



ę²čį
ūŅų¬├¹Ą─įŲėŗ╦Ńķ_į┤ŽĄĮyHadoop─ŻĘ┬║═īŹ¼F┴╦GoogleįŲėŗ╦ŃĄ─ų„ę¬╣”─▄ĪŻļSų°įŲėŗ╦ŃĄ─ųØu┴„ąąŻ¼▀@ę╗ĒŚ─┐▒╗įĮüĒįĮČÓĄ─éĆ╚╦║═Ų¾śI╦∙▀\ė├ĪŻHDFSĪóMapReduce║═HBase×ķHadoopĄ─║╦ą─Ż¼╦³éāī”æ¬┴╦GoogleįŲėŗ╦ŃūŅ║╦ą─╝╝ągGFSĪóMapRe-duce║═BigtableĄ─ķ_į┤īŹ¼FĪŻ
ų„╣سc░³└©NameNodeĪóSecondaryNameNode║═Jobtracker╩žūo▀M│╠Ż©╝┤╦∙ų^Ą─ų„╩žūo▀M│╠Ż®Ż¼ŲõėÓ╩Ū×ķč▌╩Š╣▄└Ē╝»╚║╦∙ė├Ą─╣سcŻ©╩╣ė├HadoopīŹė├│╠ą“║═×gė[Ų„Ż®ĪŻÅ─╣سc░³└©DataNode║═Tasktracker(Å─ī┘╩žūo▀M│╠)ĪŻā╔ĘNįOų├Ą─▓╗═¼ų«╠Äį┌ė┌Ż║ų„╣سc░³└©╠ß╣®Hadoop╝»╚║╣▄└Ē║═ģfš{Ą─╩žūo▀M│╠Ż¼Č°Å─╣سc░³└©īŹ¼FHadoop╬─╝■ŽĄĮyĪŻ
─┐Ū░┤╦ĒŚ─┐š²į┌▀MąąųąŻ¼ļm╚╗¼Fį┌▀Ćø]ėąĄĮ▀_1.0░µ▒ŠŻ¼║═GoogleŽĄĮy▀Ćėą║▄┤¾▓ŅŠÓŻ¼Ą½╩ŪŪ░Š░ĘŪ│Ż║├Ż¼ųĄĄ├ĻPūóĪŻ
1 HDFS
«öę╗éĆöĄō■╝»╚▌┴┐│¼▀^ę╗éƬÜ┴ó╬’└ĒÖCĄ─┤µā”─▄┴”ĢrŻ¼░čöĄō■╝»═©▀^┤¾┴┐Ą─ÖCŲ„▀MąąĘų▓╝╩Ū╩«Ęų▒žę¬Ą─ĪŻ╬─╝■ŽĄĮyĘQū÷Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼╦³┐ńŠWĮj▀Mąą┤µā”╣▄└ĒĪŻę“×ķ╩Ū╗∙ė┌ŠWĮjĄ─Ż¼╦∙ęįĢ■ĦüĒ║▄ČÓÅ═ļsĄ─ŠWĮjŠÄ│╠å¢Ņ}ĪŻ▀@╩╣Ą├Ęų▓╝╩Į╬─╝■ŽĄĮy▒╚Ų│ŻęÄĄ─╬─╝■ŽĄĮyę¬Å═ļsĄ├ČÓĪŻ└²╚ńŻ¼Ųõųąę╗éĆųžę¬Ą─╠¶æŠ═╩Ū╬─╝■ŽĄĮy╚▌╚╠╣سcÕeš`Ą─═¼Ģr▓╗üG╩¦öĄō■ĪŻ
Hadoopėąę╗éĆĘQ×ķHDFS (hadoop distributedfilesystem)Ą─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼╦³╩ŪHadoopĄ─Ų┌ķg╬─╝■ŽĄĮyĪŻ
