



0 ę²čį
ļSų°śI䚥─┐ņ╦┘░lš╣Īóė├æ¶Ą─│ų└mį÷╝ė║═ęŲäė╗ź┬ōŠWĄ─┼dŲŻ¼ųąć°ęŲäėš²├µ┼Rų°öĄō■Ą─▒¼š©ąįį÷ķLĪŻ╚ń║╬┐ņ╦┘Ąž╠Ä└Ē║Ż┴┐öĄō■Ż¼╝░Ģrėąą¦ĄžÅ─║Ż┴┐öĄō■ųą╠ß╚ĪėąārųĄĄ─ą┼ŽóŻ¼╩Ūųąć°ęŲäėĄ─╔╠äšųŪ─▄(Business IntelligenceŻ¼BI)ŽĄĮyžĮĒÜĮŌøQĄ─å¢Ņ}ĪŻ
BIŽĄĮyÅ─Ų¾śI╔·«aŽĄĮyųą╠ß╚Ī│÷ėąė├öĄō■▓ó▀MąąŪÕŽ┤Ż¼╚╗║¾Įø▀^│ķ╚Ī(Extraction)Īó▐DōQ(Transformation)║═čb▌d(Load)Ż¼╝┤ETL▀^│╠Ż¼īóöĄō■║Ž▓óĄĮę╗éĆŲ¾śI╝ēĄ─öĄō■é}Äņ└’ĪŻį┌┤╦╗∙ĄA╔ŽĪŻ└¹ė├║Ž▀mĄ─▓ķįā║═Ęų╬÷╣żŠ▀ĪóöĄō■═┌Š“(Data MiningŻ¼DM)╣żŠ▀Īóį┌ŠĆĘų╬÷(OnLine Analytical ProcessingŻ¼OLAP)╣żŠ▀Ą╚ī”Ųõ▀MąąĘų╬÷║═╠Ä└ĒŻ¼ūŅ║¾ą╬│╔ų¬ūRŻ¼ų¦│ųŲ¾śIøQ▓▀ĪŻ
öĄō■Ą─║Ż┴┐į÷ķLŻ¼╠Ä└Ē▀\╦ŃĄ─╚šęµÅ═ļsŻ¼╩╣é„ĮyBIŽĄĮy├µ┼RįĮüĒįĮ┤¾Ą─ē║┴”Ż¼ļyęįØMūŃąĶŪ¾Ż¼ų„ę¬¾w¼F×ķęįŽ┬ā╔³cŻ║
1)ėŗ╦Ńąį─▄Ą═ĪŻ
é„ĮyĄ─BIŽĄĮyŻ¼ŲõBI─▄┴”Ą─īŹ¼F═∙═∙▓╔ė├╗∙ė┌ā╚┤µĄ─┤«ąąÖCųŲĪŻ╝┤īóöĄō■╚½▓┐╗“┼·┴┐ī¦╚ļā╚┤µųąŻ¼į┘ę└┤╬▀Mąą╠Ä└ĒĪŻŲõ╠Ä└Ēąį─▄╩▄Ž▐ė┌å╬┼_ÖCŲ„Ą─ā╚┤µ╚▌┴┐║═ėŗ╦Ń─▄┴”Ż¼¤oĘ©ų¦│ų║Ż┴┐öĄō■Ą─Ęų╬÷╠Ä└ĒĪŻ
2)┐╔öUš╣ąį▓ŅĪŻ
┐╔öUš╣ąį╩ŪųĖ╠Ä└Ēąį─▄ļSŽĄĮyęÄ─Żį÷ķLĄ──▄┴”Ż¼╩ŪįOėŗBIŽĄĮy╦∙ūĘŪ¾Ą─ę╗éĆųžę¬─┐ś╦ĪŻ─┐Ū░Ą─BIŽĄĮy╚▒Ę”ę╗éĆįOėŗ┴╝║├Īó┐╔öUš╣ąįÅŖĄ─╝▄śŗŻ¼ŽĄĮyĄ─ą¦┬╩▓╗╩ŪļSų°ėŗ╦Ń┘Yį┤Ą─į÷╝ėČ°│╩ŠĆąįį÷ķLŻ¼«öŽĄĮyĄĮ▀_ę╗Č©ęÄ─ŻĢrĢ■│÷¼Fą¦┬╩ĮĄĄ═Īół╠ąąĢrķgļyęįŅA£yĄ╚å¢Ņ}ĪŻ
×ķØMūŃ║Ż┴┐öĄō■Ą─ėŗ╦Ńę¬Ū¾Ż¼▒Ż│ų┐ņ╦┘Ą─Ēææ¬║═Ė▀ąį─▄ł╠ąąŻ¼īŹ¼FBI╦ŃĘ©Ą─▓óąą╗»╩ŪĮŌøQ╔Ž╩÷å¢Ņ}Ą─ĻPµIĪŻßśī”ęį╔Žå¢Ņ}Ż¼▒Š╬─Å─¼F┤·BIŽĄĮyĄ─ąĶŪ¾│÷░lŻ¼čąŠ┐▓óīŹ¼F┴╦ę╗ĘN╗∙ė┌▓óąąÖCųŲĄ─╔╠äšųŪ─▄ŽĄĮyBI-PaaSŻ¼įōŽĄĮy┤ŅĮ©į┌ųąć°ęŲäė“┤¾įŲ”╗∙ĄAįO╩®ų«╔ŽŻ¼īŹ¼F┴╦▓󹹥─ETLĪóDMĪóOLAPĪóReportĄ╚Ė„ŅÉBI─▄┴”Ż¼╩╣Ą├BIæ¬ė├─▄ē“ØMūŃ║Ż┴┐öĄō■╠Ä└ĒąĶŪ¾ĪŻ
1 BI-PaaS
1.1 BI-PaaS╝▄śŗ
PaaS(Platform as a Service)╩Ūę╗ĘN╗∙ė┌įŲėŗ╦ŃĄ─Ę■䚯¼īóįŲŲĮ┼_─▄┴”▀MąąĘŌčbŻ¼▓ó╠ß╣®╗∙ė┌įŲ╗∙ĄAįO╩®Ą─ķ_░l║══ą╣▄ŁhŠ│ĪŻĄõą═Ą─PaaSėąForce.com║═Google App EngineĪŻPaaS×ķØMūŃæ¬ė├Ą─▒ŃĮ▌ķ_░l║═Ė▀ąį─▄ł╠ąą╠ß╣®┴╦ę╗ĘNėąą¦Ą─╩ųČ╬ĪŻę“┤╦Ż¼▒Š╬─īóPaaSĄ─įOėŗįŁ└Ēę²╚ļBIŽĄĮyŻ¼╠ß│÷┴╦BI-PaaSŽĄĮyŻ¼įōŽĄĮyė╔ķ_░l╠ū╝■ĪóBI-PaaSŲĮ┼_ā╔▓┐ĘųĮM│╔Ż¼¾wŽĄ╝▄śŗ╚ńłD1╦∙╩ŠĪŻ
