



2018─Ļ1į┬9╚šŻ¼╚½Ū“ęÄ─ŻūŅ┤¾Ą─2018▒▒├└Ž¹┘MļŖūė«aŲĘš╣į┌├└ć°└Ł╦╣ŠS╝ė╦╣└Łķ_ßĪ─╗ĪŻ▒Š┤╬ģóš╣Ą─┐Ų╝╝Ų¾śI│¼▀^4000╝ęŻ¼░³└©Ė▀═©Īóėóéź▀_Īóėó╠žĀ¢ĪóLGĪóIBMĪó░┘Č╚į┌ā╚Ą─śIĮń┐Ų╝╝Š▐Ņ^╝Ŗ╝Ŗ░l▓╝┴╦Ė„ūįūŅą┬Ą─╚╦╣żųŪ─▄ąŠŲ¼«aŲĘ║═æ┬įŻ¼ū„×ķ▒Šī├š╣Ģ■Ą─ūŅ┤¾┐┤³cŻ¼╚╦╣żųŪ─▄ąŠŲ¼«aŲʤoę╔╩▄ĄĮ┴╦ūŅ×ķÅVĘ║Ą─ĻPūóĪŻ
┼cCPU▒╚▌^Ż¼╚╦╣żųŪ─▄ąŠŲ¼ėą║╬▓╗═¼Ż┐
2017─ĻŻ¼«öAlphaGoį┌ć·ŲÕ┤¾æųą═Ļä┘┐┬ØŹ║¾Ż¼Ė„┤¾├Į¾wī”╚╦╣żųŪ─▄Ą─ėæšōŠ═▓╗Į^ė┌Č·Ż¼╔§ų┴ėą╚╦ō·ą─ÖCŲ„Ģ■Š▀éõūįų„╦╝ŠSŻ¼ĮKėąę╗╠ņĢ■Ž±ļŖė░ĪČĮKĮYš▀ĪĘųąĄ─ł÷Š░ę╗śėī”╚╦ŅÉįņ│╔╔·┤µ═■├{ĪŻ▓╗╣▄▀@ĘN╬ŻÖC╩Ūʱ┤µį┌Ż¼Ą½▒žĒÜšJūRĄĮ╚╦╣żųŪ─▄ąŠŲ¼į┌╝▄śŗ║═╣”─▄╠ž³c╔Ž┼cé„ĮyĄ─CPU╩Ūėąų°ĘŪ│Ż┤¾Ą─ģ^äeĪŻ
é„ĮyĄ─CPU▀\ąąĄ─╦∙ėąĄ─▄ø╝■╩Ūė╔│╠ą“åTŠÄīæŻ¼═Ļ│╔Ą─╣╠╗»Ą─╣”─▄▓┘ū„ĪŻŲõėŗ╦Ń▀^│╠ų„ę¬¾w¼Fį┌ł╠ąąųĖ┴Ņ▀@éĆŁh╣ØĪŻĄ½┼cé„ĮyĄ─ėŗ╦Ń─Ż╩Į▓╗═¼Ż¼╚╦╣żųŪ─▄ę¬─ŻĘ┬Ą─╩Ū╚╦─XĄ─╔±ĮøŠWĮjŻ¼Å─ūŅ╗∙▒ŠĄ─å╬į¬╔Ž─ŻöM┴╦╚╦ŅÉ┤¾─XĄ─▀\ąąÖCųŲĪŻ╦³▓╗ąĶę¬╚╦×ķĄ─╠ß╚Ī╦∙ąĶĮŌøQå¢Ņ}Ą─╠žš„╗“š▀┐éĮYęÄ┬╔üĒ▀MąąŠÄ│╠ĪŻ
