



1 ę²čį
įŲėŗ╦Ń╩Ūę╗ĘNą┬ą═Ą─śIäšĮ╗ĖČ─Ż╩ĮŻ¼═¼Ģrę▓╩Ūą┬ą═Ą─IT╗∙ĄAįO╩®╣▄└ĒĘĮĘ©ĪŻ═©▀^ą┬ą═Ą─śIäšĮ╗ĖČ─Ż╩ĮŻ¼ė├æ¶īó═©▀^ŠWĮj│õĘų└¹ė├ā×╗»Ą─ė▓╝■Īó▄ø╝■║═ŠWĮj┘Yį┤Ż¼▓óęį┤╦×ķ╗∙ĄA╠ß╣®äōą┬Ą─śIäšĘ■äšĪŻą┬ą═Ą─IT╗∙ĄAįO╩®╣▄└ĒĘĮĘ©ūīIT▓┐ķT┐╔ęį░č║Ż┴┐┘Yį┤ū„×ķę╗éĆĮyę╗Ą─┤¾┘Yį┤▀Mąą╣▄└ĒŻ¼ų¦│ųIT▓┐ķTį┌┤¾┴┐į÷╝ė┘Yį┤Ą─═¼Ģr¤oąĶ’@ų°į÷╝ėŽÓæ¬Ą─╚╦åT▀MąąŠSūo║═╣▄└ĒĪŻ
2 įŲėŗ╦ŃŽÓĻP╝╝ąg
(1)╠ōöM╗»
╠ōöM╗»┐╔ęį┤¾Ę∙Č╚╠ßĖ▀ĮM┐Ś▀^│╠ųą┘Yį┤║═æ¬ė├│╠ą“Ą─ą¦┬╩║═┐╔ė├ąįĪŻ╠ōöM╗»░č╬’└Ē┘Yį┤║═ūŅĮK│╩¼FĮoė├æ¶Ą─┘Yį┤▀Mąą┴╦ĘųļxŻ¼īŹļH╔Ž╩Ūę╗éĆ╠µ┤·▀^│╠Ż¼į┌Š▀ėąĮyę╗┴╝║├╝▄śŗįOėŗĄ─╬’└Ē┘Yį┤╔ŽäōĮ©│÷ČÓéĆ╠µ┤·┘Yį┤(╝┤╠ōöM┘Yį┤)Ż¼╠µ┤·┘Yį┤║═╬’└Ē┘Yį┤Š▀ėąŽÓ═¼Ą─Įė┐┌║═╣”─▄Ż¼ī”ė├æ¶üĒšf╠ōöM┘Yį┤Š▀éõ┼c╬’└Ē┘Yį┤ŽÓ═¼Ą─╩╣ė├╣”─▄Ż¼═¼Ģr▀Ć┐╔ęįėą▓╗═¼Ą─ī┘ąįŻ¼╚ńārĖ±Īó╚▌┴┐Īó┐╔š{š¹ąįĄ╚ĪŻ
(2)ūįäė╗»▓┐╩
įŲėŗ╦ŃĄ─ę╗éĆ║╦ą─╦╝Žļ╩Ū═©▀^ūįäė╗»Ą─ĘĮ╩Į▒M┐╔─▄Ąž║å╗»╚╬䚯¼╩╣Ą├ė├æ¶┐╔ęį═©▀^ūįų·Ę■äšĘĮ╩Į┐ņĮ▌Ąž½@╚Ī╦∙ąĶĄ─┘Yį┤║═─▄┴”ĪŻ▓┐╩╩Ū╗∙ĄAįO╩®╣▄└Ēųą╩«Ęųųžę¬Ż¼ę▓╩ŪąĶę¬╗©┘M║▄┤¾╣żū„┴┐Ą─ę╗▓┐ĘųŻ¼░³└©▓┘ū„ŽĄĮyĪóųąķg╝■║═æ¬ė├Ą╚▓╗═¼īė┤╬Ą─▓┐╩ĪŻūįäė╗»▓┐╩┐╔╠ß╣®║å╗»┴„│╠Ż¼ė├æ¶╠ß│÷╔Ļšł║¾ė╔ūįäė╗»▓┐╩ŲĮ┼_Ė∙ō■š{Č╚║═ŅA╝sūįäė═Ļ│╔ŽÓæ¬Ą─▓┐╩Ż¼ę“┤╦ė├æ¶ų╗ąĶ╗©╩«ÄūĘųńŖŻ¼╔§ų┴ÄūĘųńŖŠ═┐╔ęįĄ├ĄĮę╗éĆ═Ļš¹Ą─ŁhŠ│Ż¼śO┤¾Ąž╠ßĖ▀┴╦╣żū„ą¦┬╩ĪŻ
(3)æ¬ė├ęÄ─ŻöUš╣
įŲėŗ╦Ń╠ß╣®┴╦ę╗éĆŠ▐┤¾Ą─┘Yį┤│žŻ¼Č°æ¬ė├Ą─╩╣ė├ėųėą▓╗═¼Ą─žō▌dų▄Ų┌Ż¼Ė∙ō■žō▌dī”æ¬ė├Ą─┘Yį┤▀MąąäėæB╔ņ┐s┐╔ęį’@ų°╠ßĖ▀┘Yį┤Ą─ėąą¦└¹ė├┬╩Ż¼╝┤Ė▀žō▌dĢräėæBöUš╣┘Yį┤Ż¼Ą═žō▌dĢrßīĘ┼ČÓėÓĄ─┘Yį┤Ż¼▀@Š═╩Ūæ¬ė├ęÄ─ŻöUš╣╝╝ąg╦∙ĮŌøQĄ─å¢Ņ}ĪŻįō╝╝ągęįæ¬ė├×ķ╗∙▒Šå╬╬╗Ż¼×ķ▓╗═¼Ą─æ¬ė├╝▄śŗįOČ©▓╗═¼Ą─╝»╚║ŅÉą═Ż¼├┐ę╗ĘN╝»╚║ŅÉą═Č╝ėą╠žČ©Ą─öUš╣ĘĮ╩ĮŻ¼╚╗║¾═©▀^▒O┐žžō▌dĄ─äėæBūā╗»Ż¼ūįäė×ķæ¬ė├╝»╚║į÷╝ė╗“š▀£p╔┘┘Yį┤ĪŻ
(4)Ęų▓╝╩Į╬─╝■ŽĄĮy
Ęų▓╝╩Į┤µā”Ą──┐ś╦╩Ū└¹ė├įŲŁhŠ│ųąČÓ┼_Ę■äšŲ„Ą─┤µā”┘Yį┤üĒØMūŃå╬┼_Ę■äšŲ„╦∙▓╗─▄ØMūŃĄ─┤µā”ąĶŪ¾ĪŻŲõ╠žš„╩ŪŻ¼┤µā”┘Yį┤─▄ē“▒╗│ķŽ¾▒Ē╩Š║═Įyę╗╣▄└ĒŻ¼▓óŪę─▄ē“▒ŻūCöĄō■ūxīæ┼c▓┘ū„Ą─░▓╚½ąįĪó┐╔┐┐ąįĄ╚Ė„ĘĮ├µĄ─ę¬Ū¾ĪŻ
įŲėŗ╦Ń┤▀╔·┴╦ę╗ą®ā׹ѥ─Ęų▓╝╩Į╬─╝■ŽĄĮy║═įŲ┤µā”Ę■äšĪŻūŅĄõą═Ą─įŲŲĮ┼_Ęų▓╝╩Į╬─╝■ŽĄĮy╩ŪGoogieĄ─GFS(Coogle file system)║═ķ_į┤Ą─HadoopĪŻ▀@ā╔ĘN┐╔╔ņ┐sĄ─Ęų▓╝╩Į╬─╝■ŽĄĮy└¹ė├╚▌Õe║═╣╩šŽ╗ųÅ═ÖCųŲŻ¼ėąą¦Ąž┐╦Ę■┴╦å╬╣سc╣╩šŽī¦ų┬Ą─ŽĄĮy╣╩šŽŻ¼īŹ¼F┴╦┤¾ęÄ─Ż║Ż┴┐╝ēĄ─╬─╝■┤µā”ĪŻ