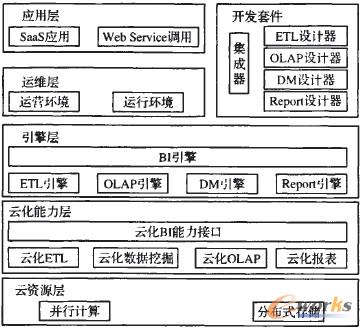
łD1 BI-PaaS¾wŽĄ╝▄śŗ
ķ_░l╠ū╝■ė╔ę╗ŽĄ┴ąBI╚╬äšłDą╬įOėŗŲ„║═ę╗éĆ╝»│╔Ų„ĮM│╔ĪŻBI╚╬äšłDą╬įOėŗŲ„░³└©ETLįOėŗŲ„ĪóDMįOėŗŲ„ĪóOLAPįOėŗŲ„║═ReportįOėŗŲ„ĪŻĖ„éĆįOėŗŲ„Ęųäeīóī”æ¬Ą─BI─▄┴”ęįį¬öĄō■Ą─ĘĮ╩Į▀MąąĘŌčbŻ¼▓ó▀MąąłDą╬╗»š╣╩ŠĪŻæ¬ė├ķ_░lš▀▀xō±Ė„ĘNBIłDą╬įOėŗŲ„Ż¼ęį═Ž└ŁĄ─ĘĮ╩Į▀MąąŽÓæ¬BI╚╬äšķ_░lĪŻĖ„éĆBI╚╬äšķ_░l═Ļ│╔ų«║¾Ż¼▓╔ė├╝»│╔Ų„░čĖ„éĆBI╚╬äšĮMčb╝»│╔×ķBIæ¬ė├Ż¼╔·│╔į¬öĄō■├Ķ╩÷╬─╝■Ż¼▓óīóŲõ▓┐╩ĄĮBI-PaaSŲĮ┼_ĪŻķ_░l╠ū╝■Ą─ę²╚ļŻ¼╝░ŲõłDą╬╗»Ą─▓┘ū„ĘĮ╩ĮŻ¼śO┤¾Ąž╠ßĖ▀┴╦BIæ¬ė├Ą─ķ_░lą¦┬╩ĪŻ
BI-PaaSŲĮ┼_░³└©æ¬ė├īėĪó▀\ŠSīėĪóę²ŪµīėĪóįŲ╗»─▄┴”īė║═įŲ┘Yį┤īėĪŻįŲ┘Yį┤īė▓╔ė├HadoopśŗĮ©Ęų▓╝╩Į┤µā”║═▓óąąėŗ╦ŃŁhŠ│Ż¼×ķBI-PaaSŲĮ┼_╠ß╣®ų¦ō╬Ż╗įŲ╗»─▄┴”īė╠ß╣®┴╦ETLĪóOLAPĪóDMĪóReportĄ╚Ė„ŅÉBIĮM╝■Ą─▓óąąīŹ¼FŻ╗ę²Ūµīėžōž¤ETLĪóOLAPĪóDMĪóReportĄ╚BI╚╬䚥─╝»│╔┼cĮŌ╬÷Ż╗▀\ŠSīė╠ß╣®ė├æ¶ūóāįĪóæ¬ė├▓┐╩Īóæ¬ė├▒O┐žĪóöĄō■Ė¶ļxĪóæ¬ė├ł╠ąąĄ╚╗∙ĄAĘ■䚯╗æ¬ė├īė╩Ū═Ō▓┐ūŌæ¶įLå¢BIæ¬ė├Ą─Įė┐┌ĪŻ
1.2 BI-PaaS╠ž³c
BI-PaaS▓╗═¼ė┌é„ĮyĄ─BI«aŲĘŻ¼Š▀ėąęįŽ┬╠ž³cŻ║
1)Ė▀Č╚▓󹹯¼Ęų▓╝┤µā”ĪŻ
BI-PaaSęįHadoopüĒ┤ŅĮ©Ąūīė╗∙ĄAįO╩®ĪŻHadoop╩Ūę╗éĆ▒╗įOėŗė├üĒį┌ė╔Ųš═©ė▓╝■įOéõĮM│╔Ą─┤¾ą═╝»╚║╔Žł╠ąąĘų▓╝╩Įæ¬ė├Ą─ķ_į┤┐“╝▄Ż¼░³└©ā╔┤¾║╦ą─į¬╦žŻ║MapReduce║═HDFS(Hadoop Distributed File System)ĪŻMapReduce╩Ūę╗ĘN▓󹹊Ä│╠─Żą═Ż¼╗∙ė┌┤╦─Żą═┐╔ęįīŹ¼FŠ▀ėą┴╝║├┐╔öUš╣ąįĄ─╦ŃĘ©Ż╗HDFS╩Ūę╗ĘNĘų▓╝╩Į╬─╝■ŽĄĮyŻ¼╠ß╣®┴╦ĘĆČ©Ą─öĄō■┤µā”ŁhŠ│ĪŻBI-PaaSĮ©┴óį┌Hadoopų«╔ŽŻ¼īóETLĪóDMĪóOLAPĪóReportĄ╚Ė„ŅÉBI─▄┴”▓óąą╗»Ż¼ęįØMūŃ║Ż┴┐öĄō■┤µā”Īóėŗ╦Ń║═Ęų╬÷Ą─ąĶę¬ĪŻ
2)Į³╦ŲŠĆąįĄ─Ė▀┐╔öUš╣ąįĪŻ
ļSų°ŽĄĮyžō║╔Ą─ūā╗»Ż¼BI-PaaS┐╔äėæBš{š¹┤µā”║═ėŗ╦Ń╣سcĄ─öĄ┴┐Ż¼üĒØMūŃBIŽĄĮyĄ─ėŗ╦ŃąĶŪ¾Ż¼▒ŻūCĘĆČ©Ą─Ēææ¬Ģrķg┼cł╠ąąąį─▄ĪŻ╝ė╦┘▒╚ĮėĮ³ŠĆąįŻ¼Š▀ėą┴╝║├Ą─öUš╣ą═║═┘Yį┤└¹ė├ą¦┬╩ĪŻ
