



ĪĪĪĪ1Īóę²čį
ĪĪĪĪįŲėŗ╦Ń╩Ūę╗ĘNą┬ą═Ą─śIäš─Ż╩ĮŻ¼─▄ē“×ķöĄō■ųąą─ÅS╔╠╣Ø╝s─▄║─Ż¼╠ßĖ▀įOéõ└¹ė├┬╩Ż¼▓ó═╗ŲŲé„ĮyĘ■äš─Ż╩Įķ_š╣ČÓśė╗»Ą─äōą┬╔╠śIĘ■äš─Ż╩ĮŻ╗ė├æ¶┐╔ęį▓╗ė├ūį╝║┘Å┘IIT╣╠Č©┘Y«aŻ¼Č°═©▀^VDC (Virtual Data CenterŻ¼╠ōöMöĄō■ųąą─)Ę■äš╠ß╣®╔╠░┤ąĶūŌė├ūį╝║╦∙ąĶĄ─ėŗ╦ŃĪó┤µā”ĪóŠWĮj┘Yį┤Ż¼▓ó┐╔ļSĢrļSąĶöUš╣Īóą┬į÷Īó═ŻūŌ┘Yį┤ĪŻ
ĪĪĪĪįŲėŗ╦Ń╗∙ĄAįO╩®╝┤Ę■äšIaaS(Infrastructure as a Service)śIäš─Ż╩ĮūŅĄõą═Ą─æ¬ė├ł÷Š░╩Ū╠ōöMöĄō■ųąą─Ż¼įōśIäš─Ż╩ĮĄ─│÷¼Fīóėŗ╦ŃÖCŽĄĮyĄ─ŠSūo▀Mąą┴╦╝ÜĘųŻ¼ė╔Ę■äš╣®æ¬µ£Ą─Ė„ĘĮĖ„╦ŠŲõ┬ÜŻ║ė├æ¶ų╗ąĶ┐╝æ]Ųõūį╔Ēæ¬ė├╗∙ė┌╠ōöMŁhŠ│Ą─▓┐╩╝▄śŗŻ¼VDCĘ■äš╠ß╣®╔╠ų╗ąĶ┐╝æ]īóė▓╝■┘Yį┤│ž╗»▓ó▒ŻūCĘ■äš┐╔ė├ąįŻ¼ė▓╝■ÅS╔╠ų╗ąĶ┐╝æ]ĄūīėįOéõī”╠ōöM╗»ŁhŠ│Ą─ų¦│ų║═ā×╗»ĪŻŠSūoųž³c╝ÜĘųų«║¾Ż¼æ¬ī”’LļUĄ─ž¤╚╬ę▓Š═╝ÜĘų┴╦ĪŻę“┤╦įŲėŗ╦ŃŁhŠ│Ž┬Ą─×─ļyæ¬ī”▓ó▓╗╩ŪĘ■äš╣®æ¬µ£ųąų╗ėą─│ę╗ĘĮąĶę¬┐╝æ]Ą─å¢Ņ}Ż¼Č°╩ŪąĶę¬Ė„ĘĮ╗∙ė┌Ė„ūįž¤╚╬ĘČć·ą╬│╔ģfš{ę╗ų┬Ą─┤ļ╩®Ż¼▀@śė▓┼─▄į┌×─ļyüĒ┼RĢrūŅ┤¾│╠Č╚Ą─£pąĪōp╩¦ĪŻ
ĪĪĪĪ▒Š╬─╠Įėæ┴╦įŲėŗ╦ŃIaaSĘ■äš╠ß╣®╔╠║═ė├æ¶æ¬ī”×─ļyĄ─▓▀┬įŻ¼▓ó╠ß│÷┴╦ę╗ĘNVDC╚▌×─╝▄śŗĪŻ
ĪĪĪĪ2Īó×─ļyĄ─Č©┴x║═ĘųŅÉ
ĪĪĪĪĖ∙ō■įŁć°äšį║ą┼Žó╗»╣żū„▐k╣½╩ęĄ─Č©┴xŻ¼×─ļy╩ŪųĖė╔ė┌╚╦×ķ╗“ūį╚╗Ą─įŁę“Ż¼įņ│╔ą┼ŽóŽĄĮy▀\ąąć└ųž╣╩šŽ╗“░c»łŻ¼╩╣ą┼ŽóŽĄĮyų¦│ųĄ─śIäš╣”─▄═ŻŅD╗“Ę■äš╦«ŲĮ▓╗┐╔Įė╩▄Īó▀_ĄĮ╠žČ©Ą─ĢrķgĄ─═╗░ląį╩┬╝■Ż¼═©│Żī¦ų┬ą┼ŽóŽĄĮyąĶę¬ŪąōQĄĮéõė├ł÷Ąž▀\ąąĪŻĖ∙ō■▀@ę╗Č©┴xŻ¼×─ļy▓╗āHųĖ║Żć[ĪóĄžšĄ╚ūį╚╗×─║”Ż¼▀Ć░³└©Ųõ╦³╚╬║╬ė╔¤oĘ©ŅAų¬Ą─įŁę“ę²ŲĄ─Ę■äš▓╗┐╔ė├ĪŻITĘ■䚥─╩¦ą¦─▄ē“ų▒Įėī¦ų┬Ų¾śIīŹ¼F║╦ą─ārųĄĄ─ĻPµIśI䚎ĄĮy╩▄ĄĮųžäōĪŻ└²╚ńŻ¼ŃyąąĄ─ATMÖC╩¦ą¦ĪóŠWšŠĄ─ŠWĒō¤oĘ©įLå¢ĪóūC╚»Ą─Į╗ęūŽĄĮy╩¦ņ`ĪóöĄō■ųąą─Ą─ŠWĮjūĶ╚¹Ą╚Ż¼ūŅĮKīóī¦ų┬ų┬├³Ą─é¹║”Ż¼įņ│╔▓╗┐╔═ņ╗žĄ─ōp╩¦ĪŻ
ĪĪĪĪ╬ęéāīó×─ļy▀Mę╗▓Į╝ÜĘųŻ¼░┤šš╚╦×ķę“╦žĄ─ČÓ╔┘Ęų×ķęįŽ┬╚²ŅÉŻ║
ĪĪĪĪ(1)ĘŪ╚╦×ķūį╚╗×─ļyŻ║║Żć[ĪóĄžšĄ╚ģ^ė“ܦ£ńąį×─ļyŻ╗
ĪĪĪĪ(2)╚╦×ķĘŪ╝╝ągąį×─ļyŻ║╗×─Īó═ŻļŖĪó╚╦åTōp╩¦Ą╚Šų▓┐┼RĢrąį×─ļyŻ╗
ĪĪĪĪ(3)╚╦×ķ╝╝ągąį×─ļyŻ║įOéõ╣╩šŽĪó▀ē▌ŗ╚▒Ž▌Īó╚╦×ķ▓┘ū„╩¦š`Ą╚┐╔ā×╗»×─ļyĪŻ
ĪĪĪĪ3ĪóVDCśIäšĖ„ĘĮąĶæ¬ī”Ą─×─ļy
ĪĪĪĪī”ė┌VDCśIäšüĒšfŻ¼æ¬ī”Ą┌ę╗ĪóĄ┌Č■ŅÉ×─ļyų„ę¬ę└═ąŅAŽ╚ųŲČ©Ą─╚▌×─ŅA░ĖŻ╗æ¬ī”Ą┌╚²ŅÉ×─ļyų„ę¬ę└═ą├▄╝»ą═Ą─╝╝ągĖ╔ŅAŻ¼Ę■äš╝▄śŗįĮÅ═ļsŻ¼ę²ŲĄ┌╚²ŅÉ×─ļyĄ─’LļUŁh╣ØŠ═įĮČÓŻ¼Ą½┼cĄ┌ę╗ĪóĄ┌Č■ŅÉ×─ļy▓╗═¼Ą─╩ŪŻ¼Ą┌╚²ŅÉ×─ļy┐╔═©▀^š¹Ė─┤ļ╩®▐Dūā×ķĪ░ę╗┤╬ąį×─ļyĪ▒Ż¼ĮĄĄ═ųžÅ═░l╔·Ą─┐╔─▄ąįĪŻ
ĪĪĪĪVDCĘ■äš╠ß╣®╔╠║═VDCė├æ¶Č╝Ģ■├µ┼Ręį╔Ž╚²ŅÉ×─ļyŻ¼Ą½Ė„ūįĄ─æ¬ī”║═ŅAĘ└┤ļ╩®▓╗═¼ĪŻ
