



1 öĄō■é}Äņ(DW)
1.1 öĄō■é}ÄņČ©┴x
öĄō■é}Äņų«ĖĖBill Inmonį┌1991─Ļ│÷░µĄ─Ī░Building the Data WarehouseĪ▒ę╗Ģ°ųą╦∙╠ß│÷Ą─Č©┴x▒╗ÅVĘ║Įė╩▄Ż║öĄō■é}Äņ(Data Warehouse)╩Ūę╗éĆ├µŽ“ų„Ņ}Ą─(Subject Oriented)Īó╝»│╔Ą─(Integrated)ĪóŽÓī”ĘĆČ©Ą─(Non-Volatile)ĪóĘ┤ė│Üv╩Ęūā╗»(Time Variant)Ą─öĄō■╝»║ŽŻ¼ė├ė┌ų¦│ų╣▄└ĒøQ▓▀(Decision Making Support)ĪŻ
ī”ė┌öĄō■é}ÄņĄ─Ė┼─Ņ╬ęéā┐╔ęįÅ─ā╔éĆīė┤╬ėĶęį└ĒĮŌŻ¼╩ūŽ╚Ż¼öĄō■é}Äņė├ė┌ų¦│ųøQ▓▀Ż¼├µŽ“Ęų╬÷ą═öĄō■╠Ä└ĒŻ¼╦³▓╗═¼ė┌Ų¾śI¼FėąĄ─▓┘ū„ą═öĄō■ÄņŻ╗Ųõ┤╬Ż¼öĄō■é}Äņ╩Ūī”ČÓéĆ«ÉśŗĄ─öĄō■į┤ėąą¦╝»│╔Ż¼╝»│╔║¾░┤ššų„Ņ}▀Mąą┴╦ųžĮMŻ¼▓ó░³║¼Üv╩ĘöĄō■Ż¼Č°Ūę┤µĘ┼į┌öĄō■é}ÄņųąĄ─öĄō■ę╗░Ń▓╗į┘ą▐Ė─ĪŻ
1.2 öĄō■é}Äņ╠ž³c
1Īó├µŽ“ų„Ņ}ĪŻ▓┘ū„ą═öĄō■ÄņĄ─öĄō■ĮM┐Ś├µŽ“╩┬äš╠Ä└Ē╚╬䚯¼Ė„éĆśI䚎ĄĮyų«ķgĖ„ūįĘųļxŻ¼Č°öĄō■é}ÄņųąĄ─öĄō■╩Ū░┤ššę╗Č©Ą─ų„Ņ}ė“▀MąąĮM┐ŚĪŻų„Ņ}╩Ūę╗éĆ│ķŽ¾Ą─Ė┼─ŅŻ¼╩ŪųĖė├æ¶╩╣ė├öĄō■é}Äņ▀MąąøQ▓▀Ģr╦∙ĻPą─Ą─ųž³cĘĮ├µŻ¼ę╗éĆų„Ņ}═©│Ż┼cČÓéĆ▓┘ū„ą═ą┼ŽóŽĄĮyŽÓĻPĪŻ
2Īó╝»│╔Ą─ĪŻ├µŽ“╩┬äš╠Ä└ĒĄ─▓┘ū„ą═öĄō■Äņ═©│Ż┼c─│ą®╠žČ©Ą─æ¬ė├ŽÓĻPŻ¼öĄō■Äņų«ķgŽÓ╗ź¬Ü┴óŻ¼▓óŪę═∙═∙╩Ū«ÉśŗĄ─ĪŻČ°öĄō■é}ÄņųąĄ─öĄō■╩Ūį┌ī”įŁėąĘų╔óĄ─öĄō■ÄņöĄō■│ķ╚ĪĪóŪÕ└ĒĄ─╗∙ĄA╔ŽĮø▀^ŽĄĮy╝ė╣żĪóģR┐é║═š¹└ĒĄ├ĄĮĄ─Ż¼▒žĒÜŽ¹│²į┤öĄō■ųąĄ─▓╗ę╗ų┬ąįŻ¼ęį▒ŻūCöĄō■é}Äņā╚Ą─ą┼Žó╩ŪĻPė┌š¹éĆŲ¾śIĄ─ę╗ų┬Ą─╚½Šųą┼ŽóĪŻ
3ĪóŽÓī”ĘĆČ©Ą─ĪŻ▓┘ū„ą═öĄō■ÄņųąĄ─öĄō■═©│ŻīŹĢrĖ³ą┬Ż¼öĄō■Ė∙ō■ąĶę¬╝░Ģr░l╔·ūā╗»ĪŻöĄō■é}ÄņĄ─öĄō■ų„ę¬╣®Ų¾śIøQ▓▀Ęų╬÷ų«ė├Ż¼╦∙╔µ╝░Ą─öĄō■▓┘ū„ų„ę¬╩ŪöĄō■▓ķįāŻ¼ę╗Ą®─│éĆöĄō■▀M╚ļöĄō■é}Äņęį║¾Ż¼ę╗░ŃŪķørŽ┬īó▒╗ķLŲ┌▒Ż┴¶Ż¼ę▓Š═╩ŪöĄō■é}Äņųąę╗░Ńėą┤¾┴┐Ą─▓ķįā▓┘ū„Ż¼Ą½ą▐Ė─║═äh│²▓┘ū„║▄╔┘Ż¼═©│Żų╗ąĶę¬Č©Ų┌Ą─╝ė▌dĪó╦óą┬ĪŻ
4ĪóĘ┤ė│Üv╩Ęūā╗»ĪŻ▓┘ū„ą═öĄō■Äņų„ę¬ĻPą─«öŪ░─│ę╗éĆĢrķgČ╬ā╚Ą─öĄō■Ż¼Č°öĄō■é}ÄņųąĄ─öĄō■═©│Ż░³║¼Üv╩Ęą┼ŽóŻ¼ŽĄĮyėøõø┴╦Ų¾śIÅ─▀^╚ź─│ę╗Ģr³c(╚ńķ_╩╝æ¬ė├öĄō■é}ÄņĄ─Ģr³c)ĄĮ─┐Ū░Ą─Ė„éĆļAČ╬Ą─ą┼ŽóŻ¼═©▀^▀@ą®ą┼ŽóŻ¼┐╔ęįī”Ų¾śIĄ─░lš╣Üv│╠║═╬┤üĒ┌ģä▌ū÷│÷Č©┴┐Ęų╬÷║═ŅA£yĪŻ
Ų¾śIöĄō■é}ÄņĄ─Į©įOŻ¼╩Ūęį¼FėąŲ¾śIśI䚎ĄĮy║═┤¾┴┐śIäšöĄō■Ą─Ęe└█×ķ╗∙ĄAĪŻöĄō■é}Äņ▓╗╩ŪņoæBĄ─Ė┼─ŅŻ¼ų╗ėą░čą┼Žó╝░ĢrĮ╗ĮoąĶę¬▀@ą®ą┼ŽóĄ─╩╣ė├š▀Ż¼╣®╦¹éāū÷│÷Ė─╔ŲŲõśIäšĮøĀIĄ─øQ▓▀Ż¼ą┼Žó▓┼─▄░lō]ū„ė├Ż¼ą┼Žó▓┼ėąęŌ┴xĪŻČ°░čą┼Žó╝ėęįš¹└ĒÜw╝{║═ųžĮMŻ¼▓ó╝░Ģr╠ß╣®ĮoŽÓæ¬Ą─╣▄└ĒøQ▓▀╚╦åTŻ¼╩ŪöĄō■é}ÄņĄ─Ė∙▒Š╚╬äšĪŻę“┤╦Ż¼Å─«aśIĮńĄ─ĮŪČ╚┐┤Ż¼öĄō■é}ÄņĮ©įO╩Ūę╗éĆ╣ż│╠Ż¼ę▓╩Ūę╗éĆ▀^│╠ĪŻ