1.1įOėŗŪ░╠ß┼c─┐ś╦
HDFSĄ─įOėŗŪ░╠ß┼c─┐ś╦╚ńŽ┬Ż║
(1)ė▓╝■Õeš`┐╔─▄Įø│Ż│÷¼FŻ¼Ųõī┘ė┌│ŻæB▓óĘŪ«É│ŻĪŻHDFSį╩įSė▓╝■│÷╣╩šŽŻ¼HDFSĄ─ūŅ║╦ą─įOėŗ─┐ś╦Š═╩ŪÕeš`Öz£y▓ó┐ņ╦┘ūįäė╗ųÅ═ĪŻ
(2)┴„╩ĮöĄō■įLå¢ĪŻ┴„╩Įūx×ķų„HDFS╔ŽĄ─æ¬ė├Ą─ų„ę¬╠Ä└ĒĘĮ╩ĮĪŻų¦│ų┼·┴┐╠Ä└ĒŻ¼Ė▀═╠═┬┴┐╩ŪöĄō■įLå¢Ą─ĻPūóųž³cĪŻ
(3)│¼┤¾ęÄ─ŻöĄō■╝»ĪŻTB╝ē╗“š▀PB╝ē╩ŪHDFSĄ─ę╗░ŃŲ¾śI╝ēĄ─╬─╝■ęÄ─ŻĪŻHDFSų¦│ų┤¾╬─╝■┤µā”Ż¼╠ßĖ▀öĄō■é„▌öĦīÆĪŻå╬ę╗Ą─HDFSīŹ└²┐╔ęįų¦ō╬öĄęįŪ¦╚fėŗĄ─╬─╝■Ż¼Č°Ūę┐╔ęįį┌ę╗éĆ╝»╚║ųąöUš╣ĄĮÄū░┘éĆ╣سcĪŻ
(4)║åå╬ę╗ų┬ąį─Żą═ĪŻī”╬─╝■īŹąąę╗┤╬ąįīæĪóČÓ┤╬ūxĄ─įLå¢─Ż╩ĮŻ¼╩ŪHDFSĄ─æ¬ė├│╠ą“│Żė├Ą─╠Ä└ĒĘĮ╩ĮĪŻ╬─╝■Į©┴óų«║¾Ż¼öĄō■īæ╚ļ═Ļ│╔ų«║¾Š═▓╗į┘ū÷Ė³Ė─ĪŻĮŌøQ┴╦öĄō■ę╗ų┬ąįå¢Ņ}Ż¼═╠═┬┴┐å¢Ņ}ę▓Ą├ęįĮŌøQĪŻ
(5)ęŲäėėŗ╦Ń▒╚ęŲäėöĄō■Ė³║åå╬ĪŻęŲäėöĄō■▒╚ęŲäėėŗ╦Ńį┌┤¾╬─╝■╔ŽüĒĄ─┤·ārĖ³Ė▀ĪŻ▓┘ū„║Ż┴┐öĄō■Ą─Ģr║“ą¦╣¹ė·╝ė├„’@Ż¼▀@śė┐╔ęį╠ßĖ▀ŽĄĮyĄ─═╠═┬┴┐║═£p╔┘ŠWĮjĄ─ōĒ╚¹ĪŻ
(6)«Éśŗ▄øė▓╝■ŲĮ┼_ķgĄ─┐╔ęŲų▓ąįĪŻ┐╔ęŲų▓ąį╩╣Ą├HDFS┐╔ęįū„×ķ▀mæ¬ąį║▄ÅŖĄ─┤¾ęÄ─ŻöĄō■æ¬ė├ŲĮ┼_ĪŻ
1.2¾wŽĄĮYśŗ
HDFS╩Ūę╗éĆ╣▄└Ēš▀ę╗╣żū„š▀ĮYśŗĄ─¾wŽĄĪŻHDFS╝»╚║ė╔ę╗éĆNameNodeŻ©╣▄└Ēš▀Ż®║═ę╗ą®DataNode(╣żū„š▀)ĮM│╔ĪŻNameNode╣▄└Ē╬─╝■ŽĄĮyĄ─į¬öĄō■Ż¼DataNode┤µā”īŹļHĄ─öĄō■ĪŻ┐═æ¶Č╦═©▀^NameNode║═DataNodeĮ╗╗źįLå¢▀@éĆ╬─╝■ŽĄĮyĪŻ┐═æ¶Č╦┬ōŽĄNameNodeęį½@╚Ī╬─╝■Ą─į¬öĄō■Ż¼Č°šµš²Ą─╬─╝■I/O▓┘ū„╩Ūų▒Įė║═DataNode▀MąąĮ╗╗źĄ─ĪŻ
