



ę²čį
Big Data╩ŪĮ³─Ļį┌įŲėŗ╦ŃŅIė“╠ß│÷Ą─ī”öĄō■Ą─╝ė▌dą¦┬╩Īó┤µā”ęÄ─Żęį╝░öĄō■Ą─Öz╦„ą¦┬╩ėą║▄Ė▀ę¬Ū¾Ą─æ¬ė├ł÷║ŽŻ¼═©│ŻöĄō■Ą─╝ė▌dą¦┬╩į┌Mb/s╔§ų┴Gb/s┴┐╝ēŻ¼öĄō■Ą─┤µā”ęÄ─Żį┌TB╔§ų┴PBęÄ─ŻŻ¼▒Š╬─ĘQ▀@ĘN─Ż╩Į×ķ“┤¾öĄō■╝»”╣▄└ĒĪŻ┤¾öĄō■╝»Ą─ę╗ŅÉųžę¬æ¬ė├ßśī”ĮYśŗ╗»öĄō■Ą─┤µā”┼cÖz╦„ĪŻĄõą═Ą─æ¬ė├╚ń║Ż┴┐╚šųŠĪóŠWĮjł¾╬─ęį╝░web2Ż¼0┐“╝▄Ž┬Ą─SNSŻ¼ļŖūė╔╠䚯¼öĄō■═┌Š“Ą╚æ¬ė├ł÷║ŽĪŻé„ĮyĄ─RDBMSė╔ė┌öĄō■ę╗ų┬ąįĄ─╝s╩°Ż¼į┌╣▄└Ē┤¾ęÄ─ŻöĄō■╝»┤µā”Śl╝■Ž┬Ż¼į┌öĄō■Ė³ą┬ĪóŠų▓┐öĄō■╩¦ą¦ęį╝░ŽĄĮyöUš╣ąįĄ╚ĘĮ├µ╣żū„ą¦┬╩Ą═Ž┬ĪŻ─┐Ū░Ą─ĮŌøQ╦╝┬Ę╩ŪŻ║═©▀^Ę┼īÆī”ė┌öĄō■ę╗ų┬ąįĄ─ę¬Ū¾Ż¼╚ĪŽ¹Å═ļsĄ─ĻP┬ō▓ķįāŻ¼ĮY║ŽŠ▀¾wĄ─æ¬ė├ł÷Š░Ż¼╠ßĖ▀ŽĄĮyĄ─┐╔ė├ąįĪŻĄ½╩Ūė╔ė┌┤¾┴┐Ą─ėøõø┤µĘ┼ė┌═¼ę╗éĆ▒Ē┐šķgųąŻ¼Ģ■▀_ĄĮöĄ╩«ā|Śl╔§ų┴╔Ž░┘ā|ŚlėøõøĄ─ęÄ─ŻĪŻį┌╚ń┤╦┤¾ęÄ─ŻöĄō■┤µā”Śl╝■Ž┬Ż¼╚ń║╬Ė▀ą¦Ą─īŹ¼FöĄō■Ą─┤µā”ĪóÖz╦„Č╝├µ┼Rų°ą┬Ą─╠¶æĪŻ
Googleī”▀@ę╗å¢Ņ}▀Mąą╔Ņ╚ļĘų╬÷Ż¼ĮY║ŽGoogleĄ─śIäš▒│Š░Ż¼╠ß│÷BigtableöĄō■╣▄└ĒĘĮĘ©Ż¼Į©┴ó┴ą┤µā”öĄō■ĮYśŗŻ¼╠ß╣®╗∙ė┌Row-KeyĄ─öĄō■Öz╦„Įė┐┌ĪŻ┤╦║¾Ż¼śIĮńę▓╝Ŗ╝Ŗ╠ß│÷Ęų▓╝╩ĮĮYśŗ╗»öĄō■┤µā”╣▄└Ē─Żą═Ż¼ę▓ĘQ×ķNo-SQLŻ©Not Only SqlŻ®öĄō■ÄņĪŻĄõą═Ą─No-SQLöĄō■Äņ░³└©DynamoŻ¼Cassandra, PNUTSŻ¼Hbaseęį╝░HypertableĄ╚Ż║Ą½╩Ū─┐Ū░Ą─║Ż┴┐ĮYśŗ╗»öĄō■╣▄└ĒŽĄĮyī”ė┌öĄō■Öz╦„Ą─ČÓī┘ąįų¦│ų▌^╚§Ż¼═©│ŻāH╠ß╣®╗∙ė┌KeyĄ─ūx╚ĪGET║═īæ╚ļPUT▓┘ū„Ż¼▓╗Š▀éõČÓī┘ąį▓ķįāŻ¼öĄųĄĮyėŗĪóĘų╬÷Ą╚Å═ļsĄ─▓ķįā╣”─▄ĪŻ