3)ķ_░l┼c▀\ĀIĘųļxĪŻ
BI-PaaS×ķķ_░lš▀╠ß╣®▒ŃĮ▌Ą─ķ_░l║═▓┐╩ŁhŠ│Ż¼╝░Ė▀ąį─▄║═Ė▀┐╔öUš╣Ą─▀\ąąŁhŠ│ĪŻBI-PaaSČ©┴x┴╦ūį╝║ų¦│ųĄ─æ¬ė├│╠ą“─Żą═Ż¼×ķķ_░l║══ą╣▄ŁhŠ│╠ß╣®ę╗éĆ└ĒĮŌæ¬ė├│╠ą“Ą─Įyę╗ęÄĘČĪŻķ_░lŁhŠ│╠ß╣®┴╦Č©ųŲ║═▓┐╩æ¬ė├│╠ą“Ą─╗∙▒ŠŠÄ│╠į¬╦žĪŻ═ą╣▄ŁhŠ│×ķ╦∙═ą╣▄Ą─æ¬ė├╠ß╣®┴╦┐╔╔ņ┐sĄ─ėŗ╦Ń║═┤µā”┘Yį┤Ż¼▒ŻūCæ¬ė├Ą─Ė▀ą¦ł╠ąąĪŻ
2 ▓óąąÖCųŲ
2.1 MapReduce▓óąą─Żą═
MapReduce╩ŪDeanĄ╚ĪŻį┌2004─Ļ╠ß│÷Ą─▓óąą┐“╝▄ĪŻį┌įō┐“╝▄Ž┬Ż¼öĄō■▒╗│ķŽ¾×ķ(keyŻ¼value)Ą─ą╬╩ĮŻ¼Č°ßśī”öĄō■Ą─▓┘ū„▒╗│ķŽ¾×ķMap║═Reduceā╔éĆ▀^│╠ĪŻŲõųąŻ¼Map╩Ūīóę╗éĆū„śIĘųĮŌ│╔×ķČÓéĆ╚╬䚯¼Č°ReduceŠ═╩Ūīó▀@ą®╚╬äš╠Ä└ĒĄ─ĮY╣¹ģR┐éŻ¼Å─Č°½@Ą├ūŅĮKĮY╣¹ĪŻė├æ¶ąĶę¬ūįČ©┴xīŹ¼FMap║═Reduceā╔éĆ║»öĄĪŻ
╚ńłD2╦∙╩ŠŻ¼ę╗éĆMapReduce╚╬äšīó▌ö╚ļöĄō■╝»ĘųĖŅ│╔ŽÓ╗ź¬Ü┴óĄ─╚¶Ė╔ēKŻ¼ęį▒ŃMap─▄ęį═Ļ╚½▓ó░lĄ─ĘĮ╩Į▀MąąĪŻę╗éĆMapReduceĄ─╚╬äš░³└©3éĆļAČ╬Ż║Ą┌ę╗éĆļAČ╬▀MąąöĄō■ĘųĖŅŻ¼ĘųĖŅ║¾Ą─├┐éĆöĄō■ēKČ╝░³║¼╚¶Ė╔éĆ(keyŻ¼value)ī”Ż¼▓ó▒╗Ęų░lĮoĖ„╣سcĪŻĄ┌Č■éĆļAČ╬▀MąąśIäš╠Ä└ĒŻ¼ųąąūx╚ļöĄō■ēKųąĄ─<keyŻ¼value>ī”Ż¼Įø▀^╠Ä└Ē║¾Ą├ĄĮųąķgĮY╣¹ĪŻųąķgĮY╣¹═¼śėęį<keyŻ¼value>Ą─ą╬╩Į▒Ē╩ŠŻ¼▓ó░┤šškeyųĄ┼┼ą“ĪóĘųģ^Ż¼░čkeyųĄŽÓ═¼Ą─ĮY╣¹║Ž▓óį┌ę╗ŲĪŻĄ┌╚²ļAČ╬▀MąąReduce▓┘ū„Ż¼īóĖ„éĆMapĄ─ųąķgĮY╣¹Å═ųŲĄĮReduce╣سcŻ¼ī”ŽÓ═¼keyųĄĄ─ųąķgĮY╣¹▀Mąą║Ž▓óĄ├ĄĮūŅĮKĮY╣¹Ż¼▓óęį(keyŻ¼value)Ą─ą╬╩Į▌ö│÷ĪŻ
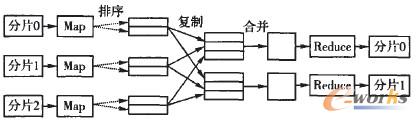
łD2 Map-ReduceŠÄ│╠─Żą═
2.2 ETL▓óąąīŹ¼F
ETLžōž¤öĄō■Ą─│ķ╚ĪĪó▐DōQ║═čb▌dŻ¼×ķ║¾└mĄ─öĄō■═┌Š“╠ß╣®ę╗ŽĄ┴ą▌^╝Ü┴ŻČ╚Ą─ŅA╠Ä└Ē▓┘ū„ĪŻ▒Š╬─╗∙ė┌MapReduceŽĄĮyĄžīŹ¼F┴╦▓óąąETLŻ¼░³└©Ą½▓╗Ž▐ė┌ęįŽ┬▓┘ū„Ż║ī┘ąį▓┘ū„Īó╚▒ųĄ╠Ä└ĒĪó╚źųžÅ═ųĄĪóģ^ķg╗»ĪóöĄō■▀BĮėĪŻŽ┬├µ┼e└²šf├„╔Ž╩÷ÄūĘNETL▓┘ū„Ą─Š▀¾w▓óąą╗»īŹ¼F▀^│╠ĪŻ
2.2.1 ╚▒ųĄ╠Ä└Ē
įŁ╩╝öĄō■ėøõøųąĄ──│ą®ī┘ąįĄ─╚▒ųĄĢ■ė░ĒæöĄō■═┌Š“╦ŃĘ©ī”ė┌ī┘ąįĄ─ūRäe┼c╠Ä└ĒŻ¼▒žĒÜėĶęį╠Ņ│õĪŻ╚▒ųĄ╠Ä└Ē╩Ūßśī”įŁ╩╝öĄō■ėøõøųąĄ─╚▒ųĄī┘ąįė├┐═æ¶ųĖČ©öĄō■ųĄ▀Mąą╠Ņ│õĪŻ▓óąą╚▒ųĄ╠Ä└ĒĄ─īŹ¼F░³└©ę╗éĆMapŻ¼¤oReduceĪŻų„ę¬▓Į¾E╚ńŽ┬ĪŻ