ĪĪĪĪ3.1VDC╠ß╣®╔╠ąĶę¬æ¬ī”Ą─×─ļy
ĪĪĪĪę╗éĆ┼õų├£╩┤_Īóš²│Ż▀\ĀIĄ─VDC─▄ē“ūīūŌæ¶═©▀^įŲ╣▄└ĒŲĮ┼_į┌15ĘųńŖā╚½@Ą├╦∙╔ĻšłĄ─┘Yį┤Ż¼▓óŪę┐╔ęįļSĢr░┤ąĶĻPķ]Īóą┬į÷║═öUš╣╠ōöMĘ■äšŲ„Ż¼▀@╩ŪVDC╠ß╣®╔╠IaaSĘ■䚥─╗∙▒Š╠ž³cĪŻŲõĘ■äš╝▄śŗ┐╔ęįĘų×ķ┘Yį┤īėĪóśIäšīėĪóš╣¼FīėŻ¼Ųõųą╚╬║╬ę╗īėČ╝ėą│÷¼F«É│ŻĄ─┐╔─▄Ż¼Š▀¾w┐╔ęį▒Ē¼F×ķŻ║
ĪĪĪĪ(1)┘Yį┤īėįOéõōpē─(╚²ŅÉ×─ļyČ╝┐╔─▄ę²Ų)Ż╗
ĪĪĪĪ(2)┘Yį┤īėŠWĮj╩▄┼ÓŻ╗
ĪĪĪĪ(3)┘Yį┤īėų„ÖCŽĄĮy╣╩šŽŻ╗
ĪĪĪĪ(4)śIäšīėš{Č╚▀ē▌ŗÕeš`Ż╗
ĪĪĪĪ(5)śIäšīėŠ▄Į^Ę■䚯╗
ĪĪĪĪ(6)š╣¼FīėŠ▄Į^Ę■䚯╗
ĪĪĪĪ(7)Ųõ╦³¤oĘ©ŅAų¬Ą─╝╝ąg╣╩šŽĪŻ
ĪĪĪĪęį╔Ž▀@ą®«É│Ż├┐ę╗ĘNČ╝Ģ■ę²ŲĘ■äš▓╗┐╔ė├ĪŻ╝▄śŗųąĖ„─ŻēKų«ķgėąŽÓ╗źę└┘ć▀ē▌ŗŻ¼ę╗╠Ä╝╝ąg╣╩šŽĮø│ŻĢ■ę²ŲĪ░▀BµiĘ┤æ¬Ī▒Ż¼ī¦ų┬ČÓéĆŁh╣Ø«É│ŻŻ¼į÷╝ėŽĄĮy╣▄└ĒĄ─Å═ļsČ╚Ż¼Å─Č°ī¦ų┬Ę■äš▓╗┐╔ė├ĢrķgĄ─čėķLĪŻ
ĪĪĪĪ╚²ŅÉ×─ļyĄ─░l╔·ļm╚╗▓╗┐╔ŅAų¬Ż¼Ą½═©▀^ł╠ąąŅAŽ╚ųŲČ©Ą─╚▌×─ŅA░ĖŻ¼VDC╠ß╣®╔╠┐╔ęįīóė╔ĘŪ╚╦×ķūį╚╗×─ļy║═╚╦×ķĘŪ╝╝ągąį×─ļyę²ŲĄ─Ę■äšķgöÓ┐žųŲį┌ūŅąĪĘČć·ĪŻ╝╝ągąį×─ļyätąĶę¬VDC╠ß╣®╔╠═©▀^ūį╔ĒĄ─╝╝ąg┴”┴┐£╩┤_Č©╬╗Īó┼┼│²Ż¼▓óī”Ę■äš╝▄śŗ▀Mąąņ¢╣╠║═ŅAĘ└ĪŻ×─ļyĄ─æ¬ī”ų▒Įėė░ĒæVDCĘ■䚥─┐╔┐┐ąį║═ĘĆČ©ąįŻ¼╩ŪŲõĘ■äš┘|┴┐Ą─ĻPµIę“╦žŻ¼ę▓╩ŪVDCīŹ¼FĘ■äš╝ēäeģfūhSLA(Service Level Agreement)╣▄└ĒĄ─ĻPµIę“╦žų«ę╗ĪŻ
ĪĪĪĪ3.2VDCė├æ¶ąĶę¬æ¬ī”Ą─×─ļy
ĪĪĪĪī”ė┌3.1╣Ø├Ķ╩÷Ą─×─ļyŻ¼VDCĘ■äš╠ß╣®╔╠ėą═ĻéõĄ─æ¬╝▒║═æ¬ī”┤ļ╩®Ż¼VDCė├æ¶į┌┤╦╗∙ĄA╔Ž┐╔│õĘų└¹ė├įŲĘ■äš┘Yį┤╔ĻšłĄ─ūįäėĪó┐ņĮ▌ĪóĘĮ▒ŃŻ¼▀Mę╗▓Į×ķūį╔Ēæ¬ė├įOų├ņ`╗ŅĄ─╚▌×─▓▀┬įĪŻ╚╗Č°┴Ēėąę╗ą®×─ļyę“╦ž╩ŪVDC╠ß╣®╔╠¤o─▄×ķ┴”Ą─Ż¼ė├æ¶▒žĒÜ┐╝æ]┐ńVDC╠ß╣®╔╠Ą─×─éõĘĮ░ĖüĒĮŌøQŻ¼▀@ą®ę“╦ž░³└©Ż║
ĪĪĪĪ(1)VDC╠ß╣®╔╠▐DūāĮøĀI▓▀┬įŻ¼▓╗į┘╠ß╣®įŲėŗ╦ŃĘ■䚯¼╦∙ėąįOéõęŲū„╦¹ė├Ż╗
ĪĪĪĪ(2)VDC╠ß╣®╔╠ą¹ĖµŲŲ«aŻ¼╦∙ėąįOéõ╚źŽ“▓╗├„ĪŻī”ė┌┤╦ŅÉ×─ļyĄ─ė├æ¶æ¬ī”┤ļ╩®īóį┌5.2╣Øįö╝Ü├Ķ╩÷ĪŻ
ĪĪĪĪ4ĪóįŲ╠ß╣®╔╠æ¬ī”×─ļyĄ─┤ļ╩®
ĪĪĪĪ4.1╗∙ĄAįO╩®ę¬Ū¾
ĪĪĪĪ┘Yį┤īė╩ŪįŲėŗ╦ŃĘ■äš╝▄śŗĄ─ūŅĄūīėŻ¼×ķ┴╦├µī”▓╗┐╔ŅAų¬Ą─×─ļyŻ¼VDC╠ß╣®╔╠▒žĒÜ£╩┤_┴╦ĮŌĖ„ėąĻP╗∙ĄAįO╩®┘Yį┤Ą─╠žąįŻ¼▓óį┌║Ž▀mĄ─╬╗ų├įOų├║Ž▀mĄ─╗∙ĄAįO╩®┘Yį┤ĪŻ
ĪĪĪĪ4.1.1ŠWĮj╩ŪĻPµI
ĪĪĪĪįŲėŗ╦ŃęįŠWĮj×ķę└═ąŻ¼ŠWĮj═©Ģ│╩ŪįŲėŗ╦ŃĘ■䚥─Ė∙▒Š▒ŻšŽĪŻVDCĘ■äšģ^ė“ā╚▓┐Ą─╬’└Ēų„ÖC▀BĮė(▒ŠĄžŠW)Īó┐ńė“š{Č╚Ą─▀BĮė(ų„Ė╔ŠW)Īóī”═Ō╠ß╣®Ę■䚥─śIäš▀BĮė(═ŌŠW)╩Ū▓╗═¼īė┤╬Ą─ŠWĮjŻ¼Ė„ūįĄ─┴„┴┐ĦīÆę¬Ū¾▓╗═¼Ż¼░lō]Ą─╣”─▄ę▓▓╗═¼ĪŻ╦∙ėą┘Yį┤Ą─š{Č╚ĪóéõĘ▌╦ŃĘ©Īó╚▌×─▓▀┬įČ╝▀\ąąį┌ØMūŃĖ„ūįąĶŪ¾Ą─ŠWĮj╔ŽŻ¼ŠWĮj«É│Żįņ│╔Ą─ōĒČ┬▌pätė░Ēæė├涾w“ׯ¼ųžätī¦ų┬Ę■äšųąöÓĪŻęįŽ┬ęįüå±R▀dįŲėŗ╦ŃĘ■äšį°Įø│÷¼FĄ─╩┬╣╩üĒšf├„▀@ę╗³cĪŻ