─┐Ū░╗∙ė┌Hadoop╠ß│÷Ą─öĄō■é}Äņ╣żŠ▀HIVEĪóPIGĄ╚Ż¼┐╔ęįų¦│ųÅ═ļsĄ─▓ķįāŚl╝■Ż¼Ą½╩Ū▓╗▀mė├ė┌┴„öĄō■Ą─Ė▀ą¦┤µā”┼cÖz╦„ĪŻ╚ńHIVEāHų¦│ų╬─▒Š╬─╝■Ą─┼·┴┐ī¦╚ļŻ¼▓╗ų¦│ų┴„öĄō■į┌ŠĆŅlĘ▒╝ė▌d▓┘ū„ĪŻį┌Å═ļsŚl╝■Ą─Öz╦„▀^│╠ųąHIVEĢ■░č▓ķįāŚl╝■ĘųĮŌ│╔ČÓéĆMapReduce╚╬䚯¼├┐éĆMap▀^│╠ęį╝░ReduceĮY╣¹Č╝ę¬░č╬─╝■īæ╚ļĄĮ╝»╚║╬─╝■ŽĄĮyųą▀MąąŠÅ┤µŻ¼ī¦ų┬ŽĄĮyÖz╦„ą¦┬╩Ą═Ż¼▓╗▀mė├ė┌┴„öĄō■Ą─Ė▀ą¦┤µā”┼c▓ķįāĪŻ
ßśī”įōå¢Ņ}Ż¼▒Š╬─╗∙ė┌HadoopĮ©┴ó├µŽ“ĮYśŗ╗»┴„öĄō■╠ß│÷Š▀ėąį┌ŠĆöĄō■╝ė▌d║═┐ņ╦┘Öz╦„Ą─Ęų▓╝╩ĮöĄō■┤µā”ŽĄĮyMDSS(Massive Data Storage System)Ż¼Į©┴óČ■ŠS▒Ē┐šķgöĄō■╣▄└Ē─Żą═Ż¼ųž³cĮŌøQöĄō■Ą─Ęų▓╝┤µā”┼cÅ═ļsŚl╝■Ą─┐ņ╦┘▓ķįāå¢Ņ}ĪŻ
1 MDSSŽĄĮy╣żū„įŁ└Ē
“┤¾öĄō■╝»”ę¬Ū¾▌^Ė▀Ą─öĄō■╝ė▌dą¦┬╩ĪóöĄō■┤µā”ą¦┬╩ęį╝░öĄō■Öz╦„ą¦┬╩Ż¼─┐Ū░ų„ꬥ─ĮŌøQ╦╝┬Ę╩Ū└¹ė├ČÓÖCģf═¼Ą─Ęų▓╝╩Į┤µā”ŁhŠ│╠ßĖ▀ŽĄĮyĄ─╠Ä└Ēą¦┬╩ĪŻMDSSĘų▓╝╩ĮŽĄĮyĮYśŗ╚ńłD1╦∙╩ŠŻ¼ŽĄĮy░³└©╚²éĆ▓┐ĘųŻ║╝ė▌dÖC╝»╚║Īó▓ķįāÖC╝»╚║Īóį¬öĄō■╣سc╝»╚║ęį╝░┤µā”╣سc╝»╚║ĪŻ
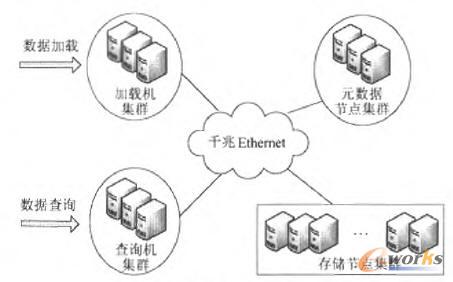
łD1 MDSSŽĄĮyĮYśŗłD
╝ė▌dÖC╝»╚║Ż║š¹éĆŽĄĮyĄ─öĄō■╝ė▌dČ╦ĪŻ┐╔ęįęį▀M│╠×ķå╬╬╗Ż¼į┌ČÓ┼_įOéõ╔Ž═¼ĢrĮ©┴óČÓéĆ▓ó░löĄō■╝ė▌d┐═æ¶Č╦Ż¼═©▀^▓ó░l╝ė▌d╠ßĖ▀ŽĄĮyš¹¾w╝ė▌dą¦┬╩ĪŻį┌MDSSųąŻ¼╝ė▌dÖC╝»╚║═¼ĢrŠÅ┤µĮ³Ų┌╚ļÄņĄ─öĄō■Ż¼Įø▀^╣╠Č©Ą─Ģrķgų▄Ų┌Ż¼░čŠÅ┤µöĄō■═©▀^Gb EthernetīæĄĮöĄō■┤µā”╣▄└Ēčbų├ųąĪŻ
▓ķįāÖC╝»╚║Ż║ė├æ¶į┌▓ķįāÖC╔Ž░l│÷▓ķįāųĖ┴ŅŻ¼▓ķįāÖCĖ∙ō■į¬öĄō■╣سc╝»╚║▒Ż┤µĄ─į¬öĄō■ą┼ŽóŻ¼Ž“┤µā”╣سcĘų░l▓ķįā╚╬䚯¼ūŅ║¾ģR┐éČÓéĆ┤µā”╣سcĘĄ╗žĄ─▓ķįāĮY╣¹Ż¼╠ßĮ╗Įoė├æ¶Ż╗
┤µā”╣سc╝»╚║Ż║│ųŠ├┤µā”ķLŲ┌▒Ż┤µĄ─Üv╩ĘöĄō■ĪŻ░čöĄō■į┤▀MąąĘųēK┤µā”Ż¼═©│Ż░čę╗┤╬╗“Äū┤╬Å─╝ė▌dÖC╦óą┬ĄĮ╝»╚║ųąĄ─öĄō■ū„×ķöĄō■ĘųēKĪŻ