NameNodeŠSūo╬─╝■ŽĄĮyśõ║═▀@éĆśõųą╦∙ėąĄ─╬─╝■║═─┐õøĪŻNameNodeę▓ėøõøų°├┐éĆ╬─╝■Ą─├┐éĆDataNodeēK╦∙į┌Ą─╬╗ų├Ż¼╚╗Č°Ż¼╦³▓ó▓╗ė└Š├ąįĄž┤µā”ēKĄ─╬╗ų├ą┼ŽóĪŻę“×ķį┌ŽĄĮyųžåóĢrŻ¼▀@ą®ą┼ŽóĢ■ė╔DataNodeųžą┬Į©┴óĪŻ
DataNode╩ŪĘų▓╝╩Į╬─╝■ŽĄĮyĄ─╣żū„š▀Ż¼žōž¤╦³éā╦∙į┌Ą─╬’└Ē╣سc╔ŽĄ─┤µā”╣▄└ĒĪŻ▀@ą®╣سcį┌┐═æ¶Č╦╗“š▀NameNodeąĶę¬ĢrŲĄĮ┤µā”║═Öz╦„Ą─ū„ė├Ż¼▓óŪę░č╦³éā┤µā”Ą─ēKĄ─ą┼Žó═©▀^ēKŪÕå╬Ą─ĘĮ╩Įų▄Ų┌ąįĄž╗žüĮoNameNodeĪŻ
łDę╗╩ŪHDFSĄ─ĮYśŗ╩ŠęŌłDĪŻ└²╚ń┐═æ¶Č╦ę¬įLå¢ę╗éĆ╬─╝■Ż¼┐═æ¶Č╦Å─NameNode½@Ą├ĮM│╔╬─╝■Ą─öĄō■ēKĄ─╬╗ų├┴ą▒ĒŻ¼ę▓Š═╩Ūę¬ų¬Ą└öĄō■ēK▒╗┤µā”į┌──ą®DataNode╔ŽŻ╗╚╗║¾Ż¼┐═æ¶Č╦ų▒ĮėÅ─DataNode╔Žūx╚Ī╬─╝■öĄō■ĪŻNameNode▓╗ģó┼c╬─╝■Ą─é„▌öĪŻ
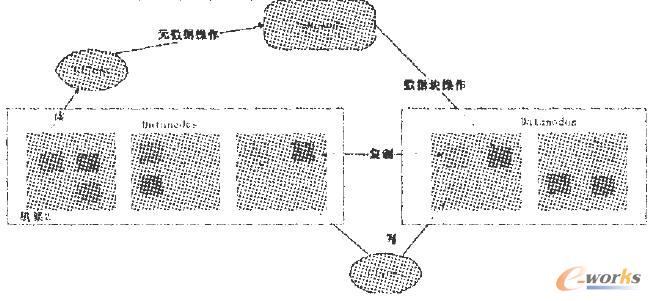
łDę╗HDFSĄ─ĮYśŗ╩ŠęŌłD
1.3▒ŻšŽ┐╔┐┐ąįĄ─┤ļ╩®
HDFSĄ─ų„ę¬įOėŗ─┐ś╦ų«ę╗Š═╩Ūį┌╣╩šŽŪķørŽ┬ę▓─▄▒ŻūCöĄō■┤µā”Ą─┐╔┐┐ąįĪŻHDFSŠ▀éõ┴╦▌^×ķ═Ļ╔ŲĄ─╚▀ėÓéõĘ▌║═╣╩šŽ╗ųÅ═ÖCųŲŻ¼┐╔ęįīŹ¼Fīó║Ż┴┐╬─╝■┤µā”į┌╝»╚║ųąŻ¼▓ó▒ŻūCŲõ┐╔┐┐ąįĪŻ
(1)╚▀ėÓéõĘ▌ĪŻHDFSīó╬─╝■░┤öĄō■ēK(Block)┤µā”Ż¼─¼šJēK┤¾ąĪ×ķ64MBŻ©┐╔┼õų├Ż®Ż¼▓ó▓╔╚Ī┴╦ę╗ŽĄ┴ąĄ─╚▌Õe╠Ä└ĒĪŻ
(2)Ė▒▒Š┤µĘ┼ĪŻ═©│ŻŪķørŽ┬Ż¼Ė▒▒ŠĄ─┤µĘ┼▓▀┬į║▄ĻPµIŻ¼ÖC╝▄ā╚╣سcų«ķgĄ─ĦīÆ▒╚┐ńÖC╝▄╣سcų«ķgĄ─ĦīÆę¬┤¾ĪŻ╦³─▄ė░ĒæHDFSĄ─┐╔┐┐ąį║═ąį─▄ĪŻłD╚²¾w¼F┴╦Å═ųŲę“ūė×ķ3Ą─ŪķørŽ┬Ż¼Ė„öĄō■ēKĄ─Ęų▓╝ŪķørĪŻ
