



1 ę²čį
╚╬║╬ę╗ĒŚą┬╝╝ąg╗“š▀ą┬Ą─Ę■äš─Ż╩ĮĄ─│╔╣”Ż¼═∙═∙╩Ūę“×ķŲõ│÷¼Fį┌ŪĪ«öĄ─ĢrķgŻ¼▓óŪęėą║Ž▀mĄ─═Ōę“║═ā╚ę“üĒ═Ųäė(└²╚ń:Üó╩ų╝ēĄ─æ¬ė├)Ż¼Š═Ž±WWWĄ─│╔╣”æ¬ė├═Ųäė┴╦╗ź┬ōŠWĄ─Ųš╝░ę╗śėŻ¼įŲėŗ╦Ńę▓▓╗└²═ŌĪŻ
2001─ĻŻ¼Googleį┌╦č╦„ę²Ūµ┤¾Ģ■╔Ž╩ū┤╬╠ß│÷įŲėŗ╦ŃĄ─Ė┼─ŅŻ¼2007─Ļ─ĻĄūŻ¼GoogleĄ─ę╗├¹╣ż│╠Ĥį┘┤╬╠ß│÷┴╦įŲėŗ╦ŃŻ¼ūį┤╦Ż¼įŲėŗ╦Ńķ_╩╝Ą├ĄĮ╣żśIĮńĪóīWągĮńĪó║═Ė„ć°š■Ė«Ą─ÅVĘ║Ēææ¬Ż«Ą½įŲėŗ╦ŃĄ─Üv╩Ę£Yį┤┐╔ęįūĘ╦▌ĄĮį¬ėŗ╦Ń(Metacomputing)ĪóŲš▀mėŗ╦Ń(pervasive computing)Īó░┤ąĶėŗ╦Ń(On demand computing)Īóą¦ė├ėŗ╦Ń(Utility computing)Īóūįų„ėŗ╦Ń(Autonomiccomputing)ĪóŠWĖ±ėŗ╦Ń(Grid computing)Ą╚Ą╚Ż¼ć└Ė±ęŌ┴x╔ŽųvŻ¼įŲėŗ╦Ń▓ó▓╗╩Ūę╗ĘN═Ļ╚½ęŌ┴x╔ŽĄ─ą┬╝╝ągŻ¼Č°╩Ūę╗ĘNą┬Ą─Ę■äš─Ż╩ĮŻ¼įŲėŗ╦Ńīóæ¬ė├║═ėŗ╦ŃÖC┘Yį┤░³└©ė▓╝■║═ŽĄĮy▄ø╝■╠ōöM╗»ų«║¾░³čb│╔Ę■䚯¼═©▀^░┤ąĶĖČ┘M(pay-as-you-go)Ą─ĘĮ╩Į┤®įĮInternetüĒØMūŃė├æ¶Ė„ĘN▓╗═¼Ą─ąĶŪ¾Ż¼ė├æ¶┐╔ęį▓╗į┘ąĶę¬┘Å┘I░║┘FĄ─ėŗ╦ŃÖCŽĄĮyŻ¼▓╗į┘ę“×ķąĶę¬Č╠Ģrķg╩╣ė├─│éĆ▄ø╝■Č°▓╗Ą├▓╗┘Å┘Iįō▄ø╝■Ą─╩╣ė├░µÖÓŻ¼▀@ĘNĘ■äš─Ż╩Įį┌▀^╚źĄ─╩«ČÓ─Ļųąėą▀^│õĘųĄ─╠ĮėæŻ¼▀@ā╔─ĻĄ─Ą─ųžą┬┼dŲ▓óęįę╗éĆą┬Ą─╝╝ąg├¹į~│÷¼FŻ¼▓ó▓╗╩Ūę“×ķ«a╔·┴╦─│ĘN╝╝ąg╔ŽĄ─═╗ŲŲŻ¼Č°╩Ūė╔ė┌ą┼ŽóöĄūų╗»ī¦ų┬öĄō■Ą─▒¼š©ąįį÷ķL╦∙ĦüĒĄ─ę╗ŽĄ┴ąå¢Ņ}ūī╬ęéā▓╗Ą├▓╗ųžą┬╦╝┐╝ėŗ╦ŃÖCŽĄĮy░lš╣Ą─ą┬ū▀Ž“Ż¼┴Ē═ŌŻ¼ė╔ė┌╝╝ąg▀M▓Į╦∙ĦüĒĄ─▓┐Ęų└Ž╝╝ągĄ─ųžą┬Å═╠Kę▓ī”įŲėŗ╦ŃĄ─░lš╣ŲĄĮ┴╦═Ų▓©ų·×æĄ─ū„ė├ĪŻ
