



1 Ū░čį
ļSų°¤oŠĆŠWĮjĪóęŲäėėŗ╦Ń║═é„ĖąŲ„ŠWĮj╝╝ągĄ─░lš╣Ż¼Ųš▀mėŗ╦ŃĄ─įOŽļš²ųØuūā│╔¼FīŹĪŻŲš▀mėŗ╦Ń┴”łD╩╣╚╦éā─▄ē“ęįę╗ĘNĘĮ▒ŃĄ─ĘĮ╩ĮīŹ¼Fį┌╚╬ęŌĄž³c┼c╚╬ęŌī”ĘĮĄ─┬ōŽĄŻ¼Å─Č°Įoé„ĮyĄ─æ¬ė├ĦüĒ┴╦ą┬Ą─╠¶æĪŻĪ░Ųš▀mėŗ╦ŃĪ▒īó╬ęéāÅ─Ī░ęįįOéõ×ķųąą─Ī▒Ą─ėŗ╦Ń─Ż╩ĮĦ╚ļĄĮĪ░ęį╚╦×ķųąą─Ī▒Ą─ėŗ╦Ń─Ż╩ĮŻ¼ęč│╔×ķ«öŪ░ėŗ╦Ń─Ż╩Į░lš╣Ą─│▒┴„ĪŻ│╔×ķīWągĮń║═╣żśIĮń蹊┐Ą─¤ß³c║═Į╣³cĪŻ
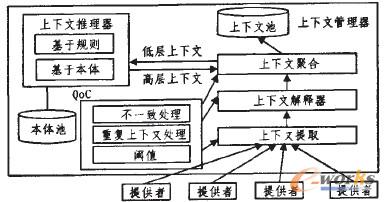
į┌Ųš▀mėŗ╦ŃŁhŠ│ųąŻ¼ė╔ė┌╦∙├µī”Ą─ęŲäėįOéõ═∙═∙ų╗Š▀ėąėąŽ▐Ą─┘Yį┤(╚ńā╚┤µĪóļŖ│ž║═CPU)Ż¼═¼Ģræ¬ė├Ą─ł╠ąą╔ŽŽ┬╬─(╚ńė├æ¶Ą─╬╗ų├Īó╩ų│ųįOéõĄ─┐╔ęĢ├µĘe)ę▓▓╗öÓ░l╔·ūā╗»Ż¼ę“┤╦ę¬Ū¾ī”æ¬Ą─æ¬ė├▒žĒÜ╩Ū╔ŽŽ┬╬─ŽÓĻPĄ─Ż¼Å─Č°╩╣æ¬ė├─▄ē“Ė∙ō■╔ŽŽ┬╬─ą┼Žó▀m┼õūį╔ĒĄ─ąą×ķĪŻę“┤╦╔ŽŽ┬╬─ŽÓĻP╝╝ąg│╔×ķŲš▀mėŗ╦ŃŁhŠ│ųąæ¬ė├Ę■äš▓╗┐╔╗“╚▒Ą─║╦ą─╝╝ągų«ę╗ĪŻ▓╗═¼Ą─╔ŽŽ┬╬─üĒį┤╦∙═Č▀fĄ─öĄō■═©│Ż╩Ū«ÉśŗĄ─Ż¼▓óŪęĖ³ą┬Ņl┬╩Įø│Ż░l╔·ūā╗»Ż¼═¼Ģrę¬┐╝æ]£╩┤_ąį║═«ÉśŗĄ─▒Ē▀_Ė±╩ĮĪŻ▀@ą®ĮyĘQ×ķ╔ŽŽ┬╬─Ą─┘|┴┐QoC(Quality of Context)Ż¼╦³╩ŪųĖė├ė┌├Ķ╩÷ą┼Žó┘|┴┐Ą─╚╬║╬ą┼ŽóŻ¼Č°▓╗╩Ū╠ß╣®ą┼ŽóĄ─▀^│╠║═ŽÓæ¬Ą─ė▓╝■įOéõĪŻ╚ń╣¹▓╗─▄Ę┤ė│╔ŽŽ┬╬─ą┼Žóę¬Į©─ŻĄ─╩└ĮńĄ─šµīŹĀŅæBŻ¼ą┼Žóīó▓╗š²┤_Ż╗╚ń╣¹░³└©├¼Č▄ą┼ŽóŻ¼ätīóī¦ų┬▓╗ę╗ų┬ąįĄ─░l╔·Ż╗╚ń╣¹╔ŽŽ┬╬─Ą──│ą®ĘĮ├µ▓╗┐╔ų¬Ż¼ätī¦ų┬ą┼ŽóĄ─▓╗═Ļš¹ĪŻīWągĮńęčš╣ķ_┤¾┴┐Ą─ĻPė┌╔ŽŽ┬╬─┘|┴┐Ą─蹊┐╣żū„Ż¼Ą½═∙═∙ĻPūóĄ─ų╗╩Ū╔ŽŽ┬╬─┘|┴┐Ą─▓┐ĘųĘĮ├µŻ¼ø]ėąÅ─Ė„éĆīė├µīŹ¼Fī”╔ŽŽ┬╬─┘|┴┐Ą─ŠC║Ž╣▄└ĒĪŻ
═¼ĢrŻ¼ųąķg╝■ęčĮø▒╗ÅVĘ║Ąžæ¬ė├ė┌Ęų▓╝╩Įėŗ╦ŃųąĪŻī”ė┌Ųš▀mæ¬ė├üĒšfŻ¼═©▀^ųąķg╝■ŲĮ┼_─▄ē“ūįäė▒O£yė├æ¶Īóæ¬ė├║══Ō▓┐ŁhŠ│ķg╦∙░l╔·Ą─Į╗╗źęį╝░▀@ą®Į╗╗ź╦∙ī¦ų┬Ą─╔ŽŽ┬╬─ūā╗»Ż¼▓óū÷│÷ŽÓæ¬Ą─Ę┤æ¬ĪŻČ°▓╗ąĶę¬ė├æ¶Ą─Ė╔╔µĪŻ×ķ┴╦╠ß╣®╔ŽŽ┬╬─ŽÓĻPĄ─Ę■䚯¼ų¦│ųŲš▀mėŗ╦ŃĄ─ųąķg╝■ŲĮ┼_▒žĒÜ─▄ē“ūRäe╔ŽŽ┬╬─Ą─ūā╗»Ż¼═¼Ģr═©▀^Š█║ŽüĒ╠ßĖ▀╔ŽŽ┬╬─Ą─┘|┴┐╗“═©▀^═Ų└Ēęį«a╔·Ė³Ė▀╝ēäeĄ─╔ŽŽ┬╬─Ż¼Å─Č°╩╣æ¬ė├─▄ē“▓╔ė├▀m«öĄ─äėū„üĒ▀m┼õ▀@ą®ūā╗»ĪŻį┌ęčėąĄ─蹊┐ųąŻ¼║▄ČÓ╔ŽŽ┬╬─Ėąų¬Ą─ŽĄĮyęčĮøŽ╚║¾▒╗Į©┴óŲüĒęįų¦│ųŲš▀mæ¬ė├Ż¼▓óķ_╩╝ĻPūó╔ŽŽ┬╬─Ą─┘|┴┐╣▄└Ēå¢Ņ}ĪŻĄ½▀@ą®ŽĄĮyų╗ĻPūó┴╦╔ŽŽ┬╬─┘|┴┐╣▄└ĒĄ─▓┐ĘųĘĮ├µĪŻę“┤╦Ż¼╬ęéā╗∙ė┌╔ŽŽ┬╬─Ėąų¬ųąķg╝■╠ß│÷┴╦ę╗ĘN╚½├µĄ─ßśī”╔ŽŽ┬╬─Ą─┘|┴┐╣▄└Ē┐“╝▄Ż¼═©▀^įō┐“╝▄─▄ē“ī”╔ŽŽ┬╬─Ą─┘|┴┐▀Mąąėąą¦Ą─╣▄└ĒŻ¼Å─Č°─▄ē“Ė³║├Ąžų¦│ųŲš▀mæ¬ė├Ą─ąĶŪ¾ĪŻ
2 ╗∙ė┌ųąķg╝■Ą─╔ŽŽ┬╬─┘|┴┐╣▄└Ē┐“╝▄
2.1 ╔ŽŽ┬╬─Ėąų¬ųąķg╝■¾wŽĄĮYśŗ
łD1╦∙╩Š×ķ╬ęéāŪ░Ų┌╣żū„ųąĮ©┴óĄ─╗∙ė┌╔ŽŽ┬╬─Ėąų¬Ą─ųąķg╝■Ą─¾wŽĄĮYśŗĪŻ║╦ą─śŗ╝■╣▄└Ē─ŻēK×ķ╬ęéāį┌Ū░└m╣żū„╦∙ķ_░lĄ─ū±čŁCORBAśŗ╝■─Żą═CCMĄ─śŗ╝■╗»ųąķg╝■Ż¼×ķ╗∙ė┌śŗ╝■Ą─æ¬ė├Īóśŗ╝■īŹ└²╠ß╣®ŲĮ┼_¤oĻPĄ─Ę■䚯¼×ķł╠ąąŲĮ┼_┘Yį┤╠ß╣®┴╦Įyę╗Ą─ŲĮ┼_¤oĻPįLå¢ĪŻśŗ╝■į┌╚▌Ų„ųął╠ąąŻ¼×ķĘų▓╝╩Įæ¬ė├Ą─╩┬äšĪó░▓╚½Īóę╗ų┬ąį║═┘Yį┤╣▄└Ē╠ß╣®ļ[╩ĮĄ─ų¦│ųŻ¼Å─Č°╩╣æ¬ė├ķ_░lš▀─▄ē“Ė³ų°ųžė┌æ¬ė├▒Š╔ĒĄ─ķ_░lĪŻ═¼Ģr┐╔ęį╠ß╣®ėąą¦Ą─╔╠śI▀ē▌ŗĄ─ųžė├Ż¼╚▌Ų„─▄ē“╠ß╣®░³└©╔·├³ų▄Ų┌╣▄└Ē║═śŗ╝■░l¼Fį┌ā╚Ą─ĘŪ╣”─▄ąį╠žąįĪŻ

łD1 ė├ė┌śŗ╝■╗»æ¬ė├Ą─╔ŽŽ┬╬─Ėąų¬ųąķg╝■ĮYśŗ
═¼ĢrŻ¼ųąķg╝■╠ß╣®Ž┬├µ3éĆ║╦ą─Ę■äš─ŻēKŻ║
Īż╔ŽŽ┬╬─╣▄└ĒŲ„─ŻēKŻ¼ī”╔ŽŽ┬╬─▀Mąą▒O£y║═╣▄└ĒŻ¼ęįæ¬ī”ŽÓĻPĄ─ūā╗»ĪŻ
Īż▀m┼õ╣▄└ĒŲ„─ŻēKŻ¼ī”╔ŽŽ┬╬─Ą─ūā╗»▀Mąą═Ų└ĒŻ¼▓ó╗∙ė┌śŗ╝■ī┘ąįĄ─¾wŽĄĮYśŗ├Ķ╩÷ęįøQČ©ŽÓæ¬Ą─śŗ╝■▀m┼õąą×ķĪŻ
Īż┼õų├Ų„─ŻēKŻ¼ī”æ¬ė├ūā┴┐▀Mąąųž┼õų├Ż¼ęįīŹ¼F╔ŽŽ┬╬─ŽÓĻPĄ─śŗ╝■▀m┼õĪŻ
Īżūįų„╣▄└ĒŲ„─ŻēKŻ¼═©▀^ę╗Č©Ą─ūįų„▓▀┬įŻ¼īŹ¼Fī”śŗ╝■║═Ę■䚥─äėæBĮēČ©┼c╠µōQĪŻ
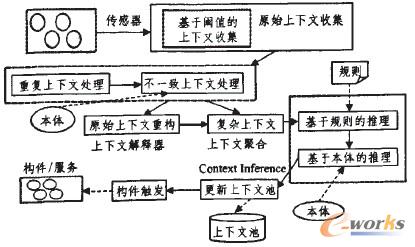
