



ę²čį
─┐Ū░Ż¼įSČÓüĒūįė┌ļŖą┼ąąśIĪó╩»ė═╩»╗»ąąśIĪóöĄūų├Į¾wąąśIĪóßt»¤ąąśIŻ¼ęį╝░Web2.0ĪóĮ╚┌Ęų╬÷ąąśIĄ─Ų¾śI╝ēė├æ¶Ż¼š²├µ┼R╬─╝■║═öĄō■┴┐Ą─ųĖöĄ╝ēį÷ķLŻ¼¼FėąĄ─╬─╝■┤µā”įO╩®▓╗─▄▀mæ¬śIäšį÷ķLŻ¼ŽĄĮy╣▄└ĒÅ═ļsŻ¼ŽĄĮy│╔▒ŠĪó▀\ĀI│╔▒Š▓╗öÓ╔Ž╔²Ż¼┤µā”įO╩®├µ┼Rų°ČÓųž╠¶æĄ╚å¢Ņ}ĪŻ╚ńÓ]╝■ĪółDŲ¼Īóę¶ŅlĪóęĢŅlĄ╚ĘŪĮYśŗ╗»öĄō■▒¼š©ąįį÷ķLŻ╗įĮüĒįĮČÓĄ─Ų¾śI╝ēæ¬ė├ī”Ė▀ąį─▄┬ōÖC╩┬äš╠Ä└Ē─▄┴”║═Å═ļs▓ķįā▓┘ū„─▄┴”Ą─ąĶŪ¾▓╗öÓ╠ßĖ▀Ż╗ī”öĄō■įLå¢Ä¦īÆ║═Ēææ¬Ģrķgęį╝░öĄō■Ą─▓óąąįLå¢śIäšėąĖ³Ė▀Ą─ę¬Ū¾Ż╗Ų¾śI¼FėąŽĄĮyĄ─öUš╣─▄┴”▓ŅŻ¼ļyęįØMūŃŲ¾śI┐ņ╦┘ūā╗»Ą─śIäšąĶŪ¾ĪŻé„ĮyĄ─NASĘĮ░ĖöUš╣─▄┴”ėąŽ▐Ż¼▓óŪę├µŽ“Ų¾śI╝ēĄ─NASįOéõārĖ±═∙═∙ĘŪ│Ż░║┘FŻ¼┘Å┘Ięį╝░░▓čb¬Ü┴óĄ─NASįOéõŻ¼īó├µ┼Rų°Š▐┤¾Ą─ĮøØ·ē║┴”║═Ņ~═ŌĄ─ŠSūo│╔▒ŠĪŻę“┤╦Ż¼×ķŲ¾śI╠ß╣®ę╗ĘNĮøØ·┐╔ąąĄ─Īóęūė┌╣▄└ĒĄ─┤µā”ŲĮ┼_Ż¼┐╔ęįÄ═ų·Ų¾śI╩╣ė├▒M┐╔─▄Ą═Ą─│╔▒Š═Ļ│╔öĄō■┼cėŗ╦Ńļpųž├▄╝»ą═╚╬äšĪŻ
įŲėŗ╦ŃŠ▀ėąäėæB▓┐╩Ą─╣”─▄Ż¼┐╔ęį└¹ė├┴«ārĄ─Ę■äšŲ„śŗĮ©Ų¾śI╝ē┤µā”ŲĮ┼_Ż¼Š▀ėąĖ³╝ėÅŚąįĪóĖ³╝ė░▓╚½ęį╝░Ė³Ą═Ą─│╔▒ŠĪŻė╚Ųõ╩Ū╦ĮėąįŲ─▄ē“▒ŻūoŲ¾śI║╦ą─öĄō■Ą─░▓╚½Ż¼ŽÓ▒╚╣½╣▓įŲĘ■䚯¼╦ĮėąįŲĘ■äš╦∙ĦüĒĄ─’LļUĢ■ĮĄĄ═║▄ČÓĪŻŲ¾śIßśī”ĻPµIśIäšæ¬ė├Īó║╦ą─öĄō■┤µā”ęį╝░öĄō■Ą─Ė▀┐╔┐┐ąįąĶŪ¾╔ŽĖ³╚▌ęūĮė╩▄Ų¾śI╦ĮėąįŲĄ─▀\ĀI─Ż╩ĮĪŻ
