



į┌ę╗┼_╬’└ĒĘ■äšŲ„ų«╔ŽśŗĮ©╠ōöM╗»│ķŽ¾īėŻ¼▓╔ė├╠ōöMÖC▒OęĢŲ„╗“╠ōöM╗»ŲĮ┼_2ĘNīŹ¼FĘĮ╩ĮŻ¼žōž¤Ę■äšŲ„Ą─│ķŽ¾Īó┘Yį┤Ą─š{Č╚┼c╣▄└ĒŻ¼īóĒŚ─┐╣▄└Ē┼cŠC║Ž╣▄└ĒŽĄĮyĘųäe▀\ąąį┌2éƬÜ┴óĄ─╠ōöMÖCų«╔ŽŻ¼Å─Č°╠ßĖ▀Ę■äšŲ„Ą─┘Yį┤└¹ė├┬╩ĪŻį┌╠ōöMÖCĄ─▀\ąą▀^│╠ųąŻ¼▓╔ė├īŹĢr▀węŲ╝╝ągīó╠ōöMÖCĄ─═Ļš¹▀\ąąĀŅæB┐ņ╦┘ĪóŲĮ╗¼Ąž▀węŲĄĮą┬Ą─Ę■äšŲ„╔ŽŻ¼ė├ė┌╣╩šŽĘ■äšŲ„Ą─ŠSūoŻ¼▓ó═©▀^╠ōöMÖCäėæBš{Č╚ĘĮĘ©Ż¼ī”┘Yį┤▀Mę╗▓Įš¹║ŽŻ¼īŹ¼F┘Yį┤Ą─äėæBĘų┼õ┼cš{Č╚Ż¼Å─Č°▀Mę╗▓Į╠ßĖ▀Ę■äšŲ„Ą─┘Yį┤└¹ė├┬╩ĪŻ
į┌╠ßĖ▀Ę■äšŲ„┘Yį┤└¹ė├┬╩Ą─═¼ĢrŻ¼æ¬ĮŌøQ┐╔┐┐ąį║═ąį─▄ķ_õNå¢Ņ}ĪŻĮŌøQ┐╔┐┐ąįĄ─ėąą¦ĘĮĘ©╩Ū▓╔ė├Ė¶ļxÖCųŲŻ¼į┌Ę■äšŲ„ų«╔Ž┤µį┌ČÓéĆ╠ōöMÖCīŹ└²ŪķørŽ┬Ż¼æ¬┤_▒Ż╠ōöMÖCų«ķgĄ─═Ļ╚½Ė¶ļxŻ¼╝┤ę╗éĆ╠ōöMÖC▒└Øó▓╗Ģ■ė░ĒæĄĮŲõ╦¹Ą─╠ōöMÖCŻ¼─▄╝░ĢrÅ─╣╩šŽųą╗ųÅ═ĪŻ─┐Ū░Ż¼ļŖ┴”öĄō■ųąą─Ą─śIäšæ¬ė├ŽĄĮyŲš▒ķ▓╔ė├Ų¾śI╝ēJ2EE æ¬ė├Ę■äšŲ„Ż¼═©▀^ć°ļH╔╠ė├ÖCŲ„╣½╦ŠŻ©IBMŻ®║═VMwareī”Żūeb Sphere║═VMware ESXĄ─ąį─▄£yįć┐╔ęį┐┤│÷Ż¼Ę■äšŲ„╠ōöM╗»Ģ■ĖČ│÷ŽĄĮyķ_õNŻ¼Ą½ąį─▄Ž┬ĮĄĄ─Ę∙Č╚ęčĮøūāĄ├┐╔ęįĮė╩▄ĪŻ
2Ż«3 ļŖ┴”öĄō■ųąą─įŲėŗ╦ŃŲĮ┼_
2Ż«3Ż«1 HadoopĄ─╝╝ąg╝▄śŗ╝░Ųõ╠žš„