ęįHadoop╬─╝■ŽĄĮy×ķ└²Ż¼Hadoop╬─╝■ŽĄĮy(HDFS)╩Ūę╗éĆ▀\ąąį┌Ųš═©ė▓╝■ų«╔ŽĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼╦³║═¼FėąĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyėąų°║▄ČÓŽÓ╦ŲąįĪŻ╚╗Č°Ż¼┼cŲõ╦¹Ęų▓╝╩Į╬─╝■ŽĄĮyĄ─ģ^äeę▓╩Ū║▄├„’@Ą─Ż║HDFS╩ŪĖ▀╚▌ÕeąįĄ─ĪŻ┐╔ęį▓┐╩į┌Ą═│╔▒ŠĄ─ė▓╝■╔ŽŻ¼HDFSĖ▀═╠═┬┴┐Ąžī”æ¬ė├│╠ą“▀MąąöĄō■įLå¢Ż¼╦³▀m║Ž┤¾öĄō■╝»Ą─æ¬ė├│╠ą“Ż¼HDFSĘ┼ķ_ę╗ą®POSIXĄ─ąĶŪ¾╚źīŹ¼F┴„╩ĮĄžįLå¢╬─╝■öĄō■ĪŻę╗éĆHDFS╝»╚║ė╔ę╗éĆ╣▄└Ē╬─╝■ŽĄĮyį¬öĄō■Ą─Name Node║═┤µā”īŹļHöĄō■Ą─ę╗ą®Data NodeĮM│╔ĪŻ
(5)Ęų▓╝╩ĮöĄō■Äņ┼cĘŪĮYśŗ╗»öĄō■┤µā”
į┌Ęų▓╝╩Į╬─╝■ŽĄĮy╔ŽŻ«Ąõą═Ą─┤µā”║Ż┴┐ĮYśŗ╗»öĄō■Ą─Ęų▓╝╩Į┤µā”ŽĄĮy░³└©GoogleĄ─BigTableĪóķ_į┤Ą─HBaseĄ╚ĪŻ▀@ą®ŽĄĮy┐╔īóĘŪĮYśŗ╗»öĄō■(╚ńŠWĒōĄ╚)┤µā”×ķĘų▓╝╩ĮĄ─ĪóČÓŠSĄ─Īóėąą“Ą─łDĪŻ
ęįHBase×ķ└²ĪŻHBase╩Ūę╗éĆĘų▓╝╩ĮĄ─Īó├µŽ“┴ąĄ─ķ_į┤öĄō■ÄņĪŻHBase╩ŪApacheĄ─HadoopĒŚ─┐Ą─ūėĒŚ─┐Ż¼HBaseį┌Hadoop╔Ž╠ß╣®┴╦ŅÉ╦Ųė┌BigtableĄ──▄┴”ĪŻHBase▓╗═¼ė┌ę╗░ŃĄ─ĻPŽĄöĄō■ÄņĪŻ╦³╩Ūę╗éĆ▀m║Žė┌ĘŪĮYśŗ╗»öĄō■┤µā”Ą─öĄō■ÄņĪŻ┴Ēę╗éĆ▓╗═¼╩ŪŻ¼HBase╗∙ė┌┴ąĄ─Č°▓╗╩Ū╗∙ė┌ąąĄ──Ż╩ĮĪŻHBase╩╣ė├║═BigtableĘŪ│ŻŽÓ╦ŲĄ─öĄō■─Żą═ĪŻė├æ¶┤µā”öĄō■ąąį┌ę╗éĆ▒Ē└’ĪŻę╗éĆöĄō■ąąōĒėąę╗éĆ┐╔▀xō±Ą─µI║═╚╬ęŌöĄ┴┐Ą─┴ąĪŻ▒Ē╩Ū╩Ķ╦╔┤µā”Ą─Ż¼ę“┤╦ė├æ¶┐╔ęįĮoąąČ©┴xĖ„ĘN▓╗═¼Ą─┴ąĪŻHBaseų„ę¬ė├ė┌ąĶę¬ļSÖCįLå¢Ż¼īŹĢrūxīæ┤¾öĄō■ĪŻį┌ŽĄĮy╝▄śŗ╔ŽŻ¼HBaseĘų│╔Master┼cRegion Serverā╔▓┐Ę▌ĪŻMasteržōž¤Ėµų¬clientī”ę╗éĆ▒ĒįLå¢ĢrŻ¼æ¬įō▐DŽ“──┼_Region ServerŻ¼Č°Region ServerŠ═╩ŪīŹļH╔Ž╠ß╣®öĄō■Ą─╣سcĪŻ
(6)Ęų▓╝╩Įėŗ╦Ń
╗∙ė┌įŲŲĮ┼_Ą─ūŅĄõą═Ą─Ęų▓╝╩Įėŗ╦Ń─Ż╩Į╩ŪMapReduceŠÄ│╠─Żą═ĪŻMapReduceīó┤¾ą═╚╬äšĘų│╔║▄ČÓ╝Ü┴ŻČ╚Ą─ūė╚╬䚯¼▀@ą®ūė╚╬äšĘų▓╝╩Įį┌ČÓéĆėŗ╦Ń╣سc╔Ž▀Mąąš{Č╚║═ėŗ╦ŃŻ¼Å─Č°į┌įŲŲĮ┼_╔Ž½@Ą├ī”║Ż┴┐öĄō■Ą─╠Ä└Ē─▄┴”ĪŻĖ┼─ŅĪ░Map(ė│╔õ)Ī▒║═Ī░Reduce(╗»║å)Ī▒Ą─ų„ę¬╦╝ŽļČ╝╩ŪÅ─║»öĄ╩ĮŠÄ│╠šZčį└’ĮĶüĒĄ─Ż¼▀ĆėąÅ─╩Ė┴┐ŠÄ│╠šZčį└’ĮĶüĒĄ─╠žąįĪŻ«öŪ░Ą─▄ø╝■īŹ¼F╩ŪųĖČ©ę╗éĆMap(ė│╔õ)║»öĄŻ¼ė├üĒ░čę╗ĮMµIųĄī”ė│╔õ│╔ę╗ĮMą┬Ą─µIųĄī”Ż¼ųĖČ©▓ó░lĄ─Reduce(╗»║å)║»öĄŻ¼ė├üĒ▒ŻūC╦∙ėąė│╔õĄ─µIųĄī”ųąĄ─├┐ę╗éĆ╣▓ŽĒŽÓ═¼Ą─µIĮMĪŻ║åå╬šfüĒŻ¼ę╗éĆė│╔õ║»öĄŠ═╩Ūī”ę╗ą®¬Ü┴óį¬╦žĮM│╔Ė┼─Ņ┴ą▒ĒĄ─├┐ę╗éĆį¬╦ž▀MąąųĖČ©Ą─▓┘ū„ĪŻ╩┬īŹ╔ŽŻ¼├┐éĆį¬╦žČ╝╩Ū▒╗¬Ü┴ó▓┘ū„Ą─Ż¼Č°įŁ╩╝┴ą▒Ēø]ėą▒╗Ė³Ė─Ż¼ę“×ķ▀@└’äōĮ©┴╦ę╗éĆą┬Ą─┴ą▒ĒüĒ▒Ż┤µą┬Ą─┤░ĖĪŻę▓Š═╩ŪšfŻ¼Map▓┘ū„╩Ū┐╔ęįĖ▀Č╚▓󹹥─Ż¼▀@ī”Ė▀ąį─▄ę¬Ū¾Ą─æ¬ė├ęį╝░▓óąąėŗ╦ŃŅIė“Ą─ąĶŪ¾ĘŪ│Żėąė├ĪŻReduce▓┘ū„ųĖĄ─╩Ūī”ę╗éĆ┴ą▒ĒĄ─į¬╦ž▀Mąą▀m«öĄ─║Ž▓óĪŻļm╚╗╦³▓╗╚ńė│╔õ║»öĄ─Ū├┤▓󹹯¼Ą½╩Ūę“×ķ╗»║å┐é╩Ūėąę╗éĆ║åå╬Ą─┤░ĖŻ¼┤¾ęÄ─ŻĄ─▀\╦ŃŽÓī”¬Ü┴óŻ¼╦∙ęį╗»║å║»öĄį┌Ė▀Č╚▓󹹣hŠ│Ž┬ę▓║▄ėąė├ĪŻ
3 æ¬ė├Ęų╬÷
3.1 å¢Ņ}║═¼FĀŅ
ī”ė┌EDC║═śIäšų¦ō╬ŽĄĮyČ°čįŻ¼┤¾┴┐Ą─śIäš╔µ╝░öĄō■Ęų╬÷║═╔╠śIųŪ─▄ĪŻ╚ń╔Ž║ŻļŖą┼Ą─ŽÓĻPŽĄĮy░┤┤¾ŅÉ┐╔äØĘų×ķBSSĪóMSSĪóOSSĪóEDIĄ╚Ż╗░┤Š▀¾wæ¬ė├ŽĄĮyätĘų×ķėŗ┘MĪóCRMĪóDWĪóŠC║ŽĮY╦ŃĪóŠWÅdĪóOAĪóERPĪóķTæ¶ĪóEDWĪó╚½ŽóęĢłDĪóėŗ┘MĘų╬÷ĪóĀIõNĘų╬÷Īó┘Yį┤╣▄└ĒĪóŠC║Ž▒ŻšŽĪóŠC║Žł¾Š»Ą╚ĪŻ▒╦┤╦¬Ü┴óĄ─ŽĄĮyš╝ė├┴╦┤¾┴┐Ą─ė▓╝■┘Yį┤ĪŻė╔ė┌┘Yį┤▒╦┤╦Ė¶ļxŻ¼Ę■äšŲ„Ą─ŲĮŠ∙└¹ė├┬╩ĘŪ│ŻĄ═ĪŻė╔ė┌╔·«aę¬Ū¾Ż¼į┬│§│÷┘~ūóę¬╩Ūł¾▒Ē)Ų┌Ż¼ėŗ╦Ńį·Ččć└ųžŻ¼┘Yį┤ėų├„’@▓╗ūŃĪŻ
═©▀^ī”ļŖą┼EDC║═śIäšų¦ō╬ŽĄĮyĄ─Ęų╬÷Ż¼╬ęéā┐╔ęį┐éĮY│÷ęįŽ┬ÄūéĆśIäš╠žąįĪŻ
(1)Ė▀ąį─▄ėŗ╦ŃĄ─ąĶŪ¾
öĄō■┴┐┤¾Īó▀\╦Ń┴┐┤¾Ą─ŽĄĮy╚ńėŗ┘MĪóCRMĪóEDWĄ╚ī”Ė▀ąį─▄ėŗ╦ŃėąąĶŪ¾ĪŻ╦─┤©ļŖą┼Ą─öĄō■Ęų╬÷Č╝╝▄śŗį┌ąĪą═ÖC╔ŽŻ¼CPU┘Yį┤╚į╚╗▓╗ē“ĪŻļm╚╗ėąę╗ŽĄ┴ąöU╚▌ā×╗»ėŗäØŻ¼Ą½ėŗ╦Ń┼c┘Yį┤ę╗ų▒ėą├¼Č▄ĪŻ╔Ž║ŻļŖą┼Ą─EDA/WS▓┐ķTę▓├µ┼Rßśī”║Ż┴┐öĄō■ū÷Ęų╬÷ł¾▒ĒĄ─ē║┴”Ż¼ė╔ė┌ėŗ╦Ń┘Yį┤ĘųļxŻ¼▓╗─▄╣▓ŽĒŻ¼┘Yį┤└¹ė├┬╩Ą═Ž┬Ż¼─┐Ū░ų„ę¬═©▀^▓╗öÓöU╚▌üĒæ¬ī”ē║┴”ĪŻ
(2)Ģrķg┤░┐┌å¢Ņ}ąĶŪ¾
öĄō■Ęų╬÷Ą─ę╗éĆ═╗│÷å¢Ņ}╩ŪĢrķg┤░┐┌Ż¼▀@į┌╔Ž║ŻļŖą┼║═╦─┤©ļŖą┼Č╝║▄═╗│÷ĪŻė╔ė┌╔·«aę¬Ū¾Ż¼į┬│§│÷┘~(ų„ę¬╩Ūł¾▒Ē)Ų┌Ż¼ėŗ╦Ńį·Ččć└ųžŻ¼┘Yį┤├„’@▓╗ūŃĪŻ─┐Ū░Ą─ų„ę¬ī”▓▀╩ŪŻ¼ī”ė┌ļAČ╬ąįęį╝░═╗░ląįĄ─ū„śIąĶŪ¾▀MąąäėæBš{š¹ęįØMūŃū„śIī”ėŗ╦Ń─▄┴”Ą─ę¬Ū¾ĪŻ╝┤Ż║ī”ė┌ųžę¬śIäšąĶŅA┴¶┘Yį┤Ż¼ī”ė┌Ųõ╦¹śIäšät▀Mąąš{Č╚╣▄└ĒŻ╗į┌│÷┘~Ū░Ż¼Ė∙ō■┘Yį┤ąĶ꬯¼═ŻĄ¶Ą═ā׎╚╝ēĄ─ėŗ╦ŃŻ¼Å─Č°ØMūŃĖ▀ā׎╚╝ēėŗ╦ŃĄ─ąĶŪ¾ĪŻ╚╗Č°Ż¼į┌Ģrķg┤░┐┌ų«═ŌŻ¼ėŗ╦Ń┘Yį┤ėųŽÓī”┐šķeĪŻ
įŲėŗ╦Ńį┌öĄō■Ęų╬÷┼c╔╠śIųŪ─▄Ęų╬÷ųąėąā╔ĘNæ¬ė├─Ż╩ĮĪŻ