▒Š╬─ĮķĮBįŲėŗ╦Ń░lš╣Ą─▒│Š░║═ų„ę¬äė┴”Ż¼╠ĮėæįŲėŗ╦ŃĄ─╠ž³c║═ā×ä▌Ż¼▓óÅ─įŲ¾wŽĄĮYśŗĄ─ĮŪČ╚Ż¼╠Įėæ┴╦įŲ╗∙ĄAįO╩®Ž┬Ą─įŲėŗ╦ŃĪóįŲ┤µā”║═įŲé„▌ö╦∙├µ┼RĄ─╠¶æ║═ÖCė÷ĪŻ
2 įŲėŗ╦ŃĄ─▒│Š░║══Ųäė┴”
üĒūįIDCĄ─ł¾Ėµ’@╩ŠŻ¼į┌2011─Ļīóėą1800EB(Exabyte)Ą─öĄō■▒╗«a╔·Ż¼öĄō■─Ļį÷ķL┬╩▀_ĄĮ60%Ż¼į┌▀@ą®öĄō■ųąŻ¼║▄┤¾ę╗▓┐Ęų╩Ūė╔éĆ╚╦«a╔·Ą─Ż¼▀@ą®öĄō■ųąĄ─Į^┤¾▓┐Ęųīó┤µā”į┌╩└ĮńĖ„ĄžĄ─┤¾ą═öĄō■ųąą─Ż¼╚╗Č°Ż¼─▄║─║═Ąž░Õ┐šķg(floorspace)│╔×ķ«öŪ░įOėŗ║═╣▄└Ē┤¾ą═öĄō■ųąą─╦∙├µ┼RĄ─ųžę¬╠¶æŻ¼└²╚ńŻ¼2005─Ļ├└ć°ą┬Į©┴óĄ─öĄō■ųąą─ąĶꬎ¹║─Ą──▄┴┐ŽÓ«öė┌╝ė└¹ĖŻ─ßüåų▌╦∙Ž¹║──▄┴┐Ą─10%(┤¾╝s5GW)Ż¼ąĶę¬╗©┘M┤¾╝s40ā|├└ĮŻ¼ėóć°Ą─1500éĆöĄō■ųąą─├┐─ĻŽ¹║─Ą──▄┴┐║═ėóć°Ą┌╩«┤¾│Ū╩ą╚R┐©╦╣╠ž╦∙ąĶꬥ──▄┴┐ŽÓ«öŻ¼2010─ĻŻ¼ėóć°å╬éĆöĄō■ųąą─├┐─Ļį┌─▄┴┐╔ŽĄ─╗©┘M▀_ĄĮ┤¾╝s740╚fėóµ^ĪŻ
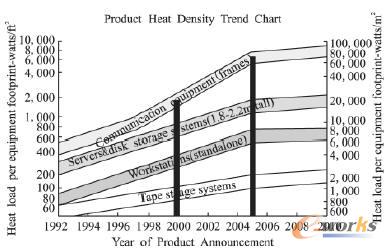
łD1 öĄō■ųąą─Ą─¤ß├▄Č╚┌ģä▌