1 Ų¾śI╦ĮėąįŲ┤µā”─Ż╩Į
1.1 Hadoop Ęų▓╝╩Įėŗ╦Ńķ_į┤┐“╝▄
Hadoop╩ŪApacheŽ┬Ą─ę╗éĆķ_į┤ĒŚ─┐Ż¼ė╔HDFSĪóMapReduceĪóHBaseĪóHive║═ZooKeeperĄ╚ĒŚ─┐ĮM│╔ĪŻHadoop ų„ę¬ė╔ā╔▓┐Ęųśŗ│╔Ż║Hadoop Ęų▓╝╩Į╬─╝■ŽĄĮyŻ©HDFSŻ®║═į┌HDFS╔ŽĄ─MapReduce ŠÄ│╠─Żą═īŹ¼F[3]ĪŻHDFS╩ŪGoogle GFSĄ─ķ_į┤░µ▒ŠĄ─īŹ¼FŻ¼ū„×ķę╗éĆĖ▀Č╚╚▌ÕeĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼╦³─▄ē“╠ß╣®Ė▀═╠═┬┴┐Ą─öĄō■įLå¢Ż¼▀m║Ž┤µā”║Ż┴┐Ż©PB ╝ēŻ®Ą─┤¾╬─╝■Ż©═©│Ż│¼▀^64 MŻ®Ż¼ŲõįŁ└ĒęŖłD1ĪŻ
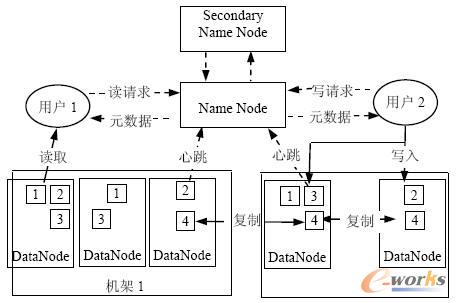
łD1 HDFS Ęų▓╝╩Į╬─╝■ŽĄĮy╝▄śŗ
HDFS▓╔ė├Master/Slave ĮYśŗĪŻŲõųąNameNodeų„꬞ōž¤ŠSūo╝»╚║ā╚Ą─į¬öĄō■Ż¼╦∙ėąēKĄ─į¬öĄō■Č╝▒╗ūóāįį┌NameNodeŻ¼ī”═Ō╠ß╣®äōĮ©Īó┤“ķ_Īóäh│²║═ųž├³├¹╬─╝■╗“─┐õøĄ─╣”─▄ĪŻDataNodežōž¤┤µā”öĄō■Ż¼▓ó╠ßžōž¤╠Ä└ĒöĄō■Ą─ūxīæšłŪ¾ĪŻDataNodeČ©Ų┌Ž“NameNode╔Žł¾ą─╠°Ż¼NameNode═©▀^Ēææ¬ą─╠°üĒ┐žųŲDataNodeĪŻ
Hadoop HBase╩Ū╗∙ė┌Google BigtableĄ─ķ_į┤īŹ¼FŻ¼ī┘ė┌HadoopĄ─ę╗éĆūėĒŚ─┐ĪŻHadoop HBase┐╔═©▀^└¹ė├Hadoop HDFS╠ß╣®Ą─╬─╝■┤µā”ŽĄĮyŻ¼HadoopMapReduce ╠ß╣®Ą─║Ż┴┐öĄō■╠Ä└Ē─▄┴”║═HadoopZookeeper╠ß╣®Ą─ģf═¼Ę■䚯¼śŗĮ©ę╗éĆĖ▀┐╔┐┐ąįĪóĖ▀ąį─▄Īó├µŽ“┴ąĪó┐╔╔ņ┐sĄ─Ęų▓╝╩Į┤µā”ŽĄĮyĪŻ▀@ĘNĘų▓╝╩Į┤µā”ŽĄĮyĄ─╠ž³c╩ŪīŹ¼F┐╔į┌┴«ār╣سc╔Ž┤ŅĮ©Ų┤¾ęÄ─ŻĮYśŗ╗»┤µā”╝»╚║ĪŻHBaseė╔ę╗éĆų„╣سcŻ©MasterŻ®ģfš{ę╗éĆ╗“ČÓéĆģ^ė“Ę■äšŲ„(Regionserver)Å─╣سcĮM│╔Ż¼ęŖłD2ĪŻ
Hadoop HBaseų„╣سcžōž¤ę²ī¦│§╩╝░▓čbŻ¼Ęų┼õģ^ė“ĮoęčūóāįĄ─ģ^ė“Ę■äšŲ„Ż¼╗ųÅ═ģ^ė“Ę■äšŲ„Ą─╣╩šŽĪŻų„╣سcžō▌d▌^▌pŻ¼ģ^ė“Ę■äšŲ„0ĄĮČÓéĆģ^ė“Ż¼Ēææ¬┐═æ¶Č╦Ą─ūx/īæšłŪ¾ĪŻģ^ė“Ę■äšŲ„═¼Ģržōž¤═©ų¬ų„╣سcŻ¼ģ^ė“Ęų┴čą┬Ą─ūėģ^ė“Ą─ą┼ŽóŻ¼ęį▒Ńų„╣سc╣▄└ĒĖĖģ^ė“Ą─Ž┬ŠĆ╝░╠µ┤·ūėģ^ė“Ą─Ęų┼╔ĪŻHBaseę└┘ćė┌Zookeeper╠ß╣®ģf═¼Ę■䚯¼─¼šJŪķørŽ┬Ż¼ę╗éĆHBaseī”æ¬ę╗éĆZookeeperīŹ└²×ķ╝»╚║ĀŅæB╠ß╣®╩┌ÖÓĪŻ
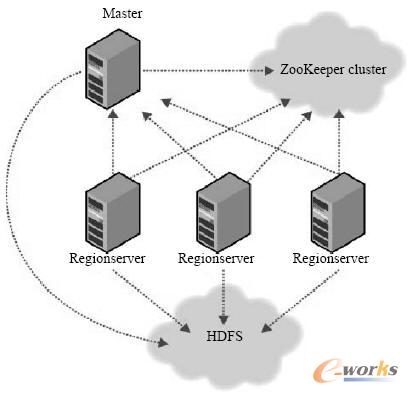
łD2 HBase ŽĄĮy┐é¾wĮYśŗ
1.2 įŲ┤µā”─Ż╩Į┼cé„Įy┤µā”─Ż╩Į▒╚▌^
įŲ┤µā”Ė┼─Ņ╩Ūį┌įŲėŗ╦ŃĖ┼─Ņ╔Žčė╔ņ║═░lš╣│÷üĒĄ─ę╗éĆą┬Ą─Ė┼─ŅĪŻįŲ┤µā”Ą─▒Š┘|╩ŪĘ■䚯¼įŲ┤µā”═©▀^ėŗ╦ŃÖC╝»╚║╝╝ągĪóŠWĖ±╝╝ąg║═Ęų▓╝╩Į╬─╝■ŽĄĮyĄ╚╝╝ągŻ¼īóŠWĮjųą┤¾┴┐Ė„ĘN▓╗═¼ŅÉą═Ą─┤µā”įOéõĮM┐ŚŲüĒģf═¼╣żū„Ż¼╠ß╣®Įyę╗Ą─öĄō■┤µā”Ę■äš║═śIäšįLå¢╣”─▄Ą─ę╗ĘN┤µā”─Ż╩ĮĪŻŲ¾śI╦ĮėąįŲ┤µā”─Ż╩ĮīŹ¼FŲ¾śI¼Fėą┘Yį┤Ą─Ė─įņöUš╣Ż¼Å─Č°æ¬ī”Ų¾śI╝ēė├æ¶Ė▀╦┘į÷ķLĄ─öĄō■┴┐┤µā”śIäš┼cöĄō■Ė▀╦┘╠Ä└ĒśIäšĪŻ