╚╦╣żųŪ─▄╩Ūį┌┤¾┴┐Ą─śė▒ŠöĄō■╗∙ĄA╔ŽŻ¼═©▀^╔±ĮøŠWĮj╦ŃĘ©ė¢ŠÜöĄō■Ż¼Į©┴ó┴╦▌ö╚ļöĄō■║═▌ö│÷öĄō■ų«ķgĄ─ė│╔õĻPŽĄŻ¼ŲõūŅų▒ĮėĄ─æ¬ė├╩Ūį┌ĘųŅÉūRäeĘĮ├µĪŻ└²╚ńė¢ŠÜśė▒ŠĄ─▌ö╚ļ╩ŪšZę¶öĄō■Ż¼ė¢ŠÜ║¾Ą─╔±ĮøŠWĮjīŹ¼FĄ─╣”─▄Š═╩ŪšZę¶ūRäeŻ¼╚ń╣¹ė¢ŠÜśė▒Š▌ö╚ļ╩Ū╚╦─śłDŽ±öĄō■Ż¼ė¢ŠÜ║¾īŹ¼FĄ─╣”─▄Š═╩Ū╚╦─śūRäeĪŻ
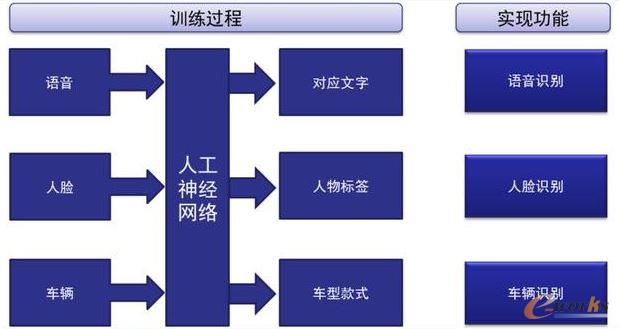
═©│ŻüĒšfŻ¼╚╦╣żųŪ─▄░³└©ÖCŲ„īW┴Ģ║═╔ŅČ╚īW┴ĢŻ¼Ą½▓╗╣▄╩ŪÖCŲ„īW┴Ģ▀Ć╩Ū╔ŅČ╚īW┴ĢČ╝ąĶ꬜ŗĮ©╦ŃĘ©║═─Ż╩ĮŻ¼ęįīŹ¼Fī”öĄō■śė▒ŠĄ─Ę┤Å═▀\╦Ń║═ė¢ŠÜŻ¼ĮĄĄ═ī”╚╦╣ż└ĒĮŌ╣”─▄įŁ└ĒĄ─ę¬Ū¾ĪŻę“┤╦Ż¼╚╦╣żųŪ─▄ąŠŲ¼ąĶꬊ▀éõĖ▀ąį─▄Ą─▓óąąėŗ╦Ń─▄┴”Ż¼═¼Ģrę¬─▄ų¦│ų«öŪ░Ą─Ė„ĘN╚╦╣ż╔±ĮøŠWĮj╦ŃĘ©ĪŻé„ĮyCPUė╔ė┌ėŗ╦Ń─▄┴”╚§Ż¼ų¦ō╬╔ŅČ╚īW┴ĢĄ─║Ż┴┐öĄō■▓óąą▀\╦ŃŻ¼Ūę┤«ąąĄ─ā╚▓┐ĮYśŗįOėŗ╝▄śŗ×ķĄ─╩Ūęį▄ø╝■ŠÄ│╠Ą─ĘĮ╩ĮīŹ¼FįOČ©Ą─╣”─▄Ż¼▓ó▓╗▀m║Žæ¬ė├ė┌╚╦╣ż╔±ĮøŠWĮj╦ŃĘ©Ą─ūįų„Ą³┤·▀\╦ŃĪŻé„ĮyCPU╝▄śŗ═∙═∙ąĶę¬öĄ░┘╔§ų┴╔ŽŪ¦ŚlųĖ┴Ņ▓┼─▄═Ļ│╔ę╗éĆ╔±Įøį¬Ą─╠Ä└ĒŻ¼į┌AIąŠŲ¼╔Ž┐╔─▄ų╗ąĶę¬ę╗ŚlųĖ┴ŅŠ═─▄═Ļ│╔ĪŻ
ĮŌūxų„┴„Ą─╚╦╣żųŪ─▄ąŠŲ¼