1)ŅA╠Ä└ĒŻ║┐é┐ž╣سcīó┤²╠Ä└ĒöĄō■ĘųĖŅ×ķēKŻ¼Ęų▓╝╩Į┤µā”ĄĮČÓ╝»╚║ŁhŠ│ųąĪŻ
2)MapŻ║
ó┘Å─öĄō■ēKųąųąąūx╚ļ<keyŻ¼value)ī”Ż¼Ųõųąkey×ķ├┐ąąöĄō■Ą─Ų½ęŲ┴┐Ż¼value×ķįōąąėøõøĄ─╬─▒Šą╬╩ĮŻ╗
ó┌ĮŌ╬÷valueųĄŻ¼ī”ŲõųąĄ─╚▒ųĄī┘ąįė├ė├æ¶ųĖČ©ųĄ╠µōQŻ¼Ę±ät▒Ż│ųįŁ╩╝ųĄ▓╗ūāŻ╗
ó█īó╠Ä└ĒĮY╣¹ą╬│╔MapĄ─▌ö│÷(keyŻ¼value)ī”Ż¼Ųõųąkey×ķ┐š╬─▒ŠŻ¼value×ķ╠Ä└Ē▀^║¾Ą─├┐ąą╬─▒ŠŻ╗
ó▄īóMap╠Ä└Ē║¾Ą─ĮY╣¹▌ö│÷ĄĮHDFSĪŻ
2.2.2 ╚źųžÅ═ųĄ
╚źųžÅ═ųĄ╩ŪīóöĄō■śė▒ŠųąĄ─ųžÅ═ėøõø▀Mąąäh│²Ż¼ų╗▒Ż┴¶ųžÅ═ėøõøųąĄ─ę╗ŚlĪŻ▓óąąąąā╚╚źųž░³└©ę╗éĆMap║═ę╗éĆReduceĪŻų„ę¬▓Į¾E╚ńŽ┬ĪŻ
1)ŅA╠Ä└ĒŻ║┐é┐ž╣سcīó┤²╠Ä└ĒöĄō■ĘųĖŅ×ķēKŻ¼Ęų▓╝╩Į┤µā”ĄĮ╝»╚║ŁhŠ│ųąĪŻ
2)MapŻ║
ó┘Å─öĄō■ēKųąųąąūx╚ļ<keyŻ¼value>ī”Ż¼Ųõųąkey×ķ├┐ąąöĄō■Ą─Ų½ęŲ┴┐Ż¼value×ķįōąąėøõøĄ─╬─▒Šą╬╩ĮŻ╗
ó┌ų▒Įėīóįōąąėøõøą╬│╔MėĪĄ─▌ö│÷(keyŻ¼value)ī”Ż¼Ųõųąkey×ķįōąąėøõøŻ¼value×ķ┐š╬─▒ŠĪŻ
3)ReduceŻ║
ó┘╩š╝»Š▀ėąŽÓ═¼keyųĄĄ─öĄō■Ż¼ų▒Įėą╬│╔ReduceĄ─▌ö│÷(keyŻ¼value)ī”Ż¼Ųõųąkey×ķš¹ąąöĄō■Ż¼value×ķ┐š╬─▒ŠŻ¼╝┤┐╔īŹ¼F╚ź│²ųžÅ═ėøõøŻ╗
ó┌īóĮY╣¹▌ö│÷ĄĮHDFSĪŻ
2.2.3 ī┘ąį▓┘ū„
ī┘ąį▓┘ū„ų„ę¬░³└©ī┘ąįĮ╗ōQĪóī┘ąįäh│²Īóī┘ąįųĄ╠Ē╝ėĪŻ¼Fęįī┘ąį╠Ē╝ė×ķ└²Ż¼šf├„Š▀¾wĄ─▓óąą╗»īŹ¼FĪŻī┘ąįųĄ╠Ē╝ė╩ŪųĖßśī”├┐ę╗ąąöĄō■Ż¼Ė∙ō■┤_Č©Ą─ėŗ╦Ń╣½╩ĮŻ¼ī”ęčėąī┘ąįųĄ▀Mąąėŗ╦ŃŻ¼½@Ą├ą┬ī┘ąįųĄŻ¼▓ó╠Ē╝ėĄĮėøõøĄ──®╬▓ĪŻ▓óąąī┘ąį╠Ē╝ė▓┘ū„░³└©ę╗éĆMapŻ¼¤oReduceĪŻ╠Ē╝ėą┬ī┘ąįĄ─ų„ę¬▓Į¾E╚ńŽ┬ĪŻ
1)ŅA╠Ä└ĒŻ║┐é┐ž╣سcīó┤²╠Ä└ĒöĄō■ĘųĖŅ×ķēKŻ¼Ęų▓╝╩Į┤µā”ĄĮ╝»╚║ŁhŠ│ųąĪŻ
2)MapŻ║
ó┘Å─öĄō■ēKųąųąąūx╚ļ(keyŻ¼value)ī”Ż¼Ųõųąkey×ķ├┐ąąöĄō■Ą─Ų½ęŲ┴┐Ż¼value×ķįōąąėøõøĄ─╬─▒Šą╬╩ĮŻ╗
ó┌ĮŌ╬÷valueųĄŻ¼½@Ą├Ųõųą├┐éĆī┘ąįĄ─ųĄŻ¼╚╗║¾░┤ššėŗ╦Ń▒Ē▀_╩Įī”ęčĮøėąī┘ąįųĄ▀Mąąėŗ╦ŃŻ¼½@Ą├ą┬ī┘ąįųĄŻ¼īæį┌įōąąėøõøĄ──®╬▓Ż║
ó█īó╠Ä└ĒĮY╣¹ą╬│╔MėĪĄ─▌ö│÷(keyŻ¼value)ī”Ż¼Ųõųąkey×ķ┐š╬─▒ŠŻ¼value×ķ╠Ä└Ē▀^║¾Ą─├┐ąą╬─▒ŠŻ╗
ó▄īóMap╠Ä└Ē║¾Ą─ĮY╣¹▌ö│÷ĄĮHDFSĪŻ
2.2.4 ģ^ķg╗»
