



ę╗Īó▒│Š░║═Ė┼ør
į┌2015─Ļ─®Ż¼×ķ┴╦ĮŌøQĖ„ŅÉśI(y©©)äš(w©┤)┤¾┴┐Ą─┼┼ąą░±Ą─ąĶŪ¾Ż¼╬ęéā╗∙ė┌redisīŹ¼F(xi©żn)┴╦ę╗éĆ═©ė├Ą─┼┼ąą░±Ę■äš(w©┤)Ż¼┴╝║├ĮŌøQ┴╦Ė„ŅÉśI(y©©)äš(w©┤)Ą─═┤³cŻ¼Ą½╩ŪļSų°śI(y©©)äš(w©┤)░l(f©Ī)š╣ĄĮ2016─ĻųąŻ¼Ųõųąę╗éĆśI(y©©)äš(w©┤)Š═╔Ļšł┴╦öĄ(sh©┤)░┘╚f┼┼ąą░±Ż¼▓óļSų°į÷ķL┌ģä▌Ż¼ŲŲŪ¦╚fųĖ╚š┐╔┤²Ż¼═¼ĢrĖ„śI(y©©)äš(w©┤)ę▓ŽŻ═¹─▄ų▒Įė╩╣ė├redisžSĖ╗öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)üĒĮŌøQĖ³ČÓå¢Ņ}(╚ń┤µā”ĻP(gu©Īn)ĻP(gu©Īn)ŽĄµ£ĪóĄž└Ē╬╗ų├Ą╚)ĪŻ
«öĢr├µ┼RĄ─å¢Ņ}┼c╠¶æ(zh©żn)╚ńŽ┬Ż║
- ┼┼ąą░±Ę■äš(w©┤)¤oĘ©ų¦ō╬Ū¦╚f╝ē┼┼ąą░±öĄ(sh©┤)(┼┼ąą░±ĄĮredisīŹ└²ė│╔õĻP(gu©Īn)ŽĄ┤µā”į┌zookeeperŻ¼zookeeper╚▌┴┐Ų┐Ņi)
- å╬ÖC╚▌┴┐¤oĘ©ØMūŃĻP(gu©Īn)ŽĄµ£Ą╚śI(y©©)äš(w©┤)ąĶŪ¾
- ┼┼ąą░±║═ĻP(gu©Īn)ŽĄµ£┤¾▓┐Ęų┤¾ė┌1MŻ¼═¼Ģr┤µį┌│¼┤¾key(>512M)Ż¼ąĶų¦│ų│¼┤¾key▀węŲ
- SNGĄ─Grocery┤µā”ĮM╝■Ż¼ų¦│ųredisģf(xi©”)ūhŻ¼Ą½ėų┤µį┌å╬key value┤¾ąĪ1MĄ─Ž▐ųŲ
- Ė▀┐╔ė├Ż¼ąĶę¬ų¦│ųredisų„éõūįäėŪąōQ
- SNGöĄ(sh©┤)ō■(j©┤)▀\ŠSĮM╬┤╠ß╣®redis╝»╚║░µĮė╚ļĘ■äš(w©┤)Ż¼į┌┴Ń▀\ŠSĄ─ų¦│ųŽ┬╚ń║╬Ė▀ą¦ų╬└Ē▒ŖČÓśI(y©©)äš(w©┤)╝»╚║Ż┐
├µī”ęį╔Ž╠¶æ(zh©żn)Ż¼Įø(j©®ng)▀^ČÓŠSČ╚Ą─ĘĮ░Ė▀xą═ī”▒╚Ż¼ūŅĮK▀xō±┴╦╗∙ė┌codis(3.x░µ▒Š)Ż¼ĮY(ji©”)║Žā╚(n©©i)▓┐ąĶŪ¾║═▀\ĀIŁh(hu©ón)Š│▀Mąą┴╦Č©ųŲ╗»Ė─įņŻ¼Įžų╣ĄĮ─┐Ū░Ż¼│§▓ĮīŹ¼F(xi©żn)┴╦ę╗éĆų¦│ųå╬ÖC/Ęų▓╝╩Į┤µā”ĪóŲĮ╗¼öU┐s╚▌Īó│¼┤¾key▀węŲĪóĖ▀┐╔ė├ĪóśI(y©©)äš(w©┤)ūįäė╗»Įė╚ļš{(di©żo)Č╚▓┐╩ĪóČÓŠSČ╚▒O(ji©Īn)┐žĪó┼õų├╣▄└ĒĪó╚▌┴┐╣▄└ĒĪó▀\ĀIĮy(t©»ng)ėŗĄ─redisĘ■äš(w©┤)ŲĮ┼_Ż¼į┌CMEMĪóGrocery▓╗─▄ØMūŃśI(y©©)äš(w©┤)ąĶŪ¾Ą─ł÷Š░Ž┬Ż¼Įė╚ļ┴╦SNGį÷ųĄ«a(ch©Żn)ŲĘ▓┐Ą╚╬Õ┤¾▓┐ķTĮ³30+śI(y©©)äš(w©┤)╝»╚║(łDę╗)Ż¼350+īŹ└²Ż¼ 2T+╚▌┴┐ĪŻ
Ž┬╬─īóÅ─ĘĮ░Ė▀xą═Īóš¹¾w╝▄śŗ(g©░u)Īóūįäė╗»Įė╚ļĪóöĄ(sh©┤)ō■(j©┤)▀węŲĪóĖ▀┐╔ė├Īó▀\ĀIīŹ█`Ą╚ĘĮ├µįö╝ÜĮķĮB╬ęéāį┌╔·«a(ch©Żn)Łh(hu©ón)Š│ųąĄ─īŹ█`ŪķørĪŻ

łDę╗ ▓┐ĘųĮė╚ļśI(y©©)äš(w©┤)┴ą▒Ē
Č■ĪóĘĮ░Ė▀xą═
Redisę“ŲõžSĖ╗Ą─öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)Īóęūė├ąįįĮüĒįĮ╩▄ĄĮÅV┤¾ķ_░l(f©Ī)š▀ÜgėŁŻ¼Ė∙ō■(j©┤)DB-EnginesĄ─ūŅą┬Įy(t©»ng)ėŗŻ¼ęčĮø(j©®ng)╩ŪĘĆ(w©¦n)ŠėöĄ(sh©┤)ō■(j©┤)Äņ«a(ch©Żn)ŲĘĄ─top10Ż©ęŖłDę╗)ĪŻįŲėŗ╦ŃĘ■äš(w©┤)«a(ch©Żn)╔╠AWSĪóAZUREĪó░ó└’įŲĪó“vėŹįŲČ╝╠ß╣®┴╦Redis«a(ch©Żn)ŲĘŻ¼Ė„įŲėŗ╦Ń«a(ch©Żn)╔╠ų„┴„ĘĮ░ĖČ╝╩Ū╗∙ė┌ķ_į┤Redisā╚(n©©i)║╦ū÷Č©ųŲ╗»ā×(y©Łu)╗»Ż¼ĮŌøQRedis▓╗ūŃų«╠ÄŻ¼į┌╠ß╔²RedisĘĆ(w©¦n)Č©ąįĪóąį─▄Ą─═¼ĢrūŅ┤¾│╠Č╚╝µ╚▌ķ_į┤RedisĪŻå╬ÖCų„éõ░µĖ„ÅS╔╠▓Ņ«É▓╗┤¾Ż¼Č╝╩Ū╗∙ė┌įŁ╔·Redisā╚(n©©i)║╦Ż¼Ą½╩Ū╝»╚║░µŻ¼AWS╩╣ė├Ą─įŁ╔·Ą─RedisūįĦĄ─Cluster