×ķļŖą┼ā╚▓┐EDC║═śIäšų¦ō╬ŽĄĮy╠ß╣®öĄō■Ęų╬÷║═╔╠śIųŪ─▄śI䚯¼īŹ¼Fé„ĮyöĄō■Ęų╬÷┼c╔╠śIųŪ─▄æ¬ė├Ą─įŲ╗»ĪŻę¬īŹ¼F┤╦ŅÉæ¬ė├─Ż╩ĮąĶę¬═Ļ│╔ęįŽ┬╣żū„Ż║└¹ė├╠ōöM╗»║═ūįäė╗»Ą╚įŲėŗ╦ŃĻPµI╝╝ągš¹║Ž¼Fėąė▓╝■┘Yį┤Ż╗▓┐╩įŲ─Ż╩ĮöĄō■Ęų╬÷┼c╔╠śIųŪ─▄ŲĮ┼_Ż╗ū±ššįŲ─Ż╩Į▀xō±ąįĄžųžśŗ¼FėąśI䚎ĄĮyųąė├ĄĮĄ─öĄō■Ęų╬÷┼c╔╠śIųŪ─▄Ę■䚯╗īó╔Ž╩÷ė├æ¶╚╬äšš{Č╚ĄĮįŲŲĮ┼_╔Ž▀Mąąėŗ╦ŃŻ¼½@Ą├įŲ─Ż╩ĮĦüĒĄ─║├╠ÄĪŻ
▓╔ė├įŲ─Ż╩Įķ_░lą┬Ą─öĄō■Ęų╬÷┼c╔╠śIųŪ─▄Ę■äšĪŻīŹ¼FŲ¾śIöĄō■Ęų╬÷įŲĪŻę¬īŹ¼F┤╦ŅÉśIäšæ¬ė├─Ż╩ĮąĶę¬ę└═ąš¹║Ž╣▓ŽĒĄ─ė▓╝■┘Yį┤Ż¼į┌įŲ─Ż╩ĮöĄō■Ęų╬÷┼c╔╠śIųŪ─▄ŲĮ┼_╔Žķ_░lą┬Ą─Ę■䚯¼ęįų¦│ųĖ„ŅÉą┬┼dĄ─æ¬ė├─Ż╩Į║═ąĶŪ¾(╚ńŻ║ęŲäė╔ńĮ╗ŠWĮjŻ¼╗∙ė┌┐═æ¶╔ńĮ╗ŠWĮjĄ─┐═æ¶ārųĄ░l¼F║═ĀIõNŻ╗┐═æ¶Ęų╚║Ż¼╗∙ė┌ė├æ¶Ąž└Ē╬╗ų├║═▄ē█EĄ─ą┼ŽóĘ■äš║═ÅVĖµ═Ų╦═Ą╚)ĪŻ
3.2 Ąõą═Ą─æ¬ė├ł÷Š░
▒Š╣ØĻU╩÷ÄūéĆĄõą═Ą─└¹ė├öĄō■Ęų╬÷║═╔╠śIųŪ─▄įŲŲĮ┼_Ą─ą┬öĄō■Ęų╬÷śI䚯¼░³└©┐═æ¶┴„╩¦Ęų╬÷Īó┐═æ¶╔ń╚║░l¼FĪó┐═æ¶ČÓųž╔ĒĘ▌ūRäeŻ¼┐═æ¶ārųĄ░lŠ“ĪŻ╔Ž╩÷Ąõą═æ¬ė├║Ł╔w┴╦įŲ─Ż╩ĮöĄō■Ęų╬÷┼c╔╠śIųŪ─▄ŲĮ┼_╠ß╣®Ą─öĄō■═┌Š“║═╔ńĢ■ŠWĮjĘų╬÷╣”─▄ĪŻ╚╗Č°Ż¼įōŲĮ┼_▓ó▓╗āHŽ▐ė┌ų¦│ųęį╔ŽśI䚯¼é„ĮyĄ─Ė„ŅÉöĄō■Ęų╬÷śI䚊∙┐╔═©▀^Č©ųŲ╗»ķ_░lŻ¼ęŲų▓ĄĮįōŲĮ┼_╔ŽĪŻ
(1)┐═æ¶┴„╩¦Ęų╬÷
ßśī”«öŪ░ųąć°ļŖą┼CŠW┐═æ¶┴„╩¦ć└ųžĄ─¼FŽ¾Ż¼└¹ė├įŲöĄō■Ęų╬÷ŲĮ┼_╠ß╣®Ą─CHAID(chisquared automatic interaction detector)Ą╚┐═æ¶Ęų╚║╦ŃĘ©Ż¼īó┐═æ¶äØĘų×ķĪ░ĘĆČ©┐═æ¶Ī▒║═Ī░Øōį┌┴„╩¦┐═æ¶Ī▒Ż¼Å─Č°┐╔ęįūīųąć°ļŖą┼īóĀIõN┘YĮ═Č╚ļĄĮ═ņ┴¶Ī░Øōį┌┴„╩¦┐═æ¶Ī▒╔ŽŻ¼ėąą¦Ąž╠ßĖ▀ĀIõN┘YĮĄ─╩╣ė├ą¦┬╩ĪŻ
Įø▀^ŪÕŽ┤║═ŅA╠Ä└ĒĄ─┐═æ¶öĄō■Ģ■▒╗╠ßĮ╗Įo▀@éĆæ¬ė├▓ó╝ėęįĘų╬÷ĪŻĘų╬÷▀^│╠░³└©CHAID─Żą═Ą─Į©┴ó║═įu╣└ā╔éĆ▓Į¾EĪŻįu╣└ĮY╣¹Ģ■ęįŅA£y£╩┤_Č╚║═LIFTā╔éĆųĖś╦Ą─ą╬╩Įš╣¼FĪŻ
(2)┐═æ¶╔ń╚║░l¼F
ßśī”ąįĀIõN▓╗āHąĶę¬┴╦ĮŌå╬éĆŅÖ┐═Ą─╠žš„Ż¼Ė³ąĶę¬ūRäe║═└ĒĮŌŅÖ┐═ą╬│╔Ą─Ė„ĘN╔ń╚║ĪŻ╚ńūRäe╝ę═źė├æ¶ą╬│╔Ą─╔ń╚║ĮYśŗŻ¼ī”ė┌╠žČ©ĘNŅÉĄ─śIäšĀIõNĢ■ėą║▄┤¾Ą─Ä═ų·ĪŻ╚╗Č°Ż¼é„ĮyĄ─ĮyėŗĘĮĘ©═∙═∙ų╗ī”┤·▒Ē╔ń╚║ęÄ─ŻĄ─ę╗ą®║åå╬ųĖś╦▀MąąĮyėŗ║═▒╚▌^Ż¼¤oĘ©Ęų╬÷┐═æ¶╔ń╚║ā╚į┌ĮYśŗĄ─▓Ņ«ÉĪŻ
└¹ė├įŲŲĮ┼_BI╦ŃĘ©ÄņųąĄ─▀B═©Ęų┴┐ĪóK-core║═śO┤¾łFĄ╚╦ŃĘ©Ż¼┐╔╔Ņ╚ļĘų╬÷┐═æ¶╔ń╚║Ą─ĮM│╔Ż¼░l¼FŠ▀ėą╔╠śIārųĄĄ─╠ž╩ŌĮYśŗĪŻ╚ńŻ║K-core║═śO┤¾łF╦ŃĘ©Ęų╬÷ę╗éĆŠWĮj╔ńģ^Ż¼┐╔ęį═©▀^Ęų╬÷ĮY╣¹░l¼FŻ¼▓╗═¼╔ń╚║Ą─ā╚▓┐┬ōŽĄŠo├▄│╠Č╚Ą─▓Ņ«É╩Ūʱ║▄┤¾Ż║K-core╦ŃĘ©┐╔ęį½@Ą├ŪÕ╬·Ą─╠«┐są“┴ąŻ¼śO┤¾łF╦ŃĘ©▀MČ°░l¼F┴╦įō╔ń╚║ā╚▓┐ę╗ą®┬ōŽĄŠo├▄Ą─ąĪłF¾wĪŻ
(3)┐═æ¶ČÓųž╔ĒĘ▌ūRäe