┴Ē═ŌŻ¼Ž¹║─Ą──▄┴┐│²┴╦╣®Ė„ĘNėŗ╦ŃÖCĮM╝■╣żū„═ŌŻ¼▀Ć«a╔·┤¾┴┐Ą─¤ß┴┐Ż¼ė╔ė┌┤¾▓┐Ęųėŗ╦ŃÖCĮM╝■ų╗─▄į┌ę╗Č©Ą─£žČ╚ŁhŠ│Ž┬▓┼─▄▒ŻūCūŃē“Ą─┐╔┐┐ąįŻ¼ę“┤╦Ż¼▀ĆąĶę¬Ņ~═ŌĄ──▄┴┐“īäėųŲ└õįOéõŻ¼NetappĄ─š{▓ķ▒Ē├„┤¾ą═öĄō■ųąą─ųąųŲ└õŽĄĮyĄ──▄║─āH┤╬ė┌Ę■äšŲ„Ż¼łD1┴ą│÷┴╦öĄō■ųąą─ų„ę¬įOéõĄ─¤ß├▄Č╚┌ģä▌Ż«┐╔ęįšJ×ķŻ¼öĄō■ųąą─Ą──▄║─å¢Ņ}╠Äė┌ę╗éĆÉ║ąį裣hĄ─ĀŅæBĪŻ
į┘š▀Ż¼ė╔ė┌öĄō■Ą─į÷ķLī¦ų┬öĄō■ųąą─ī”ą┬įOéõąĶŪ¾Ą─▓╗öÓį÷╝ėŻ¼Ą½╩ŪöĄō■ųąą─Ą─┐╔öUš╣ąį═Ļ╚½╩▄Ž▐ė┌ŲõĄž░Õ┐šķgŻ¼į┌öĄō■ųąą─Ą─┐šķg╬┤öUš╣Ą─ŪķørŽ┬Ż¼ļSų°å╬╬╗Ąž░Õ├µĘeā╚ėŗ╦ŃÖCįOéõĄ─▓╗öÓį÷╝ėŻ¼é„ĮyöĄō■ųąą─Ą─įOéõ╚▌┴┐▒žīó▀_ĄĮśOŽ▐ĪŻ
╚╗Č°Ż¼┼cęį╔ŽöĄō■ą╬│╔§r├„ī”▒╚Ą─╩ŪŻ¼įSČÓ┤¾ą═Ų¾śIĄ─IT╗∙ĄAįO╩®Ą─└¹ė├┬╩┤¾╝sų╗ėą35%Ż¼į┌─│ą®Ų¾śIųą┐╔─▄Ģ■Ą═ų┴15%Ż¼Googleę▓ł¾ĖµĘQŲõĘ■äšŲ„Ą─└¹ė├┬╩═∙═∙į┌10%ĄĮ15%ų«ķgŻ¼ę╗ĘĮ├µ╩Ūė╔ė┌öĄō■į÷Øqī¦ų┬¼F┤·öĄō■ųąą─š²├µ┼Rų°─▄║─ĪóĄž░Õ┐šķgĪó║═┐╔öUš╣ąįĄ╚å¢Ņ}Ą─ć└Š■╠¶æ;┴Ēę╗ĘĮ├µät╩ŪIT╗∙ĄAįO╩®┘Yį┤└¹ė├┬╩Ą─śOČ╚Ą═Ž┬Ż¼▀@╩╣Ą├╣żśIĮń▓╗Ą├▓╗ųžą┬╦╝┐╝╦∙├µ┼RĄ─å¢Ņ}Ż¼▓ó┼¼┴”īżŪ¾ĮŌøQĄ─ĘĮĘ©ĪŻ
╠ōöMÖC╝╝ągĄ─ųžą┬Å═╠Kę▓×ķįŲėŗ╦ŃĄ─Ą─░lš╣ŲĄĮ┴╦═Ų▓©ų·×æĄ─ū„ė├Ż¼╠ōöMÖC╝╝ąg│÷¼Fį┌╔Ž╩└╝o70─Ļ┤·Ż¼▓óų„ę¬ė├į┌IBM360Ą─┤¾ą═ÖCųąŻ¼ėŗ╦ŃÖCė▓╝■╝╝ągĄ─░lš╣╗∙▒Š╔Žū±čŁ─”Ā¢Č©┬╔Ż¼¼Fį┌▓╔ė├╔╠ė├╗»Ą─ĮM╝■ĮM│╔Ą─ū└├µļŖ─XŲõąį─▄ęčūŃęįų¦│ųČÓéĆ▓┘ū„ŽĄĮyĄ─▓óąą▀\ąąŻ¼ė╔ė┌╠ōöMÖC╝╝ąg┐╔ęįīŹ¼Fėŗ╦Ń┘Yį┤Ą─░┤ąĶĘų┼õŻ¼ę“┤╦Ż¼═Ļ╚½┐╔ęį└¹ė├╔╠ė├╗»Ą─ėŗ╦ŃÖCĮM╝■üĒśŗįņįŲŁhŠ│Ż¼į┌▀@śėę╗éĆ┤¾Ą─▒│Š░Ž┬Ż¼įŲėŗ╦Ńį┌ĮøÜv┴╦öĄ▌å╝╝ągĄ─Ž┤ČYų«║¾▒╗ųžą┬╠ß╔Žūh│╠ĪŻ