įŲ┤µā”─Ż╩Į▒╚▌^é„Įy┤µā”─Ż╩ĮŠ▀ėą╚ńŽ┬╠ž³cŻ║Ą┌ę╗Ż¼į┌╣”─▄╔ŽŻ¼ŽÓ▒╚é„Įy┤µā”─Ż╩Į├µŽ“╚ńĖ▀ąį─▄ėŗ╦ŃĪó╩┬äš╠Ä└Ēæ¬ė├Ż¼įŲ┤µā”─Ż╩ĮŠ▀ėą├µŽ“ČÓĘNŅÉą═Ą─ŠWĮjį┌ŠĆ┤µā”Ę■䚥─╠ž³cŻ╗Ą┌Č■Ż¼į┌ąį─▄╔ŽŻ¼įŲ┤µā”─Ż╩ĮŠ▀ėąĖ▀öĄō■░▓╚½ąįĪóĖ▀┐╔┐┐ąįĪóĖ▀ą¦┬╩Ż¼ęį╝░▀m║Ž╠Ä└Ē┤¾ęÄ─Żė├æ¶ĪóŠWĮjŁhŠ│Å═ļsČÓūāĄ╚śI䚥─╠ž³cŻ╗Ą┌╚²Ż¼į┌öĄō■╣▄└Ē╣”─▄╔ŽŻ¼įŲ┤µā”─Ż╩ĮąĶę¬ØMūŃé„Įy╬─╝■įLå¢ĘĮ╩ĮŻ¼═¼Ģr─▄ē“ų¦│ų║Ż┴┐öĄō■╣▄└Ē▓ó╠ß╣®╣½╣▓Ę■äšų¦ō╬╣”─▄Ż¼ęįĘĮ▒ŃįŲ┤µā”ŽĄĮy║¾┼_öĄō■Ą─ŠSūoĪŻ
╗∙ė┌╔Ž╩÷╠ž³cŻ¼įŲ┤µā”─Ż╩Įš¹¾w╝▄śŗūįĄūŽ“╔Žę└┤╬╩ŪŻ║öĄō■┤µā”īėĪóöĄō■╣▄└ĒīėĪóöĄō■Ę■äšīėęį╝░įŲČ╦æ¬ė├īėĪŻöĄō■┤µā”īė░³└©ĄūīėĄ─┤µā”Įķ┘|▓┐╩Īóėŗ╦ŃÖC╝»╚║┤ŅĮ©ęį╝░įOéõ╠ōöM╗»▀^│╠Ż╗öĄō■╣▄└ĒīėīŹ¼Fė├æ¶ÖÓŽ▐┐žųŲĪóöĄō■░▓╚½Ą╚śI䚯╗öĄō■Ę■äšīėīŹ¼FöĄō■┤µā”Īó╣▓ŽĒ║═éõĘ▌śIäš▀ē▌ŗŻ╗įŲČ╦æ¬ė├īėīŹ¼Fė├æ¶Ą─Č©ųŲśIäšĪŻįŲ┤µā”─Ż╩Įš¹¾w╝▄śŗęŖłD3ĪŻ
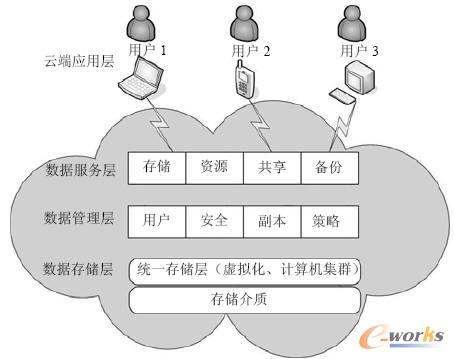
łD3 įŲ┤µā”─Ż╩Įš¹¾w╝▄śŗ
2 Ų¾śI╦ĮėąįŲ┤µā”╝▄śŗ─Żą═
HDFSŠ▀ėąĖ▀╚▌Õeąį║═Ė▀═╠═┬┴┐Ż¼ęį▌^Ą═Ą─│╔▒Šīó║Ż┴┐╬─╝■┤µā”į┌Ųš═©ÖCŲ„╝»╚║╔Ž[8]ĪŻHDFSū„×ķŲ¾śI╦ĮėąįŲ┤µā”ŲĮ┼_Ą─ĄūīėĘų▓╝╩Į╬─╝■ŽĄĮyŻ¼▀m║Ž╠Ä└Ē║═┤µā”┤¾╬─╝■ĪŻĄ½╩ŪŻ¼HDFSŽĄĮyĮYśŗ▓╗▀m║ŽąĪ╬─╝■Ą─╠Ä└Ē║═┤µā”śI䚯¼┐╔ęį└¹ė├HDFSū„×ķī”Ž¾öĄō■┤µā”╚▌Ų„Ż¼═©▀^į┌HDFS╔ŽīėśŗĮ©ę╗éĆ│ķŽ¾īėŻ¼ī”═Ō╠ß╣®ī”Ž¾┤µā”╣”─▄ĪŻ╗∙ė┌HadoopĄ─Ų¾śI╦ĮėąįŲ┤µā”╝▄śŗ─Żą═ęŖłD4ĪŻ