╔ŽŽ┬╬─╣▄└ĒŲ„žōž¤é„Ėą║═▓ČūĮ╔ŽŽ┬╬─ą┼Žóęį╝░╦³éāĄ─ūā╗»Ż¼╠ß╣®ī”╔ŽŽ┬╬─ą┼ŽóĄ─įLå¢Ż¼▓óīó╔ŽŽ┬╬─ą┼ŽóĄ─ūā╗»═©ų¬▀m┼õ╣▄└ĒŲ„─ŻēKĪŻ╔ŽŽ┬╬─╣▄└ĒŲ„─ŻēK═¼Ģržōž¤┤µā”ė├æ¶ī”æ¬ė├Ę■䚥─ąĶŪ¾║═Ų½║├Ż¼╦³▒žĒÜ╠ß╣®ņ`╗ŅĄ─╔ŽŽ┬╬─▒O£yĪŻ╬ęéāīó╔ŽŽ┬╬─╣▄└ĒŲ„ķ_░l×ķę╗éĆśŗ╝■╗»Ą─┐“╝▄Ż¼Å─Č°┐╔ęį▓Õ╚ļą┬Ą─╔ŽŽ┬╬─é„ĖąŲ„─ŻēKĪŻ╔ŽŽ┬╬─╣▄└ĒŲ„─ŻēK┐╔ęį×ķ╔ŽŽ┬╬─╠ß╣®Ė▀╝ēĄ─═Ų└Ē▓┘ū„ĪŻ└²╚ńŻ¼╦³┐╔ęįÅ─╗∙▒ŠĄ─╔ŽŽ┬╬─į¬╦žųąŠ█║Ž│÷Å═ļsĄ─╔ŽŽ┬╬─į¬╦ž╗“Å─╔ŽŽ┬╬─ųą┼╔╔·│÷ė├æ¶ąĶŪ¾ĪŻ╔ŽŽ┬╬─╣▄└ĒŲ„─ŻēK═¼Ģr▒Ż┤µ╔ŽŽ┬╬─ūā╗»Ą─Üv╩Ęą┼ŽóĪŻ
▀m┼õ╣▄└ĒŲ„─ŻēK═©▀^ę╗Č©Ą─▀m┼õęÄätžōž¤ī”╔ŽŽ┬╬─Ą─ūā╗»ī”æ¬ė├╦∙«a╔·Ą─ø_ō¶▀Mąą═Ų└ĒĪŻ▓ó×ķ«öŪ░Ą─╔ŽŽ┬╬─ėŗäØ║═▀xō±ūŅ▀m║ŽĄ─æ¬ė├ūā┴┐ĪŻū„×ķ═Ų└ĒĄ─ę╗▓┐ĘųŻ¼▀m┼õ╣▄└ĒŲ„─ŻēKąĶę¬į┌«öŪ░Ą─╔ŽŽ┬╬─ųąįLå¢▀@ą®ūā┴┐Ą─æ¬ė├ĪŻ▀m┼õ╣▄└ĒŲ„─ŻēKäėæB«a╔·ę╗éĆūŅ▀m║Ž╔ŽŽ┬╬─Ą─æ¬ė├ūāūŅĄ─┼õų├─Ż░ÕŻ¼═©▀^▀@śėĄ─┼õų├─Ż░ÕüĒ▒Ē╩Šę╗éĆ╦∙ėąæ¬ė├ūā┴┐Š∙▒╗ĮŌøQĄ──Żą═ĪŻ
┼õų├Ų„─ŻēKžōž¤ģfš{æ¬ė├Ą─│§╩╝īŹ└²Ż¼▓ó═Ļ│╔æ¬ė├╗“įOéõĄ─▒═┼õų├ĪŻ┼õų├Ų„─ŻēK═©▀^æ¬ė├┼õų├─Ż░Õł╠ąą▀m┼õ╣▄└ĒŲ„øQČ©Ą─▀m┼õĪŻ▀m┼õ╣▄└ĒŲ„║═┼õų├Ų„─ŻēK╗∙ė┌╣½╣▓Ą─ą┼Žóį¬╦žĪ¬Ī¬┼õų├─Ż░Õ▀Mąą▓┘ū„Ż¼ę“Č°╩ŪŠo±Ņ║ŽĄ─ĻPŽĄĪŻ
2.2 ╗∙ė┌▒Š¾wĄ─╔ŽŽ┬╬─┘|┴┐╣▄└Ē─Żą═
╗∙ė┌▒Š¾wĄ─Į©─ŻĘĮ╩Į═©▀^Č©┴xę╗éĆ╣½╣▓Ą─į~ģR▒Ēęįį┌ę╗éĆŠ▀¾wĄ─ŅIė“ųą▀Mąą╔ŽŽ┬╬─ą┼ŽóĄ─╣▓ŽĒŻ¼▓óŪę░³└©ī”ŅIė“ųą╗∙▒ŠĖ┼─ŅĄ─┐╔ĮŌßīĄ─Č©┴x║═▀@ą®Ė┼─Ņų«ķgĄ─ĻPŽĄĪŻę“┤╦Ż¼ĮĶų·ė┌▒Š¾wī”╔ŽŽ┬╬─ą┼Žó▀MąąĮ©─Ż─▄ē“═©▀^į┌ė├æ¶ĪóįOéõ║═Ę■äšų«ķg╣▓ŽĒ╔ŽŽ┬╬─ą┼ŽóĄ─ĮYśŗŻ¼ęįīŹ¼FšZ┴xĄ─╗ź▓┘ū„ąįĪŻ