1.3 öĄō■é}Äņ¾wŽĄĮYśŗŻ║
ę╗░ŃüĒšfŻ¼┤¾╣½╦Š╗“Ų¾śIā╚┤µį┌ų°Ė„ĘNĖ„śėĄ─ą┼ŽóŽĄĮyŻ¼▀@ą®æ¬ė├“īäėĄ─▓┘ū„ą═ą┼ŽóŽĄĮy×ķŲ¾śI▓╗═¼Ą─śI䚎ĄĮyĘ■䚯¼Š▀ėą▓╗═¼Įė┐┌║═▓╗═¼Ą─öĄō■▒Ē╩ŠĘĮĘ©Ż¼╗źŽÓ╣┬┴óĪŻ└¹ė├öĄō■é}Äņ╝╝ąg┐╔ęįäėæBĄžīóĖ„éĆ«ÉśŗŽĄĮyųąĄ─öĄō■│ķ╚Ī╝»│╔ĄĮę╗ŲŻ¼▀MąąŪÕŽ┤Īó▐DōQĄ╚╠Ä└Ēų«║¾╝ė▌dĄĮöĄō■é}ÄņųąŻ¼═©▀^ų▄Ų┌ąįĄ─╦óą┬Ż¼×ķė├æ¶╠ß╣®ę╗éĆĮyę╗Ą─Ė╔ā¶Ą─öĄō■ęĢłDŻ¼×ķöĄō■Ęų╬÷╠ß╣®ę╗éĆĖ▀┘|┴┐Ą─öĄō■į┤ĪŻš¹éĆöĄō■é}ÄņŽĄĮy╩Ūę╗éĆ░³║¼╦─éĆīė┤╬Ą─¾wŽĄĮYśŗŻ¼Š▀¾wė╔łD1▒Ē╩ŠĪŻ
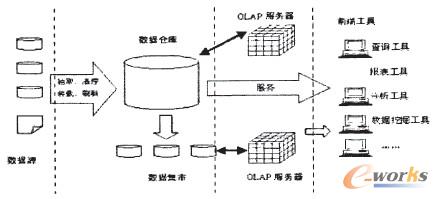
łD1 öĄō■é}ÄņŽĄĮy╝▄śŗłD
öĄō■į┤Ż║╩ŪöĄō■é}ÄņŽĄĮyĄ─╗∙ĄAŻ¼╩Ūš¹éĆŽĄĮyĄ─öĄō■į┤╚¬ĪŻ═©│Ż░³└©Ų¾śIā╚▓┐ą┼Žó║══Ō▓┐ą┼ŽóĪŻā╚▓┐ą┼Žó░³└©┤µĘ┼ė┌RDBMSųąĄ─Ė„ĘNśIäš╠Ä└ĒöĄō■║═Ė„ŅÉ╬─ÖnöĄō■ĪŻ═Ō▓┐ą┼Žó░³└©Ė„ŅÉĘ©┬╔Ę©ęÄĪó╩ął÷ą┼Žó║═ĖéĀÄī”╩ųĄ─ą┼ŽóĄ╚Ą╚Ż╗
öĄō■Ą─┤µā”┼c╣▄└ĒŻ║╩Ūš¹éĆöĄō■é}ÄņŽĄĮyĄ─║╦ą─ĪŻöĄō■é}ÄņĄ─šµš²ĻPµI╩ŪöĄō■Ą─┤µā”║═╣▄└ĒĪŻöĄō■é}ÄņĄ─ĮM┐Ś╣▄└ĒĘĮ╩ĮøQČ©┴╦╦³ėąäeė┌é„ĮyöĄō■ÄņŻ¼═¼Ģrę▓øQČ©┴╦Ųõī”═Ō▓┐öĄō■Ą─▒Ē¼Fą╬╩ĮĪŻę¬øQČ©▓╔ė├╩▓├┤«aŲĘ║═╝╝ągüĒĮ©┴óöĄō■é}ÄņĄ─║╦ą─Ż¼ätąĶę¬Å─öĄō■é}ÄņĄ─╝╝ąg╠ž³cų°╩ųĘų╬÷ĪŻßśī”¼FėąĖ„śI䚎ĄĮyĄ─öĄō■Ż¼▀Mąą│ķ╚ĪĪóŪÕ└ĒŻ¼▓óėąą¦╝»│╔Ż¼░┤ššų„Ņ}▀MąąĮM┐ŚĪŻöĄō■é}Äņ░┤ššöĄō■Ą─Ė▓╔wĘČć·┐╔ęįĘų×ķŲ¾śI╝ēöĄō■é}Äņ║═▓┐ķT╝ēöĄō■é}Äņ(═©│ŻĘQ×ķĪ░öĄō■╝»╩ąĪ▒)ĪŻ
OLAPĘ■äšŲ„Ż║ī”Ęų╬÷ąĶꬥ─öĄō■▀Mąąėąą¦╝»│╔Ż¼░┤ČÓŠS─Żą═ėĶęįĮM┐ŚŻ¼ęį▒Ń▀MąąČÓĮŪČ╚ĪóČÓīė┤╬Ą─Ęų╬÷Ż¼▓ó░l¼F┌ģä▌ĪŻŲõŠ▀¾wīŹ¼F┐╔ęįĘų×ķŻ║ROLAPĪóMOLAP║═HOLAPĪŻROLAP╗∙▒ŠöĄō■║═Š█║ŽöĄō■Š∙┤µĘ┼į┌RDBMSų«ųąŻ╗MOLAP╗∙▒ŠöĄō■║═Š█║ŽöĄō■Š∙┤µĘ┼ė┌ČÓŠSöĄō■ÄņųąŻ╗HOLAP╗∙▒ŠöĄō■┤µĘ┼ė┌RDBMSų«ųąŻ¼Š█║ŽöĄō■┤µĘ┼ė┌ČÓŠSöĄō■ÄņųąĪŻ
Ū░Č╦╣żŠ▀Ż║ų„ę¬░³└©Ė„ĘNł¾▒Ē╣żŠ▀Īó▓ķįā╣żŠ▀ĪóöĄō■Ęų╬÷╣żŠ▀ĪóöĄō■═┌Š“╣żŠ▀ęį╝░Ė„ĘN╗∙ė┌öĄō■é}Äņ╗“öĄō■╝»╩ąĄ─æ¬ė├žó░l╣żŠ▀ĪŻŲõųąöĄō■Ęų╬÷╣żŠ▀ų„ę¬ßśī”OLAPĘ■äšŲ„Ż¼ł¾▒Ē╣żŠ▀ĪóöĄō■═┌Š“╣żŠ▀ų„ę¬ßśī”öĄō■é}ÄņĪŻ