ĪĪĪĪüå±R▀d╗ź┬ōŠWĮjĘ■äš(Amazon Web ServiceŻ¼║åĘQĪ░AWSĪ▒)Ż¼Ę■äšģ^ė“ā╚▓┐Ą─ų„ÖC▀BĮėĘų×ķā╔ŅÉŻ¼ę╗ŅÉ×ķĖ▀ąį─▄Ą─ĪóĖ▀═╠═┬─▄┴”Ą─▀BĮėÅŚąįėŗ╦ŃįŲ(Elastic Comute CloudŻ¼║åĘQĪ░EC2Ī▒)║═ÅŚąį┤µā”ēK(Elastic Block StoreŻ¼║åĘQĪ░EBSĪ▒)Ą─śI䚊WŻ¼┴Ēę╗ŅÉ×ķĘĆČ©Ą─ĪóĄ══╠═┬─▄┴”Ą─▀BĮėEBS║═╚▌×─┤µā”Ą─éõĘ▌ŠWĪŻ2011─Ļ4į┬21╚šŻ¼AWSŠSūo╣ż│╠Ĥ×ķ▒▒├└─│Ę■äšģ^ė“Ą─EBSöU╚▌Ż¼į┌įOéõ┼cŠWĮjŽÓ▀BĢrŻ¼š`īóEC2┼cEBSų«ķgĄ─▀BĮėĮė╚ļéõĘ▌ŠWŻ¼═¼Ģrįņ│╔┴╦śIäš║═éõĘ▌Ę■䚥─ŠWĮjūĶ╚¹Ż¼ė╔┤╦ė|░l┴╦ę╗ŽĄ┴ąĄ─×─ļyŻ╗
ĪĪĪĪ(1)ę“śIäšōĒČ┬ų▒Įėįņ│╔įōĘ■äšģ^Ą─╠ōöMÖC(VM)¤oĘ©Ēææ¬ī”ēK┤µā”Ą─ūxīæ▓┘ū„Ż¼ė├涤oĘ©ą┬Į©╠ōöMÖCŻ╗
ĪĪĪĪ(2)ę“éõĘ▌Ę■䚥─ŠWĮjōĒČ┬ų▒Įėī¦ų┬13%Ą─╚▌×─┤µā”▒╗öDŽ┬ŠĆŻ╗
ĪĪĪĪ(3)ŠWĮjįOų├╗ųÅ═║¾Ż¼ę“╚▌×─éõĘ▌Ą─ė|░lŻ¼Ų│§¤oĘ©šęĄĮéõĘ▌Ė▒▒ŠĄ─EBS┤¾├µĘe═¼ĢråóäėĖ▒▒ŠųžĮ©Ż¼éõĘ▌ŠWĮjį┘┤╬ōĒČ┬Ż╗
ĪĪĪĪ(4)╚▌×─┤µā”Ž¹║─▀^┐ņŻ¼¤oĘ©šęĄĮéõĘ▌╦∙ąĶ┤µā”┘Yį┤Ą─EBS╩╝ĮK╠Äė┌ųžą┬īżšę┘Yį┤(re-mirroring)Ą─ĀŅæBųąŻ╗
ĪĪĪĪ(5)š{Č╚Ę■äšŲ„Įė╩š▓╗ĄĮEBSĄ─éõĘ▌Ę┤üŻ¼▀M│╠¤oĘ©ßīĘ┼Ż¼▀M│╠öĄ║▄┐ņš╝ØMŻ¼ķ_╩╝Š▄Į^Įė╩šą┬Ą─š{Č╚Ę■䚯¼ī¦ų┬Ųõ╦³Ę■äšģ^ė“Ą─šłŪ¾▓╗▒╗Ēææ¬ĪŻ
ĪĪĪĪAWS╗©┴╦3╠ņĢrķgīóįō▀BµiĘ┤æ¬ī¦ų┬Ą─«É│ŻöĄō■┴┐£pąĪĄĮ┴╦0.2%Ż¼1ų▄Ą─ĢrķgūīŽĄĮy═Ļ╚½╗ųÅ═š²│Ż▀\ū„ĪŻė╔┤╦ĮoAWSĦüĒĄ─ĮøØ·ōp╩¦×ķ╣╩šŽĘ■äšģ^ė“10╠ņĄ─ĀIśIŅ~(AWS×ķčaāöė├æ¶ū„│÷Ą─øQ▓▀)Ż╗╣╩šŽ░l╔·Ų┌ķgĮoė├æ¶Ä¦üĒĄ─ōp╩¦╩Ū¤oĘ©╣└┴┐Ą─Ż¼Ų┌ķgėąöĄ10éĆŠWšŠė├æ¶Ą─šŠ³c¤oĘ©åóäė║═▒╗įLå¢ĪŻ
ĪĪĪĪ«ö╚╗Ż¼▀@└’▓╗╩Ū░Ą╩Šį┌VDC╝▄śŗįOėŗĄ─Ģr║“į┌╦∙ėąĄ─ŠWĮj▀BĮė╔ŽČ╝╩╣ė├Ė▀╦┘ĪóĖ▀═╠═┬┴┐Ą─įOéõŻ¼Č°╩ŪÅŖš{į┌ū÷ĮM╝■╝▄śŗĪóųŲČ©╚▌×─▓▀┬įĄ─Ģr║“ąĶę¬│õĘų┐╝æ]ŠWĮj─▄┴”ęį╝░ųŲČ©║Ž└ĒĄ─śIäšĒææ¬▀ē▌ŗĘĮ░ĖüĒæ¬ī”│÷¼FŠWĮjōĒČ┬Ą─ŪķørĪŻ
ĪĪĪĪ4.1.2ų„┤µā”┼c╚▌×─┤µā”Ą─┤µā”─Ż╩Įģ^äe
ĪĪĪĪśIäšöĄō■║═╚▌×─öĄō■ī”Ąūīė┤µā”Ą─ąĶŪ¾▓╗═¼Ż¼╩╣ė├Ą─┤µā”įOéõę▓▓╗═¼Ż¼▒Ē1┴ą┼e┴╦śIäš┤µā”(ų„┤µā”)║═╚▌×─┤µā”Ą─ąĶŪ¾ģ^äeĪŻ

ĪĪĪĪė├æ¶╚š│ŻśIäšąĶꬥ─ĪóVDC╠ß╣®IaaSĘ■äš▒ž▓╗┐╔╔┘Ą─╬’└Ē┤µā”įOéõ╝┤×ķų„┤µā”Ż¼ų„┤µā”╠ß╣®─Ż░ÕÄņ║═ÅŚąį┤µā”Ę■äšĪŻ─Ż░ÕÄņųąĄ─ńRŽ±öĄō■×ķę╗┤╬īæČÓ┤╬ūxŻ¼į╩įSäh│²Ż¼▀B└mI/OĄ─ąĶŪ¾┐╔Ė▀▀_Äū╩«GBŻ╗ÅŚąį┤µā”×ķė├æ¶öĄō■Ż¼ČÓ┤╬ūxČÓ┤╬īæŻ¼į╩įSäh│²Ż¼▀B└mI/OĄ─ąĶŪ¾▓╗╣╠Č©ĪŻ×ķ▀_ĄĮūŅ╝čĄ─ė├涾w“ׯ¼ų„┤µā”ąĶę¬ūŅ┐ņĄ─┤┼▒P║═ūŅ┐ņĄ─┼cėŗ╦ŃĘ■䚎Ó▀BĄ─ŠWĮjĪŻ
ĪĪĪĪ╚▌×─┤µā”┐╔ų▒ė^└ĒĮŌ│╔ų„┤µā”Ą─Ė▒▒ŠŻ¼éõĘ▌/Å═ųŲę╗░Ń░┤šš╣╠Č©Ą─ķgĖ¶▀MąąŻ¼ę╗┤╬īæČÓ┤╬ūxŻ¼ėąäh│²▓┘ū„Ż¼▀B└mI/OĄ─ąĶŪ¾ę╗░Ń×ķÄū╩«GBŻ¼╦┘Č╚ę¬Ū¾▓╗Ė▀Ż¼Ą½▒žĒÜę¬Ū¾ĘĆČ©┐╔┐┐ĪŻ╚▌×─┤µā”║═ų„┤µā”ų«ķgĄ─ŠWĮj▓╗ę¬Ū¾┐ņ╦┘Ż¼Ą½ąĶꬎÓī”Š∙ä“Ą─┴„┴┐ĪŻ