į¬öĄō■╣سc╝»╚║Ż║ė├üĒģfš{š¹éĆ╝»╚║Ą─╣żū„Ż¼▓ķįāūė╚╬䚥─▓ó░lł╠ąąŻ¼▒Ż┤µš¹éĆŽĄĮy╣żū„╦∙ąĶĄ─į¬öĄō■ą┼ŽóĪŻį¬öĄō■╣سc╝»╚║┤µā”Ą─į¬öĄō■░³└©Ż║ŽĄĮy╣سcĀŅæBą┼ŽóŻ╗╦„ę²ĘųŲ¼Š▀¾wĄ─┤µā”╬╗ų├ą┼ŽóŻ╗▒Ē┐šķgį¬öĄō■Īó├┐éĆ▒Ē┐šķgĄ─ę╗ą®▌oų·ą┼Žóęį╝░ŽĄĮyĄ─╣żū„╚šųŠĄ╚ĪŻMDSSŽĄĮyų„ę¬ų¦│ųĘų▓╝╩ĮĄ─öĄō■┤µā”║═Öz╦„Ż¼Š▀¾wöĄō■▓ķįā┴„│╠╚ńłD2╦∙╩ŠĪŻ
ó┘ė├æ¶į┌▓ķįāÖC╔Ž╠ßĮ╗▓ķįāšłŪ¾Ż╗
ó┌▓ķįāÖCĖ∙ō■Š▀¾wĄ─▓ķįā╚╬䚯¼Ž“į¬öĄō■╣سc▓ķįāī”æ¬▒Ē┐šķgį¬öĄō■║═Öz╦„╦∙ąĶĄ─į¬öĄō■ą┼ŽóŻ╗
ó█į¬öĄō■╣سc╝»╚║Ė∙ō■▓ķįāŚl╝■Ż¼╠ß╣®Öz╦„╦∙ąĶĄ─į¬öĄō■Ż¼└²╚ńŻ║ī”æ¬Ą─▒Ē┐šķgĮYśŗöĄō■Ż¼╦„ę²ĘųēK┼c╣سcĄ─ė│╔õĻPŽĄĄ╚Ż╗
ó▄▓ķįāÖCĖ∙ō■į¬öĄō■ą┼ŽóŻ¼Į©┴ó▓ķįāęÄäØŻ¼øQČ©Ž“──ą®┤µā”╣سc░l╦═▓ķįā├³┴ŅĪŻ─│ą®▓ķįā┐╔ęį└¹ė├į¬öĄō■ą┼Žóā×╗»▓ķįā▀^│╠ĪŻė╔ė┌╝ė▌dÖCĢ■ŠÅ┤µėąĮ³Ų┌Ą─öĄō■Ż¼ßśī”Į³Ų┌öĄō■Ą─▓ķįāĢ■░l╦═ĄĮ╝ė▌dÖCŻ╗
ó▌öĄō■┤µā”╣سcĖ∙ō■Öz╦„Śl╝■Ż¼Öz╦„Ę¹║ŽŚl╝■Ą─öĄō■╝»Ż¼▓ó░l╗žĮo▓ķįāÖCŻ¼▓ķįāÖCī”▓ķįāĮY╣¹▀MąąūŅ║¾Ą─ģR┐éĪóĮyėŗŻ¼ęį╝░▒žę¬Ą─║¾Ų┌öĄō■╠Ä└Ē╣żū„Ż╗
ó▐▓ķįāÖCī”ĮY╣¹╝»░┤ššė├æ¶ųĖČ©Ą─Ė±╩ĮĘŌčbŻ¼ĘĄ╗žĮo▓ķįāė├æ¶Ż¼═Ļ│╔ę╗┤╬═Ļš¹Ą─öĄō■▓ķįā▀^│╠ĪŻ į┌╔Ž╩÷Öz╦„▀^│╠Ż¼╔µ╝░ā╔éĆ║╦ą─Ą─å¢Ņ}╩ŪŻ║┤µā”ŽĄĮy▓╔ė├║╬ĘNöĄō■┤µā”─Żą═ęį╝░ßśī”Å═ļs▓ķįāŚl╝■Ą─Š▀¾wĄ─╚╬äšĘųĮŌĘĮĘ©Ż¼Ž┬├µĘųäeį┌Ą┌3▓┐ĘųĮķĮBMDSS▓╔ė├Ą─öĄō■─Żą═Ż╗į┌Ą┌4▓┐ĘųĮķĮBÅ═ļs▓ķįāŚl╝■Ą─╚╬äšĘųĮŌÖCųŲĪŻ
2 MDSSųąöĄō■─Żą═┼c┤µā”ĮYśŗ
3.1öĄō■─Żą═
MDSS×ķė├æ¶╠ß╣®Č■ŠS▒Ē┐šķgöĄō■╣▄└Ē─Żą═Ż¼ęįėøõø×ķå╬╬╗Ż¼├┐éĆėøõøā╚░³║¼ČÓéĆūųČ╬╗“ī┘ąįŻ¼▒Ē┐šķg└¹ė├▒ĒĮYśŗ├Ķ╩÷ūųČ╬ŅÉą═ĪŻ