Mode─Ż╩Į(╝ėÅŖ░µ)Ż¼Ż¼░ó└’įŲ╗∙ė┌ProxyĪóįŁ╔·Redisā╚(n©©i)║╦īŹ¼F(xi©żn)Ż¼┬Ęė╔Ą╚į¬┤µā”öĄ(sh©┤)ō■(j©┤)▒Ż┤µį┌RDSŻ¼╝▄śŗ(g©░u)ŅÉ╦ŲCodisŻ¼ “vėŹįŲ╝»╚║░µ╩Ū╗∙ė┌ā╚(n©©i)▓┐GroceryĪŻ┴╦ĮŌ═ĻįŲėŗ╦Ń«a(ch©Żn)╔╠ĮŌøQĘĮ░ĖŻ¼į┘┐┤śI(y©©)Įńķ_į┤Īó╣½╦Šā╚(n©©i)▓┐Ż¼╔Ž╬─╠ߥĮ╬ęéā├µ┼Rå¢Ņ}ų«ę╗Š═╩Ūå╬ÖC╚▌┴┐Ų┐ŅiŻ¼ę“┤╦ąĶę¬ę╗┐Ņ╝»╚║░µ«a(ch©Żn)ŲĘŻ¼─┐Ū░śI(y©©)Įńķ_į┤Ą─ų„┴„Ą─Redis╝»╚║ĮŌøQĘĮ░ĖėąCodisŻ¼Redis ClusterŻ¼TwemproxyŻ¼╣½╦Šā╚(n©©i)▓┐Ą─ėąSNG GroceryĪóIEGĄ─TRedisŻ¼Å─ęįŽ┬ÄūéĆŠSČ╚▀Mąąī”▒╚Ż¼įö╝ÜĮY(ji©”)╣¹╚ń▒Ēę╗╦∙╩Š(2016─Ļ10į┬ĢröĄ(sh©┤)ō■(j©┤))Ż║
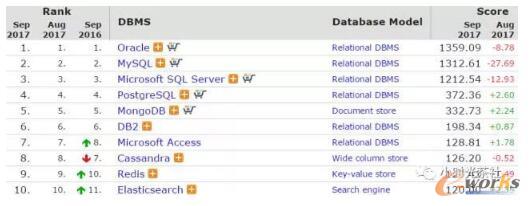
łDČ■ öĄ(sh©┤)ō■(j©┤)Äņ┴„ąąČ╚┼┼├¹
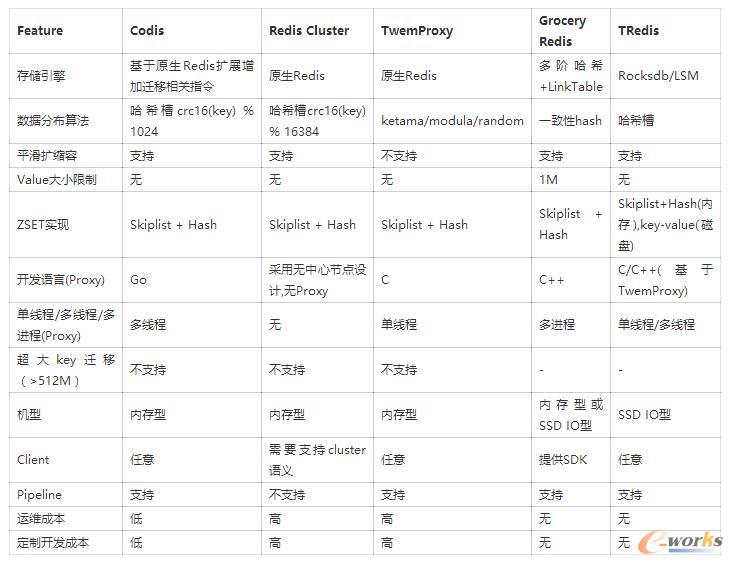
▒Ēę╗ Redis╝»╚║«a(ch©Żn)ŲĘī”▒╚
įŲėŗ╦Ń«a(ch©Żn)╔╠║═śI(y©©)Įńķ_į┤Īó╣½╦Šā╚(n©©i)▓┐Ą─ĮŌøQĘĮ░ĖÅ─š¹¾w╝▄śŗ(g©░u)ĘųŅÉŻ¼Ęųäe╩Ū╗∙ė┌Proxyųąą─╣Ø(ji©”)³c║═¤oųąą─╣Ø(ji©”)³cŻ¼į┌▀@³c╔Ž╬ęéāĖ³Ų½É█╗∙ė┌Proxyųąą─╣Ø(ji©”)³c╝▄śŗ(g©░u)įO(sh©©)ėŗŻ¼▀\ŠS│╔▒ŠĖ³Ą═ĪóĖ³╝ė┐╔┐žŻ¼Å─┤µā”ę²ŪµĘųŅÉŻ¼Ęųäe╩Ū╗∙ė┌įŁ╔·Redisā╚(n©©i)║╦║═Ą┌╚²ĘĮ┤µā”ę²ŪµŻ©╚ńGroceryĄ─ČÓļAHASH+LinkTableĪóTRedisĄ─Rocksdb)Ż¼į┌▀@³c╔Ž╬ęéāĖ³Ų½É█╗∙ė┌įŁ╔·Redisā╚(n©©i)║╦Ż¼ę“×ķ╬ęéāę¬ĮŌøQśI(y©©)äš(w©┤)ł÷Š░Š═╩ŪGrocery║═CMem¤oĘ©ØMūŃĄ─ĄžĘĮŻ¼╬ęéāśI(y©©)äš(w©┤)┤¾▓┐Ęų╩╣ė├Ą─öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)╩ŪZSETŪęKeyę╗░Ń│¼▀^1MŻ¼Äū╩«╚f╝ēį¬╦žĄ─ZSET Key╩Ū│ŻæB(t©żi)Ż¼GroceryĄ─Value 1M┤¾ąĪŽ▐ųŲ¤oĘ©ØMūŃ╬ęéāĄ─ąĶŪ¾Ż¼═¼Ģr╬ęéāąĶę¬ZSETĄ─ZRankĄ─ĢrķgÅ═(f©┤)ļsČ╚╩ŪO(LogN)Ż¼╗∙ė┌RocksDbĄ─┤µā”ę²ŪµĢrķgÅ═(f©┤)ļsČ╚╩ŪO(N)Ż¼ę“┤╦▀@ę▓╩Ū¤oĘ©Įė╩▄Ą─ĪŻļSų°śI(y©©)äš(w©┤)░l(f©Ī)š╣Ż¼╚▌┴┐ä▌▒žĢ■░l(f©Ī)╔·ūā╗»Ż¼ę“┤╦öU┐s╚▌╩Ū│ŻæB(t©żi)Ż¼Č°TwemProxy▓ó▓╗ų¦│ųŲĮ╗¼öU┐s╚▌Ż¼ę“┤╦ę▓¤oĘ©ØMūŃę¬Ū¾ĪŻūŅ║¾Ż¼╬ęéāąĶę¬ĮY(ji©”)║Žā╚(n©©i)▓┐▀\ĀIŁh(hu©ón)Š│║═ąĶŪ¾ū÷Č©ųŲ╗»Ė─įņŻ¼į┌┴Ń▀\ŠSĄ─ų¦│ųŽ┬Ż¼═©▀^╝╝ąg(sh©┤)╩ųČ╬Ż¼ūŅ┤¾│╠Č╚ūįäė╗»ų╬└ĒĪó▀\ĀI▒ŖČÓČÓśI(y©©)äš(w©┤)╝»╚║Ż¼Č°Codis┤·┤aĮY(ji©”)śŗ(g©░u)ŪÕ╬·Ż¼ķ_░l(f©Ī)šZčįėų╩Ū¼F(xi©żn)į┌▒╚▌^┴„ąąĄ─GoŻ¼¤ošō╩Ū▀\ąąąį─▄Īó▀Ć╩Ūķ_░l(f©Ī)ą¦┬╩Č╝▌^Ė▀ą¦Ż¼ę“┤╦╬ęéāūŅĮK▀xō±┴╦Codis.