╬ęéāīó╔ŽŽ┬╬─▒Š¾wäØĘų×ķ╔Žīė▒Š¾w║═ŅIė“ŽÓĻP▒Š¾wĪŻ╔Žīė▒Š¾w╩Ūę╗éĆĖ▀īė▒Š¾wŻ¼▓Č½@ę╗░ŃĄ─╔ŽŽ┬╬─ų¬ūRĪŻ├┐ę╗éĆŅIė“ųąĄ─╔ŽŽ┬╬─╣▓ŽĒ╩╣ė├ę╗ĘNę╗░Ń╗»Ą─╔ŽŽ┬╬──Żą═Į©─ŻĄ─╣½╣▓Ą─Ė┼─ŅŻ¼║═╝Ü╣Ø╠žąįėąŠ▐┤¾Ą─▓ŅäeĪŻę“┤╦Ż«æ¬ė├ŅIė“Ą─Ęųļx╣─äŅ┴╦ę╗░ŃĖ┼─ŅĄ─ųžė├Ż¼▓ó×ķČ©┴xæ¬ė├ŽÓĻPĄ─ų¬ūR╠ß╣®┴╦ę╗éĆņ`╗ŅĄ─Įė┐┌Ż¼─▄ē“£p╔┘╔ŽŽ┬╬─╠Ä└ĒĄ─žōō·Ż¼▓ó╩╣Ą├į┌ęŲäė┐═æ¶Č╦╔ŽĮŌßī╔ŽŽ┬╬─ą┼ŽóūāĄ├┐╔─▄ĪŻŅIė“ŽÓĻPĄ─▒Š¾w╩Ūę╗éĆČ©┴x┴╦ę╗░ŃĄ─Ė┼─Ņ╝Ü╣Ø║═├┐éĆūėŅIė“Ą─ī┘ąįĄ─Ą═īė▒Š¾wĄ─╝»║ŽĪŻ«öŁhŠ│░l╔·ūā╗»ĢrŻ¼├┐ę╗éĆūėŅIė“ųąĄ─Ą═īė▒Š¾w┐╔ęįÅ─Ė▀īė▒Š¾w▒╗äėæBĄž▓Õ╚ļ║═░╬│÷ĪŻ
į┌╬─½IųąŻ¼╬ęéāįö╝ÜĘų╬÷┴╦╔ŽŽ┬╬─╠Ä└ĒĄ─ę╗░Ń┴„│╠║═╔ŽŽ┬╬─╣▄└ĒŲ„Ą─ĮM│╔─ŻēKĪŻę¬▀Mąą╔ŽŽ┬╬─┘|┴┐╣▄└ĒŻ¼╩ūŽ╚ę¬Å─╔ŽŽ┬╬─Į©─ŻĄ─ĘĮ╩Į╔Ž▀Mąąį÷ÅŖĪŻ
╚ńłD2╦∙╩ŠŻ¼į┌ęčėąĄ─╗∙ė┌▒Š¾wĄ─╔ŽŽ┬╬─Ą──Żą═╗∙ĄA╔ŽŻ¼╬ęéā×ķ├┐éĆ╔ŽŽ┬╬─ī”Ž¾╠Ē╝ė┴╦6éĆģóöĄŻ¼═©▀^▀@ą®ģóöĄųąĄ─ę╗éĆ╗“ČÓéĆśŗ│╔╔ŽŽ┬╬─┘|┴┐╣▄└Ēį¬ĮMĪŻ
łD2 ╗∙ė┌▒Š¾wĄ─╔ŽŽ┬╬─┘|┴┐╣▄└Ē─Żą═
╔ŽŽ┬╬─Ą─░▓╚½Č╚(Security)Ż║╔ŽŽ┬╬─Ą─░▓╚½ąįė├üĒ▒Ē╩Š╔ŽŽ┬╬─░▓╚½Ąž═Č▀fĮoŽ¹┘Mš▀Ą─Ė┼┬╩ĪŻ▀@éĆģóöĄ─▄ē“║▄║├Ąžė├üĒĘ┤ė│╔ŽŽ┬╬─į┌é„▀f▀^│╠ųą░▓╚½ąį▒Ż│ųĄ─│╠Č╚ĪŻ
╔ŽŽ┬╬─Ą─Š½Č╚(Precision)Ż║Č©┴x×ķ╔ŽŽ┬╬─ą┼Žó├Ķ╩÷ę╗éĆ¼FīŹ╩└Įńą╬æBĄ─┴ŻČ╚ĪŻ│÷ė┌Š½Č╚┴┐╗»Ą──┐Ą─Ż¼╔ŽŽ┬╬─ą┼ŽóųĄ┐╔ęįĘų×ķ4ĘNŅÉą═Ż║▓╝Ā¢ą═ĪóöĄųĄą═Īó▀fį÷╝»Īó╝ėÖÓ╝»ĪŻ
╔ŽŽ┬╬─Ą─═Ļš¹ąį(Completeness)Ż║Č©┴x×ķŽÓī”╩š╝»ĄĮĄ─╦∙ėą╔ŽŽ┬╬─Ą─┐╔ė├╔ŽŽ┬╬─Ą─▒╚┬╩ĪŻ▀@éĆģóöĄė├üĒ║Ō┴┐ė├æ¶Č©┴xĄ─▓╗═¼╔ŽŽ┬╬─ų«ķgĄ─ĻPŽĄĪŻ
╔ŽŽ┬╬─Ą─ą┬§rČ╚(Freshness)Ż║╩ŪųĖ╔ŽŽ┬╬─ą┼Žó┤_Č©ĄĮ▒╗═Č▀fĮošłŪ¾š▀Ų┌å¢╦∙Ž¹║─Ą─Ģrå¢ĪŻę“×ķ▀^ĢrĄ─╔ŽŽ┬╬─ī”šłŪ¾š▀üĒšf╩Ūø]ėąė├Ą─Ż¼═¼śė╔ŽŽ┬╬─Ą─ą┬§rČ╚║═ą┼ŽóĄ─╦Įėą├¶ĖąČ╚ŽóŽóŽÓĻPĪŻ╔ŽŽ┬╬─Ėąų¬Ę■äšīóįu╣└æ¬ė├Ą─ąĶŪ¾ęį╝░ė├æ¶Ą─éĆ╚╦É█║├Ż¼ęįøQČ©╦∙▓╔╚ĪĄ─ŠÅ┤µ▓▀┬įĪŻ