öĄō■ŅÉą═ė╔▒ĒĮYśŗ╬─╝■├Ķ╩÷Ż«▒ĒĮYśŗ╬─╝■į┌äōĮ©▒Ē┐šķgĢr╔·│╔Ż¼▒Ż│ųĄĮį¬öĄō■╣سc╝»╚║ųąŻ¼MDSSįOėŗ┴╦ę╗ĘNßśī”å╬▒Ē┐šķgā╚├µŽ“┴„ėøõøĄ─öĄō■Įyėŗ┼cĘų╬÷šZčįŻ¼šZĘ©ęÄät┼cś╦£╩Ą─SQLŽÓ═¼Ż¼Ą½╩Ū╚ĪŽ¹┴╦ś╦£╩SQLųąĻP┬ō▓ķįāĪóŪČ╠ū▓ķįāĪóęĢłDĄ╚Å═ļsĄ─Öz╦„╣”─▄Ż¼▒Š╬─║åĘQ×ķMQLšZčįŻ¼Š▀¾wų¦│ųĄ─▓ķįā╣”─▄╚ń▒Ē1╦∙╩ŠŻ║
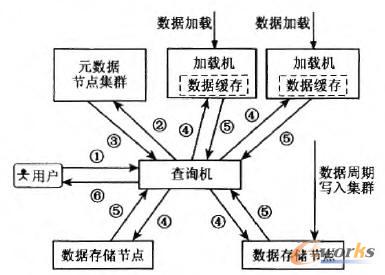
łD2 ╗∙▒ŠöĄō■─Żą═

▒Ē1 MDSS╗∙▒Š▓┘ū„ĘĮĘ©├Ķ╩÷
3.2öĄō■┤µā”ĮM┐ŚĮYśŗ
öĄō■┤µā”Ė±╩Įų„ę¬Ęų×ķā╔ĘNŅÉą═Ż║STOREŅÉą═║═ūųĘ¹ŅÉą═ĪŻSTOREŅÉą═ų▒Įė┤µā”╬─╝■ą┼ŽóŻ¼ī”öĄō■ā╚╚▌Ą─ĮŌ╬÷ė╔ė├æ¶═Ļ│╔ĪŻūųĘ¹ŅÉą═┤µā”ĘĮ╩Į░čöĄō■į┤ęįūųĘ¹ĘĮ╩ĮĘųēK┤µā”ĪŻūųĘ¹┤µā”ĘĮ╩Į┐╔ęįį┌«Éśŗ┤µā”ŁhŠ│ųąūįė╔Ą─▀węŲŻ¼Š▀ėąĖ³┤¾Ą─ņ`╗ŅąįĪŻūųĘ¹ŅÉą═┐╔ęį╠Ä└ĒöĄō■ŅÉą═░³└©Ż║INDEXŻ¼IPFIELDŻ¼TIMESTAMPęį╝░INTEGERĄ╚Ż¼į┌öĄō■╝ė▌dĢrĖ∙ō■▒ĒĮYśŗČ©┴xĄ─öĄō■ŅÉą═▀MąąöĄō■▐DōQĪŻ▒╚╚ńš¹öĄ10į┌ūųĘ¹ŅÉą═ųąąĶę¬┤µā”00000010ĪŻ▀@▓┐ĘųĄ─▐DōQ╣żū„į┌╝ė▌dÖC╔ŽīŹ¼FĪŻ
į┌├┐éĆ╦„ę²ĘųŲ¼ā╚▓┐ę²╚ļēKā╚╦„ę²Ż¼ė├üĒś╦ėø╦„ę²ĘųēKā╚▓┐▓╗═¼ūųČ╬ī┘ąįöĄō■Ą─Š▀¾w┤µā”╬╗ų├ĪŻ╦„ę²ēKĄ─┤¾ąĪ═©│Ż╩╣ė├╣╠Č©┤¾ąĪ┐šķg┤µā”Ż¼▒Ńė┌ę╗┤╬ąį╝ė▌dĄĮā╚┤µųą▀MąąöĄō■ĮyėŗŻ¼─┐Ū░╩Ū4K┤¾ąĪĪŻ╦„ę²ĘųŲ¼į┌┤µā”╣سc╔Ž▓╔ė├gzipē║┐s╦ŃĘ©▀MąąöĄō■ē║┐sŻ¼ė╔ė┌ā╚╚▌ŽÓ═¼Ą─ūųČ╬Ė∙ō■ūųĄõą“┼┼ą“║¾ŽÓÓÅ┤µā”Ż¼ę“┤╦ę²╚ļē║┐s╝╝ągĢ■’@ų°╠ßĖ▀öĄō■Ą─┤µā”ą¦┬╩ĪŻ
į┌╚šųŠĪó┴„ėøõøĄ╚æ¬ė├ł÷║ŽŻ¼Ģrķgī┘ąį╩ŪūŅ│Żė├Ą─Öz╦„ī┘ąįŻ¼MDSS▓╔ė├Ģrķgī┘ąįī”öĄō■▀MąąĘųģ^╣▄└ĒŻ¼╦„ę²ĘųŲ¼ų«ķg▒Ż│ųĢrķgėąą“ĪŻ═¼ĢrĮ©┴ó╗∙ė┌Ģrķgī┘ąįĄ─Ęų▓╝╩ĮB+ TreeŻ¼╝ė┐ņĘųģ^öĄō■Ą─Öz╦„▀^│╠ĪŻB+ TreeĄ─╚~╣سc▒Ż┤µ├┐éĆ╦„ę²ĘųŲ¼ī”æ¬Ą─ūŅ┤¾Ģrķgī┘ąį║═╦„ę²ĘųŲ¼Ą─┤µā”╣سcĄ─╬╗ų├ĪŻĘų▓╝╩ĮB+ Tree▒Ż┤µį┌į¬öĄō■╣سc╝»╚║ųąĪŻŠ▀¾wĮYśŗ╚ńłD4╦∙╩ŠĪŻ
łD3 öĄō■ĮM┐ŚĮYśŗłD