į┌Ė„ŅÉ┐═æ¶Ęų╬÷æ¬ė├ųąŻ¼═∙═∙ąĶę¬ūRäeå╬ę╗┐═æ¶Ą─ČÓųž╔ĒĘ▌ĪŻ╚ńį┌ļŖą┼ŠWųąąĶę¬ūRäeųž╚ļŠW┐═æ¶Ż¼į┌ÅVĖµĀIõN╣▄└ĒųąąĶę¬ūRäe╠ō╝┘║├įuĪŻįŲŲĮ┼_╦ŃĘ©Äņ╠ß╣®Ą─éĆ¾wųąą─ŠW║═śO┤¾łFĄ╚╦ŃĘ©Ż¼┐╔ęį▌oų·ūRäeė├æ¶Ą─ČÓųž╔ĒĘ▌ĪŻ
ļŖą┼ŠWųąĄ─ųž╚ļŠW┐═æ¶ūRäeĪŻ└¹ė├ŠWĮjĘų╬÷╦ŃĘ©Äņ╠ß╣®Ą─éĆ¾wųąą─ŠW╦ŃĘ©Ż¼┐╔ęįėŗ╦ŃĄ├ĄĮ├┐éĆ┐═æ¶Ą─┼¾ėčęį╝░┼¾ėčų«ķgĄ─┬ōŽĄŻ¼▀@ę╗ą┼Žó┐╔ęį▒╗┐┤ū„╩Ūįō┐═æ¶Ą─╔ńĢ■ĻPŽĄųĖ╝yĪŻīó▀@ę╗Ęų╬÷╣żŠ▀┼cĢræBĘų╬÷Ą╚╣żŠ▀ŽÓĮY║ŽŻ¼┐╔ęįėąą¦Ąž┼ąöÓę╗éĆ┐═æ¶╩Ūʱ╩Ūįō▀\ĀI╔╠▀^╚ź─│éĆė├æ¶į┘╚ļŠWĄ─╔ĒĘ▌ĪŻ
╠ō╝┘║├įuŻ¼±R╝ūĄ─ūRäeĪŻįŲŲĮ┼_ŠWĮjĘų╬÷╦ŃĘ©Äņ╠ß╣®Ą─śO┤¾łFĄ╚╔ń╚║░l¼F╦ŃĘ©┐╔ęįūRäe┐═æ¶╔ń╚║ųąę╗ą®ėą╚żĄ─ąĪłF¾wĪŻęįŠWĮj╔ńģ^öĄō■×ķ└²Ż¼┐╔░l¼Fę╗ą®░³║¼ā╔éĆė├æ¶Ą─ÅŖśO┤¾łFīŹļH╔Ž╩Ūę╗ą®ė├æ¶Ą─ČÓéĆ╔ĒĘ▌ĪŻ
(4)┐═æ¶ārųĄ░l¼F
é„ĮyĄ─┐═æ¶ārųĄĘų╬÷ĘĮĘ©═∙═∙īó┐═æ¶┐┤ū„╩Ūę╗éĆéƬÜ┴óĄ─éĆ¾wŻ¼ę└ō■┐═æ¶Ą─Įyėŗī┘ąįüĒ┼ąöÓ┐═æ¶Ą─ārųĄĪŻ╚╗Č°Ż¼Įyėŗī┘ąį▓óĘŪėąą¦▒Ēš„┐═æ¶ārųĄĪŻ└¹ė├įŲŲĮ┼_╔ńĢ■ŠWĮjĘų╬÷pagerank║═HITSĄ╚╦ŃĘ©Ż¼┐╔Ęų╬÷┐═æ¶į┌╔ńĢ■ŠWĮjųąĄ─╬╗ų├ī”ŲõārųĄĄ─ė░ĒæŻ¼Å─Č°ėąą¦═┌Š“│÷ārųĄ┐═æ¶ĪŻ
3.3 Ęų▓╝╩Į╝╝ąg─Żą═
öĄō■Ęų╬÷║═╔╠śIųŪ─▄įŲŲĮ┼_Ą─╝╝ąg╝▄śŗ╚ńłD1╦∙╩ŠĪŻ
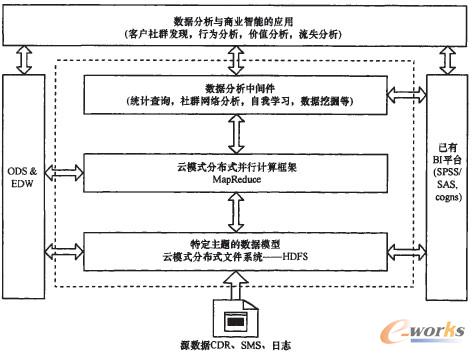
łD1 ╝╝ąg─Żą═
ė╔ęįŽ┬4īėĮYśŗĮM│╔Ż║
ĪżöĄō■Ęų╬÷┼c╔╠śIųŪ─▄Ą─æ¬ė├Ż╗
ĪżöĄō■Ęų╬÷ųąķg╝■(╦ŃĘ©Äņ║═╣żŠ▀)Ż╗
ĪżįŲ─Ż╩ĮĘų▓╝╩Į▓óąąėŗ╦Ń┐“╝▄Ż╗
ĪżįŲ─Ż╩ĮĘų▓╝╩Į╬─╝■ŽĄĮy║═╠žČ©ų„Ņ}Ą─öĄō■─Żą═ĪŻ
Ū░╩÷╣”─▄─Żą═ųąĄ─4éĆŠ▀¾wĘų╬÷æ¬ė├Üwī┘ė┌æ¬ė├īėĪŻŲĮ┼_╬┤üĒīóę¬ų¦│ųĄ─Ė„ĘNæ¬ė├īėśIäš▀ē▌ŗę▓į┌▀@īėČ©ųŲ╗»ķ_░lĪŻ
(1)öĄō■Ęų╬÷ųąķg╝■
▀@īėųąķg╝■╩Ū╝▄śŗį┌Hadoopų«╔ŽŻ¼ū±ššMapReduceėŗ╦Ń─Żą═ķ_░lĄ─ę╗ŽĄ┴ą╦ŃĘ©Äņ║═╣żŠ▀ĪŻ×ķų¦│ų¼FėąĖ„ĘNöĄō■Ęų╬÷║═╔╠śIųŪ─▄æ¬ė├Ż¼▒Šīėæ¬ų┴╔┘░³║¼Įyėŗ▓ķįāĪó╔ńĢ■ŠWĮjĘų╬÷ĪóöĄō■═┌Š“ĪóÖCŲ„īW┴ĢĄ─╦ŃĘ©Äņ║═╣żŠ▀ĪŻ┤╦═ŌŻ¼ļSų°įŲ─Ż╩ĮöĄō■Ęų╬÷┼c╔╠ĪóśIųŪ─▄ŲĮ┼_╝░Ųõæ¬ė├Ą─░lš╣Ż¼▒ŠīėĄ─╦ŃĘ©Äņ║═╣żŠ▀ę▓īó▓╗öÓĄ├ĄĮžSĖ╗║══Ļ╔ŲĪŻ
łD2š╣¼F┴╦ę╗éĆĄõą═Ą─öĄō■Ęų╬÷║═╔╠śIųŪ─▄æ¬ė├┴„│╠Ż¼░³└©å¢Ņ}Č©┴xĪóöĄō■╩š╝»ĪóöĄō■Ęų╬÷ĪóøQ▓▀Īóąąäė/▒O┐ž/īW┴Ģ╝░ŲõĄ³┤·▀^│╠ĪŻ

łD2 ę╗éĆĄõą═Ą─öĄō■Ęų╬÷║═╔╠śIųŪ─▄æ¬ė├┴„│╠
