



«öŪ░╬’└ĒCPUš²ū±čŁ─”Ā¢Č©┬╔į┌ĘĆČ©Ą─Ė▀╦┘░lš╣Ż¼╚╗Č°╚╦ŅÉī”ėŗ╦Ń─▄┴”Ą─ę¬Ū¾Ė³Ė▀Ż¼ę╗ĘĮ├µæ¬ė├ī”ėŗ╦Ń─▄┴”ę¬Ū¾│¼▀^─”Ā¢Č©┬╔Ą─╦┘Č╚Ż¼┴Ē═Ōę╗ĘĮ├µę¬Ū¾╠ßĖ▀ėŗ╦Ń─▄┴”Ą─╩╣ė├ą¦┬╩Ż¼▀@Č╝ļx▓╗ķ_▄ø╝■Ą─ģfų·ĪŻ╠ōöM╗»║═Ęų▓╝╩ĮČ╝╩Ū¼Fį┌┴„ąąĄ─╝▄śŗŻ¼╦¹éā┤·▒Ēų°ā╔éĆ▓╗═¼Ą─░lš╣ĘĮŽ“Ż║╠ōöM╗»——ę╗┼_ÖCŲ„Ęų│╔ČÓ┼_ÖCŲ„ė├Ż╗Ęų▓╝╩Į——ČÓ┼_ÖCŲ„║Ž│╔ę╗┼_ÖCŲ„ė├ĪŻš²┐╔ų^“╠ņŽ┬┤¾ä▌Ż¼ĘųŠ├▒ž║ŽŻ¼║ŽŠ├▒žĘų”ĪŻ
ę╗ĪóĘų▓╝╩Į╝▄śŗ░lš╣║═¼FĀŅ
1.Å─SMPĄĮMPP
Å─ŽĄĮy╝▄śŗüĒ┐┤Ż¼─┐Ū░Ą─╔╠ė├Ę■äšŲ„ų„ę¬Ęų×ķ╚²ŅÉŻ¼ī”ĘQČÓ╠Ä└ĒŲ„ĮYśŗSMPŻ¼ĘŪę╗ų┬┤µā”įLå¢ĮYśŗNUMAęį╝░║Ż┴┐▓óąą╠Ä└ĒĮYśŗMPPĪŻ
SMPŻ©Symmetric Multi-ProcessorŻ®
╦∙ų^ī”ĘQČÓ╠Ä└ĒŲ„ĮYśŗŻ¼╩ŪųĖĘ■äšŲ„ųąČÓéĆCPUī”ĘQ╣żū„Ż¼¤oų„┤╬╗“Å─ī┘ĻPŽĄĪŻĖ„CPU╣▓ŽĒŽÓ═¼Ą─╬’└Ēā╚┤µŻ¼├┐éĆCPUįLå¢ā╚┤µųąĄ─╚╬║╬ĄžųĘ╦∙ąĶĢrķg╩ŪŽÓ═¼Ą─Ż¼ę“┤╦SMPę▓▒╗ĘQ×ķę╗ų┬┤µā”Ų„įLå¢ĮYśŗ(UMAŻ║Uniform Memory Access)ĪŻ
SMPĘ■äšŲ„Ą─ų„ę¬╠žš„╩Ū╣▓ŽĒŻ¼ŽĄĮyųą╦∙ėą┘Yį┤(CPUĪóā╚┤µĪóI/OĄ╚)Č╝╩Ū╣▓ŽĒĄ─ĪŻę▓š²╩Ūė╔ė┌▀@ĘN╠žš„Ż¼ī¦ų┬┴╦SMPĘ■äšŲ„Ą─ų„ę¬å¢Ņ}Ż¼─ŪŠ═╩Ū╦³Ą─öUš╣─▄┴”ĘŪ│ŻėąŽ▐ĪŻ
NUMAŻ©Non-Uniform Memory Access)
ė╔ė┌SMPį┌öUš╣─▄┴”╔ŽĄ─Ž▐ųŲŻ¼╚╦éāķ_╩╝╠ĮŠ┐╚ń║╬▀Mąąėąą¦ĄžöUš╣Å─Č°śŗĮ©┤¾ą═ŽĄĮyĄ─╝╝ągŻ¼NUMAŠ═╩Ū▀@ĘN┼¼┴”Ž┬Ą─ĮY╣¹ų«ę╗ĪŻ└¹ė├NUMA╝╝ągŻ¼┐╔ęį░čÄū╩«éĆCPU(╔§ų┴╔Ž░┘éĆCPU)ĮM║Žį┌ę╗éĆĘ■äšŲ„ā╚ĪŻ