╔ŽŽ┬╬─Ą─┐šķgĘų▒µČ╚(Resolution)Ż║Č©┴x×ķ╔ŽŽ┬╬─ą┼ŽóĄ─īŹ└²┐╔ė├Ą─╬’└Ēģ^ė“Ą─Š½Č╚ĪŻ┐šķgĘų▒µČ╚╩Ūę╗éĆė├ė┌▒Żūoė├æ¶╦Į╚╦ąįĄ─Ž╝ę¬ųĖś╦Ż¼ę“×ķĖ³▒ŠĄž╗»Ą─ą┼Žó┤·▒Ē┴╦Ė³Ė▀Ą─╦Į╚╦├¶ĖąČ╚ĪŻ└²╚ńŻ¼ė├æ¶┐╔─▄į╩įSę╗éĆ┤¾śŪ░▓╚½ŽĄĮyįLå¢┤¾śŪųąĄ─╚╦öĄĪŻĄ½▓╗į╩įSįLå¢▀@ą®╚╦Ęųäeį┌╩▓├┤Ę┐ķgųąŻ¼Å─Č°▒▄├ŌŽĄĮy═ŲöÓė├æ¶╩Ūʱį┌ķ_Ģ■ĪŻ
╔ŽŽ┬╬─Ą─┤_Č©ąį(Certainty)Ż║Č©┴x×ķ╔ŽŽ┬╬─ą┼ŽóĄ─┤_Č©ąįĪŻ
2.3 ╗∙ė┌┘|┴┐╣▄└ĒĄ─╔ŽŽ┬╬─╠Ä└Ē┴„│╠
łD3╦∙╩Š×ķ┐╝æ]┘|┴┐╣▄└ĒĄ─╔ŽŽ┬╬─╣▄└ĒŲ„Ą─ĮYśŗĪŻ═©▀^ķōųĄĪóųžÅ═╔ŽŽ┬╬─Öz£y┼cŽ¹│²Īó▓╗ę╗ų┬╔ŽŽ┬╬─Öz£y┼cŽ¹│²3éĆīė┤╬üĒ═Ļ│╔ī”╔ŽŽ┬╬─Ą─┘|┴┐╣▄└ĒĪŻŲõųąķōųĄ╣▄└Ē═©▀^ī”╔ŽŽ┬╬─┘|┴┐╣▄└ĒģóöĄįOČ©ę╗Č©Ą─ķōųĄüĒī”½@╚ĪĄ─įŁ╩╝╔ŽŽ┬╬─▀Mąą│§▓ĮĄ─║Y▀xŻ¼ĮėŽ┬üĒį┌╔ŽŽ┬╬─Ą─ĮŌßī║═Š█║Ž▀^│╠ī”ųžÅ═╔ŽŽ┬╬─║═▓╗ę╗ų┬╔ŽŽ┬╬─▀Mąą▀Bž×Ą─╠Ä└ĒĪŻ
łD3 ė├ė┌┘|┴┐╣▄└ĒĄ─╔ŽŽ┬╬─╣▄└ĒŲ„ĮYśŗ
łD4Įo│÷┴╦┐╝æ]┘|┴┐╣▄└ĒĄ─╔ŽŽ┬╬─╠Ä└Ē▀^│╠ĪŻĄ┌ę╗▓Į×ķ╩š╝»įŁ╩╝╔ŽŽ┬╬─Ż¼╝┤į┌▌^Č╠Ą─ų▄Č©Ģrķgā╚Å─▓╗═¼Ą─é„ĖąŲ„üĒį┤ųą╩š╝»įŁ╩╝Ą─╔ŽŽ┬╬─ą┼ŽóĪŻĄ┌Č■▓Į╩ŪĮŌ╬÷▓╗ę╗ų┬ąįŻ¼╬ęéāų«╦∙ęį▀xō±į┌▒Š▓ĮųąĮŌ╬÷▓╗═¼įŁ╩╝╔ŽŽ┬╬─ųą┤µį┌Ą─▓╗ę╗ų┬ąįŻ¼╩Ūę“×ķįŁ╩╝╔ŽŽ┬╬─ųą┤µį┌Ą─▓╗ę╗ų┬ąįīóūŅĮKī¦ų┬Ė▀īė╔ŽŽ┬╬─ųąĄ─▓╗ę╗ų┬ąįŻ¼Č°▀@ĘNĖ▀īėĄ─▓╗ę╗ų┬ąįīó╩ŪĘŪ│ŻļyęįĮŌøQĄ─ĪŻ▓╔ė├┼·╠Ä└ĒĄ─ĘĮ╩ĮüĒ╠Ä└ĒįŁ╩╝Ą─╔ŽŽ┬╬─Ż¼├┐ę╗┼·įŁ╩╝╔ŽŽ┬╬─ųąĄ─▓╗ę╗ų┬ąįŠ∙į┌╔ŽŽ┬╬─═Ų└Ēų«Ū░ŪÕ│²═ĻŻ¼Å─Č°╩╣Ė▀īė╔ŽŽ┬╬─Ą─▓╗ę╗ų┬ąį─▄ē“▒╗Ž▐ųŲį┌ę╗éĆ╠žČ©Ą─│╠Č╚ĪŻĄ┌╚²▓Į╩ŪųžśŗįŁ╩╝╔ŽŽ┬╬─Ż¼īó╩╣ė├įŁ╩╝╔ŽŽ┬╬─Ė³ą┬╔ŽŽ┬╬─│ž▓óī”ŽÓĻPąį▀MąąÖz▓ķĪŻ▀^Ģr╗“▓╗š²┤_Ą─Ė▀īė╔ŽŽ┬╬─īóį┌▒Š▓Įųą▒╗äh│²ĪŻ╚ń╣¹╦³éāø]▒╗äh│²Ż¼īóį┌═Ų└Ē║¾ī¦ų┬ć└ųžĄ─╔ŽŽ┬╬─▓╗ę╗ų┬ąįĪŻ╚╗║¾Ż¼╬ęéā▀\ė├╗∙ė┌ęÄätĄ─═Ų└Ēęį«a╔·Ė▀īėĄ─╔ŽŽ┬╬─Ż¼▀@ą®═Ų└ĒŲ„Š∙┼õų├×ķ┐╔ūĘ█ÖŻ¼Å─Č°─▄ē“į┌╔ŽŽ┬╬─│žųąī”ŽÓĻPĄ─łD▀MąąĖ³ą┬ĪŻ
2.4 ųžÅ═╔ŽŽ┬╬─Ą─Öz£y┼cüGŚē