╚²Īóš¹¾w╝▄śŗ(g©░u)
╗∙ė┌CodisČ©ųŲķ_░l(f©Ī)Č°│╔Ą─RedisĘ■äš(w©┤)ŲĮ┼_š¹¾w╝▄śŗ(g©░u)╚ńłDČ■╦∙╩ŠŻ¼Ųõ░³║¼ęįŽ┬ĮM╝■Ż║
- ProxyŻ║īŹ¼F(xi©żn)┴╦Redisģf(xi©”)ūhŻ¼│²╔┘öĄ(sh©┤)├³┴Ņ▓╗ų¦│ų═ŌŻ¼ī”═Ō▒Ē¼F(xi©żn)║═įŁ╔·Redisę╗śėĪŻĮŌ╬÷šłŪ¾ĢrŻ¼ėŗ╦Ńkeyī”æ¬(y©®ng)Ą─╣■ŽŻ▓█Ż¼īóšłŪ¾Ęų░l(f©Ī)ĄĮī”æ¬(y©®ng)Ą─RedisŻ¼śI(y©©)äš(w©┤)═©▀^L5/CMLB▀MąąīżųĘĪŻ
- RedisŻ║ Redisį┌ā╚(n©©i)┤µųąīŹ¼F(xi©żn)┴╦string/list/hash/set/zsetĄ╚öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)Ż¼ī”═Ō╠ß╣®öĄ(sh©┤)ō■(j©┤)ūxīæĘ■äš(w©┤)Īó│ųŠ├╗»Ą╚Ż¼─¼šJę╗ų„ę╗éõ▓┐╩ĪŻ
- DashbOArdŻ║╠ß╣®╣▄└Ē╝»╚║Ą─API║═įLå¢į¬öĄ(sh©┤)ō■(j©┤)┤µā”Ą─═©ė├APIŻ©CURD▓┘ū„Ż¼Ų┴▒╬║¾Č╦į¬öĄ(sh©┤)ō■(j©┤)┤µā”▓Ņ«ÉŻ®ĪŻ
- Zk/Etcd/MysqlŻ║Ą┌╚²ĘĮį¬öĄ(sh©┤)ō■(j©┤)┤µā”Ż¼▒Ż┤µ╝»╚║Ą─proxyĪóredisĪóĖ„╣■ŽŻ▓█ī”æ¬(y©®ng)Ą─redis ĄžųĘĄ╚ą┼ŽóĪŻ
- HAŻ║╗∙ė┌Redis SentinelīŹ¼F(xi©żn)Redisų„éõĖ▀┐╔ė├Ż¼▓┐╩į┌ČÓéĆIDCŻ¼▓╔ė├QuorumÖCųŲĪóĀŅæB(t©żi)ÖC▀Mąąų„éõūįäėŪąōQĪŻ
- SchedulerŻ║š{(di©żo)Č╚Ę■äš(w©┤)Ż¼žōž¤ī”śI(y©©)äš(w©┤)Įė╚ļ╔Ļšłå╬▀Mąąūįäėš{(di©żo)Č╚▓┐╩Īó╝»╚║ūįäė╗»öU╚▌ĪóĖ„╝»╚║▀\ĀIöĄ(sh©┤)ō■(j©┤)Įy(t©»ng)ėŗĄ╚ĪŻ
- ▀\ŠS╣▄└ĒŽĄĮy(t©»ng)Ż║ Web┐╔ęĢ╗»╣▄└Ē╝»╚║Ż¼╠ß╣®śI(y©©)äš(w©┤)Įė╚ļĪó╝»╚║╣▄└ĒĪó╚▌┴┐╣▄└ĒĪó┼õų├╣▄└ĒĄ╚╣”─▄ĪŻ
- CDBŻ║┤µā”śI(y©©)äš(w©┤)╔Ļšłå╬ĪóĖ„╣Ø(ji©”)³c╚▌┴┐Ą╚ą┼ŽóĪŻ
- AgentŻ║žōž¤Č©Ģr▒O(ji©Īn)┐ž║═▓╔╝»RedisĪóProxyĪóDashboard▀\ąąĮy(t©»ng)ėŗą┼ŽóŻ¼╔Žł¾ĄĮ├ūĖ±▒O(ji©Īn)┐žŽĄĮy(t©»ng)║═CDBĪŻ
- HDFSŻ║└õéõ╝»╚║Ż¼Redis└õéõ╬─╝■├┐╠ņĢ■Č©Ģr╔Žé„ĄĮHDFSŻ¼╠ß╣®ĮośI(y©©)äš(w©┤)Ž┬▌d║═į┌ų„éõĮį╣╩šŽĄ─ŪķørŽ┬ū÷öĄ(sh©┤)ō■(j©┤)╗ųÅ═(f©┤)╩╣ė├ĪŻ
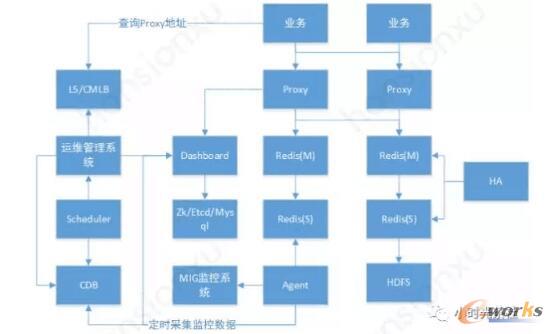
łD╚² š¹¾w╝▄śŗ(g©░u)
╦─Īóūįäė╗»Įė╚ļ
«ö├µī”│╔░┘╔ŽŪ¦─╦ų┴╔Ž╚féĆRedisīŹ└²ĢrŻ¼╚╦╣żĖ∙ō■(j©┤)śI(y©©)äš(w©┤)╔Ļšłå╬╚ź▀^×V¤oą¦╣Ø(ji©”)³cĪó║Y▀xĘ¹║ŽśI(y©©)äš(w©┤)ę¬Ū¾Ą─╣Ø(ji©”)³cĪóį┘Å─║“▀x╣Ø(ji©”)³cųąšę│÷ūŅā×(y©Łu)╣Ø(ji©”)³cĄ╚ł╠(zh©¬)ąąę╗ą®┴ąĘ▒¼Ź┐▌į’┴„│╠Ż¼▀@▓╗āHĢ■ī¦(d©Żo)ų┬╣żū„Ę”╬ČĪóą¦┬╩Ą═Ż¼Č°ŪęĖ³Ģ■┤¾┤¾╠ß╔²ŽĄĮy(t©»ng)Ą─▓╗ĘĆ(w©¦n)Č©ąįŻ¼ę²░l(f©Ī)▀\ĀI╩┬╣╩ĪŻ«öĘ▒¼ŹĪóÅ═(f©┤)ļsĄ─┴„│╠ūā│╔ūįäė╗»║¾Ż¼╣żū„Š═Ģ■ūāĄ├│õØMśĘ╚żŻ¼łD╚²╩ŪśI(y©©)äš(w©┤)Įė╚ļš{(di©żo)Č╚┴„│╠Ż¼ė├æ¶į┌▀\ŠS╣▄└ĒŽĄĮy(t©»ng)╠ßå╬Įė╚ļ║¾Ż¼š{(di©żo)Č╚Ų„Ģ■Č©ĢrÅ─CDBųąūx╚Ī┤²š{(di©żo)Č╚Ą─śI(y©©)äš(w©┤)╔Ļšłå╬Ż¼╩ūŽ╚╩Ū║Y▀x▀^×V┴„│╠Ż¼┤╦┴„│╠░³║¼ę╗ŽĄ┴ą─ŻēKŻ¼į┌įO(sh©©)ėŗ╔Ž╩Ū┐╔ęįäėæB(t©żi)öUš╣Ż¼─┐Ū░īŹ¼F(xi©żn)Ą─║Y▀x─ŻēK╚ńŽ┬Ż║
HealthŻ║ ĮĪ┐Ą╠Į£y─ŻēKŻ¼▀^×VÕ┤ÖCĪó▓├£yŽ┬ŠĆĄ─╣Ø(ji©”)³cIP
LableŻ║ś╦║×?z©Īi)ŻēKŻ¼Ė∙ō■(j©┤)śI(y©©)äš(w©┤)╔Ļšłå╬Ųź┼õ▓┐╩Łh(hu©ón)Š│(£yįćĪó¼F(xi©żn)ŠW(w©Żng))Īó▓┐╩│Ū╩ąĪóśI(y©©)äš(w©┤)─ŻēKĪóRedis┤µā”ŅÉą═(å╬ÖC░µĪóĘų▓╝╩Į┤µā”░µŻ®
InstanceŻ║ Öz▓ķ«öŪ░╣Ø(ji©”)³c╔Ž╩Ūʱėą┐šėÓĄ─RedisīŹ└²(║Y▀xRedisīŹ└²Ģr)
CapacityŻ║ Öz▓ķ«öŪ░╣Ø(ji©”)³cCPUĪóMemory╩Ūʱ│¼▀^░▓╚½ķyųĄ