╚╦╣żųŪ─▄Ą─Ė▀╝ēļAČ╬╩Ū╔ŅČ╚īW┴ĢŻ¼Č°ī”ė┌╔ŅČ╚īW┴Ģ▀^│╠ät┐╔Ęų×ķė¢ŠÜ║══ŲöÓā╔éĆŁh╣ØŻ║ė¢ŠÜŁh╣Ø═©│ŻąĶę¬═©▀^┤¾┴┐Ą─öĄō■▌ö╚ļ╗“▓╔╚Īį÷ÅŖīW┴ĢĄ╚ĘŪ▒OČĮīW┴ĢĘĮĘ©Ż¼ė¢ŠÜ│÷ę╗éĆÅ═ļsĄ─╔ŅČ╚╔±ĮøŠWĮj─Żą═ĪŻė¢ŠÜ▀^│╠ė╔ė┌╔µ╝░║Ż┴┐Ą─ė¢ŠÜöĄō■║═Å═ļsĄ─╔ŅČ╚╔±ĮøŠWĮjĮYśŗŻ¼ąĶꬥ─ėŗ╦ŃęÄ─ŻĘŪ│Ż²ŗ┤¾Ż¼═©│ŻąĶę¬GPU╝»╚║ė¢ŠÜÄū╠ņ╔§ų┴öĄų▄Ą─ĢrķgŻ¼į┌ė¢ŠÜŁh╣ØGPU─┐Ū░Ģ║Ģr░ńč▌ų°ļyęį▌pęū╠µ┤·Ą─ĮŪ╔½ĪŻ═ŲöÓŁh╣ØųĖ└¹ė├ė¢ŠÜ║├Ą──Żą═Ż¼╩╣ė├ą┬Ą─öĄō■╚ź“═ŲöÓ”│÷Ė„ĘNĮYšōŻ¼╚ńęĢŅl▒O┐žįOéõ═©▀^║¾┼_Ą─╔ŅČ╚╔±ĮøŠWĮj─Żą═Ż¼┼ąöÓę╗Åłūź┼─ĄĮĄ─╚╦─ś╩Ūʱī┘ė┌║┌├¹å╬ĪŻļm╚╗═ŲöÓŁh╣ØĄ─ėŗ╦Ń┴┐ŽÓ▒╚ė¢ŠÜŁh╣Ø╔┘Ż¼Ą½╚į╚╗╔µ╝░┤¾┴┐Ą─ŠžĻć▀\╦ŃĪŻ
į┌═ŲöÓŁh╣ØŻ¼│²┴╦╩╣ė├CPU╗“GPU▀Mąą▀\╦Ń═ŌŻ¼FPGAęį╝░ASICŠ∙─▄░lō]ųž┤¾ū„ė├ĪŻ─┐Ū░Ż¼ų„┴„Ą─╚╦╣żųŪ─▄ąŠŲ¼╗∙▒ŠČ╝╩ŪęįGPUĪóFPGAĪóASICęį╝░ŅÉ─XąŠŲ¼×ķų„ĪŻ
1.FPGA
╝┤īŻė├╝»│╔ļŖ┬ĘŻ¼ę╗ĘN╝»│╔┤¾┴┐╗∙▒ŠķTļŖ┬Ę╝░┤µā”Ų„Ą─ąŠŲ¼Ż¼┐╔═©▀^¤²╚ļFPGA┼õų├╬─╝■üĒüĒČ©┴x▀@ą®ķTļŖ┬Ę╝░┤µā”Ų„ķgĄ─▀BŠĆŻ¼Å─Č°īŹ¼F╠žČ©Ą─╣”─▄ĪŻČ°Ūę¤²╚ļĄ─ā╚╚▌╩Ū┐╔┼õų├Ą─Ż¼═©▀^┼õų├╠žČ©Ą─╬─╝■┐╔īóFPGA▐Dūā×ķ▓╗═¼Ą─╠Ä└ĒŲ„Ż¼Š═╚ńę╗ēK┐╔ųžÅ═╦óīæĄ─░ū░Õę╗śėĪŻFPGAėąĄ═čė▀tĄ─╠ž³cŻ¼ĘŪ│Ż▀m║Žį┌═ŲöÓŁh╣Øų¦ō╬║Ż┴┐Ą─ė├æ¶īŹĢrėŗ╦ŃšłŪ¾Ż¼╚ńšZę¶ūRäeĪŻė╔ė┌FPGA▀m║Žė├ė┌Ą═čė▀tĄ─┴„