ģ^ķg╗»╩Ūßśī”▀B└mąįöĄųĄą═öĄō■Ż¼īóŲõęÄ╝s×ķ─│ą®ģ^ķgųĄĪŻ└²╚ńė├æ¶─Ļ²gūųČ╬Ż¼┐╔░┤šš╚ńŽ┬ęÄätīŹ¼Fģ^ķg╗»Ż║0Ī½9ÜqÜw×ķŅÉ0,10Ī½19ÜqÜw×ķŅÉ1Ż¼ę└┤╦ŅÉ═ŲŻ¼90Üqęį╔ŽÜw×ķŅÉ9ĪŻ▓óąąģ^ķg╗»░³└©ę╗éĆMapŻ¼¤oReduceĪŻų„ę¬▓Į¾E╚ńŽ┬ĪŻ
1)ŅA╠Ä└ĒŻ║┐é┐ž╣سcīó┤²╠Ä└ĒöĄō■ĘųĖŅ×ķēKŻ¼Ęų▓╝╩Į┤µā”ĄĮ╝»╚║ŁhŠ│ųąĪŻ
2)MapŻ║
ó┘Å─öĄō■ēKųąųąąūx╚ļ(keyŻ¼value)ī”Ż¼Ųõųąkey×ķ├┐ąąöĄō■Ą─Ų½ęŲ┴┐ĪŻvalue×ķįōąąėøõøĄ─╬─▒Šą╬╩ĮŻ╗
ó┌ĮŌ╬÷valueųĄŻ¼½@Ą├Ųõųą╦∙ąĶ╠Ä└ĒĄ─ī┘ąįĄ─öĄųĄŻ¼į┌ģ^ķg╗»ė│╔õĻPŽĄĄ─ųĖī¦Ž┬Ż¼īóįŁöĄųĄą═öĄō■╠µōQ×ķŽÓæ¬Ą─ģ^ķgŅÉäeŻ╗
ó█īó╠Ä└ĒĮY╣¹ą╬│╔MapĄ─▌ö│÷(keyŻ¼value)ī”Ż¼Ųõųąkey×ķ┐š╬─▒ŠŻ¼value×ķ╠Ä└Ē▀^║¾Ą─├┐ąą╬─▒ŠŻ╗
ó▄īóMap╠Ä└Ē║¾Ą─ĮY╣¹▌ö│÷ĄĮHDFSĪŻ
2.3 öĄō■═┌Š“▓óąąīŹ¼F
öĄō■═┌Š“╩ŪųĖÅ─┤¾┴┐Ą─Īó▓╗═Ļ╚½Ą─Īóėąįļ┬ĢĄ─Īó─Ż║²Ą─öĄō■ųą╠ß╚Īļ[║¼Ą─Īó╬┤ų¬Ą─ĪóĘŪŲĮĘ▓Ą─╝░ėąØōį┌æ¬ė├ārųĄĄ─ą┼Žó╗“─Ż╩ĮĪŻöĄō■═┌Š“Ą─ę╗éĆųžę¬╣”─▄╩ŪöĄō■ĘųŅÉŻ¼╝┤īóöĄō■ė│╔õĄĮŅAŽ╚Č©┴x║├Ą─╚║ĮM╗“ŅÉĪŻ─┐Ū░│Żė├Ą─ĘųŅÉĘĮĘ©×ķ╗∙ė┌øQ▓▀śõĄ─ĘĮĘ©ĪŻ
▒Š╬─╗∙ė┌Map ReduceÖCųŲīŹ¼F┴╦▓óąąöĄō■═┌Š“Ż¼Ž┬├µęįøQ▓▀śõ×ķ└²šf├„öĄō■═┌Š“Ą─▓óąą╗»īŹ¼FĪŻ
ė├øQ▓▀śõ▀MąąĘųŅÉų„ę¬░³└©ā╔éĆ▓Į¾EŻ║Ą┌ę╗▓Į╩Ū└¹ė├ė¢ŠÜ╝»╔·│╔ę╗┐├øQ▓▀śõŻ¼Į©┴óøQ▓▀śõ─Żą═Ż¼▀@éĆ▀^│╠īŹļH╔Ž╩Ūę╗éĆÅ─öĄō■ųą½@╚Īų¬ūRŻ¼▀MąąÖCŲ„īW┴ĢĄ─▀^│╠Ż╗Ą┌Č■▓Į╩Ū└¹ė├╔·│╔Ą─øQ▓▀śõī”▌ö╚ļöĄō■▀MąąĘųŅÉŻ¼ī”▌ö╚ļĄ─ėøõøŻ¼Å─Ė∙╣سcę└┤╬£yįćėøõøĄ─ī┘ąįųĄŻ¼ų▒ĄĮĄĮ▀_─│éĆ╚~ūė╣سcŻ¼Å─Č°šęĄĮįōėøõø╦∙į┌Ą─ŅÉĪŻ
øQ▓▀śõ╔·│╔ĘĮĘ©╩Ū═©▀^ūįĒöŽ“Ž┬į÷ķL╣سcīŹ¼FĄ─Ż¼╔·│╔▀^│╠╚ńłD3╦∙╩ŠĪŻŠ▀¾w▓Į¾E╚ńŽ┬Ż║
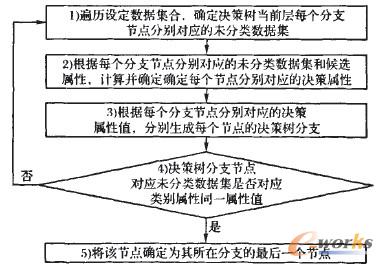
łD3 øQ▓▀śõśŗĮ©▀^│╠
1)▒ķÜvįOČ©öĄō■╝»║ŽŻ¼┤_Č©øQ▓▀śõ«öŪ░īė├┐éĆĘųų¦╣سcĘųäeī”æ¬Ą─╬┤ĘųŅÉöĄō■╝»ĪŻ
2)Ė∙ō■├┐éĆĘųų¦╣سcĘųäeī”æ¬Ą─öĄō■╝»║═║“▀xī┘ąį╝»║ŽŻ¼═©▀^Ęųäeėŗ╦Ń║“▀xī┘ąįĄ─ą┼Žóį÷ęµųĄĪŻ▀x╚ĪŠ▀ėąūŅ┤¾ą┼Žóį÷ęµųĄĄ─öĄō■ī┘ūĪū„×ķįō╣سcī”æ¬Ą─øQ▓▀ī┘ąįĪŻ
3)Ė∙ō■├┐éĆĘųų¦╣سcĘųäeī”æ¬Ą─øQ▓▀ī┘ąįĄ─ī┘ąįųĄŻ¼Ęųäe╔·│╔├┐éĆĘųų¦╣سcĄ─øQ▓▀śõĘųų¦ĪŻ