RoleŻ║Öz▓ķ«öŪ░╣Ø(ji©”)³cĮŪ╔½╩ŪʱØMūŃę¬Ū¾(╚ńRedisīŹ└²╦∙ī┘╣Ø(ji©”)³cÖCŲ„▒žĒÜ╩ŪRedis Node)Ż¼ĮŪ╔½Ęų×ķ╚²ŅÉProxy NodeŻ¼Redis NodeŻ¼Dashboard Node
ęį╔Ž║Y▀x─ŻēKŻ¼▀mė├ProxyĪóRedisĪóDashboard╣Ø(ji©”)³cĄ─║Y▀xŻ¼į┌═Ļ│╔ęį╔Ž║Y▀x─ŻēK║¾Ż¼ĘĄ╗žĄ─╩ŪĘ¹║Žę¬Ū¾Ą─║“▀x╣Ø(ji©”)³cŻ¼ī”║“▀x╣Ø(ji©”)³c╬ęéāėųąĶę¬ī”ŲõįuĘųŻ¼Å─ųąįu│÷ūŅā×(y©Łu)╣Ø(ji©”)³cŻ¼─┐Ū░īŹ¼F(xi©żn)Ą─įuĘų─ŻēKėąūŅąĪā╚(n©©i)┤µš{(di©żo)Č╚ĪóūŅ┤¾ā╚(n©©i)┤µš{(di©żo)Č╚ĪóūŅąĪCPUš{(di©żo)Č╚ĪóļSÖCš{(di©żo)Č╚Ą╚ĪŻ
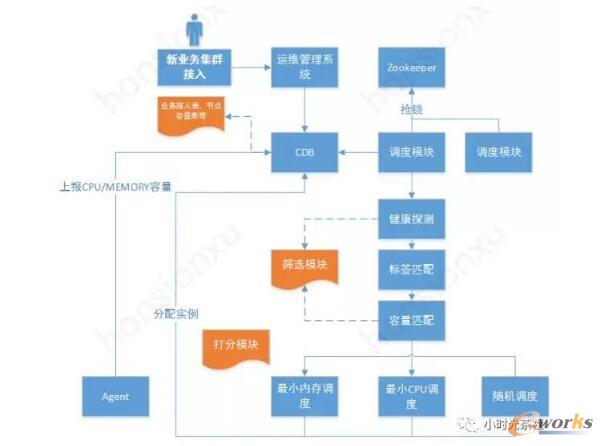
łD╦─ śI(y©©)äš(w©┤)Įė╚ļš{(di©żo)Č╚┴„│╠
═©▀^▀\ąąęį╔Žę╗ŽĄ┴ą║Y▀x║═įuĘų─ŻēK║¾Ż¼Š═┐╔ęį£╩┤_Īó┐ņ╦┘Ą─½@╚ĪĄĮą┬╝»╚║Ą─DashboardĪóProxyĪóRedisĄ─▓┐╩╣Ø(ji©”)³cĄžųĘŻ¼Ą½╩Ūļxūįäė╗»Į╗ĖČĮośI(y©©)äš(w©┤)╩╣ė├▀Ć▓Ņę╗éĆųžę¬Łh(hu©ón)╣Ø(ji©”)(▓┐╩)ĪŻ─┐Ū░ų„ę¬╩Ū═©▀^ęįŽ┬╚²éĆĘĮ├µüĒĮŌøQūįäė╗»▓┐╩Ż¼Ųõę╗Ż¼Codis▒Š╔Ē╩Ū╗∙ė┌┼õų├╬─╝■▓┐╩Ą─Ż¼├┐ą┬į÷ę╗éĆśI(y©©)äš(w©┤)╝»╚║▒žĒÜį┌┼õų├╬─╝■ųĖČ©╝»╚║├¹ūųŻ¼ą┬Į©ę╗éĆPKG░³Ż¼ŠSūo│╔▒ŠĘŪ│ŻĖ▀Ż¼╬ęéā═©▀^▒O(ji©Īn)┬ĀųĖČ©ŠW(w©Żng)┐©+║╦ą─┼õų├ĒŚ▀węŲĄĮZooKeeperŻ¼īŹ¼F(xi©żn)┼õų├╣▄└ĒAPI╗»Ż¼═¼Ģr▓┐╩░³ś╦£╩Įy(t©»ng)ę╗╗»ĪŻŲõČ■Ż¼į┌Ė„╣Ø(ji©”)³c╔ŽČ╝Ģ■▓┐╩AgentŻ¼AgentĢ■Č©Ģr▓╔╝»╔Žł¾Ė„╣Ø(ji©”)³cą┼Žó╚ļÄņĄĮ╚▌┴┐▒ĒŻ¼¤oąĶ╚╦╣żĖ╔ŅA(y©┤)Ż¼╚▌┴┐╣▄└Ēūįäė╗»Ż¼╬┤╩╣ė├Ą─īŹ└²ą╬│╔ę╗éĆąĪą═┘Yį┤buffer│žĪŻŲõ╚²Ż¼▓┐╩╩ŪéĆČÓļAČ╬Ą─┴„│╠Ż¼ąĶę¬ĘųĮŌ│╔Ė„ĀŅæB(t©żi)Ż¼▓ó▒ŻūC├┐éĆĀŅæB(t©żi)Č╝╩Ū┐╔ųž╚ļĪóāńĄ╚ąįĄ─Ż¼«ö╦∙ėąĀŅæB(t©żi)═Ļ│╔║¾Ż¼ätš{(di©żo)Č╚ĮY(ji©”)╩°Ż¼─│ĀŅæB(t©żi)╩¦öĪĢrŻ¼Ž┬┤╬š{(di©żo)Č╚Öz▓ķĄĮ╔Ļšłå╬ĘŪ═Ļ│╔ĀŅæB(t©żi)Ż¼Ģ■ūįäėųžįć╩¦öĪĄ─┴„│╠Ż¼ų▒ų┴═Ļ│╔Ż¼▓Ęų║¾Ą─▓┐╩ĀŅæB(t©żi)┴„│╠łD╚ńłD╦─╦∙╩ŠĪŻ
═©▀^ęį╔Žā╔éĆ║╦ą─┴„│╠Ż¼ūįäė╗»š{(di©żo)Č╚Ęų┼õīŹ└²+ūįäė╗»▓┐╩Ż¼╬ęéā┐╔ęįīó▓┐╩ĢrķgÅ─ūŅķ_╩╝Ą─15min+Ż¼ā×(y©Łu)╗»ĄĮ├ļ╝ēŻ¼į┌┤¾┤¾╠ß╔²╣żū„ą¦┬╩Ą─═¼ĢrŻ¼╠ß╔²┴╦ŽĄĮy(t©»ng)ĘĆ(w©¦n)Č©ąįĪó▒▄├Ō┴╦╚╦×ķ▓┘ū„Õeš`ę²ŲĄ─▀\ĀI╩┬╣╩ĪŻ
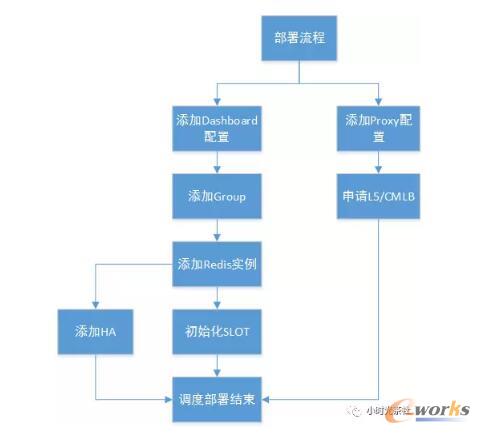
łD╬Õ ūįäė╗»▓┐╩┴„│╠
╬ÕĪóöĄ(sh©┤)ō■(j©┤)▀węŲ
öU┐s╚▌╩Ū┤µā”ŽĄĮy(t©»ng)Ą─│ŻÜw╗»▓┘ū„Ż¼└ĒŽļųąĄ─öĄ(sh©┤)ō■(j©┤)▀węŲæ¬(y©®ng)įō╩Ū▒M┴┐▓╗ė░ĒæŠĆ╔ŽśI(y©©)äš(w©┤)š²│ŻūxīæįLå¢Īóų¦│ų╚╬ęŌ┤¾ąĪĄ─KeyĪóā×(y©Łu)«ÉĄ─▀węŲąį─▄Īó▒ŻūC▀węŲŪ░║¾Ą─öĄ(sh©┤)ō■(j©┤)ę╗ų┬ąįŻ¼Ą½╩ŪCodisį┌2016─Ļ─®Ą─Ģr║“öĄ(sh©┤)ō■(j©┤)▀węŲ╣”─▄▓ŅÅŖ╚╦ęŌĪŻ╩ūŽ╚╩Ū▀węŲ╦┘Č╚┬²Ż¼Ųõ┤╬╩Ūų╗ų¦│ų═¼▓Į▀węŲŻ¼▌^┤¾Ą─Key▀węŲĢ■ūĶ╚¹Redisų„ŠĆ│╠Ż¼ė░ĒæŠĆ╔ŽśI(y©©)äš(w©┤)š²│ŻūxīæŻ¼ūŅ║¾╩Ū▓╗ų¦│ų│¼┤¾Key▀węŲ(>512M)ĪŻļm╚╗Ė„ĘNūŅ╝čīŹ█`▓╗öÓÅŖš{(di©żo)ąĶę¬▒▄├Ō┤¾KeyŻ¼Ą─┤_┤¾Key┐╔─▄Ģ■╩ŪŽĄĮy(t©»ng)Øōį┌Ą─ę╗éĆ’L(f©źng)ļU³c(╚ń┤¾keyäh│²Īó▀węŲĪó¤ß³cįLå¢Ą╚)Ż¼Ą½╩Ūį┌▓╗╔┘śI(y©©)äš(w©┤)ł÷Š░Ž┬Ż¼śI(y©©)äš(w©┤)īė╩Ū¤oĘ©Ė▀ą¦Īó║åå╬Ą─═Ļ│╔ĘųKeyĄ─Ż¼Redis▒Š╔Ēę▓į┌▓╗öÓĄ─ā×(y©Łu)╗»Ż¼ĮĄĄ═┤¾Key’L(f©źng)ļUŻ¼▒╚╚ń4.0░µ▒Š╠ß╣®┴╦«É▓Įäh│²Key╣”─▄Ż¼╠╚╚¶┤µā”īė─▄┐ņ╦┘═Ļ│╔┤¾Key▀węŲŻ¼▀@▓╗āHĢ■┤¾┤¾║å╗»śI(y©©)äš(w©┤)Č╦Ą─Å═(f©┤)ļsČ╚Ż¼Ė³Ģ■╠ß╔²RedisĘĆ(w©¦n)Č©ąįĪó┐╔ė├ąįŻ¼Ą½╩Ūā╚(n©©i)┤µą═┤µā”ŽĄĮy(t©»ng)į┌┤¾Key▀węŲĄ─╔ŽÅ═(f©┤)ļsČ╚▒╚ĘŪā╚(n©©i)┤µą═┤µā”ŽĄĮy(t©»ng)ČÓę╗éĆöĄ(sh©┤)┴┐╝ēŻ¼▀@ę▓╩Ū×ķ╩▓├┤RedisĄĮ¼F(xi©żn)į┌▀Ć╬┤īŹ¼F(xi©żn)┤¾Key▀węŲ║═«É▓Į▀węŲĄ─╣”─▄ĪŻ