─Żą═ė╔ī”Ž¾įLå¢Įė┐┌īėĪóī”Ž¾į¬öĄō■┤µā”īėĪóī”Ž¾īŹ¾wöĄō■┤µā”║═öĄō■ÜwÖn╣▄└Ēīė╦─▓┐ĘųĮM│╔ĪŻī”Ž¾įLå¢Įė┐┌īėī”═Ō╠ß╣®APIĮė┐┌╣®╔ŽīėįŲæ¬ė├śIäšš{ė├Ż¼═¼Ģr╠ß╣®┴╦RESTĪóSOAP║═HTTPSų¦│ųWEBśI䚥─įLå¢Ż¼╠ß╣®NFSŠWĻPīŹ¼FŠWĮj╬─╝■╣▓ŽĒĘ■äšĪŻī”Ž¾į¬öĄō■┤µā”īė╩Ū╗∙ė┌HBaseīŹ¼FŻ¼žōž¤ī”Ž¾öĄō■äōĮ©Īó▓ķįā║═äh│²Ą╚śI䚯¼└¹ė├HBase┐╔ęįØMūŃŽĄĮyĄ─öUš╣ąį║═Ė▀┐╔┐┐ąįĪŻī”Ž¾īŹ¾wöĄō■┤µā”╗∙ė┌HDFSĘų▓╝╩Į╬─╝■ŽĄĮyŻ¼─▄ē“īŹ¼Fī”Ž¾öĄō■║═ÜwÖn╬─╝■Ą─┐╔┐┐┤µā”Ż¼═¼Ģrų¦│ųöĄō■╚▀ėÓĪŻöĄō■ÜwÖn╣▄└Ēīė└¹ė├Hadoop MapReduce─ŻēKīŹ¼Fī”┴Ń╔óąĪī”Ž¾╬─╝■Ą─ÜwÖnśI䚯¼ęį╝░ÜwÖn╬─╝■┤µā”╣▄└Ē║═╩¦ą¦ī”Ž¾Ą─┤┼▒P┐šķg╗ž╩šĄ╚╣”─▄ĪŻ
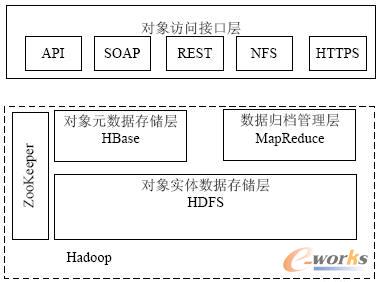
łD4 ╗∙ė┌Hadoop Ą─Ų¾śI╦ĮėąįŲ┤µā”╝▄śŗ─Żą═
ī”Ž¾įLå¢Įė┐┌īė╠ß╣®┴╦ų„┴„Ą─WebĘ■äšĮė┐┌Ż¼ų„꬞ōž¤×ķįŲČ╦æ¬ė├╠ß╣®įLå¢Įė┐┌ĪŻį┌Hadoopķ_į┤┐“╝▄Ž┬īŹ¼F┐╔╣®æ¬ė├īėš{ė├Ą─APIĮė┐┌Īó═Ō▓┐æ¬ė├┐╔ęį═©▀^Įė┐┌š{ė├īŹ¼Fī”ī”Ž¾į¬öĄō■Ą─äōĮ©Īó▓ķįā║═äh│²Ą╚╣”─▄ĪŻ
ī”Ž¾į¬öĄō■┤µā”īėų„ę¬└¹ė├HBaseķ_į┤╝▄śŗīŹ¼F┴╦ī”Ž¾į¬öĄō■Ą─╣▄└ĒĄ╚╣”─▄ĪŻHBaseĮķė┌NoSQL║═RDBMSų«ķgŻ¼āH─▄═©▀^ų„µIŻ©row