╩Įėŗ╦Ń├▄╝»ą═╚╬äš╠Ä└ĒŻ¼ęŌ╬Čų°FPGAąŠŲ¼ū÷├µŽ“┼c║Ż┴┐ė├æ¶Ė▀▓ó░lĄ─įŲČ╦═ŲöÓŻ¼ŽÓ▒╚GPUŠ▀éõĖ³Ą═ėŗ╦Ńčė▀tĄ─ā×ä▌Ż¼─▄ē“╠ß╣®Ė³╝čĄ─Ž¹┘Mš▀¾w“×ĪŻį┌▀@éĆŅIė“Ż¼ų„┴„Ą─ÅS╔╠░³└©IntelĪóüå±R▀dĪó░┘Č╚Īó╬ó▄ø║═░ó└’įŲĪŻ
2.ASIC
╝┤īŻė├╝»│╔ļŖ┬ĘŻ¼▓╗┐╔┼õų├Ą─Ė▀Č╚Č©ųŲīŻė├ąŠŲ¼ĪŻ╠ž³c╩ŪąĶę¬┤¾┴┐Ą─čą░l═Č╚ļŻ¼╚ń╣¹▓╗─▄▒ŻūC│÷žø┴┐Ųõå╬Ņw│╔▒ŠļyęįŽ┬ĮĄŻ¼Č°Ū깊Ų¼Ą─╣”─▄ę╗Ą®┴„Ų¼║¾ät¤oĖ³Ė─ėÓĄžŻ¼╚¶╩ął÷╔ŅČ╚īW┴ĢĘĮŽ“ę╗Ą®Ė─ūāŻ¼ASICŪ░Ų┌═Č╚ļīó¤oĘ©╗ž╩šŻ¼ęŌ╬Čų°ASICŠ▀ėą▌^┤¾Ą─╩ął÷’LļUĪŻĄ½ASICū„×ķīŻė├ąŠŲ¼ąį─▄Ė▀ė┌FPGAŻ¼╚ń─▄īŹ¼FĖ▀│÷žø┴┐Ż¼Ųõå╬Ņw│╔▒Š┐╔ū÷ĄĮ▀hĄ═ė┌FPGAĪŻ
╣╚ĖĶ═Ų│÷Ą─TPUŠ═╩Ūę╗┐Ņßśī”╔ŅČ╚īW┴Ģ╝ė╦┘Ą─ASICąŠŲ¼Ż¼Č°ŪęTPU▒╗░▓čbĄĮAlphaGoŽĄĮyųąĪŻĄ½╣╚ĖĶ═Ų│÷Ą─Ą┌ę╗┤·TPUāH─▄ė├ė┌═ŲöÓŻ¼▓╗┐╔ė├ė┌ė¢ŠÜ─Żą═Ż¼Ą½ļSų°TPU 2.0Ą─░l▓╝Ż¼ą┬ę╗┤·TPU│²┴╦┐╔ęįų¦│ų═ŲöÓęį═ŌŻ¼▀Ć─▄Ė▀ą¦ų¦│ųė¢ŠÜŁh╣ØĄ─╔ŅČ╚ŠWĮj╝ė╦┘ĪŻĖ∙ō■╣╚ĖĶ┼¹┬ČĄ─£yįćöĄō■Ż¼╣╚ĖĶį┌ūį╔ĒĄ─╔ŅČ╚īW┴ĢĘŁūg─Żą═Ą─īŹ█`ųąŻ¼╚ń╣¹į┌32ēKĒö╝ēGPU╔Ž▓óąąė¢ŠÜŻ¼ąĶę¬ę╗š¹╠ņĄ─ė¢ŠÜĢrķgŻ¼Č°į┌TPU2.0╔ŽŻ¼░╦Ęųų«ę╗éĆTPU PodŻ©TPU╝»╚║Ż¼├┐64éĆTPUĮM│╔ę╗éĆPodŻ®Š═─▄į┌6éĆąĪĢrā╚═Ļ│╔═¼śėĄ─ė¢ŠÜ╚╬äšĪŻ