3 įŲ¾wŽĄĮYśŗ
ėŗ╦ŃÖCÅ─šQ╔·ĄĮĮ±╠ņŻ¼ĮøÜv┴╦Äū┤╬┤¾Ą─¾wŽĄĮYśŗ╔ŽĄ─ūā▀wŻ¼Å─╔Ž╩└╝o50─Ļ┤·ĄĮ70─Ļ┤·│§Ų┌Ż¼╗∙▒Š╔Ž╩Ū¬Ü┴óīŻė├Ą─┤¾ą═ÖCŽĄĮyę╗Įy╠ņŽ┬;70─Ļ┤·│§Ų┌ĄĮ80─Ļ┤·ųąŲ┌Ż¼ķ_╩╝ėąą®ąĪą═ÖCŽĄĮy┼cūįėąŠWĮj;80─Ļ┤·ųąŲ┌ĄĮ90─Ļ┤·│§Ų┌Ż¼ķ_╩╝│÷¼FĘ■äšŲ„┼cPC┐═æ¶ÖC═©▀^Šųė“ŠW╗ź▀B;90─Ļ┤·│§Ų┌ų┴Į±Ż¼Ę■äšŲ„┼cPC┐═æ¶ÖC═©▀^Šųė“ŠWĪóÅVė“ŠW╗“InternetŽÓ▀B;«öŪ░š²į┌═ŲäėĄ─įŲėŗ╦ŃätęŌ╬Čų°Å─PCÖCĢr┤·ųžĘĄ┤¾ą═ÖCĢr┤·Ż¼Ą½¼Fį┌Ą─┤¾ą═ÖC(╝┤įŲ)▓╗į┘╩ŪČ©ųŲĄ─īŻė├│¼╝ēėŗ╦ŃÖCŻ¼Č°╩Ūė╔Ąž└Ē╔ŽĘų▓╝Ą─Īó«ÉśŗĄ─┘Yį┤═©▀^╠ōöM╗»╝╝ągŠ█║Žį┌ę╗ŲŻ¼▓ó─▄ē“ī”ė├æ¶╠ß╣®░┤ąĶĄ─┘Yį┤Ęų┼õŻ¼ęį╠ßĖ▀IT╗∙ĄAįO╩®Ą─┘Yį┤└¹ė├┬╩ĪŻ
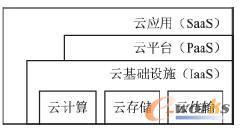
łD2 įŲŁhŠ│Ą─ĮŌ╬÷łD
łD2▒Ē╩Š┴╦įŲŁhŠ│Ą─ĮŌ╬÷łDŻ¼š²╚ńę²čįųą╠ߥĮĄ─įŲėŗ╦Ń╩Ūę╗ĘNĘ■äš─Ż╩ĮŻ¼¼Fį┌īWągĮń║═╣żśIĮńęčĮø▀_│╔╣▓ūRĄ─╩Ū░┤Ę■äšŅÉą═┤¾ų┬┐╔īóįŲėŗ╦ŃĘų×ķ╚²ŅÉ:īó▄ø╝■ū„×ķĘ■äš(Softwareas a serviceŻ¼SaaS)ĪóīóŲĮ┼_ū„×ķĘ■äš(Platform as a serviceŻ¼PaaS)Īó║═īó╗∙ĄAįO╩®ū„×ķĘ■äš(Infrastructure as a