öĄō■é}Äņ▓╗Ģ■╩Ūę╗éĆ═Ļ╔ŲĄ─╠ß╣®æ┬įą┼ŽóĄ─▄ø╝■╗“š▀ė▓╝■«aŲĘŻ¼Č°╩Ūę╗éĆė├æ¶┐╔ęįÅ─ųąšęĄĮæ┬įą┼ŽóĄ─ėŗ╦ŃŁhŠ│ĪŻį┌▀@éĆŁhŠ│ųąŻ¼ė├æ¶┐╔ęį═©▀^┼cöĄō■Ą─ų▒ĮėĮėė|üĒū÷│÷Ė³║├Ą─øQ▓▀ĪŻ╦³╩Ūę╗éĆęįė├æ¶×ķųąą─Ą─ŁhŠ│ĪŻ
1.4 öĄō■é}ÄņĄ─╣”─▄
ę╗░ŃüĒšfŻ¼┤¾╣½╦Š╗“Ų¾śIā╚┤µį┌ų°Ė„ĘNĖ„śėĄ─ą┼ŽóŽĄĮyŻ¼▀@ą®æ¬ė├“īäėĄ─▓┘ū„ą═ą┼ŽóŽĄĮy×ķŲ¾śI▓╗═¼Ą─śI䚎ĄĮyĘ■䚯¼Š▀ėą▓╗═¼Įė┐┌║═▓╗═¼Ą─öĄō■▒Ē╩ŠĘĮĘ©Ż¼╗źŽÓ╣┬┴óĪŻ└¹ė├öĄō■é}Äņ╝╝ąg┐╔ęįäėæBĄžīóĖ„éĆ«ÉśŗŽĄĮyųąĄ─öĄō■│ķ╚Ī╝»│╔ĄĮę╗ŲŻ¼▀MąąŪÕŽ┤Īó▐DōQĄ╚╠Ä└Ēų«║¾╝ė▌dĄĮöĄō■é}ÄņųąŻ¼═©▀^ų▄Ų┌ąįĄ─╦óą┬Ż¼×ķė├æ¶╠ß╣®ę╗éĆĮyę╗Ą─Ė╔ā¶Ą─öĄō■ęĢłDŻ¼×ķöĄō■Ęų╬÷╠ß╣®ę╗éĆĖ▀┘|┴┐Ą─öĄō■į┤ĪŻŠ═Ųõį┌╔╠śIųŪ─▄▀^│╠ųąĄ─ū„ė├Č°čįŻ¼öĄō■é}ÄņŠ▀ėąęįŽ┬╣”─▄Ż║
1ĪóöĄō■Į©─ŻŻ╗2ĪóöĄō■│ķ╚ĪŻ╗3ĪóöĄō■▐DōQŻ╗4ĪóöĄō■čb▌dŻ╗5ĪóöĄō■ŪÕŽ┤Öz“ׯ╗6Īó▓ķįā║═ł¾▒ĒŻ╗7ĪóOLAPŻ╗8Īóā╚▓┐Ą─ųąķg╝■Ż╗9Īóūį╔ĒĄ─╣▄└ĒŠSūoĪŻ
2 ┬ōÖCĘų╬÷╠Ä└Ē(OLAP)
2.1 ┬ōÖCĘų╬÷╠Ä└Ē(OLAP)Č©┴x
ī”ė┌öĄō■é}ÄņųąĄ─öĄō■Ż¼┐╔ęį╩╣ė├ę╗ą®į÷ÅŖĄ─▓ķįā║═ł¾▒Ē╣żŠ▀▀MąąÅ═ļsĄ─▓ķįā║═╝┤ĢrĄ─ł¾▒ĒųŲū„Ż¼┐╔ęį└¹ė├OLAP╝╝ągÅ─ČÓĘNĮŪČ╚ī”śIäšöĄō■▀MąąČÓĘĮ├µĄ─ģR┐éĮyėŗėŗ╦ŃŻ¼▀Ć┐╔ęį└¹ė├öĄō■═┌Š“╝╝ągūįäė░l¼FŲõųąļ[║¼Ą─ėąė├ą┼ŽóĪŻ
┬ōÖCĘų╬÷╠Ä└Ē(OLAP)ūŅįńė╔Arbor▄ø╝■╣½╦ŠĄ─E.F.Coddė┌1993─Ļ╠ß│÷Ż¼╦¹į┌ĪČ×ķĘų╬÷ą═ė├æ¶╠ß╣®OLAP╣żŠ▀Ż║ą┼Žó╝╝ągĄ─ą┬ąĶŪ¾ĪĘ╩ū┤╬ģ^Ęų┴╦├µŽ“╩┬äš╠Ä└ĒĄ─OLTPŽĄĮy║═├µŽ“Ęų╬÷╠Ä└ĒĄ─OLAPŽĄĮyŻ¼▓ó×ķOLAP┤_Č©┴╦ųT╚ńČÓŠSĖ┼─ŅęĢłDĪó═Ė├„ąįĪó┤µ╚Ī─▄┴”Ą╚12ŚlęÄätĪŻ▀@ą®ęÄät┐╔Ė┼└©×ķśIäšæ¬ė├║═╝╝ągæ¬ė├▀@ā╔ŅÉĪŻŲõųąČÓŠSĖ┼─ŅęĢłDŻ¼ęįČÓĮŪČ╚ė^▓ņöĄō■Ą─ĘĮ╩ĮĘĮ▒Ń┴╦śIäšŅÉė├æ¶Ä¦ų°ĮŌøQå¢Ņ}Ą─╝┘įOęį╝░ūį╝║ĮŌøQå¢Ņ}Ą─▀ē▌ŗ═Ų└ĒĄ─╦╝ŠS▀^│╠Ż¼ę▓Š═╩ŪšfŻ¼OLAPĘų╬÷╠ß╣®┴╦ė├æ¶į┌č▌└[ą═╦╝┐╝ųąŪ░╠ßĪó▀ē▌ŗā╔éĆ▓Į¾Eųą╦∙ąĶĄ─Ä═ų·Ż¼ę“┤╦╦³ėąų·ė┌╠ßĖ▀ė├æ¶Ęų╬÷ĮY╣¹Ą─£╩┤_ąįĪŻ┐╔ęŖŻ¼OLAPĘų╬÷╣żŠ▀╩ŪŠC║ŽĘų╬÷īė┤╬Ą─╣żŠ▀ų«ę╗ĪŻ
2.2 OLTP║═OLAPĄ─▒╚▌^
«öĮ±Ą─öĄō■╠Ä└Ē┤¾ų┬┐╔ęįĘų│╔ā╔┤¾ŅÉŻ║┬ōÖC╩┬äš╠Ä└ĒOLTP(on-line transaction processing)Īó┬ōÖCĘų╬÷╠Ä└ĒOLAP(On-Line Analytical Processing)ĪŻOLTP╩Ūé„ĮyĄ─ĻPŽĄą═öĄō■ÄņĄ─ų„ę¬æ¬ė├Ż¼ų„ę¬╩Ū╗∙▒ŠĄ─Īó╚š│ŻĄ─╩┬äš╠Ä└ĒĪŻOLAP╩ŪöĄō■é}ÄņŽĄĮyĄ─ų„ę¬æ¬ė├Ż¼ų¦│ųÅ═ļsĄ─Ęų╬÷▓┘ū„Ż¼é╚ųžøQ▓▀ų¦│ųŻ¼▓óŪę╠ß╣®ų▒ė^ęūČ«Ą─▓ķįāĮY╣¹ĪŻłD2┴ą│÷┴╦OLTP┼cOLAPų«ķgĄ─▒╚▌^ĪŻ
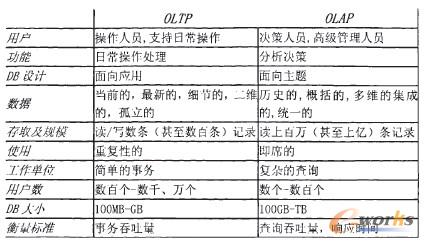