ļŖ┴”öĄō■ųąą─įŲėŗ╦ŃŲĮ┼_╩Ūę╗éĆ├µŽ“ųŪ─▄ļŖŠWśIäšæ¬ė├Ą─╦ĮėąįŲĪŻęįGoogle┼cAmazon×ķ┤·▒ĒĄ─╔╠ė├ą═įŲėŗ╦Ń╝╝ągų„ę¬æ¬ė├ė┌Ė„ūįŲ¾śIĄ─╦č╦„ę²Ūµ┼cļŖūė╔╠䚥╚Ąõą═╗ź┬ōŠWæ¬ė├Ż¼¤oĘ©ų▒Įėæ¬ė├ė┌ļŖ┴”öĄō■ųąą─įŲėŗ╦ŃŲĮ┼_ĪŻ
Hadoopū„×ķę╗éĆķ_į┤Ą─įŲėŗ╦Ń┐“╝▄Ż¼Ųõ║╦ą─░³└©HadoopĘų▓╝╩Į╬─╝■ŽĄĮyĪóĘų▓╝╩ĮöĄō■╠Ä└Ē║═Ęų▓╝╩ĮĮYśŗ╗»öĄō■▒ĒŻ¼┐╔ęįØMūŃļŖ┴”öĄō■ųąą─Ą─ąĶ꬯¼▒ŻūCŲõĖ▀┐╔┐┐ąįĪóĖ▀┐╔ė├ąį┼c┐╔╔ņ┐sąįŻ¼ų„ę¬¾w¼Fį┌ęįŽ┬ĘĮ├µĪŻ
1Ż®HadoopĘų▓╝╩Į╬─╝■ŽĄĮyŠ▀éõ▌^×ķ═Ļ╔ŲĄ─╚▀ėÓéõĘ▌║═╣╩šŽ╗ųÅ═ÖCųŲŻ¼┐╔ęį▓┐╩į┌┴«ārė▓╝■ų«╔ŽŻ¼─▄ē“Ė▀╚▌ÕeĪóĖ▀┐╔┐┐┤µā”ųŪ─▄ļŖŠW║Ż┴┐öĄō■ĪŻ
2Ż®HadoopĘų▓╝╩Į╬─╝■ŽĄĮyīóų¦│ųžō▌dŠ∙║Ō▓▀┬įŻ¼▒ŻūC┐╔╔ņ┐sąįĪŻ╚¶─│éĆ╣سcĄ─┐šķe┐šķgŽ┬ĮĄĄĮę╗Č©│╠Č╚Ż¼Ģ■ūįäėīóöĄō■░ßęŲĄĮŲõ╦¹╣سcĪŻ▀@śėŻ¼į┌žō▌dūā┤¾Ą─Ģr║“┐╔╠ßĖ▀ūį╔ĒĄ──▄┴”ęį▀m欞ō▌dĪŻ
3Ż®Ęų▓╝╩ĮöĄō■╠Ä└Ē║═Ęų▓╝╩ĮĮYśŗ╗»öĄō■▒Ē┐╔ų¦│ųĮYśŗ╗»┤µā”Ż¼Ų┴▒╬ĄūīėĘų▓╝╩ĮŠÄ│╠Ż¼ĮĄĄ═ķ_░lļyČ╚Ż¼▒ŻūCī”ųŪ─▄ļŖŠW┤¾ęÄ─ŻöĄō■╝»Ą─Ė▀═╠═┬┴┐įLå¢ĪŻ
4Ż®Hadoop╩ŪGoogleįŲėŗ╦ŃŲĮ┼_Ą─ķ_į┤īŹ¼FŻ¼ęčĮø▒╗ųąć°ęŲäėĪóč┼╗óĄ╚Ų¾śIū„×ķĖ„ūį║Ż┴┐öĄō■┤µā”┼c╠Ä└ĒŲĮ┼_Ą─╗∙▒Š╝╝ągĪŻķ_į┤╗»▒Ńė┌ßśī”ųŪ─▄ļŖŠWśIäšæ¬ė├▀MąąčąŠ┐┼cČ■┤╬ķ_░lŻ¼ęį┤_▒Żūįų„ų¬ūR«aÖÓĪŻ
2Ż«3Ż«2 ╗∙ė┌HadoopĄ─ļŖ┴”öĄō■ųąą─įŲėŗ╦ŃŲĮ┼_
