╩╣Ą├▓╗═¼ąĶŪ¾Ą─ė├æ¶┐╔ęį½@╚ĪĄĮ╦¹éā╦∙ąĶꬥ─Ė„ĘN▓╗═¼ęÄĖ±Ą─įŲöĄō■ÄņĘ■äšĪŻ
ą¦┬╩Ż║╗»Ę▒×ķ║åŻ¼ßīĘ┼╣żū„┴┐
į┌ėą┴╦öĄō■ÄņĄ─▀\ąąŁhŠ│ų«║¾Ż¼ŲõīŹ┤¾╝ę┐╔ęį┐┤ĄĮĖ„éĆė├æ¶═∙═∙Č╝Ģ■ėąūį╝║▓╗═¼ĢrČ╬Ą─ŅÉ╦Ųė┌┤┘õNĪó╗ŅäėĄ╚Ą─ę╗ą®śI䚯¼į┌▀@ą®śIäšų«ųąŻ¼ė├æ¶Ą─▓ķįāę¬Ū¾═∙═∙╩ŪĘŪ│ŻĖ▀Ą─Ż¼Ģ■│÷¼FĘŪ│ŻĖ▀Ą─▓ķįāĘÕųĄŻ¼▀@Ģr┐╔ęį═©▀^ų╗ūx╣سcüĒ▀MąąĮŌøQĪŻį┌░ó└’įŲųąŠ═ų▒Įė╠ß╣®┴╦ų╗ūxšłŪ¾Ą─īŹ└²Ż¼Č°▓╗ąĶę¬ė├æ¶ūį╝║į┘╚ź┤ŅĮ©ų╗ūxīŹ└²┴╦ĪŻ╚ń╣¹┤¾╝ęūį╝║┤ŅĮ©▀^öĄō■ÄņŻ¼Š═┐╔─▄ī”ė┌▀@éĆ▀^│╠ėą╦∙¾wĢ■Ż¼«ö┤ŅĮ©ę╗éĆų╗ūxīŹ└²Ģr═∙═∙ąĶę¬╚źśŗĮ©╗“š▀┼õų├3ĄĮ4éĆ┼õų├╬─╝■Ż¼Č°ŪęĖ„éĆų„ÖCų«ķgŻ¼░³└©ė├æ¶ÖÓŽ▐ęį╝░├▄┤aĄ─═¼▓ĮĄ╚Č╝ąĶę¬▀MąąęÄäØŻ¼▀@éĆ▀^│╠ī”ė┌│§╝ēĄ─DBAČ°čį╩Ū▒╚▌^└¦ļy║═┬ķ¤®Ą─╩┬ŪķŻ¼Č°Ūę┼c┤╦═¼Ģr▀ĆąĶę¬▒ŻšŽš¹éĆŽĄĮyį┌śIäš░lš╣Ą─▀^│╠ųąĄ─ĘĆČ©▀\ąąĪŻ

į┌░ó└’įŲ╔Ž├µŻ¼īŹļH╔ŽĢ■īóśŗĮ©ų╗ūxīŹ└²Ą─▀^│╠Ė³╝ė║å╗»Ż¼ę“×ķ░ó└’įŲöĄō■Äņ▒Š╔ĒĄ─ĄūīėŽĄĮy╝▄śŗĢ■ūįäė╗»Ąž▀Mąą╦∙ėąĄ─┼õų├ęį╝░śIäš┤_šJŻ¼ė├æ¶ų╗ąĶę¬į┌Įń├µ╔Ž├µ³cō¶░┤Ōo▓ó╠Ē╝ėę╗éĆų╗ūxīŹ└²Š═─▄ē“īóų╗ūxīŹ└²Į©┴ó═Ļ│╔Ż¼Č°Ūęį╩įSė├æ¶Į©┴ó5éĆ╔§ų┴10éĆų╗ūxīŹ└²ĪŻį┌▀@éĆ▀^│╠ųąŻ¼┤¾╝ęĢ■░l¼Fļm╚╗░ó└’įŲ╠ß╣®┴╦ų▒Įė╠Ē╝ėų╗ūxīŹ└²Ą─╣”─▄Ż¼Č°Ūę═Ļ│╔┴╦ŲõųąĄ─═¼▓ĮŻ¼Ą½╩ŪśIäšĘĮę▓Š═╩Ū╚ń╔ŽłD╦∙╩ŠĄ─įŲĘ■äšŲ„ECS╔Ž├µĄ─æ¬ė├▀Ć╩ŪąĶę¬═©▀^░čūxīæšłŪ¾║═ų╗ūxšłŪ¾▀MąąśIäšĘųļxŻ¼▀@ī”ė┌öĄō■ÄņĄ─ķ_░l╩Ū┤µį┌╚ļŪųąįĄ─Ż¼ę▓Š═╩ŪšfįŁüĒķ_░lĄ─│╠ą“ų╗ąĶę¬ę╗éĆöĄō■Äņ▀Mąą▓┘ū„Š═┐╔ęį┴╦Ż¼Č°ė╔ė┌«öŪ░╩╣ė├┴╦ų╗ūxīŹ└²Ż¼ätąĶę¬īó╦∙ėąĄ─ų╗ūx▓ķįāČ╝å╬¬ÜĄž┴Ó│÷üĒūīŲõ╚źįLå¢Ųõ╦¹╣سcŻ¼▀@ę╗³cī”ė┌│╠ą“Ą─╚ļŪųąį┐╔─▄Ģ■╩ŪĘŪ│Ż┤¾Ą─Ż¼▀@Š═┐╔─▄Ģ■╩╣Ą├║▄ČÓĄ─ķ_░lš▀¤oĘ©ų▒Įė╩╣ė├ĄĮ░ó└’įŲĄ─ų╗ūxīŹ└²┴╦Ż¼╗“š▀ėą║▄ČÓĄ─╣żū„ąĶę¬ųžą┬▀Mąąķ_░lĪŻ
ą¦┬╩Ż║ ╗»Ę▒×ķ║åŻ¼ßīĘ┼╣żū„┴┐Ż¼ ų▒Įėų¦│ųūxīæĘųļx