łD2 OLTP┼cOLAPĄ─▒╚▌^
OLAP╩Ū╩╣Ęų╬÷╚╦åTĪó╣▄└Ē╚╦åT╗“ł╠ąą╚╦åT─▄ē“Å─ČÓĮŪČ╚ī”ą┼Žó▀Mąą┐ņ╦┘Īóę╗ų┬ĪóĮ╗╗źĄž┤µ╚ĪŻ¼Å─Č°½@Ą├ī”öĄō■Ą─Ė³╔Ņ╚ļ┴╦ĮŌĄ─ę╗ŅÉ▄ø╝■╝╝ągĪŻOLAPĄ──┐ś╦╩ŪØMūŃøQ▓▀ų¦│ų╗“š▀ØMūŃį┌ČÓŠSŁhŠ│Ž┬╠žČ©Ą─▓ķįā║═ł¾▒ĒąĶŪ¾Ż¼╦³Ą─╝╝ąg║╦ą─╩ŪĪ░ŠSĪ▒▀@éĆĖ┼─ŅĪŻ
Ī░ŠSĪ▒╩Ū╚╦éāė^▓ņ┐═ė^╩└ĮńĄ─ĮŪČ╚Ż¼╩Ūę╗ĘNĖ▀īė┤╬Ą─ŅÉą═äØĘųĪŻĪ░ŠSĪ▒ę╗░Ń░³║¼ų°īė┤╬ĻPŽĄŻ¼▀@ĘNīė┤╬ĻPŽĄėąĢrĢ■ŽÓ«öÅ═ļsĪŻ═©▀^░čę╗éĆīŹ¾wĄ─ČÓĒŚųžę¬Ą─ī┘ąįČ©┴x×ķČÓéĆŠS(dimension)Ż¼╩╣ė├æ¶─▄ī”▓╗═¼ŠS╔ŽĄ─öĄō■▀Mąą▒╚▌^ĪŻę“┤╦OLAPę▓┐╔ęįšf╩ŪČÓŠSöĄō■Ęų╬÷╣żŠ▀Ą─╝»║ŽĪŻ
OLAPĘų╬÷ųąę¬└ĒĮŌūā┴┐ĪóŠSĪóŠSīė┤╬ĪóŠSĄ─╚ĪųĄĪóŠSĄ─ĘųŅÉĄ╚ų„ꬹgšZĪŻūā┴┐ųĖÅ─¼FīŹŽĄĮyųą│ķŽ¾│÷üĒė├ė┌├Ķ╩÷öĄō■Ą─īŹļH║¼┴xŻ║ŠS╩Ū┼c─│ę╗╩┬╝■ŽÓĻPĄ─ę“╦žį┌ĻPŽĄ─Żą═Ą─│ķŽ¾ĪŻ╚ń┐═æ¶┤“ļŖįÆŻ¼║¼┐═æ¶ĪóĢrķgĪóĄž³cĪóśIäš╠ß╣®╔╠ĪóśIäšŅÉą═Ą╚▀@ą®┼c┐═æ¶┤“ļŖįÆŽÓĻP┬ōŠo├▄Ą─ā╚╚▌Ż╗ŠSĄ─īė┤╬ąį╩Ū╚╦éāė^▓ņöĄō■╝Üų┬│╠Č╚▓╗═¼įņ│╔Ą─Ż¼╝┤öĄō■Ą─ŠC║Ž│╠Č╚▓╗═¼ī¦ų┬▓╗═¼Ą─ŠSīė┤╬Ż¼╚ńĢrķgŠSųąęį─ĻĪóęįį┬Īóęį╚š×ķå╬╬╗╝┤ą╬│╔┴╦▓╗═¼Ą─ŠSīė┤╬ĪŻ╦³Ą──┐Ą─ØMūŃśIäšŅÉė├æ¶╦╝┐╝å¢Ņ}Ģrųīė╔Ņ╚ļĄ─ąĶŪ¾Ż║ŠSĄ─╚ĪųĄŻ¼ę▓ĘQ×ķŠSĄ─│╔åTŻ╗ŠSĄ─ĘųŅÉ╩Ūī”ŠS╚ĪųĄĄ─äØĘųĪŻ─┐Ą─╩Ū×ķ┴╦į┌▓╗═¼Ą─ŅÉäeķg▀Mąą▒╚▌^ĪŻ╚ńõN╩█┐╔Ęų×ķĢ│õNĪó▓╗Ģ│õNĪóŲĮõNŻ¼ęŲäėśIäšŅÉą═┐╔ęįĘų×ķ═©įÆĪóČ╠ą┼Īóė╬æ“Ą╚ĪŻę╗éĆīŹļHĄ─ŽĄĮyųąŻ¼ŠSĘųŅÉ║═ŠSīė┤╬│Ż│Ż═¼Ģr┤µį┌ĪŻ╩┬īŹ╩ŪųĖ▓╗═¼ŠSČ╚į┌─│ę╗╚ĪųĄŽ┬Ą─Į╗▓µ³cŻ¼╦³╩Ūī”╩┬╝■Ą─Č╚┴┐ĪŻ└²╚ńŻ¼Ī┴Ī┴╣½╦ŠļŖęĢÖC4į┬Ę▌õN╩█800┼_ĪŻŲõųą800┼_╩Ū╩┬īŹĪŻę╗░ŃüĒšföĄ┴┐║═ĮŅ~│Żū„×ķ╩┬īŹĪŻ
2.3 ┬ōÖCĘų╬÷╠Ä└Ē(OLAP)Ą─╗∙▒ŠČÓŠSĘų╬÷▓┘ū„
OLAPĄ─ę╗éĆųžę¬╠ž³c╩Ūų„ę¬═©▀^ČÓŠSĄ─Į╗╗ź╩ĮĘĮ╩Įī”öĄō■▀MąąĘų╬÷Ż¼▀@┼cöĄō■é}ÄņĄ─ČÓŠSöĄō■ĮM┐Śš²║├ą╬│╔ŽÓ╗źĮY║ŽĪóŽÓ╗źča│õĄ─ĻPŽĄĪŻ▀@ą®╗∙▒ŠČÓŠSĘų╬÷▓┘ū„░³└©ŪąŲ¼(ŪąēK)ĪóŃ@╚ĪĪóą²▐DĄ╚Ż¼▒Ńė┌ė├æ¶Å─▓╗═¼ŠSČ╚▓ķįā║═Ęų╬÷ėąĻPöĄō■ĪŻ
(1)ŪąŲ¼║═ŪąēK
═©▀^ŪąŲ¼ĪóŪąēK╣”─▄Ż¼ė├æ¶┐╔ęįī”öĄō■▀Mąą▀^×VŻ¼īŻūóė┌─│ę╗ĘĮ├µĄ─å¢Ņ}Ż¼└²╚ńŻ¼ė├æ¶═©▀^═Žū¦Ą─ĘĮ╩Į║▄╚▌ęūĄ─Ą├ĄĮųT╚ńĪ░Ī┴Ī┴Ąžģ^2008─ĻĄ─õN╩█ŪķørĪ▒▀@śėĄ─öĄō■ĪŻ
(2)Ń@╚Ī