keyŻ®║═ų„µIĄ─rangeüĒÖz╦„öĄō■Ż¼āHų¦│ųå╬ąą╩┬äšĪŻįō─Żą═Ą─ī”Ž¾į¬öĄō■┤µā”īė╣▓įOėŗ┴╦╚²Åł▒ĒŻ¼Ęųäe╩Ūė├ė┌┤µā”ī”Ž¾į¬öĄō■╦„ę²ą┼ŽóĄ─╦„ę²╚▌Ų„▒ĒŻ¼╦„ę²╚▌Ų„▒ĒĮYśŗęŖ▒Ē1Ż¼ė├ė┌├Ķ╩÷ī”Ž¾į¬öĄō■ą┼ŽóĄ─ī”Ž¾į¬öĄō■▒ĒŻ¼ī”Ž¾į¬öĄō■╦„ę²▒ĒęŖ▒Ē2║═├Ķ╩÷ė├æ¶äh│²Ą─╩¦ą¦öĄō■Ą─ęčäh│²öĄō■▒ĒŻ¼ęčäh│²öĄō■▒ĒĮYśŗęŖ▒Ē3ĪŻī”Ž¾į¬öĄō■┤µā”īėĮ©┴óį┌HBaseų«╔ŽŻ¼═©▀^╣▄└Ē║═ŠSūo▀@╚²Åł▒ĒīŹ¼F┴╦ī”Ž¾į¬öĄō■Ą─äōĮ©Īó▓ķįā║═äh│²Ż¼ęį╝░ąĪ╬─╝■öĄō■ÜwÖnĄ─╣”─▄ĪŻ«öįLå¢īė╠ßĮ╗äōĮ©öĄō■šłŪ¾║¾Ż¼ŽĄĮyĢ■Öz▓ķįLå¢║ŽĘ©ąį║═╦„ę²╚▌Ų„▒ĒĄ─╚▌┴┐Ż¼╚ń╣¹╦„ę²╚▌Ų„▒ĒĄ─╚▌┴┐▓╗ē“Ż¼īóĢ■äōĮ©ę╗Ślą┬Ą─ī”Ž¾į¬öĄō■╦„ę²╚▌Ų„ėøõøĪŻ═©▀^Öz▓ķ║¾īóī”Ž¾į¬öĄō■ą┼Žó╠Ē╝ėų┴ī”Ž¾į¬öĄō■╦„ę²▒ĒŻ¼═¼ĢrĖ³ą┬╦„ę²╚▌Ų„▒ĒĄ─╚▌┴┐Ż¼ūŅ║¾īóī”Ž¾į¬öĄō■┤µā”ĄĮHDFS╬─╝■ŽĄĮyųąĪŻ«öįLå¢īė╠ßĮ╗äh│²öĄō■šłŪ¾║¾Ż¼ŽĄĮyĢ■Öz▓ķįLå¢║ŽĘ©ąįŻ¼═©▀^Öz▓ķ║¾äh│²ī”Ž¾į¬öĄō■į┌ī”Ž¾į¬öĄō■╦„ę²▒ĒųąĄ─╦„ę²ą┼ŽóŻ¼═¼Ģrį┌ęčäh│²öĄō■▒Ē╠Ē╝ėę╗Śläh│²öĄō■ėøõøŻ¼Ė³ą┬╦„ę²╚▌Ų„▒Ē╚▌┴┐Ż¼▀M╚ļöĄō■ÜwÖnų▄Ų┌ĢrŻ¼ŽĄĮyīóĢ■äh│²HDFS╬─╝■ŽĄĮyųąĄ─ī”Ž¾į¬öĄō■ĪŻ

▒Ē1 ╦„ę²╚▌Ų„▒Ē

▒Ē2 ī”Ž¾į¬öĄō■╦„ę²▒Ē

▒Ē3 ęčäh│²ī”Ž¾į¬öĄō■▒Ē