ļŖ┴”öĄō■ųąą─Į©įOĄ─ūŅĮK─┐Ą─╩Ū×ķĖ„éĆśI䚎ĄĮyĪóöĄō■═┌Š“┼c▌oų·ų¦│ųĄ╚æ¬ė├╠ß╣®öĄō■┤µā”Īó╣▄└Ē┼cĖ▀ąį─▄ėŗ╦ŃŁhŠ│ĪŻ×ķ┴╦ØMūŃųŪ─▄ļŖŠWī”ļŖ┴”öĄō■ųąą─Ą─Ė³Ė▀ąĶŪ¾Ż¼įOėŗ┴╦╗∙ė┌HadoopĄ─ļŖ┴”öĄō■ųąą─įŲėŗ╦ŃŲĮ┼_Ż¼╚ńłD4╦∙╩ŠĪŻ
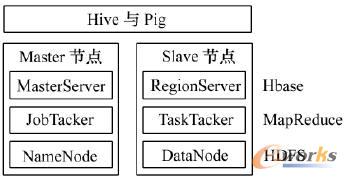
łD4 ╗∙ė┌HadoopĄ─ļŖ┴”öĄō■ųąą─įŲėŗ╦ŃŲĮ┼_
š¹éĆŲĮ┼_▓╔ė├ų„Å─╝▄śŗŻ¼Å─ļŖ┴”öĄō■ųąą─Ą─╠ōöM╗»Ę■äšŲ„╝»╚║ųą▀xō±ę╗éĆĘ■äšŲ„ū„×ķų„╣سcŻ¼Ųõ╦¹╣سcū„×ķÅ─╣سcĪŻNameNode▓┐╩į┌ų„╣سcŻ¼žōž¤╣▄└ĒĘų▓╝╩Į╬─╝■ŽĄĮyĄ─į¬öĄō■Ż¼ł╠ąą╬─╝■Ą─┤“ķ_ĪóĻPķ]┼cųž├³├¹Ą╚├³├¹┐šķg▓┘ū„Ż¼▓óģfš{┐═æ¶Č╦ī”╬─╝■Ą─įLå¢ĪŻDataNodežōž¤╠Ä└Ē┐═æ¶Č╦ī”öĄō■ēKĄ─äōĮ©ĪóÅ═ųŲĪóäh│²╝░ūxīæšłŪ¾ĪŻ├┐éĆ╬─╝■▒╗Ęų│╔─¼šJ┤¾ąĪ×ķ64 MB Ą─öĄō■ēKŻ¼╚▀ėÓ┤µā”į┌Å─╣سcĄ─DataNodeŻ¼└²╚ńŻ¼«öÅ═ųŲę“ūė×ķ3ĢrŻ¼ę╗éĆöĄō■ēKĖ▒▒Š┤µĘ┼į┌▒ŠĄžÖC╝▄Ą─DataNodeųąŻ¼┴Ēę╗éĆĖ▒▒Š┤µĘ┼į┌═¼ę╗éĆÖC╝▄Ą─┴Ēę╗éĆDataNodeųąŻ¼ūŅ║¾ę╗éĆĖ▒▒Š┤µĘ┼į┌Ųõ╦¹ÖC╝▄Ą─DataNodeųąĪŻ▀@ĘNĘĮĘ©īŹ¼F║åå╬Ż¼═©▀^╚▀ėÓéõĘ▌║═╣╩šŽ╗ųÅ═ÖCųŲŻ¼┐╔ęį┤_▒ŻļŖ┴”öĄō■ųąą─ī”┤¾ęÄ─ŻųŪ─▄ļŖŠWą┼ŽóĄ─┐╔┐┐┤µā”ĪŻ