ServiceŻ¼IaaS)Ż¼SaaS╩ŪųĖīóæ¬ė├▄ø╝■Įyę╗▓┐╩į┌įŲŁhŠ│Ž┬Ż¼ė├æ¶┐╔ęįĖ∙ō■īŹļHąĶę¬═©▀^Č©ųŲ╗“ūŌė├Ą─ĘĮ╩Į╩╣ė├╗∙ė┌WebĄ─▄ø╝■üĒ═Ļ│╔╦∙ąĶĄ─╣żū„Ż¼PaaSätīóķ_░lŁhŠ│Īóė▓╝■┘Yį┤Ą╚ĮM║Ž│╔ŲĮ┼_▓óęįĘ■䚥─ĘĮ╩Į╠ß╣®Įoė├æ¶Ż¼ė├æ¶ät┐╔ęįį┌įōŲĮ┼_╔Žķ_░læ¬ė├│╠ą“▓ó═©▀^╗ź┬ōŠW╣®Ųõ╦¹ė├æ¶╩╣ė├Ż¼IaaSų„ę¬╩ŪųĖęįĘ■äšĘĮ╩Į╠ß╣®Ė„ĘNIT┘Yį┤Ż¼┐╔ęį░³└©ėŗ╦ŃĪó┤µā”║═ŠWĮjŻ«
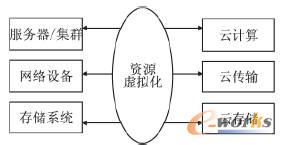
łD3 įŲ╗∙ĄAįO╩®╝▄śŗłD
łDņ`į┌1936─Ļ═©▀^ę╗éĆūxīæ┤┼Ņ^Īóę╗éĆėąŽ▐ĀŅæB┐žųŲŲ„Īó║═ę╗ŚlļpŽ“┐╔¤oŽ▐čėķLĄ─Īó▒╗Ęų│╔ę╗éĆéĆĘĮĖ±Ą─┤┼Ħ(ĘĮĖ±└’īæėąĘ¹╠¢)śŗįņ┴╦ūįäėėŗ╦ŃÖCĄ─└Ēšō─Żą═Ż¼╝┤łDņ`ÖCŻ¼┤╦║¾Ż¼±T·ųZę┴┬³╗∙ė┌łDņ`ÖC▀Mę╗▓Į╠ß│÷┤µā”│╠ą“Ą─Ė┼─ŅŻ¼ųĖ│÷ėŗ╦ŃÖCė╔┐žųŲŲ„Īó▀\╦ŃŲ„Īó┤µā”Ų„Īó▌ö╚ļįOéõ║═▌ö│÷įOéõĮM│╔Ż«ūį┤╦Ż¼±T·ųZę┴┬³ĮYśŗĄņČ©┴╦¼F┤·ėŗ╦ŃÖCĄ─╗∙▒Š╝▄śŗŻ¼╝┤Ż¼ėŗ╦ŃÖCŽĄĮyĮYśŗĄ─蹊┐╗∙▒Š╔Ž┐╔ęį║åå╬ÜwŅÉė┌3éĆå¢Ņ}:ėŗ╦ŃĪó┤µā”┼cé„▌öŻ¼╚²š▀ŽÓ╗źė░ĒæŻ«
─Ū├┤ĄĮĄūįō╚ń║╬üĒśŗįņįŲ╗∙ĄAįO╩®Ą─¾wŽĄĮYśŗ?╬ęéāšJ×ķ¼Fį┌ÅVĘ║šäšōĄ─įŲėŗ╦Ń╩Ūę╗éĆŽÓī”ÅV┴xĄ─├¹į~Ż¼ć└Ė±ęŌ┴x╔ŽüĒųvŻ¼¼Fį┌Ą─įŲėŗ╦Ń┤_ŪąĄ─├¹ūųæ¬įōĮąįŲŁhŠ│Ż¼ū„×ķįŲŁhŠ│ūŅ║╦ą─Ą─▓┐ĘųŻ¼įŲ╗∙ĄAįO╩®æ¬įōū±čŁ±T·ųZę┴┬³¾wŽĄĮYśŗŻ¼īóŲõ┐╔ęįäØĘų×ķįŲėŗ╦ŃĪóįŲ┤µā”║═įŲé„▌öŻ¼╔ŽĒōłD3▒Ē╩Š┴╦įŲ╗∙ĄAįO╩®Ą─╝▄śŗłDŻ¼ė▓╝■┘Yį┤░³└©Ę■äšŲ„/╝»╚║ĪóŠWĮjįOéõ║═┤µā”ŽĄĮyĮø▀^╠ōöM╗»ų«║¾ī”═Ō╠ß╣®░┤ąĶĄ─ėŗ╦ŃĪóöĄō■┤µā”║═é„▌öĪŻ