Ń@╚Ī░³║¼Ž“Ž┬Ń@╚Ī║═Ž“╔ŽŃ@╚Ī▓┘ū„Ż¼Ń@╚ĪĄ─╔ŅČ╚┼cŠS╦∙äØĘųĄ─īė┤╬ŽÓī”æ¬ĪŻŽ“Ž┬Ń@╚Ī╩Ū═©▀^ī”─│ę╗ąąģR┐éöĄō■▀Mąą╝ÜĘųüĒĘų╬÷öĄō■ĪŻ└²╚ńŻ¼ė├æ¶Ęų╬÷Ī░Ė„Ąžģ^Īó│Ū╩ąĄ─õN╩█ŪķørĪ▒ĢrŻ¼┐╔ęįī”─│ę╗éĆ│Ū╩ąĄ─õN╩█Ņ~╝ÜĘų×ķĖ„éĆ─ĻČ╚Ą─õN╩█Ņ~Ż¼ī”─│ę╗─ĻČ╚Ą─õN╩█Ņ~Ż¼┐╔ęį└^└m╝ÜĘų×ķĖ„éĆ╝ŠČ╚Ą─õN╩█Ņ~ĪŻ═©▀^Ń@╚ĪĄ─╣”─▄Ż¼╩╣ė├æ¶ī”öĄō■─▄Ė³╔Ņ╚ļ┴╦ĮŌŻ¼Ė³╚▌ęū░l¼Få¢Ņ}Ż¼ū÷│÷š²┤_Ą─øQ▓▀ĪŻ
Ž“╔ŽŃ@╚Ī╩ŪųĖūįäė╔·│╔ģR┐éąąĄ─Ęų╬÷ĘĮĘ©ĪŻ═©▀^Ž“ī¦Ą─ĘĮ╩ĮŻ¼ė├æ¶┐╔ęįČ©┴xĘų╬÷ę“╦žĄ─ģR┐éąąŻ¼└²╚ńī”ė┌Ė„Ąžģ^Ė„─ĻČ╚Ą─õN╩█ŪķørŻ¼┐╔ęį╔·│╔Ąžģ^┼c─ĻČ╚Ą─║ŽėŗąąŻ¼ę▓┐╔ęį╔·│╔Ąžģ^╗“š▀─ĻČ╚Ą─║ŽėŗąąĪŻ
(3)ą²▐D
ą²▐DŻ¼ę▓ĘQöĄō■▐D▌SŻ¼Š═╩ŪĖ─ūāŠSČ╚Ą─╬╗ų├ĻPŽĄŻ¼╚ńīóąą┼c┴ą╗źōQŻ¼╗“š▀īó─│ę╗éĆąąŠSęŲäėĄĮ┴ąŠSųąĪŻ×ķ┴╦ĘĮ▒Ńė├æ¶Ė³ų▒ė^Ą─▓ķ┐┤Ęų╬÷öĄō■Ż¼æ¬įōų¦│ųöĄō■Ą─ą²▐D╣”─▄Ż¼┐╔Å─▓╗═¼Ą─ęĢĮŪüĒ▓ķ┐┤öĄō■ĪŻī”ė┌ę╗ą®öĄō■Ż¼═©▀^ą²▐D╣”─▄Ż¼┐┤ŲüĒ┐╔ęįĖ³╝ėų▒ė^Ż¼└²╚ńĢrķgą“┴ąĘų╬÷ųąŻ¼Ė„Ąžģ^Ė„─ĻČ╚Ą─į÷ķL┴┐ŪķørŻ¼░č─ĻĘ▌ū„×ķą²▐DŠSČ╚Ż¼ät═¼ę╗Ąžģ^▓╗═¼─ĻČ╚Ą─öĄō■ęį╝░į÷ķL┴┐īóį┌ę╗ąą’@╩ŠŻ¼┐┤ŲüĒĖ³╚▌ęū└ĒĮŌĪŻ
OLAPĘų╬÷ųąĄ─ČÓŠSĘų╬÷│õĘų¾w¼F×ķė├æ¶ī”─│ę╗éĆ╩┬īŹęįČÓĘNĮŪČ╚š╣ķ_Ęų╬÷ĪŻ▒╚╚ńĪ┴Ī┴╣½╦ŠļŖęĢÖC4į┬Ę▌õN╩█800┼_Ż¼╚¶ęįžōž¤Ī┴Ī┴Ąžģ^Ą─õN╩█Įø└Ē▀@ę╗śIäšŅÉĮŪ╔½üĒĘų╬÷Ż¼╦¹┐╔ęįÅ─ĢrķgŠS(╚ń├┐╚š)ĪóĄžģ^ŠS(Ī┴Ī┴Ąžģ^Ą─Ė„éĆģ^┐hĪóĖ„éĆģ^┐hĄ─Ė„éĆõN╩█³c)ĪóŲĘ┼ŲŠS(▓╗═¼ŲĘ┼ŲĪóęÄĖ±Ą─ļŖęĢÖC)ĪóõN╩█╚╦åTŠS(▓╗═¼³c╔ŽĄ─õN╩█åT)Ą╚Ą╚ŠSČ╚ęįŪąŲ¼ĘĮ╩ĮĘųäeüĒĘų╬÷Ż¼ę▓┐╔ęįŠC║ŽŲüĒū„ŪąēK▒╚▌^Ż¼ę▓┐╔ęį═©Ń@╚ĪĘĮ╩Į▀Mąą╔Ņ╚ļĘų╬÷ĪŻ
─┐Ū░Ż¼│ŻęŖĄ─OLAPų„ę¬ėą╗∙ė┌ČÓŠSöĄō■ÄņĄ─MOLAP╝░╗∙ė┌ĻPŽĄöĄō■ÄņĄ─ROLAPĪŻį┌öĄō■é}Äņæ¬ė├ųąŻ¼┬ōÖCĘų╬÷╠Ä└Ēæ¬ė├ę╗░Ń╩ŪöĄō■é}Äņæ¬ė├Ą─Ū░Č╦╣żŠ▀Ż¼═¼ĢrŻ¼┬ōÖCĘų╬÷╠Ä└Ē╣żŠ▀▀Ć┐╔ęį═¼öĄō■═┌Š“╣żŠ▀ĪóĮyėŗĘų╬÷╣żŠ▀┼õ║Ž╩╣ė├Ż¼į÷ÅŖøQ▓▀Ęų╬÷╣”─▄ĪŻ
3 öĄō■═┌Š“(DM)
3.1 öĄō■═┌Š“Č©┴x
▀M╚ļČ■╩«ę╗╩└╝oęįüĒŻ¼ļSų°┐ŲīW╝╝ąg’w╦┘Ą─░lš╣Ż¼ĮøØ·║═╔ńĢ■Č╝╚ĪĄ├┴╦śO┤¾Ą─▀M▓ĮŻ¼┼c┤╦═¼ĢrŻ¼į┌Ė„éĆŅIė“«a╔·┴╦┤¾┴┐Ą─öĄō■Ż¼╚ń╚╦ŅÉī”╠½┐šĄ─╠Į╦„Ż¼Ńyąą├┐╠ņĄ─Š▐Ņ~Į╗ęūöĄŠ“ĪŻ’@╚╗į┌▀@ą®öĄō■ųąžSĖ╗Ą─ą┼ŽóŻ¼╚ń║╬╠Ä└Ē▀@ą®öĄō■Ą├ĄĮėąęµĄ─ą┼ŽóŻ¼╚╦éā▀Mąą┴╦ėąęµĄ─╠Į╦„ĪŻėŗ╦ŃÖC╝╝ągĄ─čĖ╦┘░lš╣╩╣Ą├╠Ä└ĒöĄō■│╔×ķ┐╔─▄Ż¼▀@Š══Ųäė┴╦öĄō■Äņ╝╝ągĄ─śO┤¾░lš╣Ż¼Ą½╩Ū├µī”▓╗öÓį÷╝ė╚ń│▒╦«░ŃĄ─öĄō■Ż¼╚╦éā▓╗į┘ØMūŃė┌öĄō■ÄņĄ─▓ķįā╣”─▄Ż¼╠ß│÷┴╦╔Ņīė┤╬å¢Ņ}Ż║─▄▓╗─▄Å─öĄō■ųą╠ß╚Īą┼Žó╗“š▀ų¬ūR×ķøQ▓▀Ę■äšĪŻŠ═öĄō■Äņ╝╝ągČ°čįęčĮø’@Ą├¤o─▄×ķ┴”┴╦Ż¼═¼śėŻ¼é„ĮyĄ─Įyėŗ╝╝ągę▓├µ┼R┴╦śO┤¾Ą─╠¶æĪŻ▀@Š═╝▒ąĶėąą┬Ą─ĘĮĘ©üĒ╠Ä└Ē▀@ą®║Ż┴┐░ŃĄ─öĄō■ĪŻė┌╩ŪŻ¼╚╦éāĮY║ŽĮyėŗīWĪóöĄō■ÄņĪóÖCŲ„īW┴ĢĄ╚╝╝ągŻ¼╠ß│÷öĄō■═┌Š“üĒĮŌøQ▀@ę╗ļyŅ}ĪŻ