ßśī”╔Ž╩÷Ą─å¢Ņ}Ż¼░ó└’įŲĄ─öĄō■Äņį┌░lš╣Ą─▀^│╠ųąę▓Ģ■╩šĄĮė├æ¶Ą─ąĶŪ¾║═ł¾ĖµŻ¼ę“┤╦░ó└’įŲöĄō■ÄņŠ═▀Mąą┴╦▀Mę╗▓ĮĄ─ā×╗»ĪŻį┌ų╗ūxīŹ└²Ą─▀\ąąŚl╝■ų«Ž┬Ż¼░ó└’įŲöĄō■Äņ▀Ć▀Mę╗▓ĮĄž╠ß╣®┴╦ūxīæĘųļxĄ─IPįLå¢Ż¼Ųõų„ę¬Ģ■į┌ProxyśIäšīėĄūŽ┬īŹ¼F╦∙ėąSQLĄ─╩š╝»Ż¼▓óŪęī”ė┌╦∙ėąĄ─╩š╝»ĄĮĄ─SQL▀MąąĘųŅÉŻ¼╚ń╣¹░l¼FSQL▓┘ū„╝╚ėąūx▓┘ū„ę▓ėąīæ▓┘ū„Ą─Ģr║“Ż¼ę▓Š═╩Ūūxīæ▓┘ū„į┌═¼ę╗éĆ╩┬äš└’├µĄ─Ģr║“Ż¼Ģ■īó▀@ą®▓┘ū„ūįäėĄž╠ßĮ╗ĄĮų„╣سcĪŻČ°╚ń╣¹«ö░l¼F╩┬äšųą╦∙ėąĄ─▓┘ū„Č╝╩Ūūx▓┘ū„Ą─Ģr║“Ż¼ProxyīėŠ═Ģ■īó▀@ą®ų╗ūxĄ─▓ķįāŲĮŠ∙ĄžĘų┼õĄĮĖ„éĆų╗ūx╣سcĪŻ▀@ęŌ╬Čų°æ¬ė├│╠ą“▓╗ąĶę¬Ė─ūā▒Š╔ĒĄ─┤·┤aŻ¼░ó└’įŲŠ═─▄ē“ūįäėĄž×ķė├æ¶īŹ¼FūxīæĘųļxĄ─╣żū„Ż¼Č°śIäšĘĮ▓╗ąĶę¬╚źą▐Ė─ūį╝║Ą─śIäš┤·┤aĪŻ═©▀^▀@śė▓ķįāĄ─ūxīæĘųļxĄ─╣”─▄Ż¼┐╔ęįĘŪ│Ż║├Ąž║å╗»▒Š╔Ēķ_░lęį╝░ŠSūoĄ─╣żū„┴┐ĪŻ
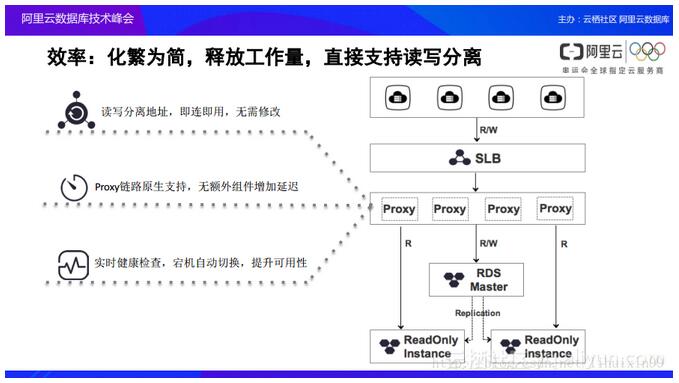
ą¦┬╩Ż║ą┬ę╗┤·ĻPŽĄą═öĄō■Äņč▌▀M
ŲõīŹ│²┴╦╔Ž├µ╦∙šfĄ─▀@ą®Ż¼░ó└’įŲöĄō■Äņ╦∙ū÷Ą─╣żū„▀Ć▀hø]ėąĮY╩°ĪŻ╚ń╣¹┤¾╝ę┴¶ęŌ┴╦░ó└’įŲūŅĮ³Ą─ą┬┬ä╗“š▀ūŅą┬Ą─«aŲĘäėŽ“Š═Ģ■ų¬Ą└Ż¼į┌░ó└’įŲöĄō■ÄņūŅą┬Ą─░µ▒Šųą╠ß╣®┴╦ĻPŽĄą═öĄō■ÄņPolarDBĄ─╝»╚║Ż¼▀@┐Ņ«aŲĘŅAėŗīóį┌╩«į┬Ę▌═Ų│÷Ż¼į┌▀@┐Ņ«aŲĘ╔Ž├µ▓╗å╬å╬ĮŌøQ┴╦ūxīæĘųļxĄ─å¢Ņ}Ż¼ę▓Ģ■╩╣ė├ĄĮūŅą┬Ą─ė▓╝■╝╝ąg╚ź▀_ĄĮ▒╚▌^║├Ą─ūxīæ┘Yį┤▒╚ĪŻį┌ūxīæĘųļxĄ─śIäšų«Ž┬Ż¼«öų„╣سcėąöĄō■īæ╚ļĄ─Ģr║“Ż¼╦∙ėąĄ─öĄō■ąĶę¬═¼▓ĮĄĮ├┐ę╗éĆų╗ūx╣سcŻ¼Č°į┌ų„╣سc║═ų╗ūx╣سcų«ķg╗“įSĢ■┤µį┌ŠWĮjčė▀tŻ¼▀@ą®ŠWĮjčė▀t┐╔─▄Ģ■ī¦ų┬Å─ų„╣سcūx│÷Ą─öĄō■║═Å─ų╗ūx╣سcūx│÷Ą─öĄō■│÷¼F▓╗ę╗ų┬Ą─ŪķørŻ¼Č°▀@╩ŪąĶ꬜IäšĘĮ╗“š▀ķ_░l╚╦åTų¬Ģį▓ó═©▀^śIäš▀Mąą▒ŻšŽĄ─ĪŻ
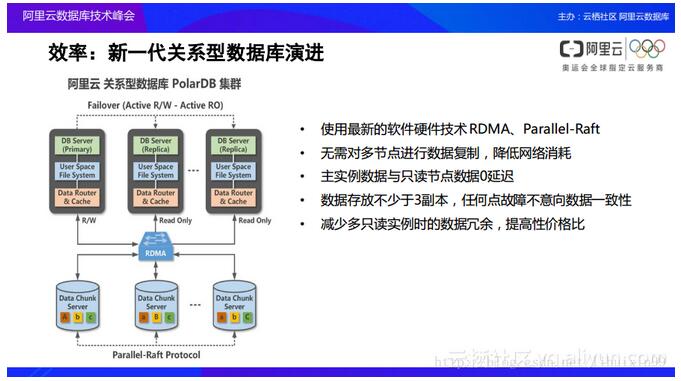
Č°į┌PolarDBųąŻ¼░ó└’įŲćLįć╩╣ė├┴╦ę╗ĘNą┬ą═Ą─╝▄śŗŻ¼═©▀^RDMAŠWĮjĢ■īóŽ┬īėĄ─Ė„éĆ┤µā”╣سc▀Mąąš¹║Ž╣▄└ĒŻ¼═©▀^Ęų▓╝╩ĮRaftģfūhīŹ¼F═Ļš¹Ą─Ąūīė╝»╚║ĪŻ▀@śė╦∙─▄▀_ĄĮĄ─ą¦╣¹Š═╩Ū«öų„╣سc▀MąąöĄō■īæ╚ļĄ─▀^│╠ųąŻ¼ĄūīėĄ─RaftģfūhĄ─öĄō■╝»╚║Ģ■░čöĄō■ūįäė┤“╔óĄĮ╚²éĆ╗“š▀ęį╔ŽĄ─┤µā”╣سc╔Ž├µŻ¼═¼Ģr▀@ą®öĄō■ę╗Ą®īæ╚ļŻ¼į┌Ųõ╦¹Ą─ų╗ūx╣سc╔ŽŠ═┐╔ęįūxĄĮĪŻę“┤╦┐╔ęį┐┤ĄĮį┌▀@śėĄ─╝▄śŗų«Ž┬Ż¼£p╔┘┴╦ČÓ╣سcų«ķgĄ─öĄō■Å═ųŲŻ¼ŠWĮjĦīÆĄ─Ž¹║─Ģ■Ė³Ą═Ż¼═¼Ģrų„╣سc║═ų╗ūx╣سcų«ķgŠWĮjöĄō■čė▀t╗∙▒Š×ķ┴ŃŻ¼ę▓Š═╩Ūšfų╗ę¬öĄō■īæ╚ļ┴╦Ż¼ų╗ūx╣سcŠ═─▄ē“ūx╚ĪĄĮŻ¼Ę¹║ŽACIDĄ─═Ļš¹įŁätĪŻ╦∙ėąĄ─öĄō■į┌┤µĘ┼Ą─Ģr║“Č╝▓╗Ģ■╔┘ė┌╚²╣سcŻ¼╚╬║╬ę╗éĆ╣سc╗“š▀öĄō■─ŻēK│÷¼F╣╩šŽĄ─Ģr║“Ż¼Č╝▓╗Ģ■įņ│╔öĄō■üG╩¦ĪŻį┌▀@śėĄ─╝▄śŗų«Ž┬Ż¼┐╔ęį▀Mę╗▓Į╩╣Ą├öĄō■ÄņĄ─╩╣ė├š▀½@╚ĪĖ³Ė▀Ą─ąįār▒╚ĪŻ
ķTÖæŻ║ ŠC║ŽŽĄĮy╣▄└ĒķTÖæĖ▀
ęį╔ŽĘųŽĒĄ─╩Ūį┌öĄō■ÄņĻPŽĄĄ─č▌▀Mųą░ó└’įŲ╠ß╣®Ą─ę╗ą®╦╝┐╝║═«aŲĘŻ¼Č°Ž┬├µĢ■ĘųŽĒ┴Ē═Ōę╗éĆå¢Ņ}ĪŻ╚ńŽ┬łD╦∙╩ŠŻ¼«öę╗éĆśIäš░lš╣ĄĮ▒╚▌^²ŗ┤¾Ą─öĄō■ęÄ─ŻĢrŻ¼┤µŽ┬üĒĄ─śIäšöĄō■▀ĆąĶę¬▀Mąą«aŲĘĄ─Ęų╬÷Ż¼▒╚╚ń«ööĄō■┴┐ęčĮø┤µĘ┼ĄĮā╔╚²─ĻĄ─Ģr║“Ż¼Ų¾śIų„┐ŽČ©ŽŻ═¹─▄ē“═©▀^▀@ā╔╚²─Ļ│┴ĄĒĄ─öĄō■üĒ▀MąąśIäšĘų╬÷ĪŻ▀@éĆĢr║“Ż¼į┌é„ĮyĄ─╝▄śŗų«Ž┬Ż¼═∙═∙Ģ■Ž“╚ńłDųą╦∙┐┤ĄĮĄ─░čöĄō■═©▀^ETLŻ¼ę▓Š═╩ŪöĄō■ī¦╚ļĄĮöĄō■é}ÄņŻ¼▓óį┌öĄō■é}Äņų«╔Žį┘╚źū÷OLAPĄ─śIäšĘų╬÷ĪŻ═¼Ģrė╔ė┌öĄō■┴┐įĮüĒįĮ┤¾Ż¼ę“┤╦ę▓ąĶę¬═©▀^Ęų▓╝╩ĮĄ─öĄō■Äņųąķg╝■īŹ¼Fę╗éĆäėū„Ż¼ę▓Š═╩Ūīóš¹éĆĄ─öĄō■Äņ▀MąąĘųÄņĘų▒Ē╩ĮĄ─╣▄└ĒĪŻ«ö╚╗Ż¼▀@śėĄ─╣”─▄į┌╗ź┬ōŠW╚”ęčĮø╩╣ė├Ą─ĘŪ│ŻČÓ┴╦Ż¼Ą½╩Ū┤¾╝ęĢ■░l¼FŽ┬łDųą┤µį┌╦─éĆ╦{╔½Ą─╣▄└Ēś╦ėøŻ¼▀@╩Ūę“×ķį┌├┐éĆīė╝ē«öųąČ╝ąĶę¬ī”ė┌öĄō■Äņ▀Mąąę╗ą®å╬¬ÜĄ─╚╦×ķ▓┘ū„║═╚╦×ķĖ╔ŅAĪŻ
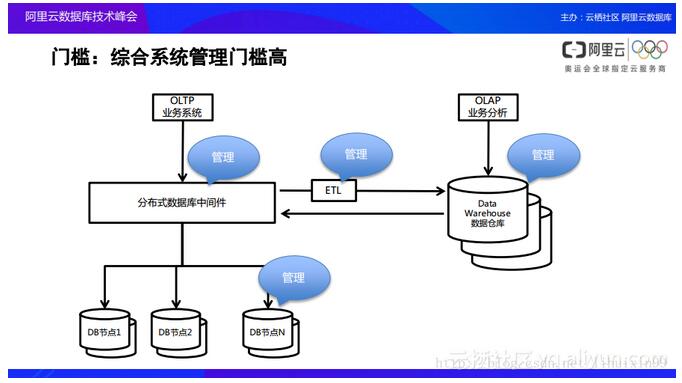
║å╗»ĘųÄņĘų▒Ē╣▄└ĒŻ¼ę╗Ę▌öĄō■īŹ¼FOLTP+OLAP=HTAP
┐╔ęį┐┤ĄĮį┌╔ŽłDĄ─š¹éĆ▀\ū„┴„│╠ųąŻ¼├┐ę╗éĆ╣سc╔Ž├µČ╝ąĶę¬▀Mąą┼õų├║═ęÄäØŻ¼Č°▀@ą®╦∙ėąĄ─┼õų├║═ęÄäØČ╝ąĶꬎ¹║─ĢrķgĪŻ▀Ćėąę╗³cŠ═╩ŪśI䚎ĄĮy╩ŪOLTPĄ─ŽĄĮyŻ¼╦∙ėąĄ─į┌ŠĆĄ─śIäšČ╝į┌╔ŽłDųąū¾é╚Ą─OLTPŽĄĮy└’├µŻ¼«öąĶę¬▀MąąĘų╬÷Ą─Ģr║“▓ó▓╗─▄ų▒Įėį┌śI䚎ĄĮy▀MąąĘų╬÷Ż¼ę“×ķ▀@Ģ■ė░ĒæśI䚎ĄĮy▒Š╔ĒĄ─ąį─▄Ż¼ę“┤╦ąĶę¬į┘▀Mąąę╗┤╬öĄō■Ą─│ķ╚ĪŻ¼īóöĄō■│ķ╚ĪĄĮOLAPĄ─öĄō■é}ÄņųąŻ¼╚╗║¾į┘╚źū÷▓ķįāĪŻ▀@śėäėū„╩╣Ą├öĄō■ČÓ┴╦╚▀ėÓŻ¼Č°Ūę╦∙ėąĄ─öĄō■¤oĘ©īŹ¼F╦∙ų^Ą─“T+0”Ą─īŹĢrĘų╬÷Ż¼į┌▀@ĘNŪķørŽ┬Ż¼╦∙ėąĄ─▓┘ū„ęį╝░▀\ŠS╣▄└ĒĢ■Ž¹║─Ė³ČÓĄ─╩╣ė├┘Yį┤ĪŻę“┤╦Ż¼į┌░ó└’įŲųąę▓╠ß╣®┴╦HybridDB