┤¾Key╚¶─▄▓Ęų│╔ąĪKeyĘų┼·┤╬«É▓Į▀węŲĪó▓óį┌▀węŲ▀^│╠ųąįōKey┐╔ūxĪó▓╗┐╔īæŻ¼ų╗ę¬▀węŲ╦┘Č╚ē“┐ņŻ¼▀@ī”śI(y©©)äš(w©┤)Č°čį╩Ū┐╔ęįĮė╩▄Ą─Ż¼į┌2016─Ļ─®Ą─Ģr║“╬ęĖ·Codis║╦ą─ū„š▀spinlockĮ╗┴„┴╦┤¾key▀węŲĄ─ŽļĘ©Ż¼┴Ņ╚╦¾@Ž▓─ż░▌Ą─╩ŪŻ¼╦¹į┌▐r(n©«ng)Üv┤║╣Ø(ji©”)Ų┌ķgŠ═┐ņ±R╝ė▒▐īŹ¼F(xi©żn)┴╦«É▓Į▀węŲįŁą═Ż¼į┌▀@▀^│╠ųą╬ęéāģf(xi©”)ų·Ųõ£yįćĪóĘ┤üBUG║═Ų┐ŅiĪó▓╗öÓĖ─▀MĪóā×(y©Łu)╗»▀węŲąį─▄Ż¼ūŅĮK«É▓Į▀węŲ▓╗āHų¦│ų╚╬ęŌ┤¾ąĪKey▀węŲŻ¼Č°Ūę▀węŲąį─▄ŽÓ▒╚═¼▓Į▀węŲę¬┐ņ5-6▒ČŻ¼╬ęéāę▓╩ŪĄ┌ę╗éĆį┌ŠĆ╔Ž┤¾ęÄ(gu©®)─Żæ¬(y©®ng)ė├īŹ█`Redis«É▓Į▀węŲĄ─Ż¼Ė³┴Ņ╚╦┐╔Ž▓Ą─╩Ū┤╦«É▓Į▀węŲĘĮ░Ėō¶öĪ┴╦Redisū„š▀antirezų«Ū░ėŗäØĄ─ČÓŠĆ│╠ĘĮ░ĖŻ¼īóš²╩Į║Ž╚ļRedis 4.2░µ▒ŠĪŻ
į┌ĮķĮB«É▓Į▀węŲĘĮ░ĖīŹ¼F(xi©żn)Ū░Ż¼Ž╚ĮķĮBŽ┬Codis╩Ū╚ń║╬▒ŻūC▀^│╠ųąöĄ(sh©┤)ō■(j©┤)ę╗ų┬ąį║═×ķ╩▓├┤═¼▓Į▀węŲ┬²ĪŻ╚ń║╬▒ŻūC▀węŲ▀^│╠ųąĖ„Proxyūx╚ĪĄĮĄ─öĄ(sh©┤)ō■(j©┤)ę╗ų┬ąįŻ┐Codisų„ę¬▀węŲ┴„│╠╚ńłD╬Õ╦∙╩ŠŻ¼Ųõ▓╔ė├┴╦ČÓļAČ╬ĀŅæB(t©żi)ÖCīŹ¼F(xi©żn)Ż¼ŅÉ╦ŲĘų▓╝╩Į╩┬äš(w©┤)ųąĄ─ČÓļAČ╬╠ßĮ╗ģf(xi©”)ūhŻ¼Ųõ║╦ą─┴„│╠╚ńŽ┬ĪŻ
į┌▀\ŠS╣▄└ĒŽĄĮy(t©»ng)╔ŽŻ¼╠ßĮ╗▀węŲųĖ┴ŅŻ¼DashboardĖ³ą┬ZooKeeper╔Ž╣■ŽŻ▓█ĀŅæB(t©żi)×ķ┤²▀węŲŻ¼╝┤ĘĄ╗ž(Ģrą“łD1Ż¼2Ż¼3▓Į¾E)ĪŻ
Dashboard«É▓ĮČ©ĢrÖz▓ķZooKeeper╔Ž╩Ūʱėą┤²▀węŲĀŅæB(t©żi)Ą─╣■ŽŻ▓█Ż¼╚¶ėąät╩ūŽ╚▀M╚ļ£╩éõųąĀŅæB(t©żi)Ż¼Dashboardīó┤╦ĀŅæB(t©żi)═¼ĢrĘų░l(f©Ī)ĄĮ╦∙ėąProxyŻ¼╚¶ėą«É│ŻProxyæ¬(y©®ng)┤╩¦öĪŻ¼ät¤oĘ©▀M╚ļ▀węŲŻ¼ĀŅæB(t©żi)╗ž═╦(Ģrą“łD4Ż¼5Ż¼6Ż¼7▓Į¾E)ĪŻ
╚¶╦∙ėąProxyæ¬(y©®ng)┤│╔╣”Ż¼ät▀M╚ļ£╩éõŠ═ŠwĀŅæB(t©żi)Ż¼Dashboardīó┤╦ĀŅæB(t©żi)═¼ĢrĘų░l(f©Ī)ĄĮ╦∙ėąProxyŻ¼Proxy╩šĄĮ┤╦ĀŅæB(t©żi)║¾Ż¼įLå¢┤╦╣■ŽŻ▓█ųąĄ─KeyĄ─śI(y©©)äš(w©┤)šłŪ¾īó▒╗ūĶ╚¹Ą╚┤²Ż¼╚¶ėąProxyæ¬(y©®ng)┤╩¦öĪŻ¼ätĢ■┴ó┐╠╗ž═╦ĄĮ╔ŽéĆĀŅæB(t©żi)(Ģrą“łD8Ż¼9Ż¼10▓Į¾E)ĪŻ
╚¶╦∙ėąProxyæ¬(y©®ng)┤│╔╣”Ż¼ät▀M╚ļ▀węŲĀŅæB(t©żi)Ż¼Dashboardīó┤╦ĀŅæB(t©żi)═¼ĢrĘų░l(f©Ī)ĄĮ╦∙ėąProxyŻ¼Proxy╩šĄĮ┤╦ĀŅæB(t©żi)║¾Ż¼▓╗į┘ūĶ╚¹ī”▀węŲ╣■ŽŻ▓█ųąĄ─KeyįLå¢Ż¼╚¶śI(y©©)äš(w©┤)šłŪ¾Keyī┘ė┌┤²▀węŲ╣■ŽŻŻ¼╩ūŽ╚Ģ■Å─▀węŲį┤Redisųąūx╚ĪöĄ(sh©┤)ō■(j©┤)Ż¼īæĄĮ─┐Ą─Č╦Redisųą╚źŻ¼╚╗║¾į┘½@╚Ī/ą▐Ė─öĄ(sh©┤)ō■(j©┤)ĘĄ╗žŻ¼▀@╩ŪŲõųąę╗ĘN▀węŲĘĮ╩ĮŻ¼▒╗äė▀węŲŻ¼Dashboardę▓Ģ■░l(f©Ī)Ųų„äė▀węŲŻ¼ų▒ų┴öĄ(sh©┤)ō■(j©┤)▀węŲĮY(ji©”)╩°(Ģrą“łD11Ż¼12Ż¼13Ż¼14Ż¼15▓Į¾E)ĪŻ
═©▀^ČÓļAČ╬Ą─ĀŅæB(t©żi)╠ßĮ╗║═╝Ü┴ŻČ╚Īóms╝ēäeĄ─µiŻ¼Codisā×(y©Łu)č┼Ą─ĮŌøQ┴╦▀węŲ▀^│╠ųąĄ─öĄ(sh©┤)ō■(j©┤)ę╗ų┬ąįĪŻ
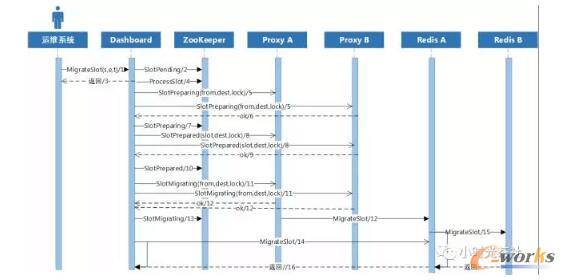
łD┴∙ Codis▀węŲĀŅæB(t©żi)┴„│╠łD
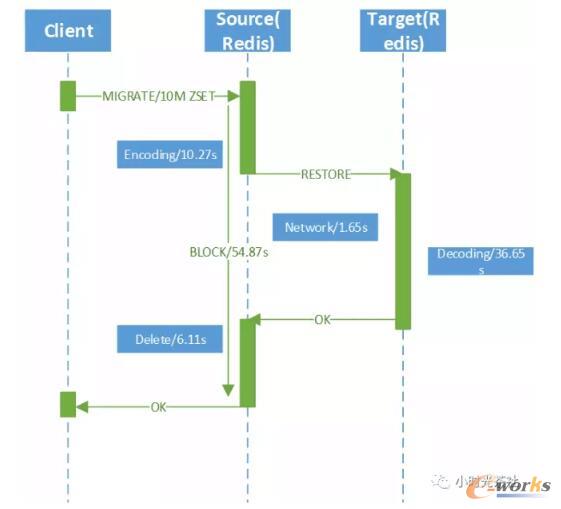
łDŲ▀ Redis═¼▓Į▀węŲ┴„│╠