öĄō■═┌Š“Ą─Üv╩Ęļm╚╗▌^Č╠Ż¼Ą½Å─20╩└╝o90─Ļ┤·ęįüĒŻ¼╦³Ą─░lš╣╦┘Č╚║▄┐ņŻ¼╝ėų«╦³╩ŪČÓīW┐ŲŠC║ŽĄ─«a╬’Ż¼─┐Ū░▀Ćø]ėąę╗éĆ═Ļš¹Ą─Č©┴xŻ¼╚╦éā╠ß│÷┴╦ČÓĘNöĄō■═┌Š“Ą─Č©┴xŻ¼└²╚ńŻ║SAS蹊┐╦∙(1997)Ż║Ī░į┌┤¾┴┐ŽÓĻPöĄō■╗∙ĄAų«╔Ž▀MąąöĄō■╠Į╦„║═Į©┴óŽÓĻP─Żą═Ą─Ž╚▀MĘĮĘ©Ī▒ĪŻHand et al(2000)Ż║Ī░öĄō■═┌Š“Š═╩Ūį┌┤¾ą═öĄō■ÄņųąīżšęėąęŌ┴xĪóėąārųĄą┼ŽóĄ─▀^│╠Ī▒┤_ŪąĄžšfŻ¼öĄō■═┌Š“(Data Mining)Ż¼ėųĘQöĄō■ÄņųąĄ─ų¬ūR░l¼F(Knowledge Discovery in DatabaseŻ¼KDD)Ż¼╩ŪųĖÅ─┤¾ą═öĄō■Äņ╗“öĄō■é}Äņųą╠ß╚Īļ[║¼Ą─Īó╬┤ų¬Ą─ĪóĘŪŲĮĘ▓Ą─╝░ėąØōį┌æ¬ė├ārųĄĄ─ą┼Žó╗“─Ż╩ĮŻ¼╦³╩ŪöĄō■Äņ蹊┐ųąĄ─ę╗éĆ║▄ėąæ¬ė├ārųĄĄ─ą┬ŅIė“Ż¼╚┌║Ž┴╦öĄō■ÄņĪó╚╦╣żųŪ─▄ĪóÖCŲ„īW┴ĢĪóĮyėŗīWĄ╚ČÓéĆŅIė“Ą─└Ēšō║═╝╝ągĪŻ
3.2 öĄō■═┌Š“Ą─ų„ę¬╣”─▄
öĄō■═┌Š“ŠC║Ž┴╦Ė„éĆīW┐Ų╝╝ągŻ¼ėą║▄ČÓĄ─╣”─▄Ż¼«öŪ░Ą─ų„ę¬╣”─▄╚ńŽ┬Ż║
1ĪóöĄō■┐éĮYŻ║└^│ąė┌öĄō■Ęų╬÷ųąĄ─ĮyėŗĘų╬÷ĪŻöĄō■┐éĮY─┐Ą─╩Ūī”öĄō■▀MąąØŌ┐sŻ¼Įo│÷╦³Ą─Šo£É├Ķ╩÷ĪŻé„ĮyĮyėŗĘĮĘ©╚ńŪ¾║═ųĄĪóŲĮŠ∙ųĄĪóĘĮ▓ŅųĄĄ╚Č╝╩Ūėąą¦ĘĮĘ©ĪŻ┴Ē═Ō▀Ć┐╔ęįė├ų▒ĘĮłDĪó’×ĀŅłDĄ╚łDą╬ĘĮ╩Į▒Ē╩Š▀@ą®ųĄĪŻÅV┴x╔ŽųvŻ¼ČÓŠSĘų╬÷ę▓┐╔ęįÜw╚ļ▀@ę╗ŅÉĪŻ
2ĪóĘųŅÉŻ║─┐Ą─╩Ūśŗįņę╗éĆĘųŅÉ║»öĄ╗“ĘųŅÉ─Żą═(ę▓│Ż│ŻĘQū„ĘųŅÉŲ„)Ż¼įō─Żą═─▄░čöĄō■ÄņųąĄ─öĄō■ĒŚė│╔õĄĮĮoČ©ŅÉäeųąĄ──│ę╗éĆĪŻę¬śŗįņĘųŅÉŲ„Ż¼ąĶę¬ėąę╗éĆė¢ŠÜśė▒ŠöĄō■╝»ū„×ķ▌ö╚ļĪŻė¢ŠÜ╝»ė╔ę╗ĮMöĄō■Äņėøõø╗“į¬ĮMśŗ│╔Ż¼├┐éĆį¬ĮM╩Ūę╗éĆė╔ėąĻPūųČ╬(ėųĘQī┘ąį╗“╠žš„)ųĄĮM│╔Ą─╠žš„Ž“┴┐Ż¼┤╦═ŌŻ¼ė¢ŠÜśė▒Š▀Ćėąę╗éĆŅÉäeś╦ėøĪŻę╗éĆŠ▀¾wśė▒ŠĄ─ą╬╩Į┐╔▒Ē╩Š×ķŻ║(v1Ż¼v2Ż¼...Ż¼vnŻ╗c)Ż¼Ųõųąvi▒Ē╩ŠūųČ╬ųĄŻ¼c▒Ē╩ŠŅÉäeĪŻ
└²╚ńŻ║Ńyąą▓┐ķTĖ∙ō■ęįŪ░Ą─öĄō■īó┐═æ¶Ęų│╔┴╦▓╗═¼Ą─ŅÉäeŻ¼¼Fį┌Š═┐╔ęįĖ∙ō■▀@ą®üĒģ^Ęųą┬╔Ļšł┘J┐ŅĄ─┐═æ¶Ż¼ęį▓╔╚ĪŽÓæ¬Ą─┘J┐ŅĘĮ░ĖĪŻ
3ĪóŠ█ŅÉŻ║╩Ū░čš¹éĆöĄō■ÄņĘų│╔▓╗═¼Ą─╚║ĮMĪŻ╦³Ą──┐Ą─╩Ū╩╣╚║┼c╚║ų«ķg▓Ņäe║▄├„’@Ż¼Č°═¼ę╗éĆ╚║ų«ķgĄ─öĄō■▒M┴┐ŽÓ╦ŲĪŻ▀@ĘNĘĮĘ©═©│Żė├ė┌┐═æ¶╝ÜĘųĪŻį┌ķ_╩╝╝ÜĘųų«Ū░▓╗ų¬Ą└ę¬░čė├æ¶Ęų│╔ÄūŅÉŻ¼ę“┤╦═©▀^Š█ŅÉĘų╬÷┐╔ęįšę│÷┐═æ¶╠žąįŽÓ╦ŲĄ─╚║¾wŻ¼╚ń┐═涎¹┘M╠žąįŽÓ╦Ų╗“─Ļ²g╠žąįŽÓ╦ŲĄ╚ĪŻį┌┤╦╗∙ĄA╔Ž┐╔ęįųŲČ©ę╗ą®ßśī”▓╗═¼┐═æ¶╚║¾wĄ─ĀIõNĘĮ░ĖĪŻ