ĪĪĪĪ┤╦═ŌŻ¼×ķā×╗»┤µā”įOų├Ż¼▀Ć┐╔ęįÅ─╬─╝■ŽĄĮyĪó┤µā”Ė±╩ĮĄ╚ĘĮ├µ×ķų„┤µā”║═╚▌×─┤µā”įOČ©▓╗═¼Ą─ÖCųŲĪŻ×ķų„┤µā”▀Mąą║Ž▀mĄ─RAIDįOų├Ż¼▒ŻūCąį─▄ĘĆČ©Ą─═¼ĢrĮĄĄ═│╔▒ŠŻ╗×ķ╚▌×─┤µā”įOų├īŻķTų¦│ųĄ─╬─╝■ŽĄĮyŻ¼═©▀^Ģrķg┤┴Īóū„š▀ą┼ŽóĄ╚ĖĮ╝ėī┘ąįīŹ¼F═¼├¹╬─╝■Ą─░µ▒Šģ^ĘųŻ¼═©▀^ē║┐sĪó│²ųž▓▀┬įīŹ¼F┤µā”┐šķgĄ─╣Ø╩ĪĪŻ
ĪĪĪĪ4.2╚▌×─▓▀┬įę¬Ū¾
ĪĪĪĪ╚▌×─Ą──┐Ą─╩Ūį┌ų„öĄō■░l╔·╣╩šŽęį║¾Ż¼═©▀^└¹ė├╚▌×─┤µā”Ą─╚▀ėÓöĄō■üĒ╗ųÅ═æ¬ė├ĪŻ╚▌×─▓▀┬įĄ─╩▄ęµ┐╔ęį┴┐╗»│╔Ųõ×ķė├æ¶═ņ╗žĄ─ų▒Įė║═ķgĮėĄ─ōp╩¦ĪŻ«ö╚▌×─╩šęµ┤¾ė┌▓┐╩│╔▒ŠĢrŻ¼Š═ųĄĄ├╚źīŹ╩®▀@éĆ╚▌×─▓▀┬įĪŻ
ĪĪĪĪ4.2.1éõĘ▌/Å═ųŲĄ─ÖCųŲ
ĪĪĪĪō■éõĘ▌ę╗░Ń╩ŪųĖ└¹ė├éõĘ▌▄ø╝■░čöĄō■Å─┤┼▒PéõĘ▌ĄĮ┤┼Ħ╗“┤┼▒P▀MąąļxŠĆ▒Ż┤µĪŻéõĘ▌öĄō■Ą─Ė±╩Į╩Ū┤┼ĦĖ±╩ĮŻ¼▓╗─▄▒╗śI䚎ĄĮyų▒ĮėįLå¢ĪŻį┌įŁöĄō■▒╗ŲŲē─╗“üG╩¦ĢrŻ¼éõĘ▌öĄō■▒žĒÜė╔éõĘ▌▄ø╝■╗ųÅ═│╔┐╔ė├öĄō■Ż¼▓┼┐╔ūīöĄō■╠Ä└ĒŽĄĮyįLå¢ĪŻ
ĪĪĪĪöĄō■Å═ųŲ╩ŪųĖ└¹ė├Å═ųŲ▄ø╝■░čöĄō■Å─ę╗éĆ┤┼▒PÅ═ųŲĄĮ┴Ēę╗éĆ┤┼▒PŻ¼╔·│╔ę╗éĆöĄō■Ė▒▒ŠĪŻ▀@éĆöĄō■Ė▒▒Š╩ŪśI䚎ĄĮyų▒Įė┐╔ęįįLå¢Ą─Ż¼▓╗ąĶę¬▀Mąą╚╬║╬Ą─öĄō■╗ųÅ═▓┘ū„Ż¼▀@ę╗³c╩ŪÅ═ųŲ┼c┤┼▒PĄĮ┤┼▒P(D2D)éõĘ▌Ą─ūŅ┤¾ģ^äeĪŻÅ═ųŲėų┐╔ęįĘų×ķ═¼▓ĮÅ═ųŲĪó«É▓ĮÅ═ųŲĪóį÷┴┐Å═ųŲĪŻ
ĪĪĪĪ▓╔ė├║╬ĘNéõĘ▌/Å═ųŲÖCųŲ╚ĪøQė┌ŽĄĮyī”RPO(Recovery Point Objective sŻ¼╗ųÅ═³c─┐ś╦)Ą─ę¬Ū¾Ż¼×ķØMūŃ▓╗═¼RPOŻ¼éõĘ▌/Å═ųŲÖCųŲĄ─īŹ¼F│╔▒Šėą║▄┤¾Ą─▓Ņ«ÉŻ¼RPOų▒ĮėøQČ©┴╦éõĘ▌/Å═ųŲÖCųŲĄ─åóäėķgĖ¶ĪŻę╗Ę▌ėąą¦Ą─╚▌×─Ė▒▒Š╩Ū×─ļyüĒ┼RĢr╩╣░c»łĄ─śI䚎ĄĮy╗ųÅ═š²│Ż╣żū„Ą─▒žę¬Śl╝■ĪŻ×ķ▓╗╩╣×─ļyī¦ų┬ų„öĄō■║═╚▌×─öĄō■═¼Ģr╩¦ą¦Ż¼═∙═∙▓╔ė├«ÉĄžéõĘ▌Ą──Ż╩ĮĪŻį┌éõĘ▌/Å═ųŲ▀\ąąĢrŻ¼ąĶę¬ū÷ĄĮ▓╗ė░ĒæśI䚎ĄĮyĄ─Ę■äšąį─▄Ż¼▀@Š═ę¬Ū¾║Ž└ĒĄ─└¹ė├éõĘ▌Ģrķg┤░┐┌Ż¼į┌ŽĄĮyŽÓī”▓╗Ę▒├”Ą─ĢrČ╬▀MąąéõĘ▌╗“Å═ųŲĪŻī”ė┌5 x 8Ą─ĘŪĻPµIŽĄĮyŻ¼éõĘ▌ĢrķgŽÓī”▌^┤¾Ż¼Ą½ī”ė┌7 x 24Ą─ų„ŽĄĮyüĒšfŻ¼éõĘ▌Ģrķg┤░┐┌Š═║▄ąĪŻ¼ąĶę¬═©▀^╝ė┐ņéõĘ▌╦┘Č╚║═īŹ¼Fį┌ŠĆÅ═ųŲüĒĮŌøQĪŻ
ĪĪĪĪūŅ│ŻęŖĄ─RPOĮėĮ³ė┌1╠ņĄ─æ¬ė├Ż¼┐╔ęį▓╔ė├├┐ų▄ę╗┤╬╚½┴┐éõĘ▌Īó├┐╠ņę╗┤╬į÷┴┐éõĘ▌Ą─▓▀┬įĪŻ╚ń┤╦½@Ą├Ą─éõĘ▌Ė▒▒ŠĖ³ą┬Ņl┬╩×ķ1╠ņŻ¼ę╗Ą®ų„öĄō■╩¦ą¦Ż¼Č╝─▄ē“╗ųÅ═ų┴1╠ņęįŪ░Ą─öĄō■ĪŻ▀@éĆéõĘ▌ÖCųŲī”ę╗ą®ę¬Ū¾▒╚▌^Ė▀Ą─ą┼Žó╩Ū═Ļ╚½▓╗┐╔Įė╩▄Ą─ĪŻ═©▀^į÷┴┐Å═ųŲ▓▀┬į┐╔ęįØMūŃĖ³ąĪĄ─RPOŻ¼Ą½į÷┴┐Å═ųŲę▓╩Ūę╗ĘNĘŪīŹĢrĄ─Å═ųŲĘĮ╩ĮŻ¼╦³ę└╚╗ąĶę¬ę└┐┐ę╗Č©Ą─▓▀┬į(öĄō■ūā╗»┴┐ķōųĄĪó╚šÜv░▓┼┼Ą╚)üĒåóäėŻ¼į÷┴┐Å═ųŲ┐╔ęįĮY║Ž┐ņšš╝╝ągėąą¦▒ŻūCöĄō■Ą─ę╗ų┬ąįĪŻ