įŲ─Ż╩ĮöĄō■Ęų╬÷┼c╔╠śIųŪ─▄ŲĮ┼_╦∙╠ß╣®Ą─╦ŃĘ©Äņ║═╣żŠ▀īó×ķæ¬ė├╠ß╣®öĄō■Ęų╬÷║═øQ▓▀ā╔éĆŁh╣ØĄ─ų¦│ųĪŻę└═ąŽ┬īėĄ─Hadoop MapReduceĘų▓╝╩Į▓óąąėŗ╦Ń┐“╝▄║═HadoopĘų▓╝╩Į╬─╝■ŽĄĮyŻ¼▒Šīėųąķg╝■▀m║Ž╠Ä└ĒØMūŃŽ┬┴ą╠žš„Ą─öĄō■ĪŻ
ĪżĘŪĮYśŗ╗»╗“░ļĮYśŗ╗»į┤öĄō■Ż¼╚ńCDRĪóČ╠ą┼╚šųŠĄ╚ĪŻ
Īż┤¾ęÄ─ŻöĄō■╝»ĪŻ
Īż┐ņ╦┘į÷ķLĄ─öĄō■╝»(╚ń├┐╚šĖ³ą┬Ą─╩ųÖCė├æ¶Ą─═©įÆ╚šųŠ)ĪŻ
▒Šīėųąķg╝■┼cé„ĮyöĄō■Ęų╬÷┼c╔╠śIųŪ─▄ųąķg╝■ŽÓ▒╚Ż¼Ųõ╠ž³cį┌ė┌Ż║
Īżßśī”║Ż┴┐öĄō■╠ß╣®Ė▀ąįār▒╚Ą─ėŗ╦ŃĘų╬÷Ż╗
Īżę└ĖĮė┌ūŅ═©ė├Ą─įŲėŗ╦ŃŲĮ┼_(Hadoop)╔ŽŻ¼┐╔ėąą¦Ąž┼cŲõ╦¹įŲėŗ╦Ńųąķg╝■▀Mąąģfš{š¹║ŽŻ╗
Īż┐ņĮ▌Ąžų¦│ųĖ„ĘNŅÉą═Ą─╔╠śIųŪ─▄ĮŌøQĘĮ░ĖĄ─ķ_░l║═▓┐╩Ż╗
Īżę└═ąMapReduceŠÄ│╠─Żą═Ż¼┐╔ęįėąą¦ĄžĮ©┴óģfū„╩ĮĄ─Ęų╬÷ų¬ūRÄņĪŻ
(2)įŲ─Ż╩ĮĘų▓╝╩Į▓óąąėŗ╦Ń┐“╝▄
╗∙ė┌įŲŲĮ┼_Ą─ūŅĄõą═Ą─Ęų▓╝╩Įėŗ╦Ń─Żą═╩ŪMapReduceŠÄ│╠─Żą═Ż¼▀@ę▓╩Ū▒ŠŲĮ┼_╩ū▀xĄ─Ęų▓╝╩Į▓óąąėŗ╦Ń─Żą═ĪŻMapReduceīó┤¾ą═╚╬äšĘų│╔║▄ČÓ╝Ü┴ŻČ╚Ą─ūė╚╬䚯¼▀@ą®ūė╚╬äšĘų▓╝╩ĮŪę▓󹹥žį┌ČÓéĆėŗ╦Ń╣سc╔Ž▀Mąąš{Č╚║═ėŗ╦ŃŻ¼Å─Č°į┌įŲŲĮ┼_╔Ž½@Ą├ī”║Ż┴┐öĄō■Ą─╠Ä└Ē─▄┴”ĪŻĖ┼─ŅĪ░Map(ė│╔õ)Ī▒║═Ī░Reduce(╗»║å)Ī▒Ą─ų„ę¬╦╝ŽļČ╝╩ŪÅ─║»öĄ╩ĮŠÄ│╠šZčį└’ĮĶĶbüĒĄ─ĪŻ
ū±ššMapReduceŠÄ│╠─Żą═ĪŻöĄō■Ęų╬÷┼c╔╠śIųŪ─▄╦ŃĘ©ÄņĄ─ķ_░lš▀┐╔ęįŠÄīæę╗éĆMap(ė│╔õ)║»öĄŻ¼ė├üĒ░čę╗ĮMµIųĄī”ė│╔õ│╔ę╗ĮMą┬Ą─µIųĄī”Ż¼▀Ć┐╔ęįŠÄīæę╗éĆReduce(╗»║å)║»öĄĪŻė├üĒ╠Ä└ĒMap║»öĄ«a╔·Ą─µIųĄī”ųąĄ─╣▓ŽĒŽÓ═¼Ą─µIĄ─╦∙ėąµIųĄī”ĪŻ║åå╬šfüĒŻ¼ę╗éĆė│╔õ║»öĄŠ═╩Ūī”ę╗ą®¬Ü┴óį¬╦žĮM│╔Ė┼─Ņ╔Ž┴ą▒ĒĄ─├┐ę╗éĆį¬╦ž▀MąąųĖČ©Ą─▓┘ū„ĪŻ╩┬īŹ╔ŽŻ¼├┐éĆį¬╦žČ╝╩Ū▒╗¬Ü┴ó▓┘ū„Ą─Ż¼Č°įŁ╩╝┴ą▒Ēø]ėą▒╗Ė³Ė─Ż¼ę“×ķ▀@└’īóäōĮ©ę╗éĆą┬Ą─┴ą▒ĒüĒ▒Ż┤µ▓┘ū„Ą─ĮY╣¹ĪŻę“┤╦Ż¼Map▓┘ū„╩Ū┐╔ęįĖ▀Č╚▓󹹥─Ż¼▀@ī”ėąĖ▀ąį─▄ę¬Ū¾Ą─æ¬ė├ęį╝░▓óąąėŗ╦ŃŅIė“Ą─ąĶŪ¾ĘŪ│Żėąė├ĪŻReduce▓┘ū„ät╩Ūī”ę╗éĆ┴ą▒ĒĄ─į¬╦ž▀Mąą▀m«öĄ─║Ž▓óĪŻļm╚╗▓╗╚ńMap║»öĄ─Ū├┤▓󹹯¼Ą½╩Ūę“×ķėąįSČÓĄ─▀\╦Ńųąė├ĄĮĄ─╗»║åČ╝ėą║åå╬Ą─▌ö╚ļ║═╗»║åĮY╣¹ĪŻ╦∙ęįReduce║»öĄį┌Ė▀Č╚▓󹹣hŠ│Ž┬═∙═∙ę▓║▄ėąė├ĪŻ
─┐Ū░Ż¼┤µį┌Ą─MapReduceĘų▓╝╩Į▓óąąėŗ╦Ń┐“╝▄īŹ¼FėąÄūĘNŻ¼ŲõųąūŅų„ꬥ─╩ŪApache Hadoop MapReduceĪŻęčĮøą╬│╔┴╦│╔╩ņ╗Ņ▄SĄ─ķ_░l║═ė├æ¶╔ń╚║ĪŻ▀@ę▓╩Ū▒ŠŲĮ┼_╩ū▀xĄ─ę└═ąĘĮ░ĖĪŻį┌Apache Hadoop MapReduceųąŻ¼Map▓┘ū„║═Reduce▓┘ū„Ą─ł╠ąą▒╗░³╣³×ķ╚╬äš(task)Ż¼Č°╚╬äšėųęįMapReduceī”Ą─ą╬╩Į▒╗░³╣³×ķū„śI(job)Ż¼žōž¤į┌Hadoop╝»╚║╣سc╔Ž░▓┼┼╚╬äšł╠ąąĄ─▄ø╝■▒╗ĘQū„TaskTrackerĪŻ═©│Żį┌├┐éĆėŗ╦Ń╣سc╔Ž▓┐╩ę╗éĆĪŻžōž¤į┌╝»╚║ĘČć·ā╚š{Č╚ū„śI║═╚╬äšł╠ąąĄ─▄ø╝■▒╗ĘQū„JobTrackerŻ¼═©│Żį┌Hadoop╝»╚║ā╚╠¶▀x¬Ü┴óĄ─ÖCŲ„üĒ▓┐╩ĪŻ
