



║åę¬
ų„ę¬ĮŌøQ¤ß▀węŲī”Ž¾į┌ā╚┤µ└¹ė├ūā╗»┐ņŻ¼┤┼▒Pūxīæ╦┘┬╩┐ņĄ╚ĀŅæBĄ─ŪķørŽ┬¤oĘ©┼ąöÓŲõ╩Ūʱ▀m║Ž░lŲ¤ß▀węŲĪŻ
▒Š┤╬╚╬äšĘĮ░Ė▀xō±┴╦ČÓ╝»│╔īW┴Ģ╦ŃĘ©Ą─═ČŲ▒▀x┼eŻ¼▀@╩Ūę╗éĆ╗∙ė┌RandomForestŻ¼AdaboostingŻ¼XgboostśIĮńų„┴„╦ŃĘ©Ą─╗ņ║ŽvotingŅA£y─Żą═ĪŻ30%šµīŹöĄō■╝»ū„×ķ“×ūCŻ¼ŅA£yŠ½Č╚97.44%Ż¼īŹ¼Fī”¤ß▀węŲ░lŲ╚╬䚥─│╔╣”┬╩ŅA£yŻ¼ī”ė┌│¼Ģr▀węŲūRäeĄ─śė▒ŠūRäe┬╩īŹ¼FŻ¼ę▓Š═╩Ūšf┐╔ęį£p╔┘įŁüĒ¤ß▀węŲ│¼Ģr╩¦öĪŪķøröĄ┴┐Ą─80%ĪŻ
1. ąĶŪ¾▒│Š░
į┌įŲėŗ╦Ń┘Yį┤╣▄└ĒųąŻ¼¤ß▀węŲ╩ŪīŹ¼F┘Yį┤┼õų├Ą─ųžę¬╩ųČ╬Ż¼│Ż│ŻĢ■ę“×ķČÓĘNł÷Š░ąĶę¬░lŲ¤ß▀węŲŻ║└²╚ń┘Yį┤š{┼õŻ¼─ĖÖCžō▌dŠ∙║Ōęį╝░▀\ŠS╚╦╣ż¤ß▀węŲĄ╚ł÷Š░ĪŻ
Č°į┌«öŪ░¤ß▀węŲ╚╬äšųąŻ¼¤ß▀węŲį┌Įø▀^ČÓ┤╬Śl╝■▀^×V║¾▀Ć╩ŪĢ■Įø│Żė÷ĄĮ▀węŲ│¼Ģr╩¦öĪĄ─ŪķørŻ¼░lŲ▓╗║Ž▀mĄ─¤ß▀węŲ╚╬䚯¼▓╗āHė░Ēæ┴╦┐═æ¶┴╦SLA¾w“ׯ¼ę▓ė░Ēæ┴╦¤ß▀węŲą¦┬╩ĪŻ
░┤ęį═∙╚╦╣żĮø“×╚ź▀Mąą┼ąöÓ╩Ūʱ▀m║Ž¤ß▀węŲŻ¼└²╚ńā╚┤µūā╗»┬╩Ė▀Ģ■ė░Ēæ¤ß▀węŲŻ¼CPU╩╣ė├┬╩ ▀^Ė▀ę▓Ģ■ė░Ēæ¤ß▀węŲŻ¼
į┌▀@ų«Ū░▒M╣▄╬ęéāų¬Ą└ā╚┤µūā╗»┬╩▀^Ė▀Ż¼CPU╩╣ė├┬╩▀^Ė▀Ż¼─╦ų┴ā╚═ŌŠW═╠═┬┴┐▀^Ė▀Č╝Ģ■ė░ĒæĄĮ¤ß▀węŲĄ─│╔╣”Ż¼ Ą½╬ęéā¤oĘ©╚źśŗĮ©ę╗éĆ║Ō┴┐ś╦£╩ĪŻ▓óŪę╚ń╣¹ŅlĘ▒╚ź▒O┐ž½@╚ĪūėÖCĄ─▀@ą®öĄō■Ż¼ę▓Ģ■ī”╠ōöMÖCąį─▄įņ│╔ė░ĒæŻ¼▓óŪę╚╦╣żę▓¤oĘ©╚ź┼ąöÓ╩▓├┤Ģrķg³c──ą®ŪķørŽ┬──éĆųĖś╦Ė³ųžę¬Ż¼ę“┤╦¤oĘ©ą╬│╔ę╗éĆŠC║ŽČ°┐═ė^ĘĆČ©Ą─┼ąäeś╦£╩ĪŻ