NUMAĘ■äšŲ„Ą─╗∙▒Š╠žš„╩ŪŠ▀ėąČÓéĆCPU─ŻēKŻ¼├┐éĆCPU─ŻēKė╔ČÓéĆCPU(╚ń4éĆ)ĮM│╔Ż¼▓óŪęŠ▀ėą¬Ü┴óĄ─▒ŠĄžā╚┤µĪóI/O▓█┐┌Ą╚ĪŻė╔ė┌Ųõ╣سcų«ķg┐╔ęį═©▀^╗ź┬ō─ŻēK(╚ńĘQ×ķCrossbar Switch)▀Mąą▀BĮė║═ą┼ŽóĮ╗╗źŻ¼ę“┤╦├┐éĆCPU┐╔ęįįL墚¹éĆŽĄĮyĄ─ā╚┤µĪŻ’@╚╗Ż¼įLå¢▒ŠĄžā╚┤µĄ─╦┘Č╚īó▀h▀hĖ▀ė┌įLå¢▀hĄžā╚┤µ(ŽĄĮyā╚Ųõ╦³╣سcĄ─ā╚┤µ)Ą─╦┘Č╚Ż¼▀@ę▓╩ŪĘŪę╗ų┬┤µā”įLå¢NUMAĄ─ė╔üĒĪŻė╔ė┌▀@éĆ╠ž³cŻ¼×ķ┴╦Ė³║├Ąž░lō]ŽĄĮyąį─▄Ż¼ķ_░læ¬ė├│╠ą“ĢrąĶę¬▒M┴┐£p╔┘▓╗═¼CPU─ŻēKų«ķgĄ─ą┼ŽóĮ╗╗źĪŻ└¹ė├NUMA╝╝ągŻ¼┐╔ęį▌^║├ĄžĮŌøQįŁüĒSMPŽĄĮyĄ─öUš╣å¢Ņ}Ż¼į┌ę╗éĆ╬’└ĒĘ■äšŲ„ā╚┐╔ęįų¦│ų╔Ž░┘éĆCPUĪŻ▒╚▌^Ąõą═Ą─NUMAĘ■äšŲ„Ą─└²ūė╝┤╬ęéā│ŻšfĄ─ąĪÖC└²╚ńHPĄ─Supterdome║═IBMĄ─PowerĘ■äšŲ„ĪŻ
Ą½NUMAĄ─╣سc╗ź┬ōÖCųŲ╩Ūį┌═¼ę╗éĆ╬’└ĒĘ■äšŲ„ā╚▓┐īŹ¼FĄ─Ż¼«ö─│éĆCPUąĶę¬▀Mąą▀hĄžā╚┤µįLå¢ĢrŻ¼╦³▒žĒÜĄ╚┤²Ż¼▀@ę▓╩ŪNUMAĘ■äšŲ„¤oĘ©īŹ¼FCPUį÷╝ėĢrąį─▄ŠĆąįöUš╣Ą─ų„ę¬įŁę“ĪŻ2013─Ļ─ĻČ╚éõ╩▄▓Ü─┐Ą─“╠įīÜ╚źIOE”Ą─įŁę“ę▓į┌┤╦ĪŻį┌IBMĄ─ąĪÖC║═OracleöĄō■ÄņĄ─ĮM║ŽŽ┬Ż¼╠įīÜ═©▀^ė▓╝■╔²╝ē½@Ą├Ą─ąį─▄į÷ķL▀_ĄĮ┴╦Ų┐ŅiŻ¼¤oĘ©ØMūŃ┐═æ¶Ą─▒¼░ląįį÷ķLĪŻ
MPPŻ©Massive Parallel Processing)
║═NUMA▓╗═¼Ż¼MPP╠ß╣®┴╦┴Ē═Ōę╗ĘN▀MąąŽĄĮyöUš╣Ą─ĘĮ╩ĮŻ¼╦³ė╔ČÓéĆSMPĘ■äšŲ„═©▀^ę╗Č©Ą─╣سc╗ź┬ōŠWĮj▀Mąą▀BĮėŻ¼ģf═¼╣żū„Ż¼═Ļ│╔ŽÓ═¼Ą─╚╬䚯¼Å─ė├æ¶Ą─ĮŪČ╚üĒ┐┤╩Ūę╗éĆĘ■äšŲ„ŽĄĮyĪŻŲõ╗∙▒Š╠žš„╩Ūė╔ČÓéĆSMPĘ■äšŲ„(├┐éĆSMPĘ■äšŲ„ĘQ╣سc)═©▀^╣سc╗ź┬ōŠWĮj▀BĮėČ°│╔Ż¼├┐éĆ╣سcų╗įLå¢ūį╝║Ą─▒ŠĄž┘Yį┤(ā╚┤µĪó┤µā”Ą╚)Ż¼╩Ūę╗ĘN═Ļ╚½¤o╣▓ŽĒ(Share Nothing)ĮYśŗŻ¼ę“Č°öUš╣─▄┴”ūŅ║├Ż¼└Ēšō╔ŽŲõöUš╣¤oŽ▐ųŲŻ©╚ńłD1╦∙╩ŠŻ®ĪŻ─┐Ū░Ą─╝╝ąg┐╔īŹ¼F512éĆ╣سc╗ź┬ōŻ¼öĄŪ¦éĆCPUĪŻ─┐Ū░śIĮńī”╣سc╗ź┬ōŠWĮjĢ║¤oś╦£╩Ż¼╚ń NCRĄ─BynetŻ¼IBMĄ─SPSwitchŻ¼╦³éāČ╝▓╔ė├┴╦▓╗═¼Ą─ā╚▓┐īŹ¼FÖCųŲĪŻĄ½╣سc╗ź┬ōŠWāH╣®MPPĘ■äšŲ„ā╚▓┐╩╣ė├Ż¼ī”ė├æ¶Č°čį╩Ū═Ė├„Ą─ĪŻ