öĄō■ÜwÖn╣▄└ĒīėĄ─ų„ę¬╚╬äš╩Ūų▄Ų┌ąįł╠ąąĄ─MapReduce╚╬䚯¼īŹ¼Fī”Ž¾īŹ¾wöĄō■Ą─ÜwÖn║═ē║┐s╣żū„ĪŻŽĄĮyų▄Ų┌ąįĄ─Æ▀├Ķī”Ž¾į¬öĄō■┤µā”īėį¬öĄō■ą┼Žó▒ĒŻ¼Įyėŗ╬┤ÜwÖnĄ─öĄō■ą┼ŽóŻ¼Ė∙ō■┼õų├Ą─ÜwÖn╬─╝■┤¾ąĪŽ▐ųŲŻ¼ī”öĄō■▀MąąĘųĮMĪŻĘųĮM═Ļ│╔║¾īó├┐éĆĘųĮMųąĄ─ī”Ž¾╬─╝■║Ž▓óĄĮę╗éĆÜwÖn╬─╝■ųąŻ¼Ė³ą┬ŽÓĻPī”Ž¾į¬öĄō■ą┼Žó▒ĒųąĄ─öĄō■ś╦ūRą┼ŽóĪŻ
3 ĮYšō
╗∙ė┌HadoopīŹ¼FĄ─Ų¾śI╦ĮėąįŲ┤µā”ŲĮ┼_Ż¼─▄ē“×ķŲ¾śI╠ß╣®ę╗ĘN┴«ārĄ─┤¾ęÄ─ŻöĄō■┤µā”ęį╝░Ė▀╦┘öĄō■╠Ä└ĒĄ─ĮŌøQĘĮ░ĖĪŻ═¼ĢrŻ¼įō┤µā”ŲĮ┼_Š▀ėąÅŚąįöUš╣Ą─╠žąįŻ¼─▄ē“ØMūŃŲ¾śIī”┤µā”ŲĮ┼_īŹĢrĄ─░┤ąĶöU╚▌Ą─ąĶŪ¾ĪŻ╗∙ė┌HBaseīŹ¼FĄ─ī”Ž¾┤µā”─Żą═Ż¼ęįHDFSū„×ķöĄō■┤µā”Ą─╚▌Ų„Ż¼ĮŌøQ┴╦öĄō■╚▀ėÓéõĘ▌Ą─å¢Ņ}ĪŻßśī”Ų¾śI▓┐ķT▒ŖČÓŻ¼Ė„▓┐ķTöĄō■Ė±╩Į▓╗═¼Ą╚Ūķør[10]Ż¼Ų¾śI╦ĮėąįŲ┤µā”ŲĮ┼_ĮŌøQ┴╦ĘŪĮYśŗ╗»║═░ļĮYśŗ╗»Ą─╦╔╔óöĄō■┤µā”Ż¼ęį╝░┤µā”īėĄ─┐╔┐┐ąį║═┐╔öUš╣ąįĄ╚å¢Ņ}ĪŻļm╚╗HDFSŽĄĮyĮYśŗ▓╗▀m║Ž┤µā”┤¾┴┐ąĪ╬─╝■Ż¼Ą½╩Ū═©▀^æ¬ė├MapReduceĘų▓╝╩Įėŗ╦Ń╠Ä└Ē╝▄śŗį┌║¾┼_╠ß╣®ī”Ž¾ÜwÖn╣▄└Ē╣”─▄Ż¼╩╣Ą├įō─Żą═┐╔ęįØMūŃ┤¾┴┐ąĪ╬─╝■Ą─┤µā”ļyŅ}ĪŻ═¼ĢrŻ¼╗∙ė┌HadoopĄ─Ų¾śI╦ĮėąįŲ┤µā”ŲĮ┼_į┌ī”Ž¾įLå¢Įė┐┌īėīŹ¼F┴╦╣”─▄žSĖ╗Ą─Įė┐┌Ż¼─▄ē“ØMūŃŲ¾śI╚šęµį÷ķLĄ─æ¬ė├ąĶŪ¾ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║╗∙ė┌Hadoop Ų¾śI╦ĮėąįŲ┤µā”ŲĮ┼_Ą─śŗĮ©
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/1112156807.html






