2. īŹ¼F─┐ś╦
╦∙ęį╬ęéāę²╚ļ┴╦ÖCŲ„īW┴Ģ&╔ŅČ╚īW┴ĢŻ¼ŽŻ═¹─▄ē“öM║Žę╗éĆÅ═ļs─Żą═╚źėŗ╦Ń▓ó┴┐╗»│÷ę╗éĆ▀m║Ž¤ß▀węŲĄ─ĀŅæBś╦£╩Ż¼īŹ¼Fī”¤ß▀węŲ░lŲ║¾╩ŪʱĢ■│¼Ģr╩¦öĪ▀MąąŅA£yĪŻ
3. īŹ¼F║åĮķ
3.1╠žš„┐šķg

3.2╠žš„╠Ä└Ē
┐╝æ]ĄĮ├┐┴ąöĄō■Ą─▓Ņ«Éėą6éĆöĄ┴┐╝ē▓ŅäeŻ¼╦∙ęįąĶę¬ī”┤¾öĄ┴┐╝ēĄ─┴ąöĄō■ ▀Mąą┐sĘ┼ĪŻ│Żė├Ą─ū÷Ę©ėą np.sqrtŻ¼np.logĪŻ
3.3 HeatMap╠žš„ŽÓĻPąįĘų╬÷
¤ß┴”łD╩ŪūŅų▒ė^Ą─š╣╩Š╠žš„ų«ķgĄ─ŠĆąįŽÓĻPąįŻ¼Å─łDųą╬ęéā┐╔ęį┐┤ĄĮcpu║═mem│╩ÅŖŽÓĻPąįŻ¼▀@╩Ū’@╚╗Ą─ĮY╣¹Ż¼Ė▀ąį─▄cpu═∙═∙░ķļS┤¾ā╚┤µŻ╗Ųõ┤╬│╩¼FųąĄ╚ŽÓĻPĄ─╩Ū│÷╚ļ┴„┴┐ĪŻė╔┤╦║åå╬┐╔ęį┐┤│÷Ė„éĆ╠žš„ģóöĄČ╝╩ŪŽÓī”¬Ü┴óĄ─Ż¼Å─ŠĆąįŽÓĻPĮŪČ╚┐┤ĪŻ

3.4╦ŃĘ©║åĮķŻ║×ķ╩▓├┤▀xō±ļSÖC╔Ł┴ų┼cXgboost
ļSÖC╔Ł┴ų
╚ń╣¹Å─╔ŅČ╚īW┴ĢĄ─ĮŪČ╚╚ź└ĒĮŌŻ¼┐╔ęįšJ×ķļSÖC╔Ł┴ųĄ─øQ▓▀śõļSÖCĘų┴čŻ¼ļ[║¼Ąžäōįņ┴╦ČÓéĆ┬ō║Ž╠žš„Ż¼▓ó─▄ē“ĮŌøQĘŪŠĆąįå¢Ņ}Ż¼
┐╔ęįŽÓī”ļx╔óĄžūįäė╠ß╚Ī╠žš„┼cÖÓųžīW┴ĢĪŻ─│ĘNęŌ┴x╔ŽīŹ¼FCNNĄ─ŠĒĘe│ž╗»╠ß╚Īū„ė├ĪŻ
▓óąąėŗ╦ŃŻ¼ī”ė┌éĆäe╠žš„╚▒╩¦▓╗├¶ĖąĪŻ
«öśŗĮ©øQ▓▀śõĢrŻ¼├┐┤╬Ęų┴čĢrŻ¼Č╝Å─╚½╠žš„║“▀xp╝»ųą▀x╚ĪméĆ▀MąąĘų┴čŻ¼ę╗░Ńm=sqrt(p)ĪŻ
ļSÖC╔Ł┴ų▓╗Ģ■│÷¼F▀^öM║ŽŻ¼ų╗꬜õĄ─éĆöĄŻ©BŻ®ūŃē“┤¾ĢrĢ■╩╣Ą├Õeš`┬╩ĮĄĄ═ĪŻ
Xgboost
į┌Kaggle▒╚┘ÉųąĄ─▒žéõ╦ŃĘ©Ż¼ī┘ė┌Gradient boostingĄ─Ė▀ą¦īŹ¼FĪŻ▓óŪęėąęįŽ┬╚²╠ÄĄ─Ė─▀MŻ║
(1). xgboostį┌─┐ś╦║»öĄųą’@╩ŠĄ─╝ė╔Ž┴╦š²ät╗»ĒŚŻ¼╗∙īW┴Ģ×ķCARTĢrŻ¼š²ät╗»ĒŚ┼cśõĄ─╚~ūė╣سcĄ─öĄ┴┐T║═╚~ūė╣سcĄ─ųĄėąĻPĪŻ
(2). GBųą╩╣ė├Loss Functionī”f(x)Ą─ę╗ļAī¦öĄėŗ╦Ń│÷é╬Üł▓Ņė├ė┌īW┴Ģ╔·│╔fm(x)Ż¼xgboost▓╗āH╩╣ė├ĄĮ┴╦ę╗ļAī¦öĄŻ¼▀Ć╩╣ė├Č■ļAī¦öĄĪŻ
(3). CART╗žÜwśõŻ©GBŻ®ųąīżšęūŅ╝čĘųĖŅ³cĄ─║Ō┴┐ś╦£╩╩ŪūŅąĪ╗»Š∙ĘĮ▓ŅŻ¼xgboostīżšęĘųĖŅ³cĄ─ś╦£╩╩ŪūŅ┤¾╗»Ż¼lamdaŻ¼gama┼cš²ät╗»ĒŚŽÓĻPĪŻ
AdaBoost
═©▀^Ą³┤·īŹ¼F░č╚§ĘųŅÉŲ„ė¢ŠÜ│╔ÅŖĘųŅÉŲ„Ż¼├┐ę╗┤╬Ą³┤·║¾Ģ■ī”Õeš`öĄō■Ą─ĻPūóČ╚Ė³Ė▀Ż©▓▀┬į×ķūŅąĪ╗»ĘųŅÉš`▓Ņ┬╩Ż®Ż¼╩╣Ą├Ž┬ę╗éĆ╗∙īW┴ĢŲ„Ģ■ī”╔Ž┤╬Ą³┤·öĄō■Ė³ėąĖ³ČÓĄ─ßśī”ąįŻ¼ūŅĮKśŗĮ©│╔ĖĮĦÖÓųžĄ─ŠĆąįĮM║Ž╝»│╔īW┴ĢĪŻ
į┌öĄō■ŪÕŽ┤Ė╔ā¶Ą─ŪķørŽ┬Ż¼ą¦╣¹Ģ■Ė³║├ĪŻ
4.─Żą═ąį─▄
4.1 Recallš┘╗ž┬╩
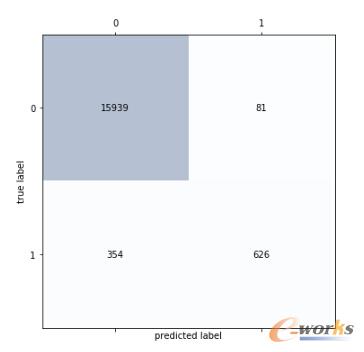
4.2AccuracyŻ║97.44%