3.GPU
╝┤łDą╬╠Ä└ĒŲ„ĪŻūŅ│§╩Ūė├į┌éĆ╚╦ļŖ─XĪó╣żū„šŠĪóė╬æ“ÖC║═ę╗ą®ęŲäėįOéõ╔Ž▀\ąą└LłD▀\╦Ń╣żū„Ą─╬ó╠Ä└ĒŲ„Ż¼┐╔ęį┐ņ╦┘Ąž╠Ä└ĒłDŽ±╔ŽĄ─├┐ę╗éĆŽ±╦ž³cĪŻ║¾üĒ┐ŲīW╝ę░l¼FŻ¼Ųõ║Ż┴┐öĄō■▓óąą▀\╦ŃĄ──▄┴”┼c╔ŅČ╚īW┴ĢąĶŪ¾▓╗ų\Č°║ŽŻ¼ę“┤╦Ż¼▒╗ūŅŽ╚ę²╚ļ╔ŅČ╚īW┴ĢĪŻ2011─ĻģŪČ„▀_Į╠╩┌┬╩Ž╚īóŲõæ¬ė├ė┌╣╚ĖĶ┤¾─Xųą▒Ń╚ĪĄ├¾@╚╦ą¦╣¹Ż¼ĮY╣¹▒Ē├„Ż¼12Ņwėóéź▀_Ą─GPU┐╔ęį╠ß╣®ŽÓ«öė┌2000ŅwCPUĄ─╔ŅČ╚īW┴Ģąį─▄Ż¼ų«║¾╝~╝s┤¾īWĪóČÓéÉČÓ┤¾īWęį╝░╚╩┐╚╦╣żųŪ─▄īŹ“×╩ęĄ─蹊┐╚╦åT╝Ŗ╝Ŗį┌GPU╔Ž╝ė╦┘Ųõ╔ŅČ╚╔±ĮøŠWĮjĪŻ
GPUų«╦∙ęįĢ■▒╗▀x×ķ│¼╦ŃĄ─ė▓╝■Ż¼╩Ūę“×ķ─┐Ū░ę¬Ū¾ūŅĖ▀Ą─ėŗ╦Ńå¢Ņ}š²║├ĘŪ│Ż▀m║Ž▓óąął╠ąąĪŻę╗éĆų„ꬥ─└²ūėŠ═╩Ū╔ŅČ╚īW┴ĢŻ¼▀@╩Ū╚╦╣żųŪ─▄Ż©AIŻ®ūŅŽ╚▀MĄ─ŅIė“ĪŻ╔ŅČ╚īW┴Ģęį╔±ĮøŠWĮj×ķ╗∙ĄAĪŻ╔±ĮøŠWĮj╩ŪŠ▐┤¾Ą─ŠWĀŅĮYśŗŻ¼ŲõųąĄ─╣سc▀BĮėĘŪ│ŻÅ═ļsĪŻė¢ŠÜę╗éĆ╔±ĮøŠWĮjīW┴ĢŻ¼║▄Ž±╬ęéā┤¾─Xį┌īW┴ĢĢrŻ¼Į©┴ó║═į÷ÅŖ╔±Įøį¬ų«ķgĄ─┬ōŽĄĪŻÅ─ėŗ╦ŃĄ─ĮŪČ╚šfŻ¼▀@éĆīW┴Ģ▀^│╠┐╔ęį╩Ū▓󹹥─Ż¼ę“┤╦╦³┐╔ęįė├GPUė▓╝■üĒ╝ė╦┘ĪŻ▀@ĘNÖCŲ„īW┴ĢąĶꬥ─└²ūėöĄ┴┐║▄ČÓŻ¼═¼śėę▓┐╔ęįė├▓óąąėŗ╦ŃüĒ╝ė╦┘ĪŻį┌GPU╔Ž▀MąąĄ─╔±ĮøŠWĮjė¢ŠÜ─▄▒╚CPUŽĄĮy┐ņįSČÓ▒ČĪŻ─┐Ū░Ż¼╚½Ū“70%Ą─GPUąŠŲ¼╩ął÷Č╝▒╗NVIDIAš╝ō■Ż¼░³└©╣╚ĖĶĪó╬ó▄øĪóüå±R▀dĄ╚Š▐Ņ^ę▓═©▀^┘Å┘INVIDIAĄ─GPU«aŲĘöU┤¾ūį╝║öĄō■ųąą─Ą─AIėŗ╦Ń─▄┴”ĪŻ
4.ŅÉ╚╦─XąŠŲ¼
ŅÉ╚╦─XąŠŲ¼╝▄śŗ╩Ūę╗┐Ņ─ŻöM╚╦─XĄ─ą┬ą═ąŠŲ¼ŠÄ│╠╝▄śŗŻ¼▀@ĘNąŠŲ¼Ą─╣”─▄ŅÉ╦Ųė┌┤¾─XĄ─╔±Įø═╗ė|Ż¼╠Ä└ĒŲ„ŅÉ╦Ųė┌╔±Įøį¬Ż¼Č°Ųõ═©ėŹŽĄĮyŅÉ╦Ųė┌╔±Įø└wŠSŻ¼┐╔ęįį╩įSķ_░lš▀×ķŅÉ╚╦─XąŠŲ¼įOėŗæ¬ė├│╠ą“ĪŻ═©▀^▀@ĘN╔±Įøį¬ŠWĮjŽĄĮyŻ¼ėŗ╦ŃÖC┐╔ęįĖąų¬Īóėøæø║═╠Ä└Ē┤¾┴┐▓╗═¼Ą─ŪķørĪŻ
IBMĄ─ True NorthąŠŲ¼Š═╩ŪŲõųąę╗éĆĪŻ2014─ĻŻ¼IBM╩ū┤╬═Ų│÷┴╦True NorthŅÉ╚╦─XąŠŲ¼Ż¼▀@┐ŅąŠŲ¼╝»║Ž┴╦54ā|éĆŠ¦¾w╣▄Ż¼śŗ│╔┴╦ę╗éĆėą100╚féĆ─ŻöM╔±Įøį¬Ą─ŠWĮjŻ¼▀@ą®╔±Įøį¬ė╔öĄ┴┐²ŗ┤¾Ą──ŻöM╔±Įø═╗ė|äėŽÓ▀BĮėĪŻTrue North╠Ä└Ē─▄┴”ŽÓ«öė┌1600╚féĆ╔±Įøį¬║═40ā|éĆ╔±Įø═╗ė|Ż¼į┌ł╠ąąłDŽ¾ūRäe┼cŠC║ŽĖą╣┘╠Ä└ĒĄ╚Å═ļsšJų¬╚╬äšĢrŻ¼ą¦┬╩ę¬▀h▀hĖ▀ė┌é„ĮyąŠŲ¼ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║╚╦╣żųŪ─▄ąŠŲ¼ĄĮĄūėą║╬▓╗═¼Ż┐
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/solutions/14019324391.html






