įŲį┌¾wŽĄĮYśŗ╔Žę╗éĆųžę¬Ą─╠ž³c╩ŪīóĄž└Ē╔ŽĘų▓╝Īó┤¾ęÄ─ŻĪó«ÉśŗĄ─┘Yį┤▀Mąą╠ōöM╗»Ż¼▓ó─▄ē“ī”ė├æ¶╠ß╣®░┤ąĶĘ■äšĪŻ
║▄ČÓßśī”ėŗ╦ŃÖCŽÓĻPĄ─┘Yį┤Ą─įLå¢═∙═∙Č╝▒Ē¼F│÷ę╗ĘN═╗░ląįĄ─ąą×ķŻ¼Ųõų„ę¬▒Ē¼F×ķį┌Č╠Ģrķgā╚ėą┤¾┴┐Ą─╩┬╝■░l╔·Ż«└²╚ńÓ]╝■Ę■äšŲ„═∙═∙į┌įń╔Ž9³cų┴10³cŽÓī”Ę▒├”Ż¼▀@╩Ūę“×ķĮ^┤¾▓┐Ęų╚╦╔Ž░ÓĄ─Ą┌ę╗╝■╩┬Ūķ═∙═∙╩Ū╠Ä└Ēū“╠ņĄ─Ó]╝■Ż¼Č°į┌═Ē╔Ž0³cū¾ėęūŅ┐šķeŻ¼ę“×ķ┤¾▓┐ĘųĄ─╚╦▀@Ģr║“Č╝ą▌Žó┴╦Ż¼▀@ĘN═╗░ląįįLå¢Ą─ų▒Įė║¾╣¹Š═╩Ūī¦ų┬Č╠Ģrķgā╚Ą─┘Yį┤Š╣ĀÄŻ¼Å─Č°įņ│╔ōĒ╚¹║═Ēææ¬ĢrķgĄ─čė▀tŻ¼╔§ų┴ėą┐╔─▄«a╔·Š▄Į^Ę■䚯¼ę╗éĆ║åå╬Ą─└²ūė╚ńŽ┬:╝┘įO─│éĆļŖūėÓ]╝■Ę■äšŲ„ė╔╝»╚║ŽĄĮyśŗ│╔Ż¼┤¾▓┐ĘųĢrķgų╗ąĶę¬╠Ä└Ē3000éĆšłŪ¾├┐├ļŻ¼Ą½į┌═╗░lĢrČ╬▒žĒÜę¬╠Ä└Ē10000éĆI/OšłŪ¾├┐├ļŻ¼╚ń╣¹├┐éĆ╝»╚║╣سc┤┼▒PĄ─╠Ä└Ē─▄┴”×ķ1000éĆI/OšłŪ¾├┐├ļŻ¼ätęŌ╬ČįōŽĄĮyį┌ę╗░ŃŪķørŽ┬ų╗ąĶę¬3éĆ╝»╚║╣سc▓óąą╠Ä└ĒŠ═┐╔ęįØMūŃę¬Ū¾(└ĒŽļŪķør)Ż«╚╗Č°Ż¼į┌═╗░lĢrČ╬▒žĒÜę¬10éĆ╝»╚║╣سc▓óąą╣żū„▓┼─▄▒ŻūCĘ■äš┘|┴┐Ż¼Ę±ätŠ═Ģ■«a╔·Š▐┤¾Ą─įLå¢čė▀tŻ¼╔§ų┴öĄō■üG╩¦Ż¼▀@▒Ē╩Šį┌ĘŪ═╗░lĢrČ╬Ż¼╬ęéā▓╗Ą├▓╗╠ß╣®┤¾┴┐Ą─┘Yį┤ęį▒ŻūC═╗░lĢrČ╬Ę■äšŲ„ŽĄĮyĄ─Ę■äš┘|┴┐ĪŻ
į┌įŲŁhŠ│