(3)╠žČ©ų„Ņ}Ą─öĄō■─Żą═
▒M╣▄MapReduceĘų▓╝╩Į▓󹹊Ä│╠─Żą═ī”ĄūīėöĄō■┤µā”▓ó¤oė▓ąįĄ─ę¬Ū¾Ż¼Ą½╩ŪŻ¼×ķ┴╦ūŅ║├Ąž└¹ė├įō─Żą═ĦüĒĄ─╔ņ┐sąįā×ä▌Ż¼═∙═∙ąĶę¬▓╔ė├Ęų▓╝╩Į╬─╝■ŽĄĮyū„×ķ▌ö╚ļöĄō■ĪóųąķgĮY╣¹ęį╝░▌ö│÷öĄō■Ą─▌d¾wĪŻ
į┌Apache Hadoop╠ū╝■ųąŻ¼▀@śėĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyŠ═╩ŪHadoopĘų▓╝╩Į╬─╝■ŽĄĮy(hadoop distributed file systemŻ¼HDFS)ĪŻ▀@ę▓╩Ū▒ŠŲĮ┼_╩ū▀xĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyĘĮ░Ėų«ę╗ĪŻįōŽĄĮy└¹ė├Hadoop╝»╚║ųąĖ„éĆ╣سcĄ─▒ŠĄž┤┼▒PüĒ┤µĘ┼öĄō■╬─╝■Ż¼┐╔ęįį┌Ųš═©Ą─ė▓╝■ŲĮ┼_╔ŽīŹ¼F┐╔┐┐Ą─öĄō■┤µā”ĪŻ
ī”═Ō▓┐┐═æ¶ÖCČ°čįŻ¼HDFSŠ═Ž±ę╗éĆé„ĮyĄ─Ęų╝ē╬─╝■ŽĄĮyŻ¼┐╔ęįäōĮ©Īóäh│²ĪóęŲäė╗“ųž├³├¹╬─╝■Ą╚ĪŻĄ½╩ŪHDFSĄ─╝▄śŗ╩Ū╗∙ė┌ę╗ĮM╠žČ©Ą─╣سcśŗĮ©Ą─Ż¼▀@╩Ūė╔╦³ūį╔ĒĄ─╠ž³cøQČ©Ą─ĪŻ▀@ą®╣سc░³└©Ż║NameNodežōž¤į┌HDFSā╚▓┐╠ß╣®į¬öĄō■Ę■䚯╗DataNodežōž¤×ķHDFS╠ß╣®┤µā”ēKĪŻHadoop╝»╚║═∙═∙░³║¼ę╗éĆNameNode║═┤¾┴┐DataNodeĪŻDataNode═©│ŻęįÖC╝▄Ą─ą╬╩ĮĮM┐ŚŻ¼ÖC╝▄ų«ķg═©▀^Į╗ōQÖCīŹ¼F▀BĮėĪŻHadoop HDFS║═Hadoop MapReduceĄ─ę╗éĆ╝┘įO╩ŪÖC╝▄ā╚▓┐╣سcų«ķgĄ─é„▌ö╦┘Č╚║═čė▀tČ╝║├ė┌ÖC╝▄ķgĪŻ
4 īŹ¼F▓Į¾E
Å─é„ĮyĄ─öĄō■Ęų╬÷┼c╔╠śIųŪ─▄Ęų╬÷─Ż╩ĮŽ“╗∙ė┌įŲėŗ╦ŃĄ─öĄō■Ęų╬÷įŲĄ─▀M╗»╩ŪļŖą┼öĄō■Ęų╬÷Ą─ĮK╝ē─┐ś╦ĪŻ▐Dą═▀^│╠æ¬įōÅ─┘Yį┤š¹║Ž┼cŲĮ┼_╠ōöM╗»ų°╩ųŻ¼Ęų▓Įę²╚ļ╠ōöM╗»Ė▀╝ē╣”─▄║═įŲėŗ╦ŃĖ┼─ŅĪŻ
(1)┘Yį┤š¹║Ž┼c³cæ¬ė├
ęį¼FėąĄ─öĄō■Ęų╬÷┼c╔╠śIųŪ─▄Ęų╬÷ŽĄĮy×ķ╗∙ĄAŻ¼▀Mąą┘Yį┤š¹║ŽŻ¼īŹ¼F╬’└Ē┘Yį┤Ą─╠ōöM╗»ĪŻ═©▀^╠ōöM╗»╝╝ągīŹ¼F┘Yį┤│ž╗»║═┘Yį┤äėæBöUš╣Ą╚╣”─▄Ż¼īŹ¼F╗∙ĄAŲĮ┼_┼cæ¬ė├ŲĮ┼_Ą─öUš╣ĪŻ─┐Ū░Ż¼īŹ¼F╠ōöM╗»Ą─«aŲĘėą║▄ČÓŻ¼ŲõųąęįVmwareĪó╬ó▄øĪóctrixĄ─╠ōöM╗»«aŲĘ×ķų„┴„ĪŻ
ę└═ą╗∙ĄAŲĮ┼_┼cæ¬ė├öUš╣ŲĮ┼_Ż¼īŹ¼FöĄō■Ęų╬÷║═╔╠śIųŪ─▄ŲĮ┼_Ą─┐ņ╦┘▓┐╩║═┘Yį┤äėæBöUš╣ĪŻ
į┌┤╦╗∙ĄA╔ŽŻ¼ĮĶų·ŲĮ┼_┐ņ╦┘▓┐╩╣”─▄║═ŽĄĮy¤o┐pęŲų├╣”─▄Ż¼▀xō±ąįĄžķ_░l║═▓┐╩ę╗┼·öĄō■Ęų╬÷║═╔╠śIųŪ─▄æ¬ė├ĪŻ
(2)ŲĮ┼_öUš╣║═æ¬ė├═ŲÅV
į┌š¹║ŽĄ─╗∙ĄA╔ŽöUš╣ŲĮ┼_Ż¼ķ_░l║═▓┐╩Ė³ČÓĄ─įŲ─Ż╩ĮöĄō■Ęų╬÷║═╔╠śIųŪ─▄æ¬ė├Ż¼═¼EDWĪóODS║═Ųõ╦¹¼FėąBIŲĮ┼_╝»│╔ĪŻ
(3)ŲĮ┼_ķ_Ę┼║═ūįų„č▌╗»