for MySQLĄ─╝▄śŗĪŻ═©▀^HybridDB for MySQL╝▄śŗĄ─öĄō■ÄņŻ¼┐╔ęįīŹ¼Fīó╔ŽłDųą╦∙┐┤ĄĮĄ─š¹éĆöĄō■µ£┬ĘŻ¼░³└©Ęų▓╝╩ĮöĄō■Äņųąķg╝■ęį╝░öĄō■é}ÄņČ╝š¹║ŽĄĮę╗éĆöĄō■ÄņųąŻ¼▀@éĆöĄō■Äņ┐╔ęįų▒ĮėīŹ¼FOLTPĄ─╩┬äš▓┘ū„Ż¼═¼Ģrę▓Įė╩▄OLAPĄ─öĄō■Ęų╬÷╠Ä└ĒŻ¼Č°Ūęš¹éĆŽĄĮyę▓╩ŪĘų▓╝╩ĮŽĄĮyĪŻ

į┌▀@éĆŽĄĮyų«╔ŽūŅ┤¾Ą─║├╠ÄŠ═╩Ūė├æ¶▓╗į┘ąĶę¬╚źĘųäeĄž╣▄└Ēā╔éĆśI䚎ĄĮyŻ║OLTPŽĄĮy║═OLAPŽĄĮyĪŻ┼c┤╦═¼Ģr▀Ć┐╔ęįīŹ¼Fėŗ╦Ń║═┤µā”Ą─Ęųļx▓┘ū„Ż¼╚ń╣¹ėŗ╦Ń┘Yį┤▓╗ūŃ▀Ć┐╔ęįå╬¬ÜĄžį÷╝ėėŗ╦Ń┘Yį┤╩╣Ą├▓ķįā╦┘Č╚Ė³┐ņĪŻČ°Ūęš¹éĆŽĄĮyīóĢ■ų▒Įė╝µ╚▌MySQLĄ─╔·æBŻ¼ę“┤╦ė├æ¶▓╗ąĶę¬▀^ČÓĄžą▐Ė─ūį╝║öĄō■Äņ▓ķįāĄ─śIäš▀ē▌ŗŻ¼┐╔ęįų▒Įė╩╣ė├MySQLĄ─┐═æ¶Č╦ęį╝░Ė„ĘN╣żŠ▀üĒ▀BĮėĄĮöĄō■Äņ╔Ž├µ╚ź▀Mąą▓┘ū„ĪŻę“┤╦Ż¼į┌HybridDB for MySQLöĄō■ÄņųąīŹ¼F┴╦ę╗ĘNą┬Ą─ą╬æBĮąū÷HTAPŻ¼īŹļH╔ŽŠ═╩Ūį┌═¼ę╗éĆöĄō■Äņ└’├µ▓╗āH┐╔ęį▀MąąOLTP▓┘ū„Ż¼▀Ć┐╔ęį▀MąąOLAP▓┘ū„Ż¼Č°ŪęŲõ┐šķg┐╔ęįöUš╣ĄĮ│¼▀^PBĄ─╝ēäeĪŻ
ßīĘ┼Ż║░▓ą─įŁė┌═Ė├„Ż¼ų„äėĄ─╠ßąč
░ó└’įŲĄ─öĄō■Äņ«aŲĘ│²┴╦╠ß╣®┴╦ęį╔ŽĄ─╣”─▄ęį═ŌŻ¼×ķ┴╦╩╣Ą├DBAĖ³╝ė╩Īą─║═░▓ą─Ż¼Į^ī”ļx▓╗ķ_Ą─Š═╩Ūī”ė┌Ė„ĘN┘Yį┤Ą─▒O┐žęį╝░ī”ė┌ę²ŪµĄ─▒O┐žĪŻį┌▀@└’▓╗ū÷▀^ČÓĄ─ĮŌ╬÷Ż¼ę“×ķį┌«aŲĘ╔Ž┤¾╝ę┐╔ęį┐┤ĄĮŻ¼░ó└’įŲęčĮø░čūį╝║įŁüĒį┌╠ņžłĪó╠įīÜĄ╚Ą─Ė„ĘĮ├µĄ─Įø“×▀Mąą┴╦š¹¾wĄ─▌ö│÷Ż¼Ģ■╠ß╣®ĘŪ│Ż╔ŅČ╚Ą─░³└©TPSĪóQPSęį╝░ŠÅ┤µ├³ųą┬╩Ą╚Ą╚ę╗ŽĄ┴ąĄ─▒O┐žŻ¼Č°Ūę┐╔ęį«a╔·ų▒ĮėĄ─łD▒ĒĪŻį┌ł¾Š»ĘĮ├µŻ¼┐╔ęį═©▀^įŲ▒O┐žįOų├╦∙ąĶꬥ─ł¾Š»Ż¼«ö╦«╬╗│¼▀^┴╦ę╗Č©Ą─ĘČć·ų«║¾┐╔ęįų▒Įė░l╦═Č╠ą┼ĪóÓ]╝■╔§ų┴═©▀^ļŖįÆĄ─ĖµŠ»üĒ╠ßąčDBA▀MąąöU╚▌╗“š▀╝░ĢrĄž░l¼Få¢Ņ}ĪŻĖ³▀Mę╗▓ĮŻ¼░ó└’įŲ▀ĆīóĢ■╠ß╣®įŲDBAĄ─ģfų·╣żŠ▀Ż¼╔§ų┴▀ĆĢ■×ķė├æ¶╠ß╣®Index═Ų╦]ęį╝░Ž±ĖµŠ»Õeš`śIäšĘų╬÷Ą╚Ę■äšĪŻ