▓╔ė├MapReduceū„×ķ╠Ä└ĒļŖ┴”öĄō■ųą║Ż┴┐öĄō■Ą─▓󹹊Ä│╠─Żą═║═ėŗ╦Ń┐“╝▄ĪŻī”ė┌┤¾ęÄ─ŻöĄō■╝»Ą─▓┘ū„Ż¼▓╔ė├╚╬äšĘųĮŌ┼cĮY╣¹ģR┐éĄ─ĘĮĘ©ĪŻ└²╚ńŻ¼īóėŗ╦ŃĀŅæB▒O£yą┼ŽóĄ─ūŅ┤¾ųĄĪóūŅąĪųĄĪóŲĮŠ∙ųĄĪó═¼▒╚┼cŁh▒╚Ą╚öĄō■▀MąąČ■┤╬╝ė╣ż▓┘ū„Ż¼Ęų░lĮoJobTrackerŻ©▓┐╩į┌ų„╣سcŻ®╣▄└ĒŽ┬Ą─Ė„éĆTaskTrackerŻ©▓┐╩į┌Å─╣سcŻ®╣▓═¼═Ļ│╔Ż¼╚╗║¾š¹║ŽĖ„éĆTaskTrackerĄ─ųąķgĮY╣¹Ż¼½@Ą├ūŅĮKĄ─ėŗ╦ŃĮY╣¹ĪŻ┴Ē═ŌŻ¼▓╔ė├Į©┴óį┌MapReduceŠÄ│╠─Żą═ų«╔ŽĄ─Ė▀╝ēöĄō■┴„šZčįPigŻ¼ė├ė┌║å╗»MapReduce╚╬䚥─ķ_░l▀^│╠ĪŻ╔Ž╩÷ĘĮĘ©īóėŗ╦Ń╣سcTaskTracker┼c┤µā”╣سcDataNode▓┐╩į┌═¼ę╗Ę■äšŲ„Ż¼─▄ē“▒▄├ŌŠWĮjĦīÆŲ┐ŅiŻ¼ėąą¦£p╔┘é„ĮyĘų▓╝╩Įėŗ╦ŃųąöĄō■į┌ŠWĮjųąĄ─é„▌öŻ¼×ķļŖ┴”öĄō■ųąą─╠ß╣®Ė▀ąį─▄Ą─Ęų▓╝╩Įėŗ╦ŃŁhŠ│ĪŻ
öĄō■Äņ┼cöĄō■é}Äņ╩ŪļŖ┴”öĄō■ųąą─īŹ¼FöĄō■═┌Š“┼c▌oų·øQ▓▀Ą─╗∙ĄAĪŻ▓╔ė├HBaseū„×ķļŖ┴”öĄō■ųąą─╦∙ę¬Ū¾Ą─Ė▀┐╔┐┐ĪóĖ▀ąį─▄ĪóīŹĢrūxīæĄ─Ęų▓╝╩ĮöĄō■ÄņŽĄĮyŻ¼īó┤ų┴ŻČ╚ĪóĮYśŗ╗»Ą─öĄō■░┤┴ąūÕ┤µā”į┌ę╗ÅłŠ▐┤¾Ą─ŽĪ╩Ķ▒ĒųąŻ¼░┤ššąąµIīó▒ĒäØĘų│╔ČÓéĆRegionŻ¼Ęų▓╝į┌Å─╣سcĄ─RegionServerų«╔ŽŻ¼▓óīóRegionęį╬─╝■Ą─ą╬╩Į┤µā”į┌Ęų▓╝╩Į╬─╝■ŽĄĮyųąĪŻRegionServeržōž¤┐═æ¶Č╦ī”RegionĄ─ūxīæšłŪ¾┼c▓┘ū„Ż¼Č°ų„╣سcĄ─MasterServeržōž¤RegionĄ─Ęų┼õŻ¼ģfš{RegionServerĄ─žō▌d▓ó▀MąąĀŅæBĄ─ŠSūoĪŻ┴Ē═ŌŻ¼▓╔ė├Hiveū„×ķļŖ┴”öĄō■ųąą─Ą─öĄō■é}ÄņŲĮ┼_Ż¼ī”Ęų▓╝╩Į╬─╝■ŽĄĮy╔ŽĄ─ųŪ─▄ļŖŠWśIäšöĄō■▀MąąETLŻ¼śŗĮ©öĄō■é}ÄņŻ¼▓╔ė├ŅÉ╦Ųė┌ĮYśŗ╗»▓ķįāšZčįŻ©SQLŻ®Ą─HiveQLīŹ¼Fī”┤¾ęÄ─ŻöĄō■╝»Ą─▓ķįā┼cĘų╬÷ĪŻĘų▓╝╩ĮöĄō■Ęų╬÷╠Ä└Ē┼cé„ĮySQLŽÓĮY║Žėą└¹ė┌é„ĮyŽĄĮyŽ“ą┬ŲĮ┼_Ą─▀węŲĪŻ
3 ¼FėąļŖ┴”öĄō■ųąą─Ž“įŲėŗ╦ŃĄ─▀węŲ▓▀┬į
3Ż«1 ▀węŲĄ──┐Ą─
ļŖ┴”öĄō■ųąą─Ą─įOėŗ┼cĮ©įO╩Ūę╗ĒŚ²ŗ┤¾Ą─ŽĄĮy╣ż│╠ĪŻ¼FėąĄ─öĄō■ųąą─ė╔ć°╝ęļŖŠW╣½╦ŠĮyę╗ęÄäØĮ©įOŻ¼Ą½Ė„ĄžĄ─ą┼Žó╗»╦«ŲĮĪóśI䚎ĄĮyæ¬ė├┼c│╔╩ņ│╠Č╚▓╗═¼Ż¼╩╣Ą├Ė„éĆŠW╩Ī╣½╦ŠöĄō■ųąą─Į©įOėąŲõūį╔ĒĄ─╠ž³cŻ¼▓┐ĘųļŖ┴”öĄō■ųąą─ęčĮøę²╚ļ┴╦╠ōöM╗»╝╝ągŻ¼│§▓ĮŠ▀éõ┴╦įŲėŗ╦Ń─▄┴”Ż¼Č°ČÓöĄļŖ┴”öĄō■ųąą─╚į╚╗═Ż┴¶į┌é„ĮyöĄō■ųąą─Ą─╦«ŲĮŻ¼▀h╬┤▀_ĄĮą┬ę╗┤·öĄō■ųąą─ī”ųŪ─▄ļŖŠW║Ż┴┐öĄō■┤µā”┼cĖ▀ą¦ėŗ╦ŃĪóĖ▀┐╔┐┐ąįĪóĖ▀┐╔ė├ąį┼c┐╔╔ņ┐sąįĄ─ę¬Ū¾ĪŻ
╗∙ė┌įŲėŗ╦ŃĄ─ą┬ę╗┤·ļŖ┴”öĄō■ųąą─╩Ū╬┤üĒĄ─░lš╣ĘĮŽ“ĪŻ┐╝æ]ĄĮļŖ┴”öĄō■ųąą─ęčĮø│§▓ĮĮ©┴óŻ¼ųŪ─▄ļŖŠW╚į╠Äė┌│§╝ēĮ©įOļAČ╬Ż¼æ¬┤_▒Ż¼FėąļŖ┴”öĄō■ųąą─Ž“ą┬ę╗┤·įŲėŗ╦ŃöĄō■ųąą─Ą─ĘųļAČ╬ŲĮĘĆ▀^Č╔Ż¼ę╗ĘĮ├µ▒ŻšŽ¼FėąļŖ┴”öĄō■ųąą─Ą─š²│Ż▀\ąąŻ¼┴Ēę╗ĘĮ├µų▓Į▀mæ¬ųŪ─▄ļŖŠW░lš╣Ą─ąĶę¬ĪŻ
3Ż«2 ▀węŲ▓▀┬į╝░ąĶę¬ĮŌøQĄ─ļy³cå¢Ņ}
Įo│÷¼FėąļŖ┴”öĄō■ųąą─Ž“╗∙ė┌įŲėŗ╦ŃĄ─ą┬ę╗┤·ļŖ┴”öĄō■ųąą─Ą─ĘųļAČ╬▀węŲ▓▀┬įŻ¼ęį┤_▒ŻŲĮĘĆ▀^Č╔ĪŻ