5.░č─Ż║²Ą─ąąśIĮø“×ūāĄ├Ė³┐ŲīWŻ¼Ė³Š½£╩Ż║
Ė∙ō■─Żą═ŅA£yĮY╣¹ėŗ╦Ń│÷ė░Ēæ¤ß▀węŲĄ─ųžę¬ųĖś╦Ż║
CPU╩╣ė├┬╩ī”¤ß▀węŲ│╔╣”ūŅĻPµIŻ¼Ųõ┤╬╩Ū░³Ą─▀M│÷┴„┴┐Ż¼┤┼▒Pūx╚Ī╦┘┬╩Ę┤Č°ė░Ēæ┴”║▄Ą═ĪŻ
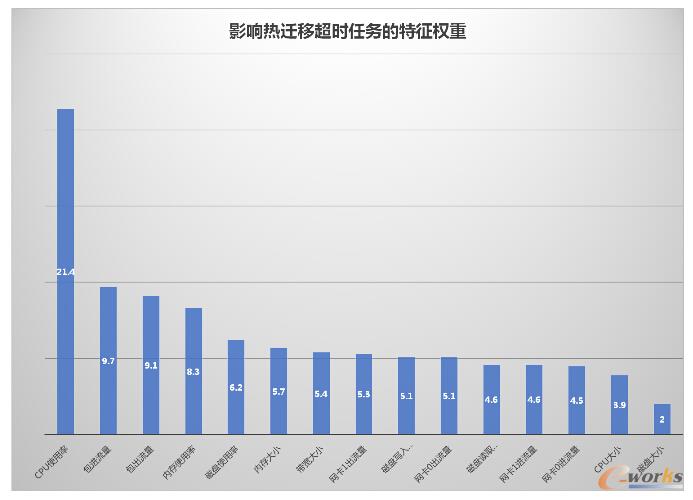
ė╔łD╬ęéā┐╔ęį┐┤ĄĮcpu╩╣ė├┬╩ī”¤ß▀węŲ│╔╣”┼cʱĄ─ė░Ēæ┴”š╝▒╚╚źĄĮ21.4%Ż¼’@ų°Ė▀ė┌Ųõ╦¹╠žš„ģóöĄŻ¼▀@ę▓╩ŪĘ¹║Ž╚╦Ą─Įø“×▀ē▌ŗĄ─Ż¼
«öę╗┼_ūėÖCcpu╩╣ė├┬╩š╝ė├▀_ĄĮę╗Č©▒╚└²ų«║¾Ż¼╚ń╣¹║¾┼_į┘░lŲ¤ß▀węŲ▒ž╚╗Ģ■š╝ė├▓┐ĘųŽĄĮy┘Yį┤Ż¼
Č°ą╬│╔¤ß▀węŲ│¼Ģr═∙═∙ę▓╩Ūę“×ķø]ėąūŃē“┘Yį┤▀MąąĒææ¬ĪŻ
Ųõ┤╬╬ęéā┐╔ęį┐┤ĄĮ▀M│÷░³┴┐Ą─ė░Ēæ┴”╩Ū═¼Ą╚Ż©9.7%Ż¼ 9.1%Ż®Ż¼į┘╚╗║¾╩Ūā╚┤µ╩╣ė├┬╩(8.3%)ęį╝░┤┼▒P╩╣ė├┬╩(6.2%)ĪŻ
┐╔ęįūóęŌĄĮĄ─╩Ū▀M│÷░³┴┐Ą─ė░Ēæ┴”▒╚╬ęéāŽļŽ¾Ą─ę¬Ė▀║▄ČÓŻ¼Č°┤┼▒Pūx╚Ī╦┘┬╩(4.6%)Ż¼┤┼▒Pīæ╚ļ╦┘┬╩(5.1%)Ą─ųžę¬ąįģsę¬▒╚╬ęéāŽļŽ¾Ą─Ą═Ż¼
▀@śėĄ─Ę┤üĮY╣¹Ė∙ō■╬ęéāĄ─ų▒ė^Įø“×╩Ū¤oĘ©½@Ą├Ą─ĪŻ
į┘═∙║¾¤ß▀węŲ░lŲ╚╬äšųąŻ¼╬ęéāę▓┐╔ęįę└ō■ęį╔ŽĄ─Ęų╬÷ĮY╣¹Ż¼
╚ń╣¹▀węŲ▓▀┬į─▄ē“╠ßŪ░Ęų┼õŅ~═Ō┘Yį┤Ż©cpuŻ¼memŻ¼▀M│÷ĦīÆŻ®ĮoĄĮ▀węŲī”Ž¾Ż¼ŽÓą┼Ģ■┤¾┤¾£p╔┘¤ß▀węŲ│¼Ģr╩¦öĪĄ─ŪķørĪŻ
6.║¾└mĖ─▀M
6.1Įø“×┐éĮY