ĪĪĪĪī”ė┌RPOĮėĮ³ė┌0Ą─ĻPµIśIäšæ¬ė├Ż¼┐╔ęį▓╔ė├«É▓ĮÅ═ųŲĄ─▓▀┬įĪŻ«É▓ĮÅ═ųŲį┌Ž“ų„ÖCĘĄ╗žīæšłŪ¾┤_šJą┼╠¢ų«║¾īŹĢr▀MąąŻ¼╩Ūę╗ĘNīŹĢrÅ═ųŲ─Ż╩ĮŻ¼ę“┤╦ėųĮą«É▓ĮńRŽ±Ż¼«É▓ĮńRŽ±ī”ė┌▀BĮėśI䚎ĄĮy║═╚▌×─ųąą─Ą─µ£┬ĘĦīÆę¬Ū¾└Ēšō╔Žų╗ąĶ▀_ĄĮĪ░╚šą┬į÷öĄō■┴┐/(24Ī┴3600 x 8)Ī▒╝┤┐╔ĪŻ«É▓ĮńRŽ±Ą─ā×ä▌į┌ė┌ė├ŽÓī”ę╗░ŃĄ─ŠWĮjĦīÆ║═QoSØMūŃĮėĮ³ė┌0Ą─RPOŻ¼Ą½ė╔ė┌Å═ųŲÖCųŲĄ─įŁę“Ż¼¤oĘ©ėąą¦Ą─▒ŻūCöĄō■Ą─ę╗ų┬ąįĪŻ
ĪĪĪĪī”ė┌RPOę¬Ū¾ć└Ė±×ķ0Ą─æ¬ė├Ż¼×─éõ▓▀┬įąĶę¬═Č╚ļĄ─│╔▒ŠūŅĖ▀Ż¼ąĶę¬▓╔ė├═¼▓ĮÅ═ųŲĄ──Ż╩ĮĪŻ═¼▓ĮÅ═ųŲ╩Ūį┌Ž“ų„ÖCĘĄ╗žīæšłŪ¾┤_šJą┼╠¢ų«Ū░īŹĢr▀MąąĄ─Ż¼ę▓Įą═¼▓ĮńRŽ±ĪŻ×ķėąą¦Ą─▒ŻūCöĄō■ę╗ų┬ąįŻ¼ąĶę¬ĻPķ]ų„ÖCŠÅ┤µŻ¼▓óąĶę¬į┌śI䚎ĄĮy║═╚▌×─ųąą─ų«ķg▓╔ė├╣Ō└wų▒▀BĪó▓©ĘųįOéõĄ─ŠWĮj▓┐╩ĪŻ
ĪĪĪĪÅ═ųŲÖCųŲėą╗∙ė┌ų„ÖC║═╗∙ė┌┤µā”ų«ĘųĪŻ╗∙ė┌ų„ÖCĄ─Å═ųŲę╗░Ńė╔░▓čbį┌ų„ÖC╔ŽĄ─Å═ųŲ▄ø╝■üĒīŹ╩®Ż¼Ģ■ė░Ēæų„ÖCŽĄĮyĄ─ąį─▄Ż╗╗∙ė┌┤µā”Ą─Å═ųŲė╔┤µā”įOéõ┐žųŲŲ„╗“╠ōöM╗»┤µā”╣▄└ĒŲĮ┼_ł╠ąąŻ¼╦³¬Ü┴óė┌ų„ÖCŻ¼▓╗Ģ■ī”ų„ÖCŽĄĮyĄ─ąį─▄įņ│╔ė░ĒæĪŻī”ė┌VDCüĒšfŻ¼╦∙ėąĄ─Ę■äšČ╝ąĶę¬╗∙ė┌ŠWĮj╠ß╣®Ż¼éõĘ▌/Å═ųŲė╔ė┌ł╠ąąÖCųŲĄ─▓╗═¼Ż¼┐╔ęį▓╗š╝ė├╬’└Ēų„ÖC┘Yį┤Ż¼Ą½▒ž╚╗Ģ■š╝ė├ŠWĮj┘Yį┤ĪŻ▀@Š═ąĶę¬īóśI䚊WĮj║═×─éõŠWĮjĘųļxŻ¼▓óīŹąą║Ž└ĒĄ─ŠWĮj▒O┐žÖCųŲĪŻ2011─Ļ4į┬21╚šŻ¼AWSĄ─Ę■äšųąöÓ╩┬╣╩│²┴╦╚╦×ķę“╦žų«═ŌŻ¼ę▓ė╔ė┌╚▌×─▀ē▌ŗųąī”ŠWĮj▀BĮė▒O£yĄ─▓╗║Ž└Ēī¦ų┬éõĘ▌▓▀┬į║¾└m┤¾┴┐Ą─ųžńRŽ±ł╠ąąŻ¼įņ│╔┴╦ōĒČ┬ĪŻ
ĪĪĪĪ4.2.2Ė▀┐╔ė├║═žō▌dÖCųŲ
ĪĪĪĪĖ▀┐╔ė├║═žō▌dŠ∙║ŌČ╝╩ŪąĶę¬į┌▒ŠĄžŠW▓┐╩Ż¼ąĶę¬▒ŻūCĖ„ų„ÖCų«ķg├ļ╝ēķgĖ¶Ą─ŅlĘ▒╗ź═©Ż¼ę“┤╦├µŽ“Ą─æ¬ė├ł÷Š░āHßśī”ų„ÖC╩¦ą¦Ż¼¤oĘ©æ¬ī”ūį╚╗×─ļyęį╝░═ŻļŖĪó╗×─Ą╚ĘŪ╝╝ąg×─ļyĪŻ
ĪĪĪĪĖ▀┐╔ė├┐╔ęį▒ŻūCų„ÖCŽĄĮy─▄ē“╠ß╣®24ąĪĢrĄ─▓╗ķgöÓĘ■䚯¼į┌ų„ÖC░l╔·╣╩šŽĢrŻ¼éõÖC─▄ē“ūįäė╝░ĢrÖz£yĄĮ╣╩šŽŻ¼▓óĮė╣▄ų„ÖC░l╔·╣╩šŽĄ─Ę■äš(┐╔ęį╩Ūų„ÖCĄ─╚½▓┐Ę■䚯¼╗“š▀āH░l╔·╣╩šŽ▓┐ĘųĄ─Ę■äš)Ż╗«öéõÖC╣╩šŽĢrŻ¼ų„ÖCÖz£yĄĮ╣╩šŽ▓ó░l╦══©ų¬Įo╣▄└ĒåTŻ¼ęį▒Ń▀Mąą╝┤ĢrŠSūoĪŻžō▌dŠ∙║ŌĄ─╠ž³cį┌ė┌─▄ē“Ęųöé┤¾┴„┴┐Ą─öĄō■Ż¼īó├▄╝»Ą─Ę■äššłŪ¾Ž┬Ę┼ĄĮ╚¶Ė╔éĆŽÓ╗ź¬Ü┴óĄ─ų„ÖC╔ŽĪŻ╚╬ę╗ų„ÖC╩¦ą¦▓ó▓╗ė░Ēæ╦∙╠ß╣®Ę■䚥─▀B└mąįĪŻ
ĪĪĪĪį┌VDCĄ─įŲėŗ╦ŃĘ■äšųąŻ¼┐╔ęį┐╝æ]į┌Ę■äš─ŻēKĄ─å╬³c╣╩šŽ╠Ä▓┐╩Ė▀┐╔ė├Ż¼į┌Ų┐Ņi╠Ä▓┐╩žō▌dŠ∙║ŌŻ¼įöęŖ6╣ØĪŻ
ĪĪĪĪ5Īóė├æ¶æ¬ī”×─ļyĄ─æ¬╝▒┤ļ╩®
ĪĪĪĪVDC×─éõĄ──┐ś╦╩ŪlaaSĘ■䚥─▀B└mąįŻ¼╝┤┘Yį┤╔ĻšłĪó▒O┐žĪó┘~å╬▓ķįāĄ╚śIäš─ŻēKĄ─š²│Ż▀\ąąŻ¼Č°ī”ė┌╠ōöMÖC▒Š╔Ē▓╗╠ß╣®×─éõÖCųŲĪŻę“┤╦×ķ┴╦▀_ĄĮūŅ╝čė├涾w“ׯ¼ė├æ¶│²┴╦░┤Š═Į³įŁät▀xō±Ąž└Ē╬╗ų├ūŅĮ³Ą─Ę■äšģ^ė“▓┐╩ūį╝║Ą─╠ōöMÖC═ŌŻ¼▀ĆąĶę¬Ė∙ō■ūį╔ĒĄ─ąĶę¬ųŲČ©║Ž▀mĄ─╚▌×─▓▀┬įŻ¼▀@ą®╚▌×─╩ųČ╬╩Ū¤oĘ©ė╔VDC┤·ä┌Ą─ĪŻ
ĪĪĪĪ5.1═¼ę╗įŲĘ■äš╠ß╣®╔╠▓╗═¼Ę■äšģ^ų«ķgĄ─╚▌×─▓▀┬įįOų├