1Ż®ų▓Įīó╣½╦Š┐é▓┐ęį╝░Ė„éĆŠW╩Ī╣½╦ŠĄ─ļŖ┴”öĄō■ųąą─╔²╝ē×ķįŲ╣سcĪŻīóöĄō■ųąą─Ą─╗∙ĄAįO╩®╠ōöM╗»Ż¼╠ß╔²Ę■䚥─┐╔ė├ąį┼cÅŚąį┐╔öUš╣ąįŻ¼╔²╝ē╗“Ė─įņ×ķ├µŽ“įŲėŗ╦ŃĄ─öĄō■ųąą─Ż¼╝┤įŲ╣سcĪŻ
2Ż®īóĖ„éĆįŲ╣سc▀BĮė│╔ļŖ┴”Ų¾śIā╚▓┐Ą─╦ĮėąįŲĪŻĖ„éĆļŖ┴”öĄō■ųąą─▓┐╩×ķĖ▀┐╔ė├Īó┐╔öUš╣Ą─įŲ╣سc║¾Ż¼īóĖ„éĆįŲ╣سc▀BĮėį┌ę╗ŲŻ¼śŗ│╔ę╗éĆČÓųąą─Ą─╦ĮėąįŲŻ¼╚ńłD5╦∙╩ŠĪŻ
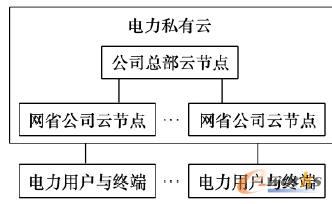
łD5 ļŖ┴”öĄō■ųąą─╦ĮėąįŲ
į┌╗∙ė┌įŲėŗ╦ŃĄ─ą┬ę╗┤·ļŖ┴”öĄō■ųąą─Ą─Į©įO║═▀węŲ▀^│╠ųąŻ¼├µ┼Rų°╚ńŽ┬ąĶę¬ųž³cĮŌøQĄ─å¢Ņ}ĪŻ
1Ż®į┌ļŖ┴”öĄō■ųąą─╔²╝ē×ķįŲ╣سcĄ─▀^│╠ųąŻ¼ąĶę¬ųž³cĮŌøQ╗∙ĄAįO╩®╠ōöM╗»Ą─å¢Ņ}ĪŻ─┐Ū░┤µį┌ČÓĘN╠ōöM╗»ĮŌøQĘĮ░ĖŻ¼└²╚ńIBM Ą─zVM ┼cPowerVMŻ¼VMwareĄ─VMware ESX ServerŻ¼╬ó▄øĄ─HyperŻŁVĄ╚ĪŻį┌▀xō±ĮŌøQĘĮ░ĖĢræ¬│õĘų┐╝æ]┼c¼FėąļŖ┴”öĄō■ųąą─Ą─╝µ╚▌ąįŻ¼£p╔┘▀węŲ│╔▒ŠĪŻ
2Ż®į┌ļŖ┴”öĄō■ųąą─╦ĮėąįŲųąŻ¼Ė„éĆŠW╩Ī╣½╦ŠöĄō■ųąą─┼c╣½╦Š┐é▓┐öĄō■ųąą─ų«ķgąĶę¬é„╦═┤¾┴┐Ą─śIäšöĄō■Ż¼┐╔ęįį┌Ė„éĆįŲ╣سcįOų├žō▌dŠ∙║ŌįOéõŻ¼śŗĮ©ļŖ┴”ŽĄĮyÅVė“ŠWĄ─╝ė╦┘═©Ą└Ż¼ęįĮŌøQöĄō■é„▌öŲ┐Ņiå¢Ņ}ĪŻ