į┌īŹļH╣ż│╠īŹ╩®ųąŻ¼│²┴╦─Żą═Ą─śŗĮ© ╠žš„╠Ä└Ēęį═ŌŻ¼Ą┌ę╗▓ĮĄ─öĄō■╩š╝»Ż¼▌ö╚ļģóöĄ┐šķgĄ─śŗįņČ╝╩Ūų┴ĻPųžę¬Ą─Ż¼öĄō■╝»Ą─┤¾ąĪęį╝░┘|┴┐ų▒ĮėøQČ©┴╦─Żą═ąį─▄Ą─╔ŽŽ▐ĪŻę╗ĘĮ├µ│²┴╦╩š╝»īŹ█`Įø“×┼ąöÓŽÓĻPĄ─ųžę¬ģóöĄŻ¼┴Ēę╗ĘĮ├µę▓▓╗─▄╚ź║åå╬┼┼│²Ųõ╦¹┐┤ŲüĒ╦Ų║§▓╗ŽÓĖ╔Ą─╠žš„ģóöĄŻ¼ę“×ķ═∙═∙┼ąöÓĮY╣¹ėą┐╔─▄┼c╚╦Ą─ų▒ėXŽÓū¾ėęŻ¼┐éų«▒M┐╔─▄Ą─╩š╝»╦∙ėąŽÓĻPģóöĄŻ¼╚╗║¾į┘═©▀^╠žš„╣ż│╠▀Mąą║Y▀x╚źųž╩Ū▒╚▌^║Ž└ĒĄ─ū÷Ę©ĪŻ
į┌▒Š┤╬ŅA£y─Żą═śŗįņųąŻ¼öĄō■ŅA╠Ä└Ē╚ź│²┼KöĄō■Ż¼╚▒╩¦öĄō■║¾╩ŻŽ┬Ą─žōśė▒ŠöĄ┴┐▀Ć╠Äį┌5k╝ēäeŻ¼ę╗░ŃČ°čįī”ė┌ę╗éĆÖCŲ„īW┴Ģ╚╬äš śė▒ŠöĄ┴┐╝ēäe▀_ĄĮ10╚féĆ╩Ū▒╚▌^║Ž▀mĄ─Ż¼
┴Ē═Ō─┐Ū░š²žōśė▒Š▒╚└²▓╗Š∙║Ōę▓Įo─Żą═ąį─▄Ą─╠ß╔²║═ŅA£yĦüĒ║▄┤¾└¦ļyŻ¼▀@éĆå¢Ņ}ŽÓą┼░ķļSöĄō■┴┐Ą─į÷ķLęį╝░Ė─╔Ų▓╔╝»öĄō■╚▒╩¦Ūķør║¾Ģ■Ą├ĄĮ▌^┤¾Ė─╔ŲĪŻ
6.2 ║¾Ų┌š╣═¹
▓┐╩ā×╗»
į┌║¾Ų┌ā×╗»ųąŻ¼Ģ■┬ō═©╬ęéāĄ─öĄō■é}ÄņCDWīŹ¼FöĄō■ūįäė▓╔╝»Ż¼─Żą═ūįäėė¢ŠÜęį╝░ūįäė▓┐╩ĪŻ
╣”─▄öUš╣
į┌║¾└m¤ß▀węŲ╝╝ągĖ─▀MųąŻ║╬ęéāĢ■Ė∙ō■į┌▓╗═¼Ą─┘Yį┤╝s╩°║═VM╣żū„žō▌dŽ┬╚źŅA£y▓╗═¼īŹĢr▀węŲ╦ŃĘ©Ą─ĻPµIģóöĄĪŻī”╗∙ė┌īŹĢr▀węŲ╦ŃĘ©Ą─▀węŲ╚╬䚯¼śŗĮ©ÖCŲ„īW┴Ģ─Żą═ŅA£y▀węŲ╚╬䚥─┐é▀węŲĢrķgŻ¼═ŻÖCĢrķgęį╝░é„▌öĄ─┐éöĄō■┴┐ĪŻ
7.╝╝ąg┐“╝▄