į┌MPPŽĄĮyųąŻ¼├┐éĆSMP╣سcę▓┐╔ęį▀\ąąūį╝║Ą─▓┘ū„ŽĄĮyĪóöĄō■ÄņĄ╚ĪŻĄ½║═NUMA▓╗═¼Ą─╩ŪŻ¼╦³▓╗┤µį┌«ÉĄžā╚┤µįLå¢Ą─å¢Ņ}ĪŻōQčįų«Ż¼├┐éĆ╣سcā╚Ą─CPU▓╗─▄įLå¢┴Ēę╗éĆ╣سcĄ─ā╚┤µĪŻ╣سcų«ķgĄ─ą┼ŽóĮ╗╗ź╩Ū═©▀^╣سc╗ź┬ōŠWĮjīŹ¼FĄ─Ż¼▀@éĆ▀^│╠ę╗░ŃĘQ×ķöĄō■ųžĘų┼õ(Data Redistribution)ĪŻ
Ą½╩ŪMPPĘ■äšŲ„ąĶę¬ę╗ĘNÅ═ļsĄ─ÖCųŲüĒš{Č╚║═ŲĮ║ŌĖ„éĆ╣سcĄ─žō▌d║═▓óąą╠Ä└Ē▀^│╠ĪŻ─┐Ū░ę╗ą®╗∙ė┌MPP╝╝ągĄ─Ę■äšŲ„═∙═∙═©▀^ŽĄĮy╝ē▄ø╝■(╚ńöĄō■Äņ)üĒŲ┴▒╬▀@ĘNÅ═ļsąįĪŻ└²╚ńNCRĄ─TeradataŠ═╩Ū╗∙ė┌MPP╝╝ągĄ─ę╗éĆĻPŽĄöĄō■Äņ▄ø╝■Ż¼╗∙ė┌┤╦öĄō■ÄņüĒķ_░læ¬ė├ĢrŻ¼▓╗╣▄║¾┼_Ę■äšŲ„ė╔ČÓ╔┘éĆ╣سcĮM│╔Ż¼ķ_░l╚╦åT╦∙├µī”Ą─Č╝╩Ū═¼ę╗éĆöĄō■ÄņŽĄĮyŻ¼Č°▓╗ąĶę¬┐╝æ]╚ń║╬š{Č╚Ųõųą─│ÄūéĆ╣سcĄ─žō▌dĪŻ
MPPęįŲõā×┴╝Ą─öUš╣╝▄śŗ│╔×ķ┴╦Ęų▓╝╩Į╝▄śŗĄ─╗∙ĄAĪŻ
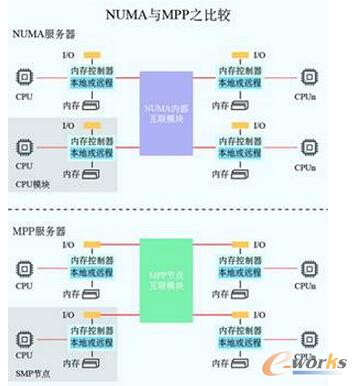
łD1 MPPĘ■äšŲ„╝▄śŗłD
2.Ęų▓╝╩Į╝▄śŗæ¬ė├¼FĀŅ
«öŪ░ų„┴„Ą─Ęų▓╝╩Įæ¬ė├ėąā╔ĘNŻ║Ęų▓╝╩ĮöĄō■Äņ║═HadoopĘų▓╝╩ĮŽĄĮyĪŻā╔ĘNĮŌøQĘĮ░Ėī”▒╚╚ń▒Ē1╦∙╩ŠĪŻ
▒Ē1 Ęų▓╝╩ĮöĄō■Äņ║═HadoopĘų▓╝╩ĮŽĄĮyĄ─ī”▒╚
MPPĘų▓╝╩ĮöĄō■Äņ▌^HadoopĘų▓╝╩ĮŽĄĮyŻ¼į┌Å═ļs▀ē▌ŗĄ─ĮYśŗ╗»öĄō■╠Ä└Ē╔ŽŠ▀ėąę╗Č©Ą─ā×ä▌Ż¼Ūę┐╔╗∙ė┌SQLķ_░lŻ¼ī”ė┌ėą▌^žSĖ╗SQLĮø“ץ─ŽĄĮyķ_░lš▀Ż¼ķ_░l┼c▀\ŠSĖ³╚▌ęūĪŻ«ö╚╗Ż¼śIĮńMPPĘų▓╝╩ĮöĄō■Äņ«aŲĘārĖ±ę▓ę¬Ė▀ė┌Hadoop▀@éĆį┤ė┌ķ_į┤╔ńģ^Ą─«aŲĘĪŻ