╦„ę²ĘųŲ¼öĄō■ū„×ķ╗∙▒ŠĄ─š{Č╚║═ėŗ╦Ńå╬╬╗Ż¼│ųŠ├┤µā”ĄĮ┤µā”╣سc╔ŽĪŻ«ööĄō■Å─╝ė▌dÖC╦óą┬ĄĮ┤µā”╣سc╝»╚║ĢrŻ¼Ė∙ō■įOų├Ą─Ė▒▒Š╚▀ėÓČ╚║═╝»╚║┤µā”╣سc┴ą▒ĒŻ¼░┤ą“▀xō±┐╔ė├Ą─┤µā”╣سcŻ¼īæ╚ļöĄō■ĪŻ«öįOų├Ė▒▒Š╚▀ėÓČ╚ĢrŻ¼╝ė▌dÖCĢ■▀xō±▓╗═¼Ą─╣سcĘųäeīæ╚ļöĄō■ĪŻ
į┌öĄō■Öz╦„ĢrŻ¼ę╗éĆ╦„ę²ĘųŲ¼Öz╦„ĮY╣¹╚ń╣¹│¼▀^ĘĄ╗žĢrķgŽ▐ųŲŻ¼┐╔ęį▀xō±ī”æ¬Ą─╦„ę²ĘųŲ¼Ą─Ė▒▒Šųžą┬ł╠ąąÖz╦„▓┘ū„Ż¼īŹ¼FöĄō■╚▌Õe╣”─▄ĪŻŽ▐ė┌Ų¬Ę∙Ż¼ĻPė┌öĄō■įö╝ÜĄ─ĮM┐ŚĘĮ╩Į▓╗į┘įö╩÷ĪŻ
3. MDSSöĄō■Öz╦„ĘĮĘ©
MDSSł╠ąąÅ═ļs▓ķįāŚl╝■Ą─╗∙▒ŠįŁät╩Ūī”▓ķįāŚl╝■äØĘų│╔▓ķįāūė╚╬䚯¼├┐éĆūė╚╬äšį┌Ęų▓╝╩ĮŁhŠ│Ž┬Ą─▓╗═¼īė┤╬╔Ž▓ó░līŹ¼FĪŻ▓ķįāŚl╝■Ą─ĘųĮŌ║═▓ķįāūė╚╬䚥─äØĘųŻ¼╝╚ę¬▒ŻūC▓ķįāšZ┴xĄ─š²┤_ąįŻ¼═¼ĢrąĶę¬│õĘų┐╝æ]Ęų▓╝╩ĮŁhŠ│Ž┬ė░ĒæöĄō■Öz╦„Ą─ČÓĘNę“╦žŻ¼│õĘų░lō]Ęų▓╝╩ĮŁhŠ│Ž┬▓ó░lĪó▓󹹥─ėŗ╦Ń─▄┴”ĪŻ
3.1▓ķįāŚl╝■ĘųĮŌ
MDSS░čŠ▀¾wĄ─▓ķįāŚl╝■ĘųĮŌ×ķ╚²ŅÉ╗∙▒ŠŚl╝■Ż¼├┐ŅÉ╗∙▒ŠŚl╝■ū„×ķę╗ŅÉ▓ķįāūė╚╬äšĪŻ
Ęųģ^▓ķįāŚl╝■Ż║Ęųģ^▓ķįāŚl╝■ų▒ĮėČ©╬╗ė┌ØMūŃ▓ķįāŚl╝■Ą──┐ś╦╦„ę²╬─╝■Ż¼┤¾┤¾┐sąĪ║Ż┴┐öĄō■Ą─▓ķįāĘČć·ĪŻMDSS▀xō±Ģrķgī┘ąįū„×ķĘųģ^▓ķįāŚl╝■Ż╗
▀^×V▓ķįāŚl╝■Ż║ĮYśŗ╗»öĄō■├┐Ślėøõøė╔ČÓéĆūųČ╬ĮM│╔Ż¼├┐éĆūųČ╬┐╔ęį¬Ü┴óįOų├▓ķįāŚl╝■ĪŻūųĘ¹ŅÉī┘ąįų¦│ų─Ż║²▓ķįāŻ¼öĄūųŅÉĄ─ų¦│ų▒╚▌^▓ķįāĄ╚ĪŻČÓéĆ▀^×V▓ķįāŚl╝■ų«ķg═©▀^▀ē▌ŗ▀\╦ŃĘ¹╠¢AND OR NOT▀Mąą▀BĮėŻ¼śŗ│╔ČÓéĆ▀ē▌ŗĮM║Ž▓ķįāŚl╝■ĪŻAND OR NOTų«ķgØMūŃ╗∙▒ŠĄ─╝»║Ž▀\╦ŃĻPŽĄŻ╗
ĮyėŗĘų╬÷▓ķįāŚl╝■Ż║ĮyėŗĘų╬÷ŅÉ▓ķįāŚl╝■ų„ę¬ė├ė┌Įø▀^Ęųģ^▓ķįāŚl╝■Īó▀^×V▓ķįāŚl╝■║¾ĘĄ╗žĄ─ĮY╣¹╝»Ż¼īŹ¼F├µŽ“╚½ŠųöĄō■╝»Ą─ĮyėŗĪóĘų╬÷▓┘ū„ĪŻ