į┘┐┤×ķ╩▓├┤═¼▓Į▀węŲ┬²Ż¼łDŲ▀╩Ū▀węŲę╗éĆ1000╚fį¬╦žĄ─ZSET║─ĢrĘų╬÷Ż¼«öClient░l(f©Ī)Ų▀węŲųĖ┴Ņ║¾Ż¼į┤Č╦īóš¹éĆZSETą“┴ą╗»│╔payload╗©┘M┴╦10.27sŻ¼═©▀^ŠW(w©Żng)Įj(lu©░)é„▌öĮo─┐Ą─Č╦Redis╗©┘M1.65sŻ¼─┐Ą─Č╦Redis╩šĄĮöĄ(sh©┤)ō■(j©┤)║¾Ż¼īóŲõĘ┤ą“┴ą╗»│╔ā╚(n©©i)┤µųąĄ─öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)Ż¼╗©┘M┴╦36.65sŻ¼ūŅ║¾į┤Č╦Redisäh│²▀węŲ═Ļ│╔Ą─Keyėų╗©┘M┴╦6.11sŻ¼Č°š¹éĆ▀węŲ▀^│╠ųąŻ¼į┤Č╦Redis╩Ū═Ļ╚½ūĶ╚¹Ą─Ż¼▓╗─▄╠ß╣®╚╬║╬ūxīæįLå¢ĪŻę“┤╦Ż¼«É▓Į▀węŲĘĮ░Ė╚¶ę¬╠ß╔²▀węŲąį─▄Ż¼▒žĒÜį┌ęį╔Ž╦─éĆ┴„│╠╔Ž├µū÷ā×(y©Łu)╗»ĪŻ
«É▓Į▀węŲĄ─┴„│╠╚ńłD░╦╦∙╩ŠŻ¼├µī”═¼▓Į▀węŲĄ─╦─éĆ║╦ą─³cŻ¼«É▓Į▀węŲĄ─ĮŌøQĘĮ░Ė╚ńŽ┬Ż║
- ▓ĘųrdbSave(encoding)▀^│╠Ż¼ĮŌøQ═¼▓Įą“┴ą╗»ķ_õNĪŻī”ė┌┤¾keyŻ¼▓╗į┘╩╣ė├rdbSaveī”öĄ(sh©┤)ō■(j©┤)▀MąąencodingŻ¼Č°╩Ū═©▀^ųĖ┴Ņ▓ĮŌŻ¼ redisųąĄ─öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)(listŻ¼setŻ¼hashŻ¼zset)Č╝┐╔ęįĄ╚ārĄ─▓Ęų│╔╚¶Ė╔éĆ╠Ē╝ėųĖ┴ŅŻ¼▒╚╚ń║¼ėą1000╚fį¬╦žĄ─zsetŻ¼┐╔ęį▓Ęų│╔10╚féĆzaddųĖ┴ŅŻ¼├┐éĆzaddųĖ┴Ņ╠Ē╝ė100éĆöĄ(sh©┤)ō■(j©┤)
- ▓ĘųRestore(network)▀^│╠Ż¼ĮŌøQ═¼▓ĮIOķ_õNĪŻ«É▓ĮIOīŹ¼F(xi©żn)Ż¼░l(f©Ī)╦═öĄ(sh©┤)ō■(j©┤)▓╗į┘ūĶ╚¹ĪŻ
- ▓ĘųrdbLoad(decoding)▀^│╠Ż¼ĮŌøQĘ┤ą“┴ą╠¢ķ_õNĪŻę“į┤Č╦░l(f©Ī)╦═▀^üĒĄ─öĄ(sh©┤)ō■(j©┤)▓╗į┘╩ŪrdbČ■▀MųŲöĄ(sh©┤)ō■(j©┤)Ż¼─┐Ą─Č╦redis¤oąĶį┘╩╣ė├rdbLoadŻ¼ų╗ąĶīó╩šĄĮĄ─╠Ē╝ėųĖ┴ŅöĄ(sh©┤)ō■(j©┤)ų▒ĮėĖ³ą┬ĄĮī”æ¬(y©®ng)Ą─ā╚(n©©i)┤µöĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)╝┤┐╔Ż¼═¼Ģr╩╣ė├┴╦ę╗ą®trickŻ¼▒╚╚ńā╚(n©©i)┤µŅA(y©┤)Ęų┼õŻ¼▒▄├ŌŅlĘ▒╔Ļšłā╚(n©©i)┤µŻ¼double▐D(zhu©Żn)ōQ│╔long longŻ¼╠ßĖ▀▀węŲąį─▄Ą╚ĪŻ
- «É▓Įäh│²KeyŻ¼ĮŌøQ═¼▓Įäh│²Key║─Ģrå¢Ņ}ĪŻ═©▀^Ņ~═ŌĄ─╣żū„ŠĆ│╠«É▓Įäh│²keyŻ¼▓╗į┘ūĶ╚¹redisų„ŠĆ│╠ĪŻ
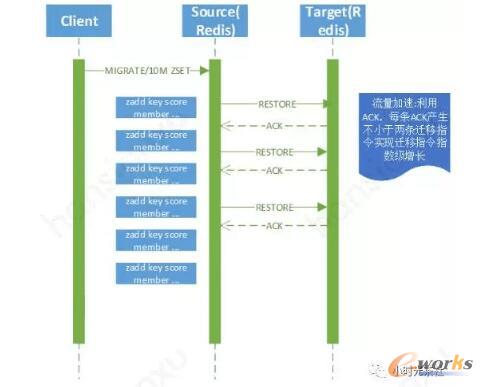
łD░╦ Redis«É▓Į▀węŲ┴„│╠
1000╚fĄ─ZSETŻ¼═¼▓Į▀węŲąĶę¬54.87sŻ¼Č°«É▓Į▀węŲų╗ąĶę¬8.3sŻ¼į┌▓╗ūĶ╚¹į┌ŠĆśI(y©©)äš(w©┤)Ą─Ū░╠ߎ┬Ż¼ąį─▄╠ß╔²6▒ČČÓŻ¼ęį╬ęéā╔·«a(ch©Żn)Łh(hu©ón)Š│─│╚½Ū“9000w┼┼ąą░±×ķ└²Ż¼ų«Ū░å╬ÖCų„éõ░µ╝ė▌dĄĮā╚(n©©i)┤µČ╝ąĶę¬20ĘųńŖŻ¼Č°ė├«É▓Į┐ńÖCŲ„▀węŲų╗ąĶę¬180sū¾ėęŻ¼ Ė³įö╝ÜĄ─▀węŲĮķĮB┐╔ģó┐┤ĖĮõøspinlockĄ─Codisą┬░µ▒Š╠žąįĮķĮBĪŻ
┴∙ĪóĖ▀┐╔ė├
Ė„ĮM╝■ųąĖ·ė├涚łŪ¾ŽÓĻP(gu©Īn)ąį║▄ÅŖĄ─ĮM╝■Ęųäe╩ŪProxyĪóRedisĪóį¬öĄ(sh©┤)ō■(j©┤)┤µā”(ZooKeeper)Ż¼ŽÓĻP(gu©Īn)ąį▌^╚§Ą─╩ŪDashboardĪŻ
ProxyŻ║ČÓÖCČÓIDC▓┐╩Ż¼š{(di©żo)Č╚Ę■äš(w©┤)Ģ■Ė∙ō■(j©┤)IDC IDŻ¼ūįäė┤“╔óŽÓ═¼proxyŻ¼▒M┴┐▒ŻūC═¼ę╗╝»╚║proxy▓┐╩į┌▓╗═¼IDCŻ¼═©▀^L5║═CMLB▀Mąą╚▌×─(z©Īi)ĪŻ
RedisŻ║╗∙ė┌Redis Sentinel▀Mąąų„éõūįäė╗»ŪąōQĪŻ
ZooKeeperŻ║Ė▀┐╔ė├Ęų▓╝╩Įģf(xi©”)š{(di©żo)Ę■äš(w©┤)Ż¼ę╗░ļęį╔Ž╣Ø(ji©”)³c┤µ╗Ņ╝┤┐╔╠ß╣®Ę■äš(w©┤)Ż¼═¼Ģrų╗ėąį┌ProxyåóäėĢr║═▀\ąą▀^│╠ųą░l(f©Ī)╔·öĄ(sh©┤)ō■(j©┤)▀węŲ▓┼Ģ■ę└┘ćZooKeeperŻ¼Į^┤¾▓┐Ęųš²│ŻšłŪ¾▓╗╩▄ZooKeeper ╝»╚║ĀŅæB(t©żi)ė░ĒæĪŻ