ĪĪĪĪVDCĄ─┐ńė“┘Yį┤š{Č╚ąĶ꬚╝ė├┤¾┴┐Ą─ŠWĮj┘Yį┤Ż¼│÷ė┌│╔▒Š┐╝æ]Ż¼ę╗░ŃVDC╠ß╣®╔╠▓╗ų„äė╠ß╣®ė├æ¶öĄō■Ą─┐ńė“éõĘ▌/Å═ųŲĪŻ╚╗Č°ī”ė┌ė├æ¶Č°čįŻ¼┐ńė“Ą─«ÉĄžĖ▒▒Š╩ŪīŹ¼FŲõ▒Š╔ĒöĄō■Ė▀┐╔ė├Ą─▒ŻšŽĪŻ«ÉĄžĖ▒▒Š░³└©╠ōöMÖCńRŽ±─Ż░ÕĪó┤µā”ĪŻVDC╠ß╣®╔╠ę╗░ŃĢ■╠ß╣®╚¶Ė╔éĆś╦£╩Ą─╠ōöMÖCńRŽ±─Ż░ÕŻ¼├┐éĆė├æ¶Č╝─▄╗∙ė┌▀@ą®ś╦£╩─Ż░ÕĮ©┴óūį╝║Ą─╠ōöMÖCĪŻė├æ¶ī”╠ōöMÖC┐╔ęį▀MąąéĆąį╗»Ą─┼õų├║═š{š¹Ż¼äh│²ČÓėÓĄ─│╠ą“ĪóĻPķ]ČÓėÓĄ─Ę■äšČ╦┐┌Ż¼ęįā×╗»ūį╔Ē▓┐╩Ą─æ¬ė├ĪŻę╗éĆĮĪ┐ĄĄ─ė├æ¶╠ōöMÖCæ¬░³║¼│²öĄō■ęį═ŌĄ─╦∙ėąĘ■äš─ŻēK╝░╦∙ąĶĄ─▀\ąąĢrŁhŠ│ĪŻ«ö▀@śėĄ─╠ōöMÖCįOų├Īóš{įć═Ļ│╔Ż¼═Č╚ļ╩╣ė├║¾Ż¼ė├æ¶ąĶę¬ī”įō╠ōöMÖCńRŽ±ū÷éõĘ▌Ż¼īóŲõū„×ķéĆąį╗»Ą──Ż░ÕŻ¼▓ó▒ŻūC▀@éĆ─Ż░Õį┌╦∙ėąĄ─Ę■äšģ^ė“ā╚Č╝Š▀éõ¬Ü┴óĄ─Ė▒▒ŠĪŻ▀@śė▓┼─▄▒ŻūCį┌╚╬║╬Ģr║“Ż¼į┌╚╬-Näšģ^ė“Ż¼ė├æ¶Č╝─▄┐ņ╦┘äōĮ©ŽÓ═¼Ą─éĆąį╗»╠ōöMÖCīŹ└²ĪŻ═©▀^╚ń┤╦ņ`╗ŅįOų├Ą─éĆąį╗»─Ż░Õ┐╔ęį╩╣Ą├VDC╔Žė├æ¶ūį╔ĒĘ■䚥─RTO▀hąĪė┌╗∙ė┌╬’└Ēų„ÖCĄ─RTOĪŻ
ĪĪĪĪī”ė┌┤µā”Č°čįŻ¼ė├æ¶ąĶę¬ūįąąįOČ©┐ńĘ■äšģ^ė“Ą─éõĘ▌║═Å═ųŲ▓▀┬įŻ¼į┌║Ō┴┐ūį╔ĒĘ■䚥─RPOS~│╔▒Š║¾▀MąąīŹļH▓┐╩Ż¼▓┐╩ĘĮ╩Į┼c4.2.1╣ØĄ─├Ķ╩÷ŅÉ╦ŲŻ¼▀@└’▓╗į┘┘ś╩÷ĪŻ
ĪĪĪĪ5.2▓╗═¼įŲ╠ß╣®╔╠ų«ķgĄ─╚▌×─
ĪĪĪĪ┐ń▓╗═¼VDC╠ß╣®╔╠Ą─╚▌×─▓▀┬į┐╝æ]Ą─╩Ūæ¬ī”å╬ę╗VDC╠ß╣®╔╠śIäš═Żų╣Ą─’LļUĪŻ╬’└Ē×─ļy░l╔·Ņl┬╩▌^ąĪŻ¼Ą½ĮøĀI─Ż╩ĮĪóśIäšĘČć·Ą─ūā╗»ļSĢrļSĄžČ╝į┌░l╔·Ż¼ę“┤╦ė├æ¶æ¬ė├Ą─▓┐╩╝░×─éõ▓▀┬įæ¬įō┐╝æ]ĄĮVDC╠ß╣®╔╠īė├µĄ─╚▀ėÓĪŻ
ĪĪĪĪ5.2.1ų„Īóéõ╠ß╣®╔╠ų«ķgĘ■䚥─ę└┘ćĻPŽĄ
ĪĪĪĪ▀x╚Īéõė├╠ß╣®╔╠Ą─įŁätæ¬┼c▀x╚Īų„╠ß╣®╔╠Ą─įŁätę╗ų┬Ż¼ąĶę¬│õĘų┐╝æ]Ųõ─▄ē“╠ß╣®Ą─Ę■äš─▄┴”Ż¼Č°Ūęų„Īóéõ╠ß╣®╔╠ų«ķg▓╗┤µį┌śIäš╔ŽĄ─ŽÓ╗źę└┘ćĻPŽĄĪŻ╚ń╣¹éõė├╠ß╣®╔╠Ą─╬’└ĒįO╩®ę└┘ćė┌ų„╠ß╣®╔╠Ż¼─Ū├┤«öų„╠ß╣®╔╠Ą─įŲėŗ╦ŃĘ■äšĮKų╣║¾Ż¼éõė├╠ß╣®╔╠Ą─Ę■äšĢ■╩▄ĄĮ▀BĦĄ─ė░ĒæŻ¼ī”įŲėŗ╦ŃĘ■䚥─ė├æ¶üĒšfŠ═╩¦╚ź┴╦╚▌×─Ą─ęŌ┴xĪŻę“┤╦į┌▀x╚Īéõė├╠ß╣®╔╠ĢrŻ¼ė├æ¶æ¬įō┐╝æ]ęįŽ┬įŁätŻ║
ĪĪĪĪ(1)ų„ĪóéõVDC╠ß╣®╔╠ų«ķg▓╗┤µį┌ŽÓ╗źĄ─╬’└ĒįO╩®ūŌ┘UśI䚯╗
ĪĪĪĪ(2)ų„ĪóéõVDC╠ß╣®╔╠Ą─╗∙ĄAįO╩®╣®Įo▓╗ę└┘ćė┌═Ļ╚½ŽÓ═¼Ą─ų▒ī┘ÅS╔╠Ż¼╝┤├┐ę╗éĆVDC╠ß╣®╔╠āHę└┐┐ŲõĪ░¬ÜėąĪ▒Ą─ų▒ī┘įOéõÅS╔╠Č╝ėą─▄┴”┤ŅĮ©│÷─▄ē“╠ß╣®═Ļš¹Ę■䚥─IaasĘ■äš╝▄śŗĪŻ
ĪĪĪĪ5.2.2╗∙ė┌ų„Īóéõ╠ß╣®╔╠Ą─╚▌×─▓▀┬į
ĪĪĪĪ5.2.2.1╩╣ė├éõė├╠ß╣®╔╠ū÷éõĘ▌
ĪĪĪĪ▀@└’╦∙šfĄ─éõĘ▌āHųĖöĄō■éõĘ▌Ż¼ėąĻPéõĘ▌ķgĖ¶Ą─▀xČ©
ĪĪĪĪ┼c4.2.1╣Ø├Ķ╩÷Ą─įŁätę╗ų┬ĪŻ▀@└’ąĶę¬ūóęŌĄ─╩ŪŻ¼▓╗═¼VDC╠ß╣®╔╠Ą─┤µā”╬─╝■ŽĄĮy▓╗ę╗Č©ŽÓ╗ź╝µ╚▌Ż¼▀@Š═ąĶę¬▀xō±Ę¹║Žūį╝║ąĶŪ¾Ą─éõė├╠ß╣®╔╠ĪŻ╝┤«öąĶę¬╩╣ė├╗ųÅ═▓▀┬įĢrŻ¼Å─éõė├╠ß╣®╔╠Ą─┤µā”Ę■äšųą½@╚ĪĄ─éõĘ▌Ė▒▒Š─▄ē“╝░Ģr▓ó═Ļš¹Ą─é„▌öų┴ų„╠ß╣®╔╠Ż¼▓óŪę─▄ē“▒╗ų„╠ß╣®╔╠Ę■äšųąĮ©┴óĄ─╠ōöMĘ■äšŲ„ūRäe▓ó£╩┤_Ą─ūx╚ĪĪŻ