ßīĘ┼ė├æ¶│╔▒ŠŻ║ųąąĪŲ¾śIę▓┐╔ęį½@Ą├Ė▀Č╦Ę■äš
į┌Ų¾śI░lš╣Ą─▀^│╠ųąŻ¼ļSų°śIäš▓╗öÓĄž░lš╣Ż¼ąĶę¬Ė³║├Ąž▒ŻšŽśI䚥─▀B└mĘĆČ©ąįĪŻī”ė┌║▄ČÓŲ¾śIČ°čįŻ¼öĄō■Äņųąą─└’├µ═∙═∙ų╗ėąę╗éĆIDCĄ─ÖCĘ┐Ż¼╚╗Č°╚ń╣¹▀@éĆIDCÖCĘ┐│÷¼FöÓļŖ╗“š▀╣╩šŽĄ─Ģr║“Ż¼Š═ø]ėą▐kĘ©▀MąąĖ³▀Mę╗▓ĮĄ─śIäš▓┘ū„ĪŻ░ó└’įŲį┌öĄō■Äņ¾wŽĄų«Ž┬ęčĮø═Ļ│╔╚ńŽ┬łD╦∙╩ŠĄ─š¹¾w╝▄śŗĪŻ«ö┤¾╝ę┐┤ĄĮ░ó└’įŲöĄō■Äņ«aŲĘ┘Å┘IĒōĄ─Ģr║“Ģ■░l¼F░ó└’įŲ▓╗āH╠ß╣®┴╦å╬ųąą─Ą─ļp╣سc─Żą═Ż¼▀Ćį┌║▄ČÓĄžė“ųą╠ß╣®┴╦ČÓ┐╔ė├ģ^Ą──Żą═ĪŻČÓ┐╔ė├ģ^─Żą═Š═╩Ū░čų„╣سc║═éõė├╣سcĘ┼į┌ę╗éĆ│Ū╩ąĄ─ā╔éĆ▓╗═¼Ą─┐╔ė├ģ^╔ŽŻ¼ę▓Š═╩Ūšfė├æ¶Ą─īŹ└²ų╗┘Å┘I┴╦ę╗éĆŻ¼Ą½╩Ūį┌▓┐╩Ą─Ģr║“ģs▓┐╩į┌┴╦ę╗éĆ│Ū╩ąĄ─ā╔éĆųąą─Ż¼ę╗Ą®ų„ųąą─│÷¼Fš¹¾w╣╩šŽĄ─Ģr║“Ż¼ė├æ¶Ą─śIäšę└╚╗┐╔ęį═©▀^ŪąōQĄĮéõė├ųąą─└^└m╠ß╣®Ę■äšĪŻ┤¾╝ę┐╔ęįŽļŽ¾Ż¼╚ń╣¹ø]ėąįŲ╝▄śŗĄ─ų¦ō╬Ż¼ę└┐┐ūį╝║┤ŅĮ©ČÓ┐╔ė├ģ^─Żą═Ą─Ģr║“Ż¼┐╔─▄Ģ■ąĶę¬ĘŪ│ŻĖ▀Ą─śIäš│╔▒ŠŻ¼▀@╩Ūę“×ķ═¼│Ūų«ķg╣Ō└w┤ŅĮ©Ą─┘Mė├╩ŪĘŪ│Ż░║┘FĄ─ĪŻ
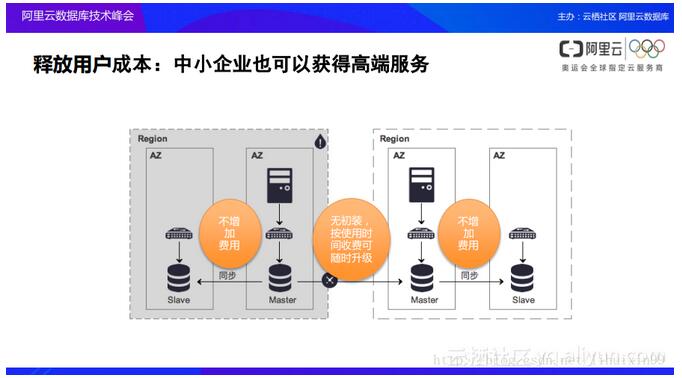
│²┤╦ų«═ŌŻ¼░ó└’įŲ▀ĆĢ■×ķŲ¾śI╠ß╣®┐ńöĄō■ųąą─Ą─įLå¢ĪŻ║▄ČÓė├æ¶┐╔─▄Ģ■šf¼Fį┌ūį╝║Ą─Ų¾śI▀Ć▓╗┤¾Ż¼▀Ć▓╗ąĶꬥĮ▀@śėĄ─śIäš▒ŻūoŻ¼Ą½╩Ūį┌▀@└’ŽļĖµįV┤¾╝ęĄ─╩Ū▀@śėĄ─ė^³c═∙═∙╩Ū▓╗š²┤_Ą─ĪŻ╚ń╔ŽłD╦∙╩ŠŻ¼«öŪ░į┌═¼│Ūļpųąą─×─éõ└’├µ▓╗ąĶę¬į÷╝ėė├æ¶Ą─│╔▒ŠŻ¼─Ū├┤Š══Ļ╚½┐╔ęįį┌Ų¾śI░lš╣ų«│§Š═╩╣ė├▀@śėĄ─╝▄śŗŻ¼ę“×ķį┌Ų¾śI░lš╣Ą─▀^│╠ųąŻ¼╚╬║╬ę╗éĆ╝╝ąg╔ŽĄ─╣╩šŽ╗“š▀Ę■䚥─Õ┤ÖC═∙═∙Ģ■įņ│╔║¾└mĖ³┤¾Ą─ōp╩¦ĪŻ╦∙ęį╚ń╣¹─▄ē“╠ßŪ░į┌▓╗į÷╝ė▀^ČÓ│╔▒ŠĄ─ŪķørŽ┬īŹ¼FŲ¾śI═¼│Ū╚▌×─ęį╝░┐ńĄžė“śI䚯¼═∙═∙─▄ē“ī”ė┌Ų¾śIśI䚥─░lš╣╠ß╣®Ė³┤¾Ą─Ä═ų·ĪŻį┌░ó└’įŲ╔ŽŻ¼ŲõīŹ╗∙ė┌░ó└’įŲ▒Š╔ĒĄ─╝╝ąg╝▄śŗŠ═┐╔ęį×ķė├æ¶Ė³║├ĄžßīĘ┼▀@▓┐Ęų│╔▒ŠŻ¼Č°ė├æ¶▓╗ąĶę¬ūį╝║┤ŅĮ©╣Ō└wŠ═┐╔ęįÅ═ė├╦∙ėą¼FėąĄ─ŠWĮjŻ¼▀@╩╣Ą├Ų¾śIį┌│§╩╝ļAČ╬Š═┐╔ęįŽ±┤¾Ų¾śIę╗śė╩╣ė├ĄĮ╦∙ėąĄ─öĄō■ÄņĄ─Ė▀Č╦Ę■äšĪŻ