▀@╩ŪʱęŌ╬Čų°MPPĘų▓╝╩ĮöĄō■ÄņŠ═╩Ū┤¾öĄō■╠Ä└ĒĄ─ūŅ╝čĮŌøQĘĮ░Ė─ž?╬ęéāęįŃyąąŽĄĮyöĄō■Ą─ārųĄ├▄Č╚║═öĄō■╠žš„×ķ└²üĒ┐╝æ]▀@éĆå¢Ņ}ĪŻī”ė┌ŃyąąŽĄĮyöĄō■Ż¼╬ęéā╗∙▒Š┐╔ęį▀_│╔▀@śėę╗éĆ╣▓ūRŻ║ŃyąąŽĄĮyöĄō■ųąŻ¼ĮYśŗ╗»öĄō■ārųĄ├▄Č╚═©│ŻĖ▀ė┌ĘŪĮYśŗ╗»╗“░ļĮYśŗ╗»öĄō■Ż¼Č°į┌ŃyąąöĄō■ųąĘŪĮYśŗ╗»öĄō■š╝ė├┴╦┤¾┴┐Ą─┤µā”┘Yį┤ĪŻ▀@╩Ūę“×ķŃyąąŽĄĮyųąĮYśŗ╗»öĄō■ęį┘~äšöĄō■×ķų„Ż¼Č°ĘŪĮYśŗ╗»öĄō■ätų„ę¬╝»ųąį┌æ{ūCė░Ž±Ą╚öĄō■ĪŻ«ö╚╗ĮYśŗ╗»öĄō■ųąę▓░³└©▓┐Ęų╚šųŠą┼ŽóĄ╚ārųĄ├▄Č╚▓╗Ė▀Ą─öĄō■ĪŻ
öĄō■┤µā”┼c╠Ä└Ē╝╝ągį┌ė╔“ę╗ĘN╝▄śŗų¦│ų╦∙ėąæ¬ė├”Ž““ČÓĘN╝▄śŗų¦│ųČÓŅÉæ¬ė├”▐DūāĪŻ═¼śėī”ė┌öĄō■Ž¹┘MīėöĄō■╠Ä└Ē╝╝ągŻ¼ę▓æ¬Ė∙ō■öĄō■ārųĄ├▄Č╚╝░öĄō■╠žš„Ą╚ę“╦ž▓╔ė├┼cų«ŽÓŲź┼õĄ─╝▄śŗüĒų¦│ųĪŻī”ė┌öĄō■Ž¹┘MīėöĄō■ųą─Ūą®ārųĄ├▄Č╚Ė▀Ą─Į╗ęū╝░┘~äšöĄō■┐╔▓╔ė├MPPĘų▓╝╩ĮöĄō■ÄņśŗĮ©öĄō■╠Ä└ĒŲĮ┼_Ż¼Č°ī”ė┌─Ūą®ārųĄ├▄Č╚▓╗Ė▀Ą─ĮYśŗ╗»öĄō■║═ĘŪŻ©░ļŻ®ĮYśŗ╗»öĄō■ät┐╔ęį▓╔ė├HadoopĘų▓╝╩ĮŽĄĮyū„×ķ╠Ä└ĒŲĮ┼_ĪŻ
3.Ęų▓╝╩ĮŠųŽ▐ąįŻ║CAP└Ēšō
╚ńłD2╦∙╩ŠŻ¼CAPįŁ└Ēųąėą╚²éĆę¬╦žŻ║ę╗ų┬ąį(Consistency)Ż¼┐╔ė├ąį(Availability)║═Ęųģ^╚▌╚╠ąį(Partition tolerance)ĪŻ
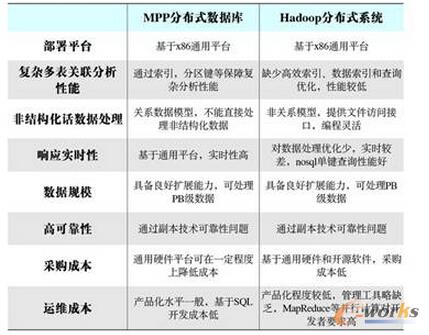
łD2 CAPįŁ└Ē╩ŠęŌłD
CAPįŁ└ĒųĖĄ─╩Ūį┌Ęų▓╝╩ĮŽĄĮyųą▀@╚²éĆę¬╦žūŅČÓų╗─▄═¼ĢrīŹ¼Fā╔³cŻ¼▓╗┐╔─▄╚²š▀╝µŅÖĪŻę“┤╦į┌▀MąąĘų▓╝╩Į╝▄śŗįOėŗĢrŻ¼▒žĒÜū÷│÷╚Ī╔ßĪŻČ°ī”ė┌Ęų▓╝╩ĮöĄō■ŽĄĮyŻ¼Ęųģ^╚▌╚╠ąį╩Ū╗∙▒Šę¬Ū¾Ż¼Ę±ätŠ═╩¦╚ź┴╦ārųĄĪŻę“┤╦įOėŗĘų▓╝╩ĮöĄō■ŽĄĮyŻ¼Š═╩Ūį┌ę╗ų┬ąį║═┐╔ė├ąįų«ķg╚Īę╗éĆŲĮ║ŌĪŻī”ė┌┤¾ČÓöĄWebæ¬ė├Ż¼ŲõīŹ▓ó▓╗ąĶę¬ÅŖę╗ų┬ąįŻ¼ ę“┤╦Ā▐╔³ę╗ų┬ąįČ°ōQ╚ĪĖ▀┐╔ė├ąįŻ¼╩Ū─┐Ū░ČÓöĄĘų▓╝╩ĮöĄō■Äņ«aŲĘĄ─ĘĮŽ“ĪŻ