«öŽĄĮy═Ļ│╔╗∙ė┌ķōųĄĄ─įŁ╩╝╔ŽŽ┬╬─║Y▀x║¾Ż¼ĮėŽ┬üĒąĶę¬┐╝æ]Ą─Š═╩ŪųžÅ═╔ŽŽ┬╬─Ą─ŪÕ│²ĪŻį┌╔ŽŽ┬╬──Żą═ųąŻ¼×ķ├┐éĆ╔ŽŽ┬╬─įOų├┴╦╔ŽŽ┬╬─IDĪŻę“┤╦╦∙ų^─óÅ═╔ŽŽ┬╬─Ż¼Š═╩ŪŠ▀ėąŽÓ═¼Ą─╔ŽŽ┬╬─IDŻ¼╗“š▀Š▀ėąŽÓ═¼Ą─╔ŽŽ┬╬─├¹/ųĄī”ĪŻ
╦ŃĘ©1Įo│÷┴╦ųžÅ═╔ŽŽ┬╬─Ą─Öz£yĘĮĘ©ĪŻ╩ūŽ╚┼ąöÓą┬ĄĮ▀_Ą─╔ŽŽ┬╬─Ą─ID╠¢║═├¹/ųĄī”ĪŻ╩Ūʱ┼c¼FėąĄ─╔ŽŽ┬╬─ųžÅ═ĪŻ╚ń╣¹ėą╔ŽŽ┬╬─Š▀ėąŽÓ═¼Ą─ID╠¢║═├¹ųĄī”ĪŻätÖz▓ķ▀@ą®╔ŽŽ┬╬─Ą─üĒį┤ĪŻ╚ń╣¹╦³éāŠ▀ėąŽÓ═¼Ą─üĒį┤Ż¼ät╦³éāĘųäeüĒūį▓╗═¼Ą─ĢrČ╬Ż¼Ė∙ō■ŽÓæ¬Ą─┘|┴┐ģóöĄ▀MąąüGŚē╝┤┐╔ĪŻ╚ń╣¹╦³éāüĒį┤▓╗═¼Ż¼ät╔ŽŽ┬╬─Ą─╩š╝»▀^│╠┤µį┌Õeš`Ż¼ąĶę¬▓╔╚Īę╗Č©Ą─Öz▓ķ┤ļ╩®ĪŻ
╦ŃĘ©1 ųžÅ═╔ŽŽ┬╬─Öz£y╦ŃĘ©
INPUTŻ║ą┬ĄĮ▀_Ą─╔ŽŽ┬╬─
1Ż«½@Ą├╔ŽŽ┬╬─ID
2Ż«╚ń╣¹┤µį┌Š▀ėąŽÓ═¼IDĄ─╔ŽŽ┬╬─
3Ż«╚ń╣¹ŽÓæ¬Ą─╔ŽŽ┬╬─üĒį┤ŽÓ═¼
4Ż«╚ń╣¹Š▀ėąŽÓ═¼Ą─Ģrķg┤┴
5Ż«šęĄĮųžÅ═Ą─╔ŽŽ┬╬─Ż¼ł╠ąąüGŚē
6Ż«Ę±ätÖz▓ķ╔ŽŽ┬╬─Ą─╩š╝»
7Ż«╚ń╣¹šęĄĮŠ▀ėąŽÓ═¼├¹ųĄī”Ą─╔ŽŽ┬╬─
8Ż«░┤┘|┴┐į¬ĮM▀MąąüGŚē
2.5 ▓╗ę╗ų┬╔ŽŽ┬╬─Öz£y┼cüGŚē
ī”ė┌╦∙Öz£yĄĮĄ─ųžÅ═╔ŽŽ┬╬─Ż¼╬ęéā▓╔╚Ī┴╦Ū░Ų┌╣żū„ųą╠ß│÷Ą─╚ńŽ┬Ą─ÄūĘN▓╗ę╗ų┬üGŚē╦ŃĘ©Ż║
(1)╚½üGŚē▓╗ę╗ų┬ąįŽ¹│²Ż║ī”ė┌Öz£y│÷Ą─ø_═╗╔ŽŽ┬╬─Ż¼ę¬═©▀^äh│²ŽÓæ¬Ą─╔ŽŽ┬╬─üĒŽ¹│²▓╗ę╗ų┬ąįĪŻ╦∙ų^╚½üGŚē▓╗ę╗ų┬ąįŽ¹│²╩ŪūŅ×ķų▒ė^Ą─▓╗ę╗ų┬ąįŽ¹│²ĘĮĘ©Ż¼╝┤īó«a╔·ø_═╗Ą─╔ŽŽ┬╬─īŹ└²▓╗╝ėģ^ĘųĄž═Ļ╚½äh│²ĪŻ
(2)ūŅą┬╔ŽŽ┬╬─üGŚē▓╗ę╗ų┬ąįŽ¹│²Ż║ŽÓī”ė┌ūŅą┬╔ŽŽ┬╬─üGŚē▓╗ę╗ų┬ąįŽ¹│²╦ŃĘ©üĒšfŻ¼ūŅą┬╔ŽŽ┬╬─üGŚē▓╗ę╗ų┬ąįŽ¹│²▓ó▓╗üGŚē╦∙ėą░l╔·ø_═╗Ą─╔ŽŽ┬╬─Ż¼ę“×ķ║▄ČÓø_═╗Ą─░l╔·╩Ūė╔ė┌ą┬▀M╚ļĄ─╔ŽŽ┬╬─īŹ└²║═ęčėąĄ─╔ŽŽ┬╬─īŹ└²ų«ķgĄ─ø_═╗Ż¼╔§ų┴▀@▓┐ĘųęčėąĄ─╔ŽŽ┬╬─īŹ└²┐╔─▄╝┤īó╝ė╚ļ╔ŽŽ┬╬─│ž▀Mąą┤µā”ĪŻę“┤╦═©▀^▒╚▌^╔ŽŽ┬╬─īŹ└²Ą─starttimeė“║═updatetimeė“Ż¼─▄ē“┼ąČ©╔ŽŽ┬╬─īŹ└²Ą─ą┬┼f│╠Č╚ĪŻ