└²╚ńŻ║īó╔Ļšł╚╦Ęų×ķĖ▀Č╚’LļU╔Ļšłš▀Ż¼ųąČ╚’LļU╔Ļšłš▀Ż¼Ą═Č╚’LļU╔Ļšłš▀ĪŻ
4ĪóĻP┬ōĘų╬÷Ż║╩ŪīżšęöĄō■ÄņųąųĄĄ─ŽÓĻPąįĪŻā╔ĘN│Żė├Ą─╝╝ąg╩ŪĻP┬ōęÄät║═ą“┴ą─Ż╩ĮĪŻĻP┬ōęÄät╩Ūīżšęį┌═¼ę╗éĆ╩┬╝■ųą│÷¼FĄ─▓╗═¼ĒŚĄ─ŽÓĻPąįŻ╗ą“┴ą─Ż╩Į┼c┤╦ŅÉ╦ŲŻ¼īżšęĄ─╩Ū╩┬╝■ų«ķgĢrķg╔ŽĄ─ŽÓĻPąįŻ¼└²╚ńŻ║Į±╠ņŃyąą└¹┬╩Ą─š{š¹Ż¼├„╠ņ╣╔╩ąĄ─ūā╗»ĪŻ
5ĪóŅA£yŻ║░č╬šĘų╬÷ī”Ž¾░lš╣Ą─ęÄ┬╔Ż¼ī”╬┤üĒĄ─┌ģä▌ū÷│÷ŅAęŖĪŻ└²╚ńŻ║ī”╬┤üĒĮøØ·░lš╣Ą─┼ąöÓĪŻ
6ĪóŲ½▓ŅĄ─Öz£yŻ║ī”Ęų╬÷ī”Ž¾Ą─╔┘öĄĄ─ĪóśOČ╦Ą─╠ž└²Ą─├Ķ╩÷Ż¼Įę╩Šā╚į┌Ą─įŁę“ĪŻ└²╚ńŻ║į┌ŃyąąĄ─100╚f╣PĮ╗ęūųąėą500└²Ą─Ų█įpąą×ķŻ¼Ńyąą×ķ┴╦ĘĆĮĪĮøĀIŻ¼Š═ę¬░l¼F▀@500└²Ą─ā╚į┌ę“╦žŻ¼£pąĪęį║¾ĮøĀIĄ─’LļUĪŻ
ęį╔ŽöĄō■═┌Š“Ą─Ė„ĒŚ╣”─▄▓╗╩Ū¬Ü┴ó┤µį┌Ą─Ż¼╦³éāį┌öĄō■═┌Š“ųą╗źŽÓ┬ōŽĄŻ¼░lō]ū„ė├ĪŻ
3.3 öĄō■═┌Š“Ą─ĘĮĘ©
ū„×ķę╗ķT╠Ä└ĒöĄō■Ą─ą┬┼d╝╝ągŻ¼öĄō■═┌Š“ėąįSČÓĄ─ą┬╠žš„ĪŻ╩ūŽ╚Ż¼öĄō■═┌Š“├µī”Ą─╩Ū║Ż┴┐Ą─öĄō■Ż¼▀@ę▓╩ŪöĄō■═┌Š“«a╔·Ą─įŁę“ĪŻŲõ┤╬Ż¼öĄō■┐╔─▄╩Ū▓╗═Ļ╚½Ą─Īóėąįļ┬ĢĄ─ĪóļSÖCĄ─Ż¼ėąÅ═ļsĄ─öĄō■ĮYśŗŻ¼ŠSöĄ┤¾ĪŻūŅ║¾Ż¼öĄō■═┌Š“╩ŪįSČÓīW┐ŲĄ─Į╗▓µŻ¼▀\ė├┴╦ĮyėŗīWŻ¼ėŗ╦ŃÖCŻ¼öĄīWĄ╚īW┐ŲĄ─╝╝ągĪŻęįŽ┬╩Ū│ŻęŖ║═æ¬ė├ūŅÅVĘ║Ą─╦ŃĘ©║═─Żą═Ż║
é„ĮyĮyėŗĘĮĘ©Ż║ó┘│ķśė╝╝ągŻ║╬ęéā├µī”Ą─╩Ū┤¾┴┐Ą─öĄō■Ż¼ī”╦∙ėąĄ─öĄō■▀MąąĘų╬÷╩Ū▓╗┐╔─▄Ą─ę▓╩Ūø]ėą▒žę¬Ą─Ż¼Š═ę¬į┌└ĒšōĄ─ųĖī¦Ž┬▀Mąą║Ž└ĒĄ─│ķśėĪŻó┌ČÓį¬ĮyėŗĘų╬÷Ż║ę“ūėĘų╬÷Ż¼Š█ŅÉĘų╬÷Ą╚ĪŻó█ĮyėŗŅA£yĘĮĘ©Ż¼╚ń╗žÜwĘų╬÷Ż¼Ģrķgą“┴ąĘų╬÷Ą╚ĪŻ
┐╔ęĢ╗»╝╝ągŻ║ė├łD▒ĒĄ╚ĘĮ╩Į░čöĄō■╠žš„ė├ų▒ė^Ąž▒Ē╩÷│÷üĒŻ¼╚ńų▒ĘĮłDĄ╚Ż¼▀@Ųõųą▀\ė├Ą─įSČÓ├Ķ╩÷ĮyėŗĄ─ĘĮĘ©ĪŻ┐╔ęĢ╗»╝╝ąg├µī”Ą─ę╗éĆļyŅ}╩ŪĖ▀ŠSöĄō■Ą─┐╔ęĢ╗»ĪŻ
øQ▓▀śõŻ║└¹ė├ę╗ŽĄ┴ąęÄätäØĘųŻ¼Į©┴óśõĀŅłDŻ¼┐╔ė├ė┌ĘųŅÉ║═ŅA£yĪŻ│Żė├Ą─╦ŃĘ©ėąCARTĪóCHAIDĪóID3ĪóC4.5ĪóC5.0Ą╚ĪŻ
╔±ĮøŠWĮjŻ║─ŻöM╚╦Ą─╔±Įøį¬╣”─▄Ż¼Įø▀^▌ö╚ļīėŻ¼ļ[▓žīėŻ¼▌ö│÷īėĄ╚Ż¼ī”öĄō■▀Mąąš{š¹Ż¼ėŗ╦ŃŻ¼ūŅ║¾Ą├ĄĮĮY╣¹Ż¼ė├ė┌ĘųŅÉ║═╗žÜwĪŻ
▀zé„╦ŃĘ©Ż║╗∙ė┌ūį╚╗▀M╗»└ĒšōŻ¼─ŻöM╗∙ę“┬ō║ŽĪó═╗ūāĪó▀xō±Ą╚▀^│╠Ą─ę╗ĘNā×╗»╝╝ągĪŻ
ĻP┬ōęÄät═┌Š“╦ŃĘ©Ż║ĻP┬ōęÄät╩Ū├Ķ╩÷öĄō■ų«ķg┤µį┌ĻPŽĄĄ─ęÄätŻ¼ą╬╩Į×ķĪ░A1Ī─A2Ī─...AnĪ·B1Ī─B2Ī─...BnĪ▒ĪŻę╗░ŃĘų×ķā╔éĆ▓Į¾EŻ║ó┘Ū¾│÷┤¾öĄō■ĒŚ╝»ĪŻó┌ė├┤¾öĄō■ĒŚ╝»«a╔·ĻP┬ōęÄätĪŻ