DashboardŻ║ žōž¤ģf(xi©”)š{(di©żo)╝»╚║ĀŅæB(t©żi)ūāĖ³╝░ę╗ų┬ąįŻ¼─┐Ū░į┌įO(sh©©)ėŗ╔Ž╩ŪéĆå╬³cŻ¼Ą½╩Ūų╗ėąį┌Š═╝»╚║▀\ąą▀^│╠ųą░l(f©Ī)╔·öĄ(sh©┤)ō■(j©┤)▀węŲ▓┼Ģ■ę└┘ć╦³Ż¼ę“┤╦╩Ū╚§ŽÓĻP(gu©Īn)ąįŻ¼ ║¾└m(x©┤)▀Ć┐╔ęįā×(y©Łu)╗»│╔ČÓ╣Ø(ji©”)³c▓┐╩Ż¼═©▀^ZooKeeperĄ─Ęų▓╝╩ĮµiüĒ▒ŻūCų╗ėąę╗éĆ╣Ø(ji©”)³c─▄╠ß╣®Ę■äš(w©┤)Ż¼«ö╠ß╣®Ę■äš(w©┤)Ą─╣Ø(ji©”)³c╣╩šŽĢrŻ¼═©▀^ę╗ŽĄ┴ą┴„│╠(╚ńąĶ═©ų¬ProxyŻ¼DashboardūāĖ³Ą╚)īŹ¼F(xi©żn)Dashboardūįäė╗»╣╩šŽŪąōQĪŻ
ųž³cĮķĮBredisĄ─ų„éõūįäėŪąōQ┴„│╠Ż¼│ŻęŖĄ─Master-Slave┤µā”ŽĄĮy(t©»ng)ūįäėŪąōQĘĮ░Ėę╗░Ńėą╚ńŽ┬╚²ĘNŻ║
- ╗∙ė┌ZooKeeperüĒū÷ų„éõūįäėŪąōQŻ¼╚ń╣½╦Šā╚(n©©i)▓┐Ą─TDSQLŻ¼į┌Mysqlų„éõ╣Ø(ji©”)³c╔Ž▓┐╩AgentŻ¼į┌ZooKeeper╝»╚║╔Žūóāį┼RĢr╣Ø(ji©”)³cŻ¼«öų„ÖCÕ┤ÖCĢrŻ¼Schedulerį┌Öz£yĄĮ┼RĢr╣Ø(ji©”)³cŽ¹╩¦│¼▀^ķyųĄ║¾░l(f©Ī)Ų╚▌×─(z©Īi)┴„│╠ĪŻ
- ╗∙ė┌ŽÓ╗ź¬Ü┴óĄ─╠Į£yAgentīŹ¼F(xi©żn)Ż¼╚ńMIGĄ─DCacheŻ¼IEGĄ─TRedisĪŻIEG TRedisīóų„éõūįäėŪąōQ┴„│╠▓Ęų│╔╣╩šŽøQ▓▀─ŻēKŻ©╠Į£yRedis┤µ╗ŅŻ®Īó╣╩šŽ═¼▓Į─ŻēKĪó╣╩šŽ▒O(ji©Īn)┐ž─ŻēKŻ©double checkŻ®Īó╣╩šŽŪąōQ▒Ē═¼▓Į─ŻēK(īó┤²ŪąōQĄ─īŹ└²Ę┼╚ļĻĀ┴ą)Īó╣╩šŽ║╦ą──ŻēK( ŪąōQ┬Ęė╔)ĪŻ
- ╗∙ė┌QuorumĄ─Ęų▓╝╩Į╠Į£yAgentŻ¼╚ńRedisĄ─SentinelŻ¼Sentinelį┌ą┬└╦╬ó▓®Ą╚╣½╦ŠęčĮø(j©®ng)▀Mąą┴╦▌^┤¾ęÄ(gu©®)─Żæ¬(y©®ng)ė├Ż¼Codisę▓╩Ū╗∙ė┌┤╦īŹ¼F(xi©żn)ų„éõūįäėŪąōQŻ¼╬ęéāį┌┤╦╗∙ĄA(ch©│)╔Žį÷╝ė┴╦ĖµŠ»║═«öŠW(w©Żng)Įj(lu©░)│÷¼F(xi©żn)Ęųģ^(q©▒)ĢrŻ¼į÷╝ė┴╦ę╗éĆĮĄ╝ē▓┘ū„Ż¼▒▄├Ō─X┴čŻ¼Ųõįö╝Ü┴„│╠łD░╦╦∙╩ŠĪŻ
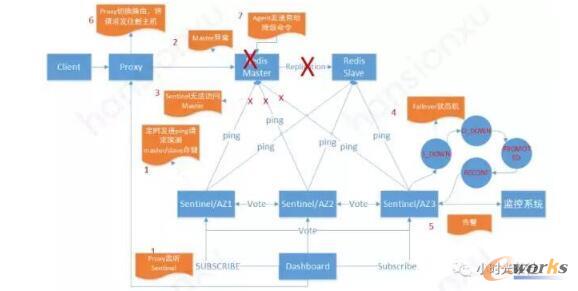
łDŠ┼ Redisų„éõūįäėŪąōQ┴„│╠
łDŠ┼┴„│╠║åę¬Ęų╬÷╚ńŽ┬Ż║
łDųą╚²éĆSentinel▓┐╩į┌▓╗═¼Ą─┐╔ė├ģ^(q©▒)Ż¼īŹļH¼F(xi©żn)ŠW(w©Żng)╬ęéā╩Ū▓┐╩┴╦╬ÕéĆŻ¼Ė▓╔wĖ„┤¾▀\ĀI╔╠IDCĄ╚Ż¼Ė„SentinelĢ■Č©ĢrŽ“master/slave░l(f©Ī)╦═pingĄ╚šłŪ¾╠Į£ymaster/slave┤µ╗ŅŻ¼▓ó═©▀^gossipģf(xi©”)ūhŽÓ╗źĮ╗┴„ą┼ŽóŻ¼═¼ĢrĖ„ProxyīŹĢr▒O(ji©Īn)┬ĀSentinelĄ─ĀŅæB(t©żi)Ž¹ŽóĪŻŻ©łD░╦1Ż¼2┴„│╠Ż®
«ömaster│÷¼F(xi©żn)«É│ŻŻ¼Sentinelį┌ę╗Č©Ģrķg(┐╔┼õų├Ż¼╚ń2minŻ¼▒▄├ŌŠW(w©Żng)Įj(lu©░)ČČäėŻ¼š`Ūą)ā╚(n©©i)Č╝│ų└m(x©┤)¤oĘ©įLå¢MasterĢrŻ¼SentinelŠ═Ģ■šJ×ķ┤╦╣Ø(ji©”)³c×ķų„ė^╣╩šŽŻ©S_DOWNŻ®Ż¼SentinelĢ■▒╦┤╦═©▀^gossipģf(xi©”)ūhŽÓ╗źĮ╗ōQą┼ŽóŻ¼«öę╗░ļęį╔Ž(┐╔┼õų├)Ą─sentinelšJ×ķ┤╦masterČ╝╣╩šŽ║¾Ż¼┤╦╣Ø(ji©”)³cĢ■▒╗┼ąöÓ×ķ┐═ė^╣╩šŽ(O_DOWN)Ż¼Ė„SentinelĢ■▀x┼e│÷ę╗éĆLeaderüĒł╠(zh©¬)ąąų„éõŪąōQŻ¼Leader╩ūŽ╚Å─Ė„éõÖCųą▀xō±ę╗éĆūŅ╝č╣Ø(ji©”)³cŻ¼╦ŃĘ©╩Ū╩ū▀x▀^×VĄ¶┼cmasteröÓŠĆĢrķg│¼▀^ķyųĄĄ─slaveŻ¼Ųõ┤╬ā×(y©Łu)Ž╚▀xō±slave_priority▌^ąĪĄ─Ż¼╚¶priorityę╗śėŻ¼ät▀xō±replication offsetūŅ┤¾Ą─Ż¼╚¶offsetę▓ę╗ų┬Ż¼ät░┤ūųĄõĒśą“┼┼ą“▀xō±ūŅąĪĄ─runid.▀xō±│÷ūŅ╝č║“▀xmaster║¾Ż¼LeaderĢ■īóŲõ╠ß╔²×ķmasterŻ¼═¼ĢrŽ“ėåķåš▀░l(f©Ī)│÷+switch-master ╩┬╝■Ż¼═©▀^tnm2/uwork░l(f©Ī)│÷L0ĖµŠ»═©ų¬ķ_░l(f©Ī)▀\ŠSŻ¼╚╗║¾Ė³Ė─Ųõ╦¹éõÖCų„Å─ĻP(gu©Īn)ŽĄŻ¼Å─ą┬ų„ÖC═¼▓ĮöĄ(sh©┤)ō■(j©┤)Ż©łD░╦3Ż¼4Ż¼5┴„│╠Ż®ĪŻ
Ė„éĆProxy╩šĄĮSentinelĄ─+switch-master event║¾Ż¼Ģ■▒ķÜv╦∙ėąsentinel▓ķįā╣╩šŽĮMūŅą┬masterŻ¼«öę╗░ļęį╔ŽĄ─sentinelĘĄ╗ž┴╦╣╩šŽĮMą┬Ą─masterŻ¼ProxyätĢ■ŪąōQ┬Ęė╔Ż¼┬Ęė╔ĄĮĮMĄ─šłŪ¾Ż¼īó░l(f©Ī)ĄĮą┬Ą─masterŻ¼ų„éõūįäėŪąōQ═Ļ│╔ĪŻŻ©łD░╦6┴„│╠Ż®