Š▀¾wĄ─▓ķįāŚl╝■░³└©Ż║öĄō■ĘųĮM▓┘ū„Ż©GROUP BYŻ®Ż¼öĄō■┼┼ą“▓┘ū„Ż©ORDER BYŻ®Ż¼TOP-KŻ¼ęį╝░Įyėŗ║»öĄŻ¼╚ńSUMŻ¼AVGŻ¼MAXŻ¼MINĄ╚ĪŻ
3.2▓ķįāūė╚╬䚥─▓ó░lł╠ąą┼cöĄō■ģR┐é
į┌Ęų▓╝╩ĮŁhŠ│Ž┬Ż¼┐╔ęį░čę╗éĆŠ▀¾wĄ─Å═ļs▓ķįā╚╬äš░┤šš╔Ž╩÷ĘųŅÉĘĮĘ©ĘųĮŌ│╔╚²ŅÉ╗∙▒Š▓ķįāŚl╝■Ż¼├┐ŅÉ▓ķįāŚl╝■ī”æ¬ę╗ĘN▓ķįāūė╚╬䚯¼└¹ė├Ęų▓╝╩ĮŁhŠ│Ž┬Ą─▓╗═¼īė┤╬ł╠ąąŠ▀¾wĄ─▓ķįāūė╚╬äšĪŻ
MDSS▓╔ė├Ģrķgī┘ąįū„×ķĘųģ^ŅÉÖz╦„Śl╝■Ż¼Ė∙ō■Öz╦„Śl╝■ųąĄ─Ģrķgī┘ąį┐╔ęįų▒ĮėÖz╦„ĄĮĘ¹║ŽŚl╝■Ą──┐ś╦╦„ę²ĘųŲ¼Ż¼╝ė╦┘Öz╦„▀^│╠ĪŻ▀@ę╗³c┼c─┐Ū░Ą─No-SQLöĄō■Äņ▓╗═¼Ż¼─┐Ū░No-SQLöĄō■Äņ═©│Ż░┤ššĻPµIūų▀MąąöĄō■ēKĘų┴čŻ¼▓ó╔µ╝░ĄĮą┬└ŽöĄō■ēKĄ─▀węŲĪó║Ž▓óĄ╚▓┘ū„ĪŻMDSS▓╔ė├Ģrķgī┘ąįū„×ķĘųģ^Śl╝■║å╗»┴╦öĄō■╣▄└Ē▓▀┬įŻ¼═¼ĢrĘ¹║Ž╚šųŠŅÉöĄō■Ż¼┴„öĄō■Ą─æ¬ė├ł÷Š░ĪŻ
ĮyėŗĘų╬÷ŅÉ▓ķįāŚl╝■ų„ę¬ßśī”Š▀ėąĘųĮMŻ¼┼┼ą“Ż¼öĄųĄĘų╬÷Ż¼ęį╝░TOPKŅÉĄ─Öz╦„Śl╝■▀MąąŠ▀¾w▓┘ū„ĪŻ▀@ŅÉ▓ķįā▓┘ū„ąĶę¬Ė∙ō■╚½▓┐Ą─ĮY╣¹╝»▀MąąĮyėŗ║¾▓┼─▄Įo│÷š²┤_Ą─▓ķįāĮY╣¹ĪŻ
MDSSßśī”▓┐Ęų▓ķįāū÷┴╦╠ž╩Ōā×╗»╠Ä└ĒĪŻ▒╚╚ńāHī”ūųČ╬ī┘ąį▀Mąą║åå╬ĮyėŗĄ─ĘųĮMĪó┼┼ą“Īó╚źųžĄ╚▓ķįāŻ¼╚ńSELECT DOMAIN „ GROUP BY(ORDER BY) DOMAINŻ╗SELECT DISTINCT *„Ż¼▒M╣▄Š▀ėąĮyėŗĘų╬÷║»öĄś╦ūRŻ¼Ą½╩Ūė╔ė┌į┌┤µā”╣سc╔Ž▀Mąąėŗ╦Ń▓╗Ģ■ė░ĒæūŅ║¾▓ķįāĮY╣¹Ą─š²┤_ąįŻ¼MDSSĢ■▀xō±Ę┼ĄĮĄūīė┤µā”╣سc╔Ž═¼▀^×VŅÉ▓ķįāŚl╝■ę╗Ų▓óąął╠ąąĪŻ┤╦ĢrĘĄ╗žĄ─ūė▓ķįāĮY╣¹╝»╩ŪęčĮøĘų║├ĮMĪó┼┼║├ą“╗“╚źųž║¾Ą─ĮY╣¹╝»Ż¼ūŅ║¾Ą─öĄō■ģR┐éļAČ╬ų╗ū÷ę╗┤╬ī”æ¬Ą─Įyėŗ▓┘ū„Ż¼Ģ■┤¾┤¾╠ßĖ▀öĄō■ģR┐éļAČ╬Ą─ł╠ąąą¦┬╩ĪŻ
4. īŹ“×ĮY╣¹┼cĘų╬÷