Å─┐═æ¶Č╦ĮŪČ╚Ż¼ČÓ▀M│╠▓ó░lįLå¢ĢrŻ¼Ė³ą┬▀^Ą─öĄō■į┌▓╗═¼▀M│╠╚ń║╬½@╚ĪĄ─▓╗═¼▓▀┬įŻ¼øQČ©┴╦▓╗═¼Ą─ę╗ų┬ąįĪŻī”ė┌ĻPŽĄą═öĄō■ÄņŻ¼ę¬Ū¾Ė³ą┬▀^Ą─öĄō■─▄▒╗║¾└mĄ─įLå¢Č╝─▄┐┤ĄĮŻ¼▀@╩ŪÅŖę╗ų┬ąįĪŻ╚ń╣¹─▄╚▌╚╠║¾└mĄ─▓┐Ęų╗“š▀╚½▓┐įLå¢▓╗ĄĮŻ¼ät╩Ū╚§ę╗ų┬ąįĪŻ╚ń╣¹Įø▀^ę╗Č╬Ģrķg║¾ę¬Ū¾─▄įLå¢ĄĮĖ³ą┬║¾Ą─öĄō■Ż¼ät╩ŪūŅĮKę╗ų┬ąįĪŻ
Ą½Webæ¬ė├ę▓ėą└²═ŌŻ¼▒╚╚ńų¦ĖČīÜŽĄĮyŻ¼Š═ę¬Ū¾öĄō■Ż©Ńyąą┘~æ¶Ż®Ą─ÅŖę╗ų┬ąįŻ¼Č°Ūę├µī”┤¾┴┐╠įīÜė├æ¶Ż¼┐╔ė├ąįę¬Ū¾║▄Ė▀Ż¼ę“┤╦ų╗─▄Ā▐╔³öĄō■Ą─Ęųģ^╚▀ėÓĪŻ
ī”ė┌MPP DBČ°čįŻ¼ļmšf╩Ūą¹ĘQScale outŻ©ÖMŽ“öUš╣Ż®Ż¼Ą½╩Ū▀@ĘNoutę╗░ŃĄĮ100Ż¼Č°Hadoopę╗░Ń┐╔ęįĄĮ1000+ĪŻį┌╬ęéāĄ─£yįćųąŻ¼ę▓░l¼FŠĆąįöUš╣ąįę╗ĒŚ╝┤╩╣╩Ūį┌▌^ąĪĄ─╣سcöĄĘĮ├µŻ¼ę▓▓ó╬┤▀_ĄĮĮ^ī”Ą─ų▒ŠĆĄ─ąį─▄ĪŻ
▀@╩Ū×ķ╩▓├┤─žŻ┐╬ęéā┤¾ų┬┐╔ęįÅ─CAP└Ēšō╔ŽüĒšęĄĮę╗ą®└Ēė╔ĪŻę“×ķMPP DB╩╝ĮK▀Ć╩ŪDBŻ¼ę╗Č©ę¬┐╝æ]CŻ©ConsistencyŻ®Ż¼Ųõ┤╬┐╝æ]AŻ©AvailabilityŻ®Ż¼ūŅ║¾▓┼į┌┐╔─▄Ą─ŪķørŽ┬▒M┴┐ū÷║├PŻ©Partition-toleranceŻ®ĪŻČ°HadoopŠ═╩Ū×ķ┴╦▓óąą╠Ä└Ē║═┤µā”įOėŗĄ─Ż¼╦∙ęįā׎╚┐╝æ]Ą─╩ŪPŻ¼╚╗║¾╩ŪAŻ¼ūŅ║¾į┘┐╝æ]CĪŻ╦∙ęį║¾š▀Ą─┐╔öUš╣ąį«ö╚╗║├ė┌Ū░š▀ĪŻ
Č■Īó╠ōöM╗»╝▄śŗ░lš╣║═¼FĀŅ
─┐Ū░Ż¼╠ōöM╗»Ą─ārųĄęčĮø▒╗ÅVĘ║šJ┐╔Ż¼╠ōöM╗»╝▄śŗę▓ęčĮø×ķ┤¾╝ę╦∙╩ņų¬Ż¼▒Š╬─▓╗į┌▀@└’┘ś╩÷Ż¼āH╠Įėæę╗ą®ĻPµIĄ─Ė³ą┬ĪŻ
1.╚½╚┌║Ž╠ōöM╗»╝▄śŗ
╚½╚┌║Ž╠ōöM╗»╝▄śŗŻ¼ę▓Š═╩Ū╬ęéā│ŻšfĄ─▄ø╝■Č©┴xöĄō■ųąą─ĪŻÅ─ūŅų▒ė^Ą─Č©┴xüĒ┐┤Ż¼Š═╩Ū╠ōöM╗»Īó▄ø╝■╗»öĄō■ųąą─Ą─ę╗Ūą┘Yį┤ĪŻ╠ōöM╗»╩ŪÅ─Ę■äšŲ„╠ōöM╗»ķ_╩╝Ą─Ż¼╠ōöMÖCĦüĒĄ─║├╠Ä║▄ČÓ┐═æ¶Č╝ęčĮøĘŪ│Ż┴╦ĮŌĪŻĄ½╩ŪŠWĮjĪó┤µā”╩Ū╬’└Ēąį║▄ÅŖĄ─┘Yį┤Ż¼╠ōöMÖCļm╚╗ĦüĒ┴╦ę╗ą®ņ`╗ŅąįŻ¼ø]ėą▐kĘ©į┌Ųõ╦¹┘Yį┤╔Ž¾w¼FĪŻų╗ū÷ėŗ╦Ń╠ōöM╗»ŽÓ«öė┌āH═Ļ│╔┴╦š¹éĆ╣żū„Ą─30%ĪŻ▄ø╝■Č©┴xĄ─öĄō■ųąą─Š═╩Ū░čöĄō■ųąą─╦∙ėąĄ─é„Įy╬’└Ēė▓╝■Ą─┘Yį┤▀Mąą╠ōöM╗»Īó▄ø╝■╗»Ż¼Å─Č°īŹ¼F┴╦┘Yį┤Ą─│ķŽ¾║═┼cė▓╝■Ą─ĮŌ±Ņ║═Ż¼╩ŪīŹ¼FįŲėŗ╦ŃĄ─╗∙ĄAĪŻ