┤¾╝ę┐╔ęį┐┤ĄĮŻ¼į┌░ó└’įŲöĄō■ÄņśIäšųą▒╚▌^ūóųžĄ─Š═╩Ū╚ńŽ┬łD╦∙╩ŠĄ─╬Õ³cŻ║╚ń║╬Ä═ų·ė├æ¶╣Ø╩Ī│╔▒ŠŻ¼╚ń║╬╩╣öĄō■ÄņĄ─ąį─▄▀_ĄĮĖ³Ė▀Ż¼╚ń║╬ŠSūośI䚥─▀B└mąįŻ¼ęį╝░śIäšöUš╣─▄┴”║═öĄō■╚▌×─Ą╚ĪŻČ°▀@ę╗ŪąĄ──▄┴”Č╝╩Ū═©▀^įŲ═ą╣▄ŲĮ┼_▀MąąęÄäØ║═┘x─▄Ą─ĪŻ

╚²Īó╔·æBĄ─┴”┴┐
į┌ęį╔ŽĄ─ā╚╚▌ųą×ķ┤¾╝ęĘųŽĒ┴╦įŲöĄō■Äņ╔ŽĄ─«aŲĘ“īäėĪó░ó└’įŲöĄō■Äņ╠ß╣®┴╦╩▓├┤śėĄ─▒Żūoęį╝░░ó└’įŲöĄō■Äņ╩Ū╚ń║╬│ą▌dė├æ¶ąĶŪ¾Ą─ĪŻĮėŽ┬üĒ×ķ┤¾╝ęĘųŽĒöĄō■Äņ╔·æBĄ─┴”┴┐ĪŻ
░ó└’įŲMySQL╔·æB¾wŽĄ
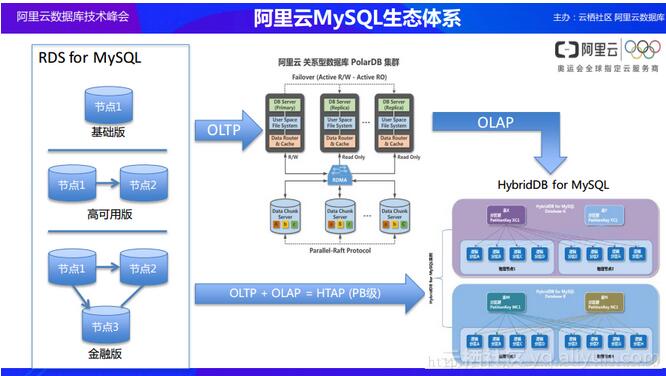
«ö░ó└’įŲūŅ│§╚źęÄäØöĄō■Äņ«aŲĘĄ─Ģr║“Ż¼╩ūŽ╚ū÷Ą─«aŲĘŠ═╩ŪMySQLŻ¼ę“×ķį┌«öĢrMySQLę▓╩Ū╩╣ė├ūŅ×ķÅVĘ║Ą─öĄō■ÄņŻ¼╠žäe╩Ūį┌╗ź┬ōŠWśIĮńĪŻĄ½╩Ūį┌▓╗öÓĄ─░lš╣▀^│╠ųąę▓░l¼F▓╗öÓėąĖ³ČÓĄ─╗ź┬ōŠWśIäšęį╝░Ų¾śI┐═æ¶Ģ■▀M╚ļĄĮ░ó└’įŲ¾wŽĄ╔ŽüĒŻ¼╦∙ęį░ó└’įŲąĶę¬ėąĖ³ČÓĄ─öĄō■ÄņŅÉą═üĒī”▀@ą®ė├æ¶▀Mąąų¦ō╬ĪŻ║▄ČÓĄ─ė├æ¶▓╗āHāHąĶę¬╩╣ė├SQLĄ─öĄō■ÄņŻ¼▀ĆĢ■ąĶę¬ū÷ŠÅ┤µ▓óŪęąĶę¬▀MąąöĄō■Ęų╬÷ĪŻį┌Ž┬łDųąŻ¼┤¾╝ę┐╔ęį┐┤ĄĮ░ó└’įŲų▓ĮĄžį÷╝ėĖ³ČÓĄ─ę²ŪµŻ¼░┤ššDB-EnginesĄ─ĮyėŗŻ¼─┐Ū░░ó└’įŲöĄō■ÄņęčĮø─▄ē“Ė▓╔w70%Ą─öĄō■Äņ«aŲĘŻ¼▀@ę▓╩Ūė╔╩ął÷╦∙øQČ©Ą─ĪŻČ°▀@ą®«aŲĘųąĄ─▓┐Ęų«aŲĘęčĮøķ_╩╝ū▀╔Ž┴╦░ó└’įŲūį蹥─Ą└┬ĘŻ¼Ž±ų«Ū░╠ߥĮĄ─HybridDB for MySQLęį╝░PolarBDĄ╚ĪŻ«ö╚╗Ż¼│²┴╦ūįčą«aŲĘų«═ŌŻ¼░ó└’įŲę▓Ģ■╝µŅÖĄĮ╩ął÷╔Ž├µŲõ╦¹ė├æ¶Ą─ąĶŪ¾Ż¼ę▓Ģ■╠ß╣®Ž±SQL ServerĪóHBaseĪóMongoDBęį╝░RedisĄ╚ę╗ŽĄ┴ąĄ─öĄō■Äņ«aŲĘŻ¼▀@Š═╩Ū░ó└’įŲ─┐Ū░Ą─öĄō■Äņ«aŲĘš¹¾w┤¾╔·æBĪŻ

«ö╚╗╬ęéāę▓┐╔ęį┐┤ĄĮ┴Ē═Ōę╗éĆ╔·æB─Żą═Ż¼┼eéĆ└²ūėŠ═╩Ū─┐Ū░║▄ČÓĄ─ė├æ¶Č╝į┌╩╣ė├MySQLĄ─öĄō■ÄņŻ¼į┌MySQLöĄō■Äņų«Ž┬Ż¼░ó└’įŲĢ■╠ß╣®ČÓĘN▓╗═¼Ą─öĄō■Äņą╬æB║═─Ż╩ĮŻ¼ūīė├æ¶┐╔ęį═Ļ╚½│┴Į■į┌MySQLš¹¾w╔·æBµ£┬Ęų«ųąĪŻ╚ńŽ┬łDū¾é╚╦∙╩ŠŻ¼RDS for