(3)ą─╠°Öz£yĪŻ╝»╚║ųąĄ─├┐éĆDataNodeų▄Ų┌ąįĄžŽ“NameNode░l╦═ą─╠°░³║═ēKł¾ĖµĪŻ╚ń╣¹š²┤_Įė╩šĄĮą─╠°░³Ż¼ätūC├„įōDataNode╣żū„ø]ėą«É│ŻĪŻ
(4)░▓╚½─Ż╩ĮĪŻåóäėŽĄĮyĢrŻ¼NameNode╩ūŽ╚▀M╚ļę╗éĆ░▓╚½─Ż╩ĮĪŻ┤╦Ģr▓╗Ģ■│÷¼FöĄō■ēKĄ─īæ▓┘ū„ĪŻNameNodeĢ■╩šĄĮĖ„éĆDataNodeōĒėąĄ─öĄō■ēK┴ą▒Ēī”╦³Ą─öĄō■ēKł¾ĖµŻ¼╦∙ėąĄ─öĄō■ēKą┼Žó▒╗NameNode½@╚ĪĪŻ
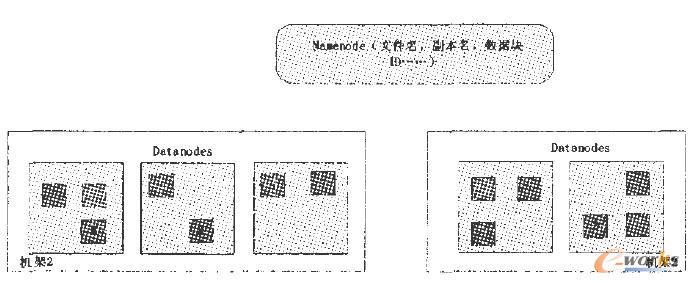
łDČ■Å═ųŲę“ūė×ķ3ĢröĄō■ēKĘų▓╝ŪķørłD
(5)öĄō■═Ļš¹ąįÖz£yĪŻČÓĘNįŁę“Ģ■įņ│╔Å─DataNode½@╚ĪĄ─öĄō■ēKėą┐╔─▄╩Ūōpē─Ą─ĪŻī”╬─╝■ā╚╚▌Ą─ąŻ“×║═Öz▓ķŻ¼ė╔HDFS┐═æ¶Č╦▄ø╝■═Ļ│╔ĪŻ╚ń╣¹ąŻ“×│÷«É│ŻŻ¼┐═æ¶Č╦Š═Ģ■šJ×ķöĄō■ēKėąōpē─Ż¼īóÅ─Ųõ╦¹DataNode╚ĪĄ├įōöĄō■ĘųēKĄ─Ė▒▒ŠĪŻ
(6)┐šķg╗ž╩šĪŻų„ę¬╠Ä└Ē▒╗äh│²╬─╝■Ą─┼RĢr┤µĘ┼å¢Ņ}Ż¼▒ŻūCŲõį┌ę╗Č©Ą─Ģrķgā╚▀Ć┐╔ęį▒╗╗ųÅ═Ż¼│¼▀^ĢrŽ▐Ż¼ätßīĘ┼ŽÓæ¬öĄō■ēKĪŻ
(7)į¬öĄō■┤┼▒P╩¦ą¦ĪŻHDFSĄ─║╦ą─öĄō■ĮYśŗ╩Ūė│Ž±╬─╝■║═╩┬äš╚šųŠĪŻ╝┘╚ń▀@ą®╬─╝■įŌĄĮōpē─Ż¼HDFSīóĢ■ūāĄ├▓╗┐╔ė├ĪŻ«öNameNodeųžą┬åóäėĄ─Ģr║“Ż¼┐é╩Ū▀xō±ūŅą┬Ą─ę╗ų┬Ą─ė│Ž±╬─╝■║═╩┬äš╚šųŠĪŻį┌HDFS╝»╚║ųąNameNode╩Ūå╬³c┤µį┌Ą─Ż¼╚ń╣¹╦³│÷¼F╣╩šŽŻ¼▒žĒÜ╩ųäėĖ╔ŅAĪŻ─┐Ū░Ż¼▀Ć▓╗ų¦│ųūįäėųžåó╗“š▀ŪąōQĄĮ┴Ē═ŌĄ─NameNodeĪŻ
(8)┐ņššĪŻ┐ņššų¦│ųī”─│éĆĢrķgöĄō■Ą─Å═ųŲŻ¼┐╔ęįį┌HDFSöĄō■▒╗ōpē─ĢrŻ¼└¹ė├╗žØL╠Ä└Ē╗žĄĮ▀^╚źę╗éĆęčų¬š²┤_Ą─Ģrķg³cĪŻĄ½╩Ū─┐Ū░HDFS▓╗ų¦│ų┐ņšš╣”─▄ĪŻ