Ą½╩Ūį┌śOČ╦ŪķørŽ┬╚¶ŠW(w©Żng)Įj(lu©░)│÷¼F(xi©żn)Ęųģ^(q©▒)Ż¼śI(y©©)äš(w©┤)Ę■äš(w©┤)ĪóéĆäeProxyĖ·Redis Masterį┌═¼ę╗éĆ┐╔ė├ģ^(q©▒)Ż¼ätĢ■│÷¼F(xi©żn)─X┴čŻ¼×ķ┴╦▒▄├Ō┤╦ĘNŪķørŻ¼▓┐╩į┌RedisÖCŲ„╔ŽĄ─AgentĢ■Č©Ģr│ų└m(x©┤)Öz£y┼cZooKeeper▀BĮė╩Ūʱ═©Ģ│Ż¼╚¶▀BĮė▓╗╔ŽätĢ■Ž“Redis░l(f©Ī)╦═ĮĄ╝ēųĖ┴ŅŻ¼▓╗┐╔ūxīæŻ©łD░╦7┴„│╠Ż®ĪŻ
Ų▀Īó▀\ĀIīŹ█`
1.ČÓŠSČ╚▒O(ji©Īn)┐ž
Proxy/Dashboard/RedisÖCŲ„╔ŽĄ─AgentČ©Ģr▓╔╝»proxyĪóredisĄ─qpsĪóconnectionĪómemory_usedĄ╚10ÄūéĆųĖś╦Ż¼╔Žł¾ĄĮ├ūĖ±▒O(ji©Īn)┐žŽĄĮy(t©»ng)Ż¼ßśī”║╦ą─▒O(ji©Īn)┐žųĖś╦┼õų├ķyųĄ║═▓©äėĖµŠ»ĪŻ▒O(ji©Īn)┐žŽĄĮy(t©»ng)į┌ŠĆ╔ŽöĄ(sh©┤)┤╬▓ČūĮĄĮ╝»╚║«É│Ż(╚ń▀BĮėöĄ(sh©┤)│¼▀^ķyųĄĪó─│redisīŹ└²¤oéõÖCĄ╚)Ż¼╝░Ģr░l(f©Ī)│÷ėąą¦ĖµŠ»Ż¼╠ßŪ░░l(f©Ī)¼F(xi©żn)å¢Ņ}ĪóĮŌøQå¢Ņ}ĪŻ═¼ĢrŻ¼ę▓▓╗▀BVPNĄ─ŪķørŽ┬ę▓┐╔ęį▒ŃĮ▌Ąž═©▀^╩ųÖC┐ņ╦┘▓ķ┐┤▒O(ji©Īn)┐žŪ·ŠĆĪóČ©╬╗å¢Ņ}Ą╚Ż¼┤¾┤¾╠ßĖ▀╣żū„ą¦┬╩ĪŻ
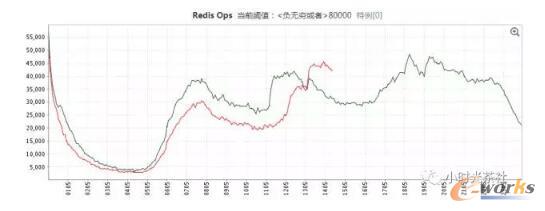
łD╩« Redis OpsŪ·ŠĆ
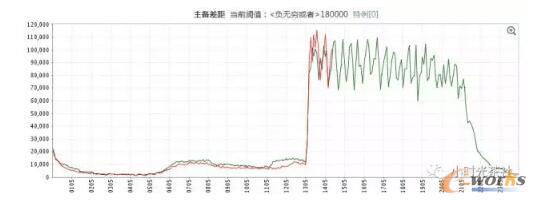
łD╩«ę╗ master/slave offset▓Ņ«ÉŪ·ŠĆ
2 . Ą═žō▌dā×(y©Łu)╗»
╝»╚║┐s╚▌║═ŽÓ═¼śI(y©©)äš(w©┤)Å═(f©┤)ė├═¼╝»╚║
┤µā”ÖCČÓīŹ└²▓┐╩Ż¼¼F(xi©żn)į┌─¼šJ8éĆīŹ└²
═©▀^AgentĒśą“ė|░l(f©Ī)éĆīŹ└²aof rewrite║═rdb saveŻ¼▒▄├ŌČÓéĆīŹ└²═¼ĢrforkŻ¼Å─Č°╠ßĖ▀┤µā”ÖCā╚(n©©i)┤µ╩╣ė├┬╩ų┴ūŅĖ▀80%
ProxyÖCŲ„ČÓīŹ└²▓┐╩(▀Mąąųą)
3 .ČÓūŌæ¶
ąĪśI(y©©)äš(w©┤)═©▀^į┌keyŪ░ŠYį÷╝ėśI(y©©)äš(w©┤)ś╦ūRŻ¼Å═(f©┤)ė├ŽÓ═¼╝»╚║
┤¾śI(y©©)äš(w©┤)╩╣ė├¬Ü┴ó╝»╚║Ż¼¬Ü┴óÖCŲ„
4.öĄ(sh©┤)ō■(j©┤)░▓╚½╝░éõĘ▌
įLå¢╦∙ėąRedisīŹ└²Č╝ąĶę¬ĶbÖÓ(qu©ón)
Proxyīė┐╔Įy(t©»ng)ėŗģR┐é╦∙ėąīæšłŪ¾ųĖ┴Ņ
─¼šJķ_åóAOF╚šųŠ
Č©Ģr╔Žł¾Redis AOFĪóRDB╬─╝■ĄĮHDFS╝»╚║
░╦Īó┐éĮY(ji©”)
╗∙ė┌Codis×ķ║╦ą─Ą─RedisĘ■äš(w©┤)ŲĮ┼_Ė▀ą¦ĮŌøQ┴╦SNG┤¾┴┐śI(y©©)äš(w©┤)Ą─═┤³c(▓╗Ž▐ųŲKey┤¾ąĪŻ¼įŁ╔·Ą─Redisā╚(n©©i)║╦Ż¼Ė▀ąį─▄)Ż¼╠ßĖ▀┴╦ķ_░l(f©Ī)ą¦┬╩Ż¼ų·┴”«a(ch©Żn)ŲĘĖ³┐ņ░l(f©Ī)š╣Ż¼Ą½╩Ūę“╚╦┴”ėąŽ▐(░ļéĆķ_░l(f©Ī)═Č╚ļŻ¼į┌śI(y©©)äš(w©┤)ĒŚ─┐╚╦┴”ŠoÅłĄ─Ģr║“Ż¼┴Ń═Č╚ļ)Ż¼▀Ćėą╚¶Ė╔┤²═Ļ╔ŲĄ─ĄžĘĮŻ¼╚ń▓╗ų¦│ų└õ¤ßĘųļxĄ╚ĪŻ į┌Ū¦║¶╚fåŠųąŻ¼─┐Ū░╣½╦Šā╚(n©©i)Ą─┤µā”ĮMūį蹥─CKV+Ż©╗∙ė┌╣▓ŽĒā╚(n©©i)┤µīŹ¼F(xi©żn)RedisĖ„ŅÉöĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)Ż®Ą─å╬ÖCų„Å─░µę▓ĮKė┌╔ŽŠĆŻ¼╝»╚║░µę▓į┌ŠoĶī├▄╣─Ą─ķ_░l(f©Ī)ųąŻ¼CKV+▌^║├Ą─ĮŌøQ┴╦Redisā╚(n©©i)┤µ╩╣ė├┬╩Īó┐ńIDC▓┐╩ĪóöĄ(sh©┤)ō■(j©┤)éõĘ▌╝░═¼▓ĮÖCųŲĄ─ę╗ą®▓╗ūŃų«╠ÄŻ¼║¾└m(x©┤)śI(y©©)äš(w©┤)ę▓īóėąĖ³ČÓĄ─▀xō±ŻĪūŅ║¾ĖąųxantirezŻ¼spinlockĄ─¤o╦ĮžĢ½IŻĪ
Š┼Īóģó┐╝┘Y┴Ž
Redis Documentation
Github Codis
Github Redis
Codisą┬░µ▒Š╠žąįĮķĮB(spinlock)
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║┤¾ęÄ(gu©®)─Ż codis ╝»╚║Ą─ų╬└Ē┼cīŹ█`
▒Š╬─ŠW(w©Żng)ųĘŻ║http://www.guhuozai8.cn/html/solutions/14019321459.html



▀xą═ųąą─")
¾w“×ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")