MySQL╠ß╣®┴╦╗∙ĄA░µĪóĖ▀┐╔ė├░µęį╝░Į╚┌░µŻ¼╩╣Ą├ė├æ¶┐╔ęį┐ņ╦┘Ąž▀MąąśI䚥─╩╣ė├Ż¼▀Mę╗▓Įį┌╬┤üĒ░ó└’įŲöĄō■ÄņīóĢ■░l▓╝Ą─PolarDBę▓Ģ■┬╩Ž╚Ąžų¦│ųMySQLĄ─ę²ŪµŻ¼ūīŠ▀ėąÄū╩«TBöĄō■╗“š▀╔Ž░┘TBöĄō■Ą─▓óŪęŽļę¬╩╣ė├Ė³╝ėĘĆČ©Ą─öĄō■ÄņŽĄĮyĄ─┤¾ą═┐═æ¶─▄ē“ĘŪ│Ż║├ĄžĮŌøQė÷ĄĮĄ─å¢Ņ}ĪŻ═¼ĢrŻ¼║▄ČÓ╚╦Ģ■šJ×ķMySQL╔Ž├µ▓ó▓╗▀m║Ž╚źū÷OLAPśIäšĘų╬÷╣żū„Ż¼Ą½╩Ū╚ń╣¹╦∙ėąĄ─ķ_░l╚╦åTČ╝╩Ū╩ņŽżMySQLĄ─▓óŪę▓╗ŽŻ═¹╠°│÷MySQLĄ─┐“╝▄Č°Ūꎯ═¹╚ź╗∙ė┌MySQLīŹ¼FśIäšĘų╬÷▓┘ū„Ż¼▀@śė═©▀^HybridDB for MySQLŠ═─▄ē“└^└m╚ź│ą▌d▀@śėĄ─śI䚯¼Č°Ūęį┌▀@éĆŽĄĮy╔Ž├µ▀Ć┐╔ęį═¼Ģrš¹║ŽOLTP║═OLAPĪŻę“┤╦Ż¼į┌öĄō■Äņ«aŲĘĄ─ęÄäØ▀^│╠ų«ųąŻ¼░ó└’įŲĢ■│õĘųĄž┐╝æ]ė├æ¶▒Š╔ĒĄ─ĖąŪķę“╦žŻ¼«öė├æ¶╠žäeāAŽ“ė┌─│ę╗öĄō■ÄņĄ─Ģr║“Ż¼░ó└’įŲŠ═Ģ■ßśī”ė┌▀@éĆöĄō■Äņū÷│÷ę╗ŽĄ┴ąĄ─«aŲĘŻ¼╩╣Ą├ė├æ¶┐╔ęį═©▀^Įyę╗Ą─╝╝ąg╚ź═Ļ│╔╦∙ėąĄ─╝╝ąg╣żū„Ż¼Č°ø]▒žę¬īó╦∙ėąĄ─╣żū„Ęų╔óĄĮ▓╗═¼Ą─öĄō■Äņ▓ó╩╣ė├▓╗═¼Ą─SQL─Żą═▀Mąąųžą┬ķ_░lĪŻ
░ó└’įŲPostgreSQL╔·æBŽĄĮy
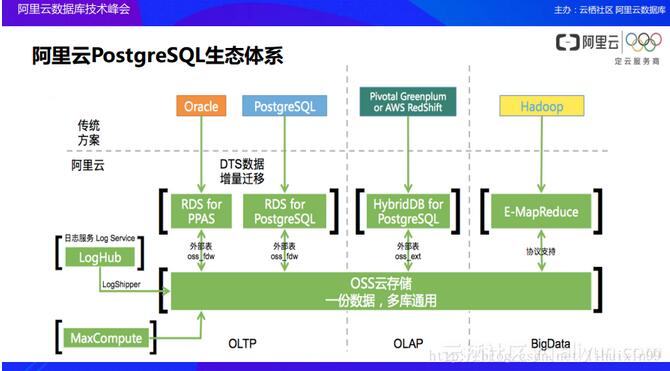
│²┴╦MySQL╔·æBų«═ŌŻ¼Į³─ĻPostgreSQL╔·æBŽĄĮyę▓╩ŪĘŪ│Ż╗¤ßĄ─Ż¼░ó└’įŲöĄō■ÄņłFĻĀį┌PostgreSQL╔·æB╔Žę▓čžė├┴╦║═MySQL╔·æBųąŽÓ═¼Ą─╦╝┬ĘĪŻ░ó└’įŲ▓╗ų╗╩Ū×ķė├æ¶╠ß╣®ę╗éĆå╬¬ÜĄ─RDS for PostgreSQLĄ─ŽĄĮyŻ¼ę“×ķPostgreSQL║═Oracle▒╚▌^ŽÓ╦ŲŻ¼╦∙ęį▀ĆĢ■ßśī”╗∙ė┌PostgreSQLĄ─į÷ÅŖ░µ▒Š——RDS for PPSüĒģfų·Oracleė├æ¶üĒ▀MąąöĄō■▀węŲĪŻ═¼Ģr░ó└’įŲę▓Ģ■═Ų│÷ßśī”ė┌öĄō■é}ÄņĄ─HybridDB for PostgreSQLüĒīŹ¼FöĄō■Ęų╬÷ĪŻČ°Ūę╦∙ėąĄ─▀@ą®¾wŽĄČ╝┐╔ęį═©▀^═Ō▓┐▒ĒĄ─ą╬╩Į╚ź▓┘ū„OSSŻ¼╔§ų┴į┌OSS╔Ž├µĘ┼ę╗Ę▌öĄō■Ż¼Ė„éĆ▓╗═¼Ą─OLTPĪóOLAPöĄō■Äņ«aŲĘČ╝┐╔ęįī”ė┌OSS╔ŽĄ─öĄō■▀Mąąūxīæ▓┘ū„║═Ęų╬÷æ¬ė├üĒīŹ¼Fš¹¾w╔·æBµ£Ą─▀\ąą▀^│╠ĪŻ
╦─ĪóSQL+NoSQL+Big Dataę╗šŠ╩ĮĮŌøQöĄō■┤“═©