(3)╗∙ė┌┤_Č©ąį╔ŽŽ┬╬─üGŚēŻ║╗∙ė┌┤_Č©ąį╔ŽŽ┬╬─üGŚē▓╗ę╗ų┬ąįŽ¹│²╦ŃĘ©ŽÓī”ūŅą┬╔ŽŽ┬╬─üGŚē╦ŃĘ©Š▀ėąĖ³Ė▀Ą─£╩┤_ąįŻ¼═¼ĢrŽÓī”╚½üGŚē▓╗ę╗ų┬ąįŽ¹│²╦ŃĘ©─▄ē“×ķæ¬ė├▒Ż┴¶Ė³ČÓĄ─╔ŽŽ┬╬─ą┼ŽóĪŻĄ½╗∙ė┌┤_Č©ąįĄ─╔ŽŽ┬╬─üGŚē╦ŃĘ©ąĶę¬ī”├┐éĆ╔ŽŽ┬╬─īŹ└²▀Mąą┤_Č©ąįĄ─┼ąČ©║═▒╚▌^Ż¼Å─Č°Ģ■╝ė┤¾╦ŃĘ©Ą─Ņ~═Ōķ_õNŻ¼ĮĄĄ═╦ŃĘ©Ą─ą¦┬╩ĪŻ
(4)╗∙ė┌ŽÓĻPąį╔ŽŽ┬╬─üGŚēŻ║ī”ė┌▓╗═¼Ą─╔ŽŽ┬╬─üĒšfŻ¼Ė³ŅlĘ▒Ą─įŁ╩╝╔ŽŽ┬╬─▒╚▓╗ŅlĘ▒Ą──Ūą®╔ŽŽ┬╬─Š▀ėąĖ³Ė▀Ą─ā׎╚╝ēŻ¼ę▓┐╔─▄╩Ūš²┤_Ą─╔ŽŽ┬╬─ĪŻ╚╗Č°ĪŻę¬×ķ▓╗═¼ĘNŅÉĄ─╔ŽŽ┬╬─▒╚▌^Ņl┬╩╩ŪĘŪ│Ż└¦ļyĄ─ĪŻ╗∙ė┌▀@éĆįŁę“ĪŻ┐╝æ]▀@ą®╔ŽŽ┬╬─▒╦┤╦ų«ķgĄ─ŽÓĻPąįŻ¼ę▓Š═╩Ū╦³éā▒╗╩╣ė├Ą─ŅlĘ▒│╠Č╚×ķ├┐ę╗éĆįŁ╩╝╔ŽŽ┬╬─▀MąąČ╚┴┐Ż¼Š▀ėąĖ³┤¾Ą─ŽÓī”Ņl┬╩ųĄĄ─╔ŽŽ┬╬─Į³üĒĖ³×ķŅlĘ▒Ż¼ę“┤╦╦³éāĖ³┐╔─▄╩Ūš²┤_Ą─╔ŽŽ┬╬─ĪŻ«öø_═╗░l╔·ĢrŻ¼üGŚēŠ▀ėą▌^ąĪĄ─ŽÓī”Ņl┬╩ųĄĄ─╔ŽŽ┬╬─ĪŻŽ┬╩Į×ķėŗ╦ŃįŁ╩╝╔ŽŽ┬╬─Ą─ŽÓī”Ņl┬╩Ą─ĘĮĘ©ĪŻ

3 ąį─▄£yįć
╚ńłD5╦∙╩ŠŻ¼╬ęéā▒╚▌^║═Ęų╬÷┴╦╚½üGŚēĪóūŅą┬╔ŽŽ┬╬─üGŚēĪó╗∙ė┌┤_Č©ąį╔ŽŽ┬╬─üGŚē║═╗∙ė┌ŽÓĻPąį╔ŽŽ┬╬─üGŚēÄūĘN▓╗ę╗ų┬ąįŽ¹│²╦ŃĘ©Ą─ū„ė├ĪŻ
łD5 ĘŪę╗ų┬ąįĮŌ╬÷Ą─š²┤_ąįĖ┼┬╩Ęų╬÷
īŹ“×ųą╣▓╩╣ė├3┼_ėŗ╦ŃÖCŻ¼ę╗éĆ4G RAMĪó2 Xeon CPUsĄ─╣żū„šŠ║═ā╔éĆ═©▀^Šųė“ŠW╗ź┬ōĄ─PC┐═æ¶Č╦ĪŻę╗éĆ┐═æ¶Č╦žōž¤│õ«öįŁ╩╝╔ŽŽ┬╬─Ą─╠ß╣®š▀Ż¼Č°┴Ēę╗éĆät│õ«ö╔ŽŽ┬╬─Ą─Ž¹┘Mš▀ĪŻį┌īŹ“×ųąŻ¼×ķ┴╦║å╗»ī”╔ŽŽ┬╬─ą┼Žóš²┤_ąįĄ─Ęų╬÷Ż¼ų╗╩╣ė├┴╦ā╔ĘNŅÉą═Ą─é„ĖąŲ„ĪŻę¬ųĖ│÷Ą─╩ŪŻ¼į┌▀@éĆįć“×ųą▒M╣▄ų╗╩╣ė├┴╦ā╔ĘNŅÉą═Ą─é„ĖąŲ„ĪŻ╬ęéāĄ─¾wŽĄĮYśŗ║═╦ŃĘ©ę▓─▄ē“▓╗ū÷╚╬║╬ą▐Ė─Ąž▀mė├ė┌Ė³ČÓĄ─é„ĖąŲ„ŅÉą═Ż¼ę“×ķ╦³éāßśī”šZ┴x╔ŽŽ┬╬─įOėŗŻ¼Č°ĘŪ╬’└Ēé„ĖąŲ„ĪŻ«öę²╚ļą┬Ą─é„ĖąŲ„ŅÉą═ĢrŻ¼╬©ę╗ąĶę¬ū÷Ą─Š═╩Ūį÷╝ė╠žČ©Ą─įŁ╩╝╔ŽŽ┬╬─╠ß╣®š▀ĪŻ
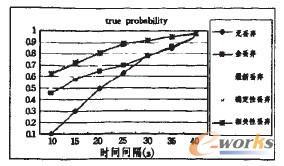