2 MapReduce
GoogleĄ─MapReduceŠÄ│╠─Żą═┐╔ęį═©▀^HadoopīŹ¼FĪŻHadoopĄ─║╦ą─╩ŪMapReduceŻ«Č°MapReduceīŹļH╔Ž╩Ūę╗ĘNĘų▓╝╩Įėŗ╦Ń─Żą═ĪŻMapReduce╩Ūķ_į┤ŲĮ┼_Ż¼╦∙ėąė├æ¶Č╝┐╔ęį├Ō┘M╩╣ė├▀@éĆ┐“╝▄▓ó▀Mąą▓󹹊Ä│╠ĪŻ╩╣ė├įō─Żą═Ż¼Ęų▓╝╩Į▓óąą│╠ą“Ą─ŠÄīæūāĄ├ĘŪ│Ż║åå╬ĪŻ
Hadoop Map/Reduce┐“╝▄╩Ūę╗éĆų„Ż»Å─╝▄śŗĪŻ╦³░³└©ę╗éĆJobtracker║═╚¶Ė╔Tasktracker(╝»╚║ųą├┐éĆ╣سcČ╝ėąę╗éĆTasktracker)ĪŻJobtracker╩Ūė├æ¶║═MapReduce┐“╝▄ų«ķgĄ─Į╗╗ź³cĪŻTasktracker░┤ššJobtrackerĄ─ųĖ┴Ņł╠ąą╚╬äš▓ó╠Ä└ĒmapļAČ╬ĄĮre-duceļAČ╬Ą─öĄō■▐DęŲĪŻ
MapReduceū„śI(Job)╩Ū┐═æ¶Č╦ł╠ąąĄ─å╬╬╗Ż¼╦³░³└©┴╦▌ö╚ļöĄō■ĪóMapReduce│╠ą“║═┼õų├ą┼ŽóĪŻHadoop═©▀^░čę╗éĆū„śIĘų│╔╚¶Ė╔éĆąĪ╚╬äš(Task)üĒ╠Ä└ĒŻ¼Ųõ░³└©ā╔ĘNŅÉą═Ą─╚╬䚯║Map╚╬äš║═Reduce╚╬äšĪŻėąā╔ĘNŅÉą═Ą─╣سc┐žųŲų°ū„śIł╠ąą▀^│╠Ż║Jobtracker║═ČÓéĆTasktrackerĪŻJobtracker═©▀^š{Č╚╚╬äšį┌Tasktracker╔Ž▀\ąąŻ¼üĒģfš{╦∙ėą▀\ąąį┌ŽĄĮy╔ŽĄ─ū„śIĪŻTasktracker▀\ąą╚╬䚥─═¼ĢrŻ¼░č▀MČ╚ł¾Ėµé„╦═ĄĮJobtrackerŻ¼Jobtrackerätėøõøų°├┐ĒŚ╚╬䚥─š¹¾w▀Mš╣ŪķørĪŻ╚ń╣¹Ųõųąę╗éĆ╚╬äš╩¦öĪŻ¼Jobtracker┐╔ęįųžą┬š{Č╚╚╬䚥Į┴Ē═Ōę╗éĆTasktrackerĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║HadoopĄ─║╦ą─╝╝ąg蹊┐╗“Ė┼╩÷
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/1112156747.html






