×ķ┴╦£yį接ĮyĄ─Š▀¾wąį─▄Ż¼ßśī”─│▀\ĀI╔╠DNSįLå¢ėøõø▀Mąą┬õĄž┤µā”ĪŻīŹ“ףhŠ│×ķŻ║╝ė▌dÖC×ķā╔éĆ╣سc, ┼õų├×ķAMD Opteron 2378 8║╦800MHz 8Gā╚┤µX 2Ż╗▓ķįāÖCę╗éĆ╣سcŻ¼┼õų├×ķAMD Opteron 2378 8║╦800MHz 16Gā╚┤µŻ╗į¬öĄō■╝»╚║ę╗éĆ╣سcŻ¼Š▀¾w┼õų├×ķAMD Opteron 2378 8║╦800Mhz 16Gā╚┤µĪŻ╦─éĆ┤µā”╣سcŻ¼Š▀¾w┼õų├×ķAMD Opteron 8380 4║╦800MHz X 4ĪŻ┤µā”╣سc╝ė▌d┤┼▒PĻć┴ąŻ¼├┐éĆ╣سc╝ė▌d5T┤┼▒P┐šķgŻ¼╝»╚║╠ß╣®20TĄ─┤┼▒P┤µā”┐šķgĪŻ
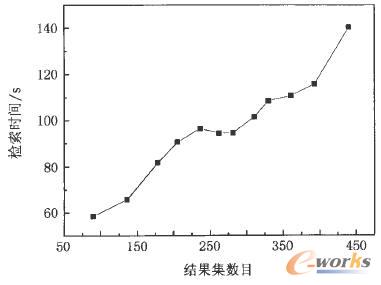
ŽĄĮy▀B└m▀\ąą50╠ņū¾ėęŻ¼ŲĮŠ∙├┐╠ņ╚ļÄņöĄō■┴┐4-5ā|ŚlėøõøŻ¼▒Ż┤µDNSėøõø230ā|Ślū¾ėęŻ¼š╝ė├Ą─┤µā”┐šķg14TBĪŻį┌«öŪ░öĄō■ęÄ─ŻŚl╝■Ž┬▀MąąŠ▀¾wĄ─īŹ“×£yįćĪŻ
╩ūŽ╚Įo│÷▓╗═¼Ą─Öz╦„ĢrķgķgĖ¶ī”Öz╦„ą¦┬╩Ą─ė░ĒæĪŻßśī”2011-07-01:00:00:00ĄĮ2011-07-01:24:00:00Ų┌ķgā╚Ż¼▀B└m24éĆąĪĢrĄ─öĄō■▀MąąīŹ“×Ęų╬÷ĪŻįōĢrķgČ╬ā╚Ą─▒Ż┤µĄ─ėøõøöĄ─┐×ķ510335051ŚlĪŻŠ▀¾wĄ─Öz╦„Śl╝■░³└©Ž┬┴ąŚl╝■Ż║
─Ż║²Öz╦„Śl╝■Ż║DOMAIN=www.*.com.cnŻ╗
Š½┤_Ųź┼õī┘ąįÖz╦„Ż║TYPE=AŻ╗
Ęųģ^Öz╦„Śl╝■Ż║TIME=TŻ╗
įOÖz╦„Ģrķg×ķT×ķģóöĄŻ¼«öT╚Ī▓╗═¼ĢrķgķgĖ¶ĢrŻ¼Öz╦„ą¦┬╩┼cŠ▀¾wĄ─ĢrķgĻPŽĄ╚ńłD4╦∙╩ŠĪŻ
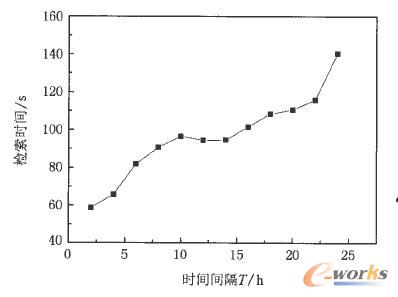
łD4 ▓╗═¼Öz╦„ĢrķgķgĖ¶ī”æ¬Ą─Öz╦„ą¦┬╩
Å─łD4┐╔ęį┐┤│÷Öz╦„ą¦┬╩╗∙▒Š╔Ž┼cÖz╦„Śl╝■Ą─ĢrķgķgĖ¶│╔ŠĆąįį÷ķLĪŻį┌öĄō■ÄņęÄ─Ż×ķ230ā|ėøõø┤µā”┐šķg×ķ14TB╦─éĆ┤µā”╣سcŚl╝■Ž┬Ż¼ī”24éĆąĪĢrā╚Ą─öĄō■▀MąąČÓī┘ąįÖz╦„ĢrŻ¼Öz╦„Ģrķgį┌140sū¾ėęĘĄ╗ž▓ķįāĮY╣¹ĪŻįōĮY╣¹▀h▀hĖ▀ė┌é„ĮyöĄō■ÄņĄ─▓ķįāą¦┬╩ĪŻŲõų„ę¬ĢrķgŽ¹║─į┌▓ķįāÖCÅ─į¬öĄō■╣سc▓ķįāį¬öĄō■ą┼Žóęį╝░ČÓ▓ķįā╣سcķgĄ─öĄō■═©ą┼║═ģR┐é╔ŽĪŻ
Å─łD5ųą┐╔ęį┐┤│÷Ż¼MDSSÖz╦„ą¦┬╩┼cĘĄ╗žĄ─ĮY╣¹╝»ėąĻPĪŻ«öĮY╣¹╝»▀^┤¾ĢrŻ¼▓╗āHé„▌ööĄō■ĪóöĄō■ģR┐éš╝ė├Ė³ČÓĄ─ĢrķgŻ¼į┌╩╣ė├┴ą┤µā”ĮYśŗŻ¼ųžśŗš¹ŚlįŁ╩╝ėøõøČ╝Ģ■š╝ė├Ė³ČÓĄ─ĢrķgĪŻ