│²┴╦╔Ž╩÷Ą─│Żė├ĘĮĘ©═ŌŻ¼▀Ćėą┤ų╝»ĘĮĘ©Ż¼─Ż║²╝»║ŽĘĮĘ©Ż¼Bayesian Belief NetordsŻ¼ūŅÓÅĮ³╦ŃĘ©(k-nearest neighbors method(KNN))Ą╚ĪŻ
3.4 öĄō■═┌Š“Ą─īŹ╩®┴„│╠
Ū░├µ╬ęéāėæšō┴╦öĄō■═┌Š“Ą─Č©┴xŻ¼╣”─▄║═ĘĮĘ©Ż¼¼Fį┌ĻPµIĄ─å¢Ņ}╩Ū╚ń║╬īŹ╩®Ż¼Ųõę╗░ŃĄ─öĄō■═┌Š“┴„│╠╚ńŽ┬Ż║
å¢Ņ}└ĒĮŌ║═╠ß│÷Ī·öĄō■£╩éõĪ·öĄō■š¹└ĒĪ·Į©┴ó─Żą═Ī·įuār║═ĮŌßī
å¢Ņ}└ĒĮŌ║═╠ß│÷Ż║į┌ķ_╩╝öĄō■═┌Š“ų«Ū░ūŅ╗∙ĄAĄ─Š═╩Ū└ĒĮŌöĄō■║═īŹļHĄ─śIäšå¢Ņ}Ż¼į┌▀@éĆ╗∙ĄAų«╔Ž╠ß│÷å¢Ņ}Ż¼ī”─┐ś╦ėą├„┤_Ą─Č©┴xĪŻ
öĄō■£╩éõŻ║½@╚ĪįŁ╩╝Ą─öĄō■Ż¼▓óÅ─ųą│ķ╚Īę╗Č©öĄ┴┐Ą─ūė╝»Ż¼Į©┴óöĄō■═┌Š“ÄņŻ¼Ųõųąę╗éĆå¢Ņ}╩Ū╚ń╣¹Ų¾śIįŁüĒĄ─öĄō■é}ÄņØMūŃöĄō■═┌Š“Ą─ę¬Ū¾Ż¼Š═┐╔ęįīóöĄō■é}Äņū„×ķöĄō■═┌Š“ÄņĪŻ
öĄō■š¹└ĒŻ║ė╔ė┌öĄō■┐╔─▄╩Ū▓╗═Ļ╚½Ą─Īóėąįļ┬ĢĄ─ĪóļSÖCĄ─Ż¼ėąÅ═ļsĄ─öĄŠ“ĮYśŗŻ¼Š═ę¬ī”öĄō■▀Mąą│§▓ĮĄ─š¹└ĒŻ¼ŪÕŽ┤▓╗═Ļ╚½Ą─öĄō■Ż¼ū÷│§▓ĮĄ─├Ķ╩÷Ęų╬÷Ż¼▀xō±┼cöĄō■═┌Š“ėąĻPĄ─ūā┴┐Ż¼╗“š▀▐Dūāūā┴┐ĪŻ
Į©┴ó─Żą═Ż║Ė∙ō■öĄō■═┌Š“Ą──┐ś╦║═öĄō■Ą─╠žš„Ż¼▀xō±║Ž▀mĄ──Żą═ĪŻ
įuār║═ĮŌßīŻ║ī”öĄō■═┌Š“Ą─ĮY╣¹▀MąąįuārŻ¼▀xō±ūŅāץ──Żą═Ż¼ū„│÷įuārŻ¼▀\ė├ė┌īŹļHå¢Ņ}Ż¼▓óŪęę¬║═īŻśIų¬ūRĮY║Žī”ĮY╣¹▀MąąĮŌßīĪŻ
ęį╔ŽĄ─┴„│╠▓╗╩Ūę╗┤╬═Ļ│╔Ą─Ż¼┐╔─▄Ųõųą─│ą®▓Į¾E╗“š▀╚½▓┐ę¬Ę┤Å═▀MąąĪŻ
3.5 öĄō■═┌Š“Ą─æ¬ė├¼FĀŅ
öĄō■═┌Š“╦∙ę¬╠Ä└ĒĄ─å¢Ņ}Ż¼Š═╩Ūį┌²ŗ┤¾Ą─öĄō■Äņųąšę│÷ėąārųĄĄ─ļ[▓ž╩┬╝■Ż¼▓óŪę╝ėęįĘų╬÷Ż¼½@╚ĪėąęŌ┴xĄ─ą┼ŽóŻ¼Üw╝{│÷ėąė├Ą─ĮYśŗŻ¼ū„×ķŲ¾śI▀MąąøQ▓▀Ą─ę└ō■ĪŻŲõæ¬ė├ĘŪ│ŻÅVĘ║Ż¼ų╗ę¬įō«aśIėąĘų╬÷ārųĄ┼cąĶŪ¾Ą─öĄō■ÄņŻ¼Įį┐╔└¹ė├öĄō■═┌Š“(DM)╝╝ąg▀Mąąėą─┐Ą─Ą─░lŠ“Ęų╬÷ĪŻ│ŻęŖĄ─æ¬ė├░Ė└²ČÓ░l╔·į┌┴Ń╩█śIĪóžöäšĮ╚┌▒ŻļUĪóųŲįņśIĪó═©ėŹ╝░ßt»¤Ę■äšąąśIŻ║
1Īó┴Ń╩█╔╠Å─ŅÖ┐═┘Å┘I╔╠ŲĘųą░l¼Fę╗Č©Ą─ĻPŽĄŻ¼╠ß╣®┤“š█┘Å╬’╚»Ą╚Ż¼╠ßĖ▀õN╩█Ņ~Ż╗
2Īó▒ŻļU╣½╦Š═©▀^öĄō■═┌Š“Į©┴óŅA£y─Żą═Ż¼▒µäe│÷┐╔─▄Ą─Ų█įpąą×ķŻ¼▒▄├ŌĄ└Ą┬’LļUŻ¼£p╔┘│╔▒ŠŻ¼╠ßĖ▀└¹ØÖŻ╗
3Īóį┌ųŲįņśIųąŻ¼░ļī¦¾wĄ─╔·«a║═£yįćųąČ╝«a╔·┤¾┴┐Ą─öĄō■Ż¼Š═▒žĒÜī”▀@ą®öĄō■▀MąąĘų╬÷Ż¼šę│÷┤µį┌Ą─å¢Ņ}Ż¼╠ßĖ▀┘|┴┐Ż╗
4ĪóļŖūė╔╠䚥─ū„ė├įĮüĒįĮ┤¾Ż¼┐╔ęįė├öĄō■═┌Š“ī”ŠWšŠ▀MąąĘų╬÷Ż¼ūRäeė├æ¶Ą─ąą×ķ─Ż╩ĮŻ¼▒Ż┴¶┐═æ¶Ż¼╠ß╣®éĆąį╗»Ę■䚯¼ā×╗»ŠWšŠįOėŗĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║╔╠śIųŪ─▄Ż©BIŻ®╝╝ągŻ©BIŽĄĮyöĄō■é}ÄņĪóOLAP║═öĄō■═┌Š“╝╝ągŻ®






