4)Ęųäe┼ąöÓ├┐éĆøQ▓▀śõĘųų¦╣سcī”æ¬Ą─öĄō■╝»╩Ūʱī”æ¬ĘųŅÉī┘ąįĄ─═¼ę╗ī┘ąįųĄĪŻ╚ń╣¹ĮY╣¹×ķʱŻ¼ätøQ▓▀śõĘųų¦Ž┬Ą─Āö³c┤_Č©×ķ«öŪ░īėĄ─Ž┬ę╗īėĄ─Ęųų¦╣سcŻ¼▓óīó«öŪ░║“▀xī┘ąį╝»║Ž£p╚ź«öŪ░øQ▓▀ī┘ąįŻ¼ū„×ķįōĘųų¦Ą─║“▀xī┘ąį╝»║ŽŻ¼▓óīóŽ┬ę╗īėū„×ķ«öŪ░īėĘĄ╗ž1)Ż╗╚ń╣¹╩ŪŻ¼ätł╠ąą5)ĪŻ
5)īó┼ąöÓĮY╣¹×ķ“╩Ū”Ą─øQ▓▀śõĘųų¦Ž┬Ą─╣سcĘųäe┤_Č©×ķŲõ╦∙į┌Ęųų¦Ą─ūŅ║¾ę╗éĆ╣سcĪŻ
ųžÅ═1)Ī½5)Ż¼ę└┤╬┤_Č©øQ▓▀śõĄ┌Č■īėų┴ūŅ║¾ę╗īėĖ„╣سcī”æ¬Ą─öĄō■ī┘ąįŻ«ų▒ĄĮĖ„Ęųų¦Ž┬ūŅŽ┬īė╣سcī”æ¬Ą─öĄō■╝»Ż¼Ųõųą╦∙ėąėøõøĄ─ĘųŅÉī┘ąįĮį×ķ═¼ę╗ī┘ąįųĄŻ¼ät═Ļ│╔øQ▓▀śõĄ─śŗĮ©▀^│╠ĪŻ
į┌Ą┌2)▓ĮųąĪŻŲõ║╦ą─╩Ū×ķ├┐éĆ╣سc▀x╚Ī─▄ūŅ╝čĘųŅÉ«öŪ░öĄō■╝»Ą─ī┘ąįŻ¼│╔×ķįō╣سcĄ─øQ▓▀ī┘ąįĪŻ│Żė├Ą─ID3║═C4.5Ą╚øQ▓▀śõ╔·│╔╦ŃĘ©Ż¼Č╝ęį├┐éĆ║“▀xī┘ąįĄ─ą┼Žóį÷ęµųĄüĒ║Ō┴┐ŲõĘųŅÉ─▄┴”ĪŻøQ▓▀śõ╔Ž├┐éĆ╣سc▀xō±║“▀xī┘ąįųąŠ▀ėąūŅĖ▀ą┼Žóį÷ęµųĄĄ─ī┘ąįū„×ķūŅ╝čĘųŅÉī┘ąįŻ¼│╔×ķįō╣سcĄ─øQ▓▀ī┘ąįĪŻ×ķĄ├ĄĮ╠žČ©║“▀xī┘ąįĄ─ą┼Žóį÷ęµųĄŻ¼ąĶę¬Įyėŗ┤²ĘųŅÉöĄō■╝»ųąįōī┘ąį├┐éĆī┘ąįųĄī”æ¬▓╗═¼ĘųŅÉŅÉäeĄ─ŅlČ╚Ż¼▀MČ°ėŗ╦Ńįōī┘ąįĄ─ą┼Žóņžęį╝░ą┼Žóį÷ęµųĄĪŻ▀@╩ŪøQ▓▀śõ╔·│╔╦ŃĘ©ųąūŅų„ꬥ─ėŗ╦ŃļAČ╬ĪŻ
ę“┤╦Ż¼×ķ┴╦╠ßĖ▀╠Ä└Ē╦┘Č╚Ż¼ī”Ą┌2)▓Į╠ß╣®▓óąą╗»īŹ¼F(╚ńłD4╦∙╩Š)Ż¼ęį▓󹹥─ĘĮ╩Į┤_Č©øQ▓▀śõųą═¼ę╗īė├┐éĆ║“▀x╣سcĘųäeī”æ¬Ą─øQ▓▀ī┘ąįŻ¼╝┤ęį▓óąąĘĮ╩Įėŗ╦Ń═¼ę╗īė╔Ž├┐éĆ║“▀x╣سcĄ─Ė„║“▀xī┘ąįĄ─ī┘ąįųĄī”æ¬įOČ©ŅÉäeĄ─ŅlČ╚Ż¼▀MČ°Ė∙ō■╦∙Ą├ŅlČ╚ėŗ╦Ńįōī┘ąįĄ─ą┼Žóį÷ęµųĄŻ╗ęį▓óąąĘĮ╩Į┤_Č©Š▀ėąūŅ┤¾ą┼Žóį÷ęµųĄĄ─öĄō■ī┘ąį×ķįō║“▀x╣سcī”æ¬Ą─øQ▓▀ī┘ąįĪŻ
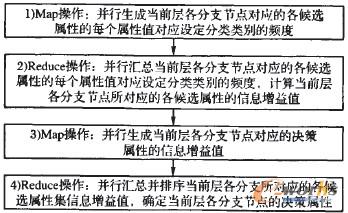
łD4 ┤_Č©øQ▓▀ī┘ąį▓óąą╗»▀^│╠
▓óąą▀^│╠░³└©2éĆMap║═2éĆReduceŻ¼Š▀¾w├Ķ╩÷╚ńŽ┬ĪŻ
1)MapŻ║
ó┘Å─öĄō■ēKųąųąąūx╚ļ<keyŻ¼value>ī”Ż¼Ųõųąkey×ķ├┐ąąöĄō■Ą─Ų½ęŲ┴┐Ż¼value×ķįōąąėøõøĄ─╬─▒Šą╬╩ĮĪŻ
ó┌ĮŌ╬÷valueųĄŻ¼Ė∙ō■ĮŌ╬÷ĮY╣¹ą╬│╔MapĄ─▌ö│÷(keyŻ¼value)ī”Ż¼Ųõųąkey×ķĘųų¦ŠÄ╠¢Ż½║“▀xī┘ąį├¹Ż½║“▀xī┘ąįųĄŻ½ŅÉäeŻ¼value×ķŠų▓┐ŅlČ╚ĪŻ╝┤įōĘųēKöĄō■ūė╝»ųą╦∙ėą╬┤ĘųŅÉöĄō■ī┘ąįĄ─├┐éĆī┘ąįųĄī”æ¬Ą─ŅlČ╚ĮyėŗĒŚĪŻ
ó█īóMap╠Ä└Ē║¾Ą─ĮY╣¹▌ö│÷ĄĮHDFSĪŻ
2)ReduceŻ║