ėŗ╦Ń┤µā”╚┌║Ž
HDFS╩ŪGoogle╣½╦ŠĄ─GFSĄ─ķ_į┤īŹ¼FŻ¼GFS╩Ū┤¾öĄō■Ą─╗∙ĄAĪŻHDFS╩ŪĘų▓╝╩ĮĄ─╬─╝■ŽĄĮyŻ¼╝┤├┐┼_Ę■äšŲ„į┌ų╗╩╣ė├ā╚ų├ė▓▒PĄ─ŪķørŽ┬Ż¼═©▀^ŠWĮj╗ź▀BŻ¼ĮMĮ©┴╦ę╗éĆė╔ČÓéĆ╣سcĮM│╔Ą─Ż¼├┐éĆ╣سcČ╝═¼Ģr╩╣ė├▓óąą╬─╝■ŽĄĮyĪŻĘų▓╝╩Į╬─╝■ŽĄĮy╩ŪŽ╚▀Mų¦ō╬╗ź┬ōŠWæ¬ė├Ą─╗∙ĄAŻ¼¤ošō╩Ū╠įīÜ▀Ć╩Ū“vėŹŻ¼Č╝ėąę╗éĆ╗∙ė┌ķ_į┤Ż¼ūį╝║čą░lĄ─Ż¼├¹ĮąTFSŻ©Ū╔║ŽŻ¼Č╝ĮąTFSŻ®Ą─Ęų▓╝╩Į╬─╝■ŽĄĮyĪŻTFS╩Ūų¦ō╬Ųõ║Ż┴┐öĄō■Ą─╗∙ĄAĪŻ
Ceph╩ŪOpenStackųąūŅ┴„ąąĄ─┤µā”╣▄└Ē─ŻēKŻ¼═¼Ģrų¦│ų╬─╝■¾wĮyŻ¼ēKįOéõ║═ī”Ž¾┤µā”ĪŻCephŽ±ę╗┼·║┌±RŻ¼┤¾ėą╚Ī┤·swiftŻ©ī”Ž¾┤µā”Ż®║═cinderŻ©ēKįOéõŻ®Ą─┌ģä▌ĪŻ
┤µā”«aŲĘ▒Š╔Ēę▓╠Äį┌ūāĖ’Ą─▀^│╠ųąŻ¼SSDĄ─│÷¼FÅžĄūĖ─ūā┴╦é„Įy┤µā”ĪŻSSDū„×ķŠÅ┤µ─▄ē“śO┤¾Ą─╠ß╔²Ęų▓╝╩Į╬─╝■ŽĄĮyĄ─ąį─▄Ż¼═©▀^╗ź┬ōŠWęčĮøūC├„ūį╝║īŹ┴”Ą─╬─╝■ŽĄĮy▒žīóį┌Ų¾śI╩ął÷╝żŲą┬Ą─└╦│▒ĪŻ
ėŗ╦ŃŠWĮj╚┌║Ž
¡ SDN║═VXLAN
SDN╠ß│÷┴╦▓╔ė├▄ø╝■Č©┴xŠWĮjĄ─╦╝┬ĘŻ¼Š▀ėą▐D░l║═┐žųŲĘųļxĪó┐žųŲ▀ē▌ŗ╝»ųąĪóŠWĮj╠ōöM╗»ĪóŠWĮj─▄┴”ķ_Ę┼╗»Ą╚╠ž³cĪŻSDNīŹ¼FĄ─║╦ą─┐žųŲŲ„Ż¼╝┤┐╔ęį╩ŪŲš═©Ą─╬’└ĒĘ■äšŲ„ę▓┐╔ęį╩Ū╠ōöMÖCĪŻ
VXLAN╝╝ąg╩Ū×ķ┴╦ĮŌøQöĄō■ųąą─╠ōöMČÓūŌæ¶║═╠ōöMÖC▀węŲĄ─å¢Ņ}Č°įOėŗĄ─ĪŻVXLAN╝╝ąg▓╔ė├┴╦L2 over L3╝╝ągŻ¼į┌įŁėąĄ─öĄō■ł¾╬─ĘŌčbųąį÷╝ė┴╦VXLANĘŌčbŻ¼▓óį÷╝ė┴╦IPĘŌčbŻ¼╩╣Ą├įŁėąĄ─L2ł¾╬─┐╔ęį┤®įĮL3ŠWĮjŻ¼öU┤¾┴╦Č■īėŠWĮjĄ─ĘČć·Ż¼╩╣Ą├╠ōöMÖC▀węŲ ┐╔ęįņ`╗Ņ┐ńįĮ╚²īė▓┐╩ĪŻ═¼ĢrŻ¼VXLANĘŌčb┤¾┤¾öUš╣┴╦ūŌæ¶IDūųČ╬Ż¼▒▄├Ō┴╦▓╔ė├VLANĘĮ╩Į╩▄ĄĮ4K╚▌┴┐Ą─Ž▐ųŲĪŻ