Å─łD5ųą┐╔ęį┐┤│÷Ż¼╗∙ė┌┤_Č©ąį║═╗∙ė┌ŽÓĻPąįĄ─▓╗ę╗ų┬ąįŽ¹│²╦ŃĘ©Š▀ėąĖ³║├Ą─ąį─▄ĪŻ═¼Ģrį┌╣żū„šŠ╔Žī”╔Ž╩÷╦ŃĘ©Ą─ąį─▄▀Mąą┴╦▒╚▌^║═Ęų╬÷Ż¼░l¼FļSų°ā╚┤µųą┐éĄ─╔ŽŽ┬╬─Ą─į÷╝ėŻ¼╦ŃĘ©Ą─ą¦┬╩īóĢ■ŽÓæ¬ĄžŽ┬ĮĄĪŻ
łD6ęį╗∙ė┌ŽÓĻPąįĄ─üGŚē╦ŃĘ©×ķ└²Ż¼«öŠÅø_ģ^╔ŽŽ┬╬─īŹ└²×ķ1000Ī½2000ĢrŻ¼╩╣ė├Ą─Ģrķg×ķ1.5sĪ½2.0sĪŻČ°į┌╔ŽŽ┬╬─īŹ└²×ķ3000Ī½4000ĢrŻ¼ąĶę¬6sĪŻ═¼ĢrŻ¼╚½üGŚē╦ŃĘ©║═ūŅą┬üGŚē╦ŃĘ©ŽÓī”üĒšfŠ▀ėą▌^Ą═Ą─▓╗ę╗ų┬ąį╠Ä└ĒĢrķgŻ¼Č°╗∙ė┌┤_Č©ąįĄ─üGŚē╦ŃĘ©ė╔ė┌ąĶę¬ī”╔ŽŽ┬╬─īŹ└²Ą─┤_Č©ąį▀Mąą┼ąČ©Ż¼ę“┤╦Š▀ėąŽÓī”ūŅĖ▀Ą─╠Ä└ĒĢrķgĪŻ
łD6 ĘŪę╗ų┬ąįĮŌ╬÷Ą─ąį─▄Ęų╬÷
═¼Ģr╬ęéāī”ÄūĘN▓╗═¼╦ŃĘ©Ą─Õeš`┬╩▀Mąą┴╦▒╚▌^ĪŻ×ķ┴╦▀Mąą▒╚▌^Ż¼╬ęéāīó3éĆæ¬ė├Ęųäe▀\ąą┴╦600┤╬(┐é╣▓30éĆ┤¾čŁŁhŻ¼├┐éĆ裣h20┤╬)Ż¼▓óėøõø┴╦├┐ę╗Ė±čŁŁhĄ─Õeš`┬╩ĪŻį┌įć“×ųąŻ¼╦∙ėą▒╗ėøõøŽ┬üĒĄ─Õeš`╩Ūæ¬ė├Ą─▓╗ģfš{Ą─ąą×ķŻ¼Č°ŽĄĮyĄ─Õeš`Ż¼╚ńā╚┤µęń│÷Ą╚ät▓╗╝ėęį┐╝æ]ĪŻÅ─įć“×ĮY╣¹ųą═¼śė┐╔ęį┐┤│÷Ż¼ļSų°š²┤_ąįĖ┼┬╩Ą─╠ßĖ▀Ż¼Ė„╔ŽŽ┬╬─▓╗ę╗ų┬ąį╣▄└ĒÖCųŲ─▄ē“į┌▓╗═¼│╠Č╚╔Ž╠ßĖ▀╔ŽŽ┬╬─Ėąų¬æ¬ė├Ą─ĮĪēčąįŻ¼┤¾┴┐ė╔ė┌╔ŽŽ┬╬─ø_═╗╦∙«a╔·Ą─▓╗ģfš{Ą─ąą×ķ▒╗£p╔┘Ż¼Å─Č°╠ßĖ▀┴╦╔ŽŽ┬╬─Ėąų¬æ¬ė├Ą─ąį─▄ĪŻ
ĮY╩°šZ╔ŽŽ┬╬─Ėąų¬ŽĄĮy═©│Ż└¹ė├üĒūįė┌▓╗═¼Ą─╬’└Ēé„ĖąŲ„Ą─Ėąų¬╔ŽŽ┬╬─ą┼ŽóĪŻČ°ė╔ė┌é„ĖąŲ„Ą─ęūÕeąįŻ¼╦∙«a╔·Ą─╔ŽŽ┬╬─ą┼ŽóĄ─┘|┴┐¤oĘ©Ą├ĄĮėąą¦Ą─▒ŻūCĪŻ¼FėąĄ─╔ŽŽ┬╬─┘|┴┐ĘĮ├µĄ─蹊┐═∙═∙ų╗ĻPūó╔ŽŽ┬╬─┘|┴┐Ą──│ę╗ĘĮ├µĪŻę“┤╦Ż¼į┌Ū░Ų┌╣żū„Ą─╗∙ĄA╔ŽŻ¼▒Š╬─╠ß│÷┴╦╗∙ė┌ųąķg╝■Ą─╔ŽŽ┬╬─┘|┴┐╣▄└Ē┐“╝▄Ż¼īŹ¼F┴╦ī”╔ŽŽ┬╬─┘|┴┐Ą─ČÓīė┤╬Ą─╣▄└ĒĪŻīŹ“×ūC├„Ż¼įōĘĮĘ©─▄ē“ėąą¦╠ßĖ▀╔ŽŽ┬╬─┘|┴┐Ą─╣▄└Ēą¦╣¹ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║Ųš▀mėŗ╦ŃŁhŠ│Ž┬╗∙ė┌ųąķg╝■Ą─╔ŽŽ┬╬─┘|┴┐╣▄└Ē┐“╝▄蹊┐
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/1112153136.html






