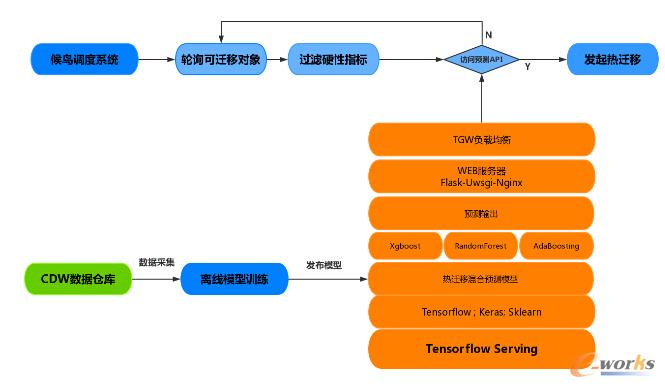
ų„ę¬░³║¼ServingĘ■äš┐“╝▄Ż¼Modelé}ÄņŻ¼WEBĘ■äšīėŻ¼║¾Ų┌Ą─╦∙ėąŅA£yĘ■äš/öĄō■═┌Š“Ęų╬÷Č╝īóį┌▀@éĆ┐“╝▄Ž┬▀\ąąŻ¼▓╗Ž▐ė┌öĄō■▓╔╝» ─Żą═ė¢ŠÜ ░µ▒Š╣▄└Ēęį╝░▓┐╩░l▓╝ĪŻ
TensorFlow Serving
╩Ūę╗éĆ╣żśI╝ē┐╔ė├ė┌ÖCŲ„īW┴Ģ─Żą═ serving Ą─Ė▀ąį─▄ķ_į┤ÄņĪŻ╦³┐╔ęįīóė¢ŠÜ║├Ą─ÖCŲ„īW┴Ģ─Żą═▓┐╩ĄĮŠĆ╔ŽŻ¼╩╣ė├ gRPC ū„×ķĮė┐┌Įė╩▄═Ō▓┐š{ė├ĪŻīótensorflowė¢ŠÜ│÷üĒĄ──Żą═Ė³║├Ą─æ¬ė├į┌╔·«aŁhŠ│ųąŻ¼═©▀^APIĄ╚Ą╚ų¦│ųĄ─ĘĮ╩ĮüĒĘĮ▒Ńī”═Ō╠ß╣®ĘĆČ©┐╔┐┐Ą─Ę■äš
WEBĘ■äšŲ„ĮYśŗ
Flask-uWsgi-NginxŻ║ Flaskžōž¤╚╬äšš{Č╚Ż¼uWsgi-Nginxžō▌d▐D░lŻ¼
─┐Ū░ęčīŹ¼F3┼_ÖCŲ„╚▌×─▓┐╩Ż¼Įyę╗Įė╚ļTGWīŹ¼Fžō▌dŠ∙║ŌĪŻ
TensorflowClient
ų„꬞ōž¤┼cTensorflowServing═©ą┼║═š{ė├─Żą═apiŻ¼═©▀^š{ė├TensorFlow Serving Ą─ Predict API ║═ gRPC Ą─ implementations.insecure_channel Å─Č°śŗĮ©ę╗éĆ requestĪŻ
8.Įė╚ļ┴„│╠Ż║
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║╗∙ė┌╗ņ║Ž╝»│╔īW┴Ģ╦ŃĘ©Ą─¤ß▀węŲ│¼ĢrŅA£y─Żą═
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/solutions/14019321357.html






