▀@éĆļAČ╬Ą─ŲĮ┼_Į©įO─┐ś╦╩Ūś╦£╩╗»įŲ─Ż╩ĮöĄō■Ęų╬÷║═╔╠śIųŪ─▄æ¬ė├Ą─ķ_░lĮė┐┌║═▀\ąąĢrĮė┐┌Ż¼╠ß╣®▌^×ķ═Ļ╔ŲĄ─ķ_░l╠ū╝■Ż¼╣─äŅ║═╬³ę²║Žū„╗’░ķ╣▓═¼žSĖ╗ŲĮ┼_║═æ¬ė├Ą─╣”─▄ĪŻ
5 ļy³c║═’LļU
į┌öĄō■Ęų╬÷┼c╔╠śIųŪ─▄Ęų╬÷ųąæ¬ė├įŲėŗ╦Ń╝╝ągŻ¼─▄╠ßĖ▀öĄō■Ęų╬÷Ą─ą¦┬╩Ż¼ūīŲ¾śIĖ³╝ė─▄▀mæ¬┐ņ╦┘ūā╗»Ą─╩ął÷Ż¼×ķ┐ņ╦┘═Ų│÷ą┬Ą─«aŲĘ╠ß╣®öĄō■ę└ō■Ż¼Ą½╩ŪįŲėŗ╦Ńę▓┤µį┌ę╗ą®ļy³c║═’LļUĪŻ
(1)«aŲĘ▀xō±å¢Ņ}
Ę■äšŲ„╠ōöM╗»╝╝ąg║═«aŲĘø]ėąĮyę╗Ą─ś╦£╩ŲĮ┼_║═ķ_Ę┼ģfūhŻ¼śIā╚Ę■äšŲ„╠ōöM╗»«aŲĘ┴╝▌¼▓╗²RŻ¼▀xō±▓╗║Ž▀mĄ─«aŲĘĢ■ĦüĒć└ųžĄ─═Č┘Y’LļUĪŻČ°ŪęĘ■äšŲ„╠ōöM╗»▄ø╝■ārĖ±▓╗ĘŲŻ¼Č╠Ų┌ĪóąĪĘČć·ā╚Ą─æ¬ė├ļyęŖą¦ęµĪŻ
(2)┐╔┐┐ąįå¢Ņ}
ė╔ė┌į┌ę╗┼_Ę■äšŲ„╔Ž▀\ąąČÓéĆųžę¬Ą─æ¬ė├│╠ą“║═öĄō■ÄņŻ¼╠ōöM╗»Ą─ITŁhŠ│▒╚┤¾ą═ėŗ╦ŃÖC║═╬óą═ėŗ╦ŃÖCŁhŠ│Ė³╚▌ęūįŌĄĮ×─ļyąį▒└ØóĄ─ŲŲē─Ż¼ę“×ķ╦³éāėą═¼śė╝»ųąĄ─┘Yį┤Ż¼Ą½╩ŪŻ¼ė▓╝■Ą─┐╔┐┐ąį▓╗═¼ĪŻ
(3)öĄō■░▓╚½å¢Ņ}
öĄō■╩ŪŲ¾śIĄ─╔·├³Ż¼öĄō■Ą─üG╩¦║═ą╣┬Čī”ļŖą┼üĒšf╩Ū▓╗╚▌║÷ęĢĄ─’LļUĪŻįŲėŗ╦ŃĦüĒ▒Ń└¹Ą─═¼ĢrŻ¼ę▓ĮoöĄō■ĦüĒ┴╦’LļUĪŻ
(4)ŁhŠ│Ą─Å═ļs╗»
╠ōöM╗»Ą─▒Š┘|╩Ūæ¬ė├ų╗┼c╠ōöMīėĮ╗╗źŻ¼Č°┼cšµš²Ą─ė▓╝■Ė¶ļxĪŻį┌įņ│╔▒Ń└¹Ą─═¼ĢrŻ¼ę▓įņ│╔┴╦’LļUĪŻ▄ø╝■║═ė▓╝■ų«ķg▒╗ŪąöÓ┬ōŽĄīóī¦ų┬░▓╚½╚╦åT┐┤▓╗ĄĮįOéõ▒│║¾░l╔·Ą─’LļUŻ¼Ę■äšŲ„ŁhŠ│ūāĄ├Ė³╝ė▓╗═¼Č©ĪóÅ═ļsŻ¼░▓╚½╚╦åTūŅĮK╩¦╚źė▓╝■▒Š╔Ē╠ß╣®Ą─ĘĆČ©ąįĪŻ«öæ¬ė├│÷¼F╣╩šŽĢrŻ¼ąĶꬊ½┤_Č©╬╗╩Ūė▓╝■▀Ć╩Ū▄ø╝■╣╩šŽŻ¼į┌╠ōöM╗»╩└ĮńųąŻ¼▀@īó╩Ūę╗ĒŚÅ═ļsČ°╚▀ķLĄ─╣żū„ĪŻ
6 ĮY╩°šZ
ųąć°ļŖą┼īŹ¼FöĄō■įŲų«║¾Ż¼┐╔ęį┐ņ╦┘┤ŅĮ©ę╗éĆöĄō■Ęų╬÷įŲėŗ╦ŃŲĮ┼_ĪŻ▀@éĆ▀^│╠īó═©▀^╣▄└ĒŲĮ┼_ūįäė╗»īŹ¼FĪŻöĄō■Ęų╬÷įŲĄ─öUš╣ąįĪŻ▒ŻūCĖ„ŅÉŲĮ┼_Č╝┐╔ęįģó┼cĄĮįŲėŗ╦ŃųąĪŻģó┼cŲĮ┼_Ą─ÖCŲ„┐╔ęį╩Ū┘Yį┤│žĄ─ķeų├ÖCŲ„Ż¼ę▓┐╔öUš╣ĄĮĘŪ╔·«aŁhŠ│Ą─ÖCŲ„Ż¼╚ńķ_░l£yįć┘Yį┤│žŻ¼╔§ų┴▐k╣½ÖCŲ„ĪŻöĄō■Ęų╬÷įŲŠ▀ėąņ`╗ŅÅŚąįŻ¼ę“┤╦Ė„ŅÉÖCŲ„┐╔▀xō±┐šķeĢrČ╬╝ė╚ļįŲŲĮ┼_Ż¼╚ń▐k╣½ÖCŲ„┐╔į┌ę╣ķg┐šķeĢrČ╬╝ė╚ļįŲĘų╬÷ĪŻ░ū╠ņ╚į▀MąąĖ„ūį╚╬äšĪŻņ`╗ŅĄž╝ė╚ļ┼c═╦│÷▓ó▓╗ųąöÓįŲėŗ╦Ń▒Š╔ĒĪŻöĄō■Ęų╬÷įŲŠ▀ėąĖ▀┐╔┐┐ąįŻ¼╝┤╩╣│÷¼Fę╗ą®ÖCŲ„Ą─┼RĢr╣╩šŽĪŻįŲŲĮ┼_─▄ē“ūįäėÖz£y║═▀mæ¬Ż¼▓ó▓╗ųąöÓįŲŲĮ┼_Ęų╬÷┼cėŗ╦ŃĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║įŲėŗ╦Ńį┌ļŖą┼öĄō■┼c╔╠śIųŪ─▄Ęų╬÷ųąĄ─æ¬ė├蹊┐
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/1083975603.html






