╩š╝»Š▀ėąŽÓ═¼keyųĄĄ─öĄō■Ż¼▓óąą║Ž▓óŽÓ═¼Ęųų¦Ž┬ĪóŠ▀ėąŽÓ═¼║“▀xī┘ąįĄ─▓╗═¼ī┘ąįųĄĄ─ŅlČ╚ĮyėŗĒŚŻ¼▓óėŗ╦Ń├┐éĆĘųų¦Ž┬Īó├┐éĆ║“▀xī┘ąįĄ─ą┼Žóņž║═ą┼Žóį÷ęµųĄŻ╗Reduce▌ö│÷Ą─(keyŻ¼value)ī”×ķŻ║key×ķĘųų¦ŠÄ╠¢Ż¼value×ķī┘ąį├¹+ą┼Žóį÷ęµųĄĪŻ
3)MapŻ║
ó┘ī”Ą┌2)▓ĮĄ─Reduce▌ö│÷╬─╝■ĘųēK▓óę└┤╬ūx╚ļ├┐ąąöĄō■Ż¼ą╬│╔MapĄ─▌ö│÷(keyŻ¼value)ī”Ż¼Ųõųąkey×ķĘųų¦ŠÄ╠¢Ż¼value×ķī┘ąį├¹+ą┼Žóį÷ęµųĄŻ╗
ó┌īóMap╠Ä└Ē║¾Ą─ĮY╣¹▌ö│÷ĄĮHDFSĪŻ
4)ReduceŻ║
╩š╝»Š▀ėąŽÓ═¼keyųĄĄ─öĄō■Ż¼▓óąąīóŠ▀ėąŽÓ═¼(Ęųų¦ŠÄ╠¢)Ą─Ž“┴┐ūė╝»Ż¼░┤ššą┼Žóį÷ęµųĄ┼┼ą“Ż¼▀xō±▓óĘĄ╗žūŅ┤¾ą┼Žóį÷ęµųĄī”æ¬Ą─║“▀xī┘ąįū„×ķįōĘųų¦ŠÄ╠¢ī”æ¬╣سcĄ─øQ▓▀ī┘ąįĪŻReduce▌ö│÷Ą─(keyŻ¼value)ųąŻ¼key×ķĘųų¦ŠÄ╠¢+øQ▓▀ī┘ąį├¹Ż¼value×ķ┐š╬─▒ŠĪŻ
3 īŹ“×
3.1 æ¬ė├īŹ└²
┐═æ¶┴„╩¦ŅA£yį┌ļŖą┼ŅIė“╩Ūę╗éĆ│ŻęŖĄ─æ¬ė├īŹ└²Ż¼ļŖą┼╣½╦ŠĖ∙ō■ęčėąĄ─┐═æ¶Ą─Üv╩ĘöĄō■Ż¼ī”║¾Ų┌┐═æ¶┴„╩¦ąą×ķ▀MąąŅA£yŻ¼ęį▒Ń▓╔╚Ī┤ļ╩®üĒ═ņ┴¶┐═æ¶ĪŻ┐═æ¶┴„╩¦ŅA£yĄ─śIäš┴„│╠╚ńłD5╦∙╩ŠĪŻ
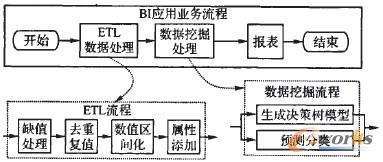
łD5 “┴„╩¦ŅA£y”śIäš┴„│╠
┐═æ¶┴„╩¦ŅA£y╩╣ė├BI-PaaSĄ─ķ_░l╠ū╝■üĒķ_░lŻ¼æ¬ė├ķ_░l░³└©ETLķ_░lĪóDMķ_░lĪóReportķ_░l║═æ¬ė├╝»│╔4éĆ▓Į¾EĪŻ
1)╩╣ė├ETLįOėŗŲ„╔·│╔ETL╠Ä└Ē┴„ĪŻįō┴„│╠═©▀^╚▒ųĄ╠Ä└ĒĪó╚źųžÅ═ųĄ╠Ä└ĒŻ¼═Ļ│╔ī”öĄō■Ą─ŪÕŽ┤╣żū„Ż╗═©▀^öĄō■ģ^ķg╗»╠Ä└ĒŻ¼═Ļ│╔ī”öĄō■Ą─▐DōQ╣żū„Ż¼×ķöĄō■═┌Š“╦ŃĘ©«a╔·║Ž▀mĄ─öĄō■Ė±╩ĮŻ╗═©▀^ī┘ąįųĄ╠Ē╝ė╠Ä└ĒŻ¼×ķ║¾└möĄō■═┌Š“╦ŃĘ©£╩éõę╗éĆŅÉś╦║×ī┘ąįĪŻ
2)╩╣ė├DMįOėŗŲ„╔·│╔öĄō■═┌Š“╠Ä└Ē┴„ĪŻįō┴„│╠░čĮø▀^ETLŅA╠Ä└ĒĄ─öĄō■Ęų×ķė¢ŠÜ╝»║═£yįć╝»ā╔ŅÉĪŻ╩ūŽ╚ė╔Š▀ėąŽ╚“×ų¬ūRĄ─ė¢ŠÜ╝»öĄō■ė¢ŠÜ╔·│╔øQ▓▀śõ─Żą═Ż¼╚╗║¾╩╣ė├įō─Żą═ī”£yįć╝»öĄō■▀MąąĘųŅÉŅA£yŻ¼ęį░l¼F┴„╩¦ąįÅŖĄ─┐═æ¶╚║¾wĪŻ
3)į┘└¹ė├ReportįOėŗŲ„Ż¼ęį═Žū¦Ą─ĘĮ╩Į╔·│╔ł¾▒ĒĖ±╩ĮŻ¼░čöĄō■═┌Š“Ą├ĄĮĄ─┐═æ¶ŅA£yĮY╣¹ęį║Ž▀mĄ─ĘĮ╩Į▀Mąąš╣¼FĪŻ
4)ūŅ║¾═©▀^╝»│╔Ų„Ż¼įOėŗBIæ¬ė├Ą─śIäš┴„│╠Ż¼īóŪ░├µ╦∙įOėŗĄ─ETL╚╬äšĪóDM╚╬äš║═ł¾▒Ē╚╬äš▀Mąą╝»│╔Ż¼╔·│╔BIæ¬ė├ĪŻ
3.2 īŹ“×┼õų├