ĪĪĪĪ5.2.2.2╩╣ė├éõė├╠ß╣®╔╠ŪąōQ▓┐╩
ĪĪĪĪī”ė┌╩╣ė├IaasĘ■䚥─ė├æ¶üĒšfŻ¼─▄ē“į┌ąĶꬥ─Ģr║“į┌éõė├VDC╠ß╣®╔╠╠Ä┤ŅĮ©Ų╠ōöM▀\ąąŁhŠ│╠ß╣®ī”═ŌĘ■äš╩Ū▀xō±éõė├╠ß╣®╔╠Ą─ų„ę¬─┐Ą─ĪŻį┌▀@éĆł÷Š░ųąŻ¼┐╔ęįšJ×ķų„VDC╠ß╣®╔╠Ą─Ę■äšęčĮø═Ļ╚½░c»łŻ¼ęč¤oĘ©Å─ųąūx╚Ī│÷╚╬║╬Ą─ą┼ŽóŻ¼░³└©╠ōöMÖCĄ─┼õų├Īó─Ż░Õęį╝░ė├æ¶öĄō■Ą╚ĪŻ×ķ┴╦į┌éõė├VDC╠ß╣®╔╠Ą─IaaSŁhŠ│ųąŅAŽ╚ū÷║├┐╔ęįåóäėśI䚣hŠ│Ą─╦∙ėą£╩éõŻ¼ė├æ¶ąĶę¬┐╝æ]ęįŽ┬ÄūéĆĘĮ├µŻ║
ĪĪĪĪ(1)éõė├╠ß╣®╔╠ų¦│ųĄ─╬─╝■ŽĄĮyŻ¼═¼5.2.2.1╣ØŻ╗
ĪĪĪĪ(2)į┌éõė├╠ß╣®╔╠╠ÄĄ─öĄō■éõĘ▌Ż¼═¼5.2.2.1╣ØŻ╗
ĪĪĪĪ(3)éõė├╠ß╣®╔╠ų¦│ųĄ─╠ōöMÖC▓┘ū„ŽĄĮyąĶę¬Ę¹║Žė├æ¶╦∙ąĶ▀\ąąĢrĄ─ŁhŠ│Ż╗
ĪĪĪĪ(4)ė├æ¶į┌ų„VDC╠ß╣®╔╠╠Äū÷Ą─├┐ę╗┤╬ŽĄĮyĖ³ą┬Č╝ę¬╝░ĢrĄžĘ┤ė│į┌éõė├╠ß╣®╔╠ųąŻ¼Š▀¾w▒Ē¼F×ķŽĄĮyĖ³ą┬║¾╠ōöMÖC─Ż░ÕĄ─Ė³ą┬Ż¼▓╗═¼VDC╠ß╣®╔╠Ą─Ą─╠ōöMÖC─Ż░Õ▓╗ę╗Č©╝µ╚▌Ż¼▀@ąĶę¬ė├æ¶╩ųäėį┌éõė├VDCŁhŠ│ųąū÷¬Ü┴óĄ─Ė³ą┬Ż╗
ĪĪĪĪ(5)×ķų„ĪóéõVDC╠ß╣®╔╠Ą─Ę■äš▓┐╩▒O┐žĪŻ
ĪĪĪĪ▀@└’╦∙šfĄ─▒O┐ž░³║¼╚²éĆĘĮ├µŻ║š{ė├vDcĘ■äšŲĮ┼_API½@╚ĪĄ─ėąĻP╠ōöMÖCĄ─╚½Šų▒O┐žĪóĖ„╠ōöMÖCīŹ└²Ą─ąį─▄▒O┐žĪóė├æ¶ūį╔Ē▓┐╩Ę■䚥─▒O┐žĪŻ═©▀^▀@╚²ĘĮ├µĄ─▒O┐žė├æ¶▓┼─▄ē“Ą┌ę╗Ģrķgū÷│÷į┌éõė├VDC╠ß╣®╔╠╠Äåóė├Ę■䚥─øQ▓▀ĪŻąĶę¬ūóęŌĄ─╩ŪŻ¼ė╔ė┌▒O┐žĄ──┐Ą─╩Ū×ķ┴╦╝░Ģr░l¼F║═ŅAĘ└ų„╠ß╣®╔╠╦∙╠ß╣®Ą─Ę■äš╩¦ą¦Ż¼ę“┤╦▒O┐ž│╠ą“▒Š╔Ēæ¬įō▓┐╩į┌ŽÓī”ų„Īóéõ╠ß╣®╔╠¬Ü┴óĄ─ŁhŠ│ųąŻ¼ė╔┤╦üĒ▒ŻūCVDC╠ß╣®╔╠Ą─Ę■äš▓╗ė░Ēæ▒O┐ž│╠ą“Ą─š²│Ż▀\ąąĪŻ
ĪĪĪĪ6ĪóVDCĄ─╚▌×─╝▄śŗĮ©ūh
ĪĪĪĪ¤ošō╩ŪVDC╠ß╣®╔╠▀Ć╩ŪVDCė├æ¶Ż¼╚▌×─▓▀┬į▓┐╩Ą──┐Ą─į┌ė┌─▄ē“į┌×─ļyĮĄ┼RĢrį┌RTOŽ▐Č©ĘČć·ā╚╗ųÅ═ų┴Ž▐Č©Ą─RPOĀŅæBŻ¼ę“┤╦Ė„ĘĮĪ░ć└ųöĪ▒Ą─╚▌×─▓▀┬įČ╝æ¬įōū÷Č©Ų┌Ą─č▌ŠÜŻ¼ęį▒Ń╝░Ģr░l¼Få¢Ņ}▓ó▀MąąčaŠ╚Ż¼ūŅ┤¾│╠Č╚Ą─ĮĄĄ═╚╦×ķ╝╝ągąį×─ļyĪŻ▀@└’Įo│÷ę╗éĆ┐╔╣®VDC╠ß╣®╔╠ģó┐╝Ą─╚▌×─╝▄śŗĪŻ
ĪĪĪĪ┤ŅĮ©═Ļ│╔Ą─IaaSĘ■äš╝▄śŗ╩Ū▓┐╩╚▌×─▓▀┬įĄ─Ū░╠߯¼IaaS╝▄śŗłD╚ńłD1╦∙╩ŠĪŻ
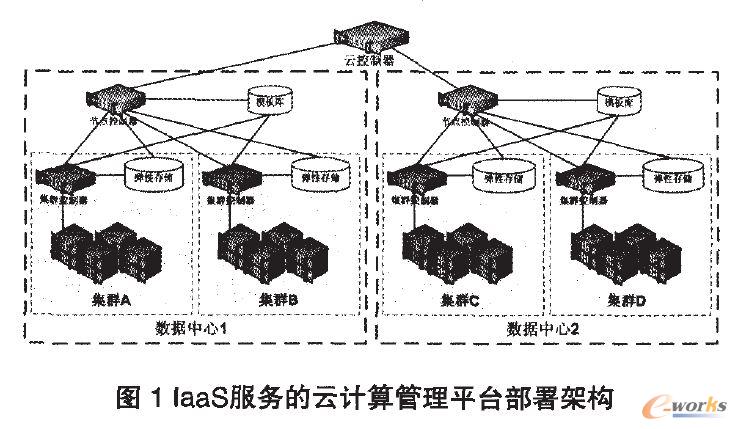
ĪĪĪĪłD1ųą╦∙╩ŠĄ─įŲ┐žųŲŲ„Īó╣سc┐žųŲŲ„Š∙×ķå╬³c╣╩šŽŻ¼×ķ╠ß╔²VDCĄ─Ę■äš┐╔ė├ąįŻ¼┐╔ęį×ķŲõįOų├Ė▀┐╔ė├╝╝ągŻ¼╝»╚║┐žųŲŲ„ąĶę¬ģR┐é╦∙ėąų„ÖCĄ─ŠWĮjžō▌dŻ¼ą╬│╔ĦīÆŲ┐ŅiŻ¼ę“┤╦┐╔ęįįOų├žō▌dŠ∙║Ō╝▄śŗĪŻ┤╦═ŌŻ¼š¹éĆįŲŲĮ┼_Ą─į¬öĄō■Äņę▓Į©ūh╩╣ė├Ė▀┐╔ė├▀Mąą▓┐╩Ż¼╚ńłD2╦∙╩ŠĪŻ
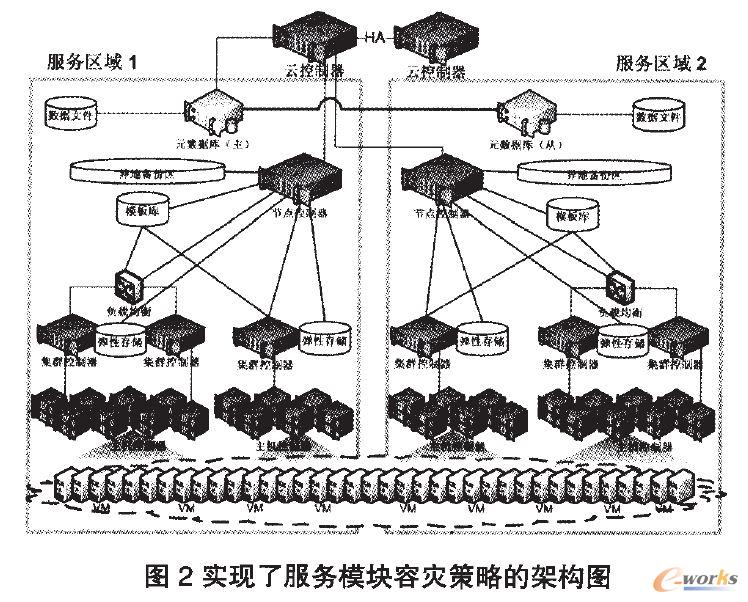