VXLAN┼cSDNŻ¼Ū░š▀ĮŌøQ╠ōöM▀węŲŻ¼║¾š▀ĻPūó┐žųŲŻ¼īóų¦ō╬╬┤üĒįŲėŗ╦ŃŠWĮjĄ─┤ŅĮ©ĪŻ
¡ NFV
NFV╝┤ŠWĮj╣”─▄╠ōöM╗»Ż¼é„ĮyŠWĮjįOéõ╩Ūė╔īŻķTĄ─ė▓╝■ąŠŲ¼║═Č©ųŲ▄ø╝■ŲĮ┼_ĮM│╔Ą─ĪŻNFVųĖ░čČ©ųŲ▄ø╝■ŲĮ┼_░▓čbį┌═©ė├ė▓╝■ŲĮ┼_Ż¼╝┤x86Ę■äšŲ„╔ŽĪŻŲõ▒Š┘|į┌ė┌ĮŌøQļŖą┼▀\ĀI╔╠ČÓ─ĻüĒĖ▀░║Ą─ŠWĮj│╔▒Š║═ĘŌķ]Ą─ŠWĮj╣”─▄ĪŻ
¡ SDN┼cNFV
SDN╩Ūę╗ĘN┐ńįOéõ╝ēĄ─╝╝ągŻ¼▓╗āHų╗¾w¼Fį┌Ų¾śIŠWųąĄ──│ę╗┼_įOéõ╔ŽŻ¼Ųõ═©▀^Ė─ūāŠWĮj┐žųŲīė┼c▐D░līėĄ─▀ē▌ŗĻPŽĄŻ¼īó×ķŽ┬ę╗┤·ŠWĮjĦüĒĖ³ČÓĪóĖ³ą┬Ą─╣”─▄Ż¼▒╚╚ńßśī”▓╗═¼Ą─śIäš┐═æ¶╚║Ż¼═©▀^Ė─ūā╣سcįOéõĄ─▐D░l┴„▒ĒŻ¼ā×╗»▓╗═¼Ą─śIäš┴„ĪŻČ°NFVätī┘ė┌«aŲĘ╝ēĄ─╝╝ągŻ¼═©▀^Ė─ūāå╬┼_įOéõ╣”─▄Ą─│ą▌dą╬æB▀MČ°ė░Ēæš¹éĆŠWĮj╝▄śŗŻ¼▒╚╚ńį┌│Ūė“ŠWųąŻ¼īóįŁ▒Š┤µį┌ė┌Įyę╗╝»│╔ŠWĻPįOéõųąĄ─┬Ęė╔ĪóČÓ├Į¾węį╝░░▓╚½Ą╚ŠWĮj╣”─▄▐DęŲĄĮ═©ė├Ę■äšŲ„╔Ž▀\ąąŻ¼ęį▒ŃĮĄĄ═│╔▒ŠĪóĖ³║├ĄžĒææ¬ė├æ¶Ą─ąĶŪ¾ĪŻ└²╚ńŻ¼H3CĄ─VSRŻ¼Š═╩Ūę╗┐Ņ▀\ąąį┌ś╦£╩Ę■äšŲ„╠ōöMÖC╔ŽĄ─╝ā▄ø╝■┬Ęė╔Ų„«aŲĘŻ¼īŹ¼F┴╦ėŗ╦ŃŲĮ┼_║═ŠWĮjŲĮ┼_Ą─╚┌║ŽĪŻ
2.╣½ėąįŲĘ■äš
¤ošō╣½ėąįŲ▀Ć╩Ū╦ĮėąįŲŻ¼įŲĘ■äš╣▄└ĒŲĮ┼_Įø▀^ČÓ─ĻĄ─░lš╣ęčĮø┬õĄžŻ¼Ųõ╣”─▄─ŻēKęčĮø┤_Č©ĪŻįŲ╣▄└ĒŲĮ┼_ė╔ķTæ¶æ¬ė├ĪóĘ■äš▀\ĀIĪó┘Yį┤╣▄└ĒĪó▀\ŠS╣▄└ĒĪóŽĄĮy╣▄└Ēęį╝░Įė┐┌Ą╚ĮM│╔ĪŻė├æ¶─▄ē“═©▀^ūįĘ■äšķTæ¶Portal▀Mąąė├æ¶ĄŪõøĄŪõøĪóĘ■äšėå┘ÅĪóĘ■äšūāĖ³ĪóĘ■äš═╦ėåĪó┘Yį┤╩╣ė├Ą╚Ę■äš▓┘ū„ĪŻ▀\ĀI╚╦åT─▄ē“═©▀^▀\ĀI╣▄└ĒķTæ¶Portal▀Mąąė├æ¶╣▄└ĒĪó┘Yį┤─Ż░Õ╣▄└Ēęį╝░ŽĄĮy╣▄└ĒĄ╚▀\ĀI▓┘ū„ĪŻ┤¾╝ę┐╔ęį┐┤ĄĮŻ¼╚┌║Ž║¾╠ōöM╗»╝▄śŗū„×ķę╗▓┐Ęų░³║¼į┌┘Yį┤╣▄└ĒųąŻ©╚ńłD3╦∙╩ŠŻ®ĪŻ
łD3 įŲĘ■äš╣▄└ĒŲĮ┼_Ą─ų„ę¬╣”─▄
╚²ĪóĮY╩°šZ
ļSų°śI䚥─▓╗öÓ░lš╣Ż¼é„ĮyŲ¾śIė├æ¶Ģ■░l¼F╠žČ©æ¬ė├Ż¼═©▀^é„ĮyĄ─ė▓╝■╔²╝ēę▓¤oĘ©ØMūŃŲõąĶŪ¾Ż¼╝┤ė÷ĄĮ┴╦ąį─▄╗“š▀╚▌┴┐Ą─╠ņ╗©░ÕĪŻę“┤╦Ż¼é„ĮyŲ¾śIĘ┤Č°▐DŽ“╗ź┬ōŠWąąśIīW┴ĢĘų▓╝╩Į╝▄śŗüĒĮŌøQ╦¹éāė÷ĄĮĄ─å¢Ņ}ĪŻ“└ŌńRķT”╩┬╝■Ą─ų„ĮŪ——├└ć°ć°╝ę░▓╚½Šųų«╦∙ęį▀xųąAmazonüĒ╠ß╣®Ųõ╗∙ĄAįO╩®Č°ø]ėą▀xųąIBMę▓╩Ū╗∙ė┌Ųõ║Ż┴┐öĄō■Ż©╩└ĮńĘČć·ā╚▒O┬ĀļŖįÆŻ¼▒O┐žļŖÓ]Ż®▀^×VĘų╬÷Ą─ąĶŪ¾ĪŻ
Ą½╩ŪĘų▓╝╩Į╝▄śŗę▓▓╗╩Ū╚f─▄Ą─ĪŻé„ĮyąąśIĄ─ITÅŖš{öĄō■ę╗ų┬ąįŻ¼Č°Ęų▓╝╩ĮŽĄĮyÅŖš{ŠĆąįöUš╣Ż¼ų╗▒ŻūCūŅĮKę╗ų┬Ż¼▀@ā╔š▀▓╗┐╔╝µĄ├ĪŻ┤¾╝ę┐╔ęįģó┐╝Ū░╬─Ą─CAP└ĒšōŻ¼öĄō■ę╗ų┬ąįŻ¼┐╔ė├ąįŻ¼Ęųģ^─═╩▄ąį▀@╚²š▀į┌╚╬ę╗Ģr┐╠Ż¼╚╬║╬ŽĄĮyų╗ėąā╔ĒŚ─▄═¼Ģr│╔┴óĪŻ
│²┤╦ęį═ŌŻ¼é„ĮyąąśI║═╗ź┬ōŠWŲ¾śIĄ─Į©įO─Ż╩Įę▓╩Ū▓╗═¼Ą─Ż¼é„ĮyąąśIāAŽ“ė┌┘Å┘IČ©ųŲė▓╝■Ż©UnixĘ■äšŲ„Ż¼FC┤µā”Ż®║═╔╠śI▄ø╝■Ż©OracleöĄō■ÄņŻ¼Weblogicųąķg╝■Ż®║═╔╠śIĄ─ĮŌøQĘĮ░ĖĪŻė╔ė┌▓╗šŲ╬š║╦ą─╝╝ągŻ¼Ų¾śIIT╣▄└Ē╚╦åTė÷ĄĮå¢Ņ}Ģ■ų▒Įėū╔įāÅS╔╠Ż¼īŻśIÅS╔╠×ķŲ¾śI┴xäš▀B└mąį▒│Ģ°ĪŻČ°╗ź┬ōŠWŲ¾śIė╔ė┌┐╔ęį┐┤ĄĮį┤┤·┤a▓óŪęŠ▀éõ▓┘ū„ŽĄĮyā╚║╦╝ēą▐Ė─Ą──▄┴”Ż¼āAŽ“ė┌╩╣ė├ķ_į┤▄ø╝■Ż¼x86╝▄śŗ┴«ārė▓╝■┼õ║Ž┤¾┴┐╣ż│╠ĤȩųŲķ_░lŻ╗Ų¾śIė÷ĄĮå¢Ņ}ų╗ėąę└┐┐ūį╝║ĮŌøQĪŻ▀@ā╔ĘNĘĮ╩Įø]ėą╩ļā×╩ļ┴ėŻ¼▀m║ŽĄ─Š═╩ŪūŅ║├Ą─Ż¼Č°ŪęÅ─│╔▒Š╔ŽŲõīŹųv▓Ņ▓╗ČÓĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║ą┬ę╗┤·öĄō■ųąą─Ą─ėŗ╦Ń╝▄śŗ
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/solutions/14019318121.html






