│²┴╦╔Ž╩÷╠ߥĮĄ─░ó└’įŲ×ķ▓ĘųĄ─MySQL║═PostgreSQL╔·æBµ£┤“įņĄ─¬Ü╠žĄ─ĘĮ░Ėų«═ŌŻ¼░ó└’įŲöĄō■Äņ▀ĆĢ■┼c░ó└’įŲĄ─Ė„ĘNöĄō■µ£┬ĘĄ─▄ø╝■▀Mąąš¹║ŽęÄäØĪŻį┌Ž┬├µ▀@ÅłłDųąŻ¼┤¾╝ę┐╔ęį┐┤ĄĮŻ¼═©▀^░ó└’įŲĄ─DTSęį╝░CDP▀@śėöĄō■╣żŠ▀Ż¼┐╔ęįīóŪ░Č╦Ą─Key-ValueĄ─ŠÅ┤µīėĪóOLTPĪóNoSQLĪóĘų╬÷ęį╝░Big Data▀Mąąš¹¾wöĄō■Ą─┤“═©ĪŻįŲ╔ŽĄ─öĄō■┐╔ęį═©▀^▒╚▌^ĘĮ▒ŃĄ─ĘĮ╩Į╝ė╔ŽśIäš╝▄śŗĄ──Żą═ķ_░lŠ═┐╔ęįīŹ¼Fī”ė┌╦∙ėąöĄō■į┌Ė„éĆöĄō■«aŲĘų«ķgĄ─¤o┐p┤“═©Ż¼▓óīŹ¼F┴╦š¹¾wĄ─öĄō■Į╗ōQĪŻĮ╗ōQ═ĻöĄō■ų«║¾Š═┐╔ęįūīĖ„éĆöĄō■ŽĄĮyĖ³┤¾Ąž░lō]ūį╝║Ą─śIäšārųĄĪŻ

╚ńĮ±Ż¼öĄō■ÄņŲõīŹęčĮø╩Ū▀_ĄĮ┴╦░┘╗©²RĘ┼Ą─ĀŅæBŻ¼─┐Ū░ėąĘŪ│ŻČÓĄ─ę²Ūµęį╝░▓╗═¼Ą─śIäšęÄäØĪŻČ°░ó└’įŲĄ─įŲöĄō■Äņę└┼f▒³│ųų°▀@śėĄ─Äū³c«aŲĘ└Ē─ŅŻ║░ó└’įŲĢ■×ķė├æ¶╠ß╣®▓╗═¼īė╝ēĄ─öĄō■Äņ«aŲĘŻ¼ūīė├æ¶┐╔ęįīŹ¼F▓╗═¼Ą─ąĶŪ¾Ż¼▓╗═¼Ą─ė├æ¶┐╔ęį┘Å┘IĄĮ▓╗═¼ārĖ±Īó┐╔┐┐ąįęį╝░ąį─▄Ą─öĄō■Äņ«aŲĘĪŻ░ó└’įŲŽŻ═¹═©▀^įŲŲĮ┼_Ą─┤“═©īŹ¼Fė├æ¶öĄō■ÄņśŗĮ©Ą─ūŅ┐ņ╦┘Ą─░lš╣ą¦┬╩Ż¼Č°▓╗ŽŻ═¹ę“×ķ╝▄śŗĄ─Ė─ūā╗“š▀č▌ūāŻ¼Č°╚źĄ╚┤²Äūų▄╔§ų┴ę╗éĆį┬Ą─ęÄäØŻ¼Č°ŽŻ═¹═©▀^³cÄūŽ┬░┤ŌoŠ═─▄ē“Ą├ĄĮą┬Ą─öĄō■Äņ╗“š▀┤ŅĮ©│÷ą┬Ą─╝»╚║Ż¼▓ó┼cįŁėąĄ─╝»╚║▀Mąą¤o┐p▀BĮėĪŻ═¼ĢrŻ¼į┌│╔▒Š╔Ž├µŻ¼ę“×ķĄ├ĄĮ┴╦įŲ╗∙ĄA╝▄śŗĄ─▒ŻūCŻ¼ė├æ¶ø]ėą▒žę¬ūį╝║╚źį┘┤ŅĮ©░║┘FĄ─╣Ō└w╗“š▀ÖC╣±Ą╚ė▓╝■įOéõŻ¼Č°┐╔ęįų▒Įė╚ź╔·«aīŹ└²ĪŻė├æ¶╦∙┘Å┘IĄ─įŲöĄō■ÄņŲõīŹ┤·▒Ē┴╦║▄ČÓ¢|╬„Ż¼░³└©▄ø╝■ĪóÖCŲ„ĪóÖC╝▄ęį╝░ŠWĮjĄ╚Ż¼Č°▀@ę╗ŽĄ┴ąĄ─¢|╬„░ó└’įŲęčĮø┤ŅĮ©║├┴╦Ż¼ė├æ¶┐╔ęįĖ∙ō■ūį╝║Ą─ąĶŪ¾ų▒Įė╚ź┘Å┘Ię╗éĆį┬Īóā╔éĆį┬╗“š▀ę╗─ĻĄ─╩╣ė├┴┐╝ēŻ¼Č°ø]ėą▒žę¬╚źę╗┤╬ąįĄž▀Mąą│╔▒ŠĄ─ų¦ĖČĪŻūŅ║¾Ż¼░ó└’įŲŽŻ═¹═©▀^ūįäė╗»Ą─▓┐╩Īó╣▄└Ē║═▒O┐žŻ¼ßīĘ┼DBAĄ─╣żū„┴┐Ż¼ūīDBA├Ōė┌╚ź▒╗▓┐╩Īó╣▄└ĒĄ╚▀\ŠS╣żū„╦∙└p└@Ż¼ūī╦¹éā░čĖ³ČÓĄ─Ģrķg║═ĮøÜv╚ź═Č╚ļĄĮ×ķŲ¾śI▀MąąśIäšā×╗»Ż¼ė├╝╝ąg×ķŲ¾śIäōįņĖ³ČÓĄ─║╦ą─╔·«a┴”╔Ž├µ╚źĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║įŲöĄō■Äņ«aŲĘ╝░╝▄śŗįOėŗ▒│║¾Ą─┐╝┴┐
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839721028.html






