ĪĪĪĪį┌╝▄śŗ╔ŽŻ¼─Ż░ÕÄņĄ─ū„ė├ĘČć·×ķš¹éĆ╣سcŻ¼╗“š¹éĆĘ■äšģ^ė“Ż¼ÅŚąį┤µā”Ą─ū„ė├ĘČć·×ķš¹éĆ╝»╚║ĪŻį┌Ė„ūįĄ─ū„ė├ĘČć·ā╚Ż¼VDC╠ß╣®╔╠欫ö▒ŻūCöĄō■Ą─┐╔ė├ąįŻ¼▓óŪę─Ż░ÕÄņĪóÅŚąį┤µā”Ą─š{ė├ī”╔ŽīėĄ─ė├æ¶═Ė├„ĪŻ└²╚ńAWSĄ─║åå╬┤µā”Ę■äš(Simple Storage ServiceŻ¼║åĘQĪ░S3Ī▒Ę■äš)ļm╚╗┐╔ė├ąį▓╗Ė▀(╝┤Įø│Ż│÷¼F¤oĘ©▀BĮė╗“Ę■äš▓╗┐╔ė├Ą─¼FŽ¾)Ż¼Ą½┐╔ęį▒ŻūCė├æ¶öĄō■▓╗üG╩¦ĪŻį┌Ę■äšģ^ė“ā╚▓┐Ż¼VDC╠ß╣®╔╠Ą─╬’└ĒįOéõµ£Įė╩ŪŽÓī”ĘĆČ©Ą─▒ŠĄžŠWŻ¼╔į╝ėįOų├╝┤┐╔ūŅąĪ╗»éõĘ▌š╝ė├Ą─śIäšÄ¦īÆĪŻī”ė┌┐ńė“┤µā”Ą─éõĘ▌Ż¼ė╔ė┌ąĶ꬚╝ė├│╔▒ŠŽÓī”▌^Ė▀Ą─ų„Ė╔ŠWĦīÆŻ¼ę“┤╦VDC╠ß╣®╔╠▓╗ūįäė×ķ├┐éĆė├æ¶╠ß╣®«ÉĄž╚▌×─Ż¼Ą½┐╔ęįįOų├╚▌×─═©Ą└ė╔ė├æ¶ūįąąČ©ųŲ╩╣ė├ĪŻī”ė┌ė├æ¶Č°čįŻ¼ų╗ąĶ×ķéõĘ▌Ģrš╝ė├Ą─ŠWĮj┴„┴┐║═éõĘ▌Ė▒▒Šš╝ė├Ą─┤µā”┐šķgĖČ┘M╝┤┐╔ĪŻį┌Š▀éõ═Ļ╔ŲĄ─╬’└ĒįOéõų¦ō╬Ą─═¼ĢrŻ¼╚▌×─▓▀┬įĄ─ė|░l╦ŃĘ©ę▓ų┴ĻPųžę¬ĪŻAWSĄ─╩┬╣╩š²╩Ūė╔ė┌╚▌×─ė|░l╦ŃĘ©Ą─▀ē▌ŗ▓╗ć└├▄ī¦ų┬┴╦▀BĦąįĄ─Ę■äšųąöÓŻ¼Ž╚Ū░Ą─╚╦×ķ▓┘ū„╩¦š`ŪĪ║├▒®┬Č┴╦ė|░l╦ŃĘ©Ą─┬®Č┤Ż¼AWS▓┼Ą├ęįįOĘ©ņ¢╣╠ŲõśIäš▀ē▌ŗĪŻę╗░ŃüĒšfŻ¼╗∙ė┌▓╗┐╔┐┐įOéõĮ©┴óĄ─ĘĆČ©┤µā”ŽĄĮyČ╝ąĶę¬ę└┘ćė┌LOCKSS▓▀┬įŻ¼ę“┤╦«öĖ▒▒Š£p╔┘ĢrŻ¼╚▌×─▓▀┬įĢ■ūįäėė|░lĖ▒▒ŠųžĮ©│╠ą“ĪŻī¦ų┬Ė▒▒Š▀ē▌ŗüG╩¦Ą─šTę“ėąČÓĘNŻ¼ūŅŠ▀┤·▒ĒąįĄ─╩Ū┤µā”Įķ┘|╬’└Ēōpē─║═┤µā”Įķ┘|ŠWĮjšłŪ¾▓╗Ēææ¬ĪŻųžĮ©Ė▒▒ŠĄ─═ŠÅĮ╚ń╣¹ę└┘ćė┌ŲõšTę“Ż¼Š═Ģ■│÷¼F╦└裣hĪŻAWSę“×ķŠWĮjōĒČ┬ī¦ų┬▓┐ĘųéõĘ▌Ė▒▒Š▒╗öDŽ┬ŠĆŻ¼╚▌×─▓▀┬įÖz£yĄĮĖ▒▒Š▀ē▌ŗüG╩¦Ģrūįäėė|░l▒ŠĄžŠWĘČć·ā╚Ą─┤µā”╦č╦„▓óĮ©┴óą┬Ą─Ė▒▒ŠŻ¼┤¾┴┐Ą─Ė▒▒ŠųžĮ©ųĖ┴Ņ═¼Ģrė|░l╩╣Ą├ęčĮøōĒČ┬Ą─ŠWĮj┘Yį┤Ė³╝ėōĒČ┬Ż¼▓╗Ą½Ė³╝ėÉ║╗»┴╦╚▌×─▓▀┬įŻ¼ę▓╩╣Ą├š²│ŻśIäšįŌ╩▄┴╦ė░ĒæĪŻ
ĪĪĪĪš²╚ńAWS╣┘ĘĮ┬Ģ├„╦∙čįŻ¼╚ń╣¹ø]ėąŠSūo╣ż│╠ĤĄ─š`▓┘ū„Ż¼╚▌×─ė|░l╦ŃĘ©Ą─▀@ę╗▀ē▌ŗ╚▒Ž▌īó╩╝ĮK┤µį┌Ż¼▓óŪę║▄ļyį┌╚š│ŻĄ─╚▌×─č▌ŠÜųą░l¼FĪŻ▀@Š═šf├„▀ē▌ŗĄ─═Ļ╔ŲąĶę¬į┌īŹ█`ųą┬²┬²Ęe└█Ż¼¼Fį┌┐┤╦Ųć└├▄Ą─▓▀┬įę▓Ģ■┤µį┌ę╗ą®╔ą╬┤▒®┬ČĄ─╚▒Ž▌Ż¼¤ošō╩ŪVDC╠ß╣®╔╠▀Ć╩ŪVDCė├æ¶Ż¼Č╝ąĶę¬į┌IaaSĘ■䚥─╩╣ė├▀^│╠ųą▓╗öÓĄ─═Ļ╔ŲĪóņ¢╣╠Ė„ūįĄ─╚▌×─▓▀┬įĪŻ
ĪĪĪĪ7Īó┐éĮY
ĪĪĪĪ×ķ┴╦æ¬ī”ūį╚╗×─ļyĪó╚╦×ķĘŪ╝╝ąg×─ļy║═╚╦×ķ╝╝ągąį×─ļyŻ¼VDC╠ß╣®╔╠║═VDCė├æ¶Č╝ąĶę¬▓┐╩Ė„ūįūį╔ĒĄ─╚▌×─▓▀┬įĪŻī”ė┌VDCĘ■äš╠ß╣®╔╠üĒšfŻ¼ąĶę¬į┌╬’└Ē┘Yį┤╚ń┤µā”ĪóŠWĮjĪóįŲ╣▄└ĒŲĮ┼_Ą─Ę■äš─ŻēKĄ╚īė├µįOų├┐╔ąąĄ─╚▌×─║═žō▌d▓▀┬įŻ╗ī”ė┌VDCė├æ¶Ż¼│²┴╦ę└┘ćė┌╠ß╣®╔╠Ą─×─éõ▓▀┬į═Ō▀ĆąĶę¬æ¬ī”VDC╠ß╣®╔╠ĮKų╣Ę■䚥─’LļUŻ¼▓╔╚ĪČÓ╠ß╣®╔╠Ą─▓▀┬įĪŻ
ĪĪĪĪ«ö╚╗Ż¼×ķ┴╦╩╣IaaSĘ■äš║═▓┐╩į┌IaaSĘ■äš╔ŽĄ─æ¬ė├ĘĆČ©│ų└mĄ─▀\ąąŻ¼│²┴╦╚▌×─▓▀┬įęį═ŌŻ¼░▓╚½▓▀┬įĄ─▓┐╩ę▓╩Ū║▄ųžę¬Ą─ę╗▓┐ĘųŻ¼▀@╔µ╝░ĄĮVDCÖCĘ┐▒Š╔ĒĄ─IDC░▓╚½Ż¼ęį╝░╠ōöMīėĄ─░▓╚½Ż¼▀@╩ŪVDCĄ─IaaSĘ■äšĮ©įOųą▒žĒÜųž³c┐╝æ]Ą─ę╗▓┐ĘųĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║£\╬÷įŲėŗ╦ŃIaaSĘ■䚥─×─ļyæ¬ī”▓▀┬į
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/1083974415.html






