3Ż®░▓╚½ąį╩ŪįŲėŗ╦Ńį┌ļŖ┴”öĄō■ųąą─æ¬ė├▀^│╠ųąąĶę¬ĮŌøQĄ─ę╗éĆųžę¬å¢Ņ}ĪŻ╗∙ė┌įŲėŗ╦ŃĄ─ą┬ę╗┤·ļŖ┴”öĄō■ųąą─╩Ūį┌ļŖ┴”Ų¾śIā╚▓┐Į©┴óĄ─╦ĮėąįŲŻ¼┐╔ūį╬ę╣▄└Ē┼cŠSūoŻ¼śIäšöĄō■═©▀^ļŖ┴”ŽĄĮyÅVė“īŻŠWé„▌öĪŻļŖ┴”öĄō■ųąą─į┌ļŖ┴”░▓╚½Ęųģ^¾wŽĄųąī┘ė┌╣▄└Ēą┼Žó┤¾ģ^Ż©░▓╚½ģ^ó¾Ż®Ż¼┐╔ęįįOų├ļŖ┴”īŻė├Ą─å╬Ž“░▓╚½Ė¶ļxčbų├Ż¼į┌╬’└Ēīė├µ╔ŽīŹ¼F┼c╔·«a┐žųŲ┤¾ģ^╝░═Ō▓┐╣½╣▓ą┼ŽóŠWĄ─░▓╚½Ė¶ļxĪŻ
4Ż®į┌ļŖ┴”öĄō■ųąą─╦ĮėąįŲų«╔ŽŻ¼Įyę╗▓┐╩╗∙ė┌HadoopĄ─įŲėŗ╦ŃŲĮ┼_ĪŻį┌Hadoop╝╝ągĄ─╗∙ĄA╔Žūįų„čą░lįŲėŗ╦ŃŲĮ┼_Ż¼īó╩ŪĮ©įOą┬ę╗┤·ļŖ┴”öĄō■ųąą─Ą─ĻPµIŻ¼ŽÓĻP蹊┐╣żū„š²į┌▀Mę╗▓Įķ_š╣Ż¼čąŠ┐│╔╣¹īó┴Ē╬─ėæšōĪŻ
4 ĮYšZ
▒Š╬─═©▀^蹊┐Ę■äšŲ„╠ōöM╗»ĪóīŹĢr▀węŲĪóHadoopĄ╚╝╝ągå¢Ņ}Ż¼Įo│÷┴╦ļŖ┴”Ų¾śIįŲėŗ╦ŃöĄō■ųąą─Ą─š¹¾w╝▄śŗŻ¼▓óįOėŗ┴╦╗∙ė┌HadoopĄ─ļŖ┴”öĄō■ųąą─įŲėŗ╦ŃŲĮ┼_Ż¼ęįĘ¹║Žą┬ę╗┤·öĄō■ųąą─Ą─░lš╣┌ģä▌Ż¼ØMūŃųŪ─▄ļŖŠWĄ─śIäšąĶę¬ĪŻįŲėŗ╦Ńū„×ķą┬┼d╝╝ągŻ¼Ųõ¾wŽĄĮYśŗĪó╠ōöM╗»ĪóöĄō■┤µā”╝░┘Yį┤╣▄└ĒĄ╚å¢Ņ}╚į╚╗ėą┤²▀Mę╗▓Į蹊┐ĪŻ║¾└möMßśī”ųŪ─▄ļŖŠWĄ─Š▀¾wśIäšæ¬ė├┼cą┼ŽóĘ■䚯¼čąŠ┐ū„śIĄ─Ęų┼õ▓▀┬į┼cš{Č╚╦ŃĘ©Ż¼▓ó▓╔ė├įŲĘ┬šµ╣żŠ▀CloudSim ▀Mąąąį─▄▒╚▌^║═ā×╗»ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║╗∙ė┌įŲėŗ╦ŃĄ─ļŖ┴”öĄō■ųąą─╗∙ĄA╝▄śŗ╝░ŲõĻPµI╝╝ąg(Ž┬)
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/1083976751.html






