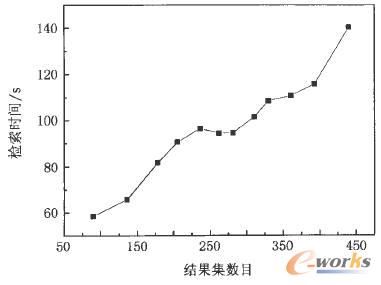
łD5 Öz╦„ą¦┬╩┼cĘĄ╗žĄ─ĮY╣¹╝»öĄ─┐ĻPŽĄ
łD6’@╩ŠŻ¼«ö╩╣ė├ČÓéĆ▀ē▌ŗŚl╝■ĮM║ŽĢrŻ¼Öz╦„Śl╝■═©▀^OR╗“AND▀Mąą▀BĮėŻ¼Öz╦„ą¦┬╩┼cČÓÖz╦„Śl╝■éĆöĄų«ķgĄ─ĻPŽĄĪŻ═©▀^łD╩Š┐╔ęį┐┤│÷Ż¼▀ē▌ŗŚl╝■Ą─éĆöĄį÷╝ėĢrŻ©īŹ“×ųąį÷╝ėĄĮ32éĆÖz╦„Śl╝■Ż®Ż¼Öz╦„Ģrķg╗∙▒Š▓╗░l╔·ūā╗»ĪŻ

łD6 Öz╦„ą¦┬╩┼c▀^×VŅÉÖz╦„Śl╝■Ą─ĻPŽĄ
ė╔ė┌▀^×VŅÉÖz╦„Śl╝■į┌Ęų▓╝╩Į┤µā”╣سc╔Ž▓ó░lł╠ąą,├┐éĆ╣سcßśī”Š▀¾wĄ─╦„ę²ĘųŲ¼åóäėČÓŠĆ│╠Öz╦„Ż¼═¼ĢrMDSS╦„ę²ĘųŲ¼▓╔ė├┴ą┤µĮYśŗŻ¼▀mė┌æ¬ė├į┌┤¾öĄō■╝»ĪóÅ═ļsÖz╦„Śl╝■Ą─Ęų╬÷æ¬ė├ųąĪŻ
ĮY║Ž╔Ž╩÷ā╔éĆīŹ“ׯ¼┐╔ęįĄ├│÷MDSSŠ▀¾wĄ─▓ķįāą¦┬╩ų„ę¬┼cÖz╦„ĮY╣¹╝»öĄ─┐ėąĻPŻ¼«öĮY╣¹╝»▀^┤¾Ż¼ė╔Ęų▓╝╩ĮŽĄĮyĄ─öĄō■═©ą┼Īó▓ķįāÖC╔ŽĄ─öĄō■ģR┐éĄ╚▓┘ū„Ģ■š╝ė├▌^ČÓĄ─ĢrķgŻ¼▀MČ°ī¦ų┬ŽĄĮyÖz╦„ą¦┬╩Ž┬ĮĄĪŻī”ė┌ŽÓī”Å═ļsĄ─Öz╦„Śl╝■┐╔ęįĖ∙ō■Š▀¾w╦„ę²ĮYśŗĪóöĄō■┤µā”ĮM┐ŚĘĮ╩Į▀MąąŠ▀¾wĄ─ā×╗»ĪŻ─┐Ū░MDSSŽĄĮy┐╔ęįėąą¦ĮŌøQČÓī┘ąįöĄō■Öz╦„ąĶŪ¾Ż¼Č°ī”ė┌Ė³Å═ļsĄ─ĻP┬ō▓ķįāŻ¼š²į┌▀Mę╗▓ĮĄ─蹊┐įOėŗųąĪŻ
5 ĮY╩°šZ
▒Š╬─ĮY║Ž┴╦é„ĮyĻPŽĄą═öĄō■ÄņįOėŗ╦╝Žļ▓óĮĶĶb┴╦įŲ┤µā”ųą│Żė├Ą─öĄō■╣▄└ĒĘĮ╩ĮŻ¼Į©┴ó├µŽ“ĮYśŗ╗»öĄō■Ą─║Ż┴┐öĄō■┤µā”Öz╦„ŽĄĮyĪŻŽĄĮyų¦│ųĮYśŗ╗»öĄō■Ą─Ė▀ą¦╝ė▌dĪóĘų▓╝┤µā”┼cÅ═ļsŚl╝■Ą─▓ķįā╣”─▄ĪŻ▀Mę╗▓ĮĖ─▀Mų„ꬥ─Ė─▀MĘĮŽ“░³└©Ż¼╚ń║╬╠ßĖ▀į¬öĄō■Ą─╣▄└ĒĪóįLå¢ą¦┬╩Ż╗╚ń║╬Į©┴óĘų▓╝╩ĮŁhŠ│Ž┬├µŽ“Å═ļsŚl╝■Ą─Ė▀ą¦▓ķįāęÄäØĄ╚ĘĮ├µĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║║Ż┴┐ĮYśŗ╗»öĄō■┤µā”Öz╦„ŽĄĮy
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/1083976032.html






