īŹ“×öĄō■╩ŪÅ─ųąć°ęŲäėĄ─įÆå╬öĄō■ųą│ķśė½@Ą├Ż¼├┐Ślėøõøėą49éĆī┘ąįŻ¼ā╔Ę▌öĄō■┤¾ąĪ┤¾╝s×ķ10 GB║═100 GBĪŻīŹ“ףhŠ│ė╔60éĆPC╣سcĮM│╔Ż¼├┐éĆėŗ╦Ń╣سcĄ─ė▓╝■ŁhŠ│×ķ4║╦CPUŻ¼8 GBā╚┤µŻ¼1 TBė▓▒PŻ¼1 GBŠWĮj▀m┼õŲ„ĪŻŲõųą2éĆPC╣سcĖ„ū„×ķNameNode║═JobTrackerŻ¼Ųõ╦¹╣سcū„×ķDataNode║═TaskTrackerĪŻīŹ“×╩╣ė├Ą─Hadoop░µ▒Š╩Ūhadoop 0.20.1Ż¼blocksizeįO×ķ64 MBŪęĖ▒▒ŠöĄįO×ķ2ĪŻ
3.3 īŹ“×ĮY╣¹╝░Ęų╬÷
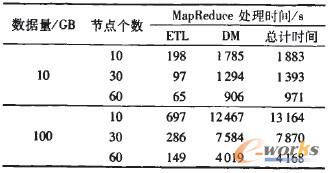
Ęųäe▓╔ė├öĄō■┴┐10 GB║═100 GBū„×ķīŹ“×öĄō■Ż¼ETL┴„│╠╬─╝■║═DM┴„│╠╬─╝■Įyę╗įOų├50éĆMap║═50éĆReduceŻ¼īŹ“×ÖCŲ„Ęųäe▓╔ė├10,30║═60éĆ╣سcŻ¼ė├ęį蹊┐▓╗═¼DataNode╣سcöĄŪķørŽ┬╝ė╦┘▒╚Ą─ąį─▄Ż¼īŹ“×ĮY╣¹╚ń▒Ē1╦∙╩ŠĪŻ
▒Ē1 ╗∙ė┌Map ReduceĄ─▓óąąETLĢrķgī”▒╚
1)ąį─▄ĪŻ
īŹ“×ĮY╣¹▒Ē├„▓╔ė├10Ī½60éĆ╣سcŠ═┐╔ęįęį▌^Ė▀ąį─▄ų¦│ų100 GBöĄō■Ą─ETL▓┘ū„║═öĄō■═┌Š“╦ŃĘ©ĪŻČ°į┌ĮøĄõ╔╠ė├öĄō■═┌Š“╣żŠ▀ųąŻ¼ė╔ė┌╚▒Ę”┐╔öUš╣ąįŻ¼ę╗░ŃāH─▄ų¦│ų300 MBöĄō■Ą─═┌Š“ĪŻ
2)öUš╣ąįĪŻ
▒ŠīŹ“×▓╔ė├10╣سcĪó30╣سcĪó60╣سcĪó32╣سc║═64╣سcęÄ─Żī”▓óąąöĄō■╠Ä└Ē║═▓óąąöĄō■═┌Š“╦ŃĘ©Ą─öUš╣ąį▀Mąą£yįćĪŻ
łD6(b)ųą├Ķ╩÷┴╦ļSų°╣سcöĄį÷╝ėĄ─╝ė╦┘▒╚ŪķørĪŻ’@╚╗Ż¼«ö╣سc▓╗ūāĢrŻ¼╠Ä└ĒĄ─öĄō■┴┐į÷╝ėŻ¼ät╝ė╦┘▒╚ĮėĮ³ŠĆąįŻ╗«ööĄō■┴┐▓╗ūāĢrŻ¼į÷╝ė╣سcŻ¼╝ė╦┘▒╚ĮėĮ³ŠĆąįĪŻĄ½╩ŪŻ¼«ö╣سcöĄ┴┐ŽÓī”ąĶę¬╠Ä└ĒĄ─öĄō■┴┐▀^ČÓĢrŻ¼╝ė╦┘▒╚Ę┤Č°ę“×ķĘŪėŗ╦Ńķ_õNČ°▀hļx└Ēšō╝ė╦┘▒╚ĪŻīŹ“×ĮY╣¹▒Ē├„Ż¼▓óąąöĄō■╠Ä└Ē║═▓óąąöĄō■═┌Š“╦ŃĘ©Š▀ėąā׹ѥ─öUš╣─▄┴”ĪŻ
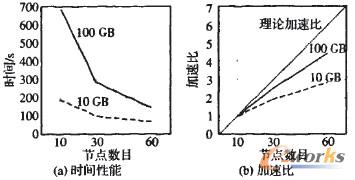
łD6 öĄō■▓óąą╠Ä└ĒĢrķgąį─▄║═╝ė╦┘▒╚
4 ĮYšZ
BI-PaaS┤ŅĮ©ė┌ųąć°ęŲäė┤¾įŲ╗∙ĄAįO╩®ų«╔ŽŻ¼ęįHadoopĄ─ÅŖ┤¾▓óąąėŗ╦Ń║═Ęų▓╝┤µā”─▄┴”×ķų¦ō╬Ż¼īóETLĪóDMĪóOLAPĪóReportĄ╚Ė„ŅÉBI─▄┴”▓óąą╗»ĪŻÅ─Č°ėąą¦Ąžų¦│ųļŖą┼▀\ĀIĄ─║Ż┴┐öĄō■Ęų╬÷Ż¼╠ßĖ▀ļŖą┼ŅIė“öĄō■Ęų╬÷ąį─▄Īó┐╔öUš╣ąįŻ¼ĮĄĄ═ŽĄĮyŲĮ┼_│╔▒ŠĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║╗∙ė┌▓óąąÖCųŲĄ─╔╠äšųŪ─▄ŽĄĮyBI-PaaS
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/solutions/1401937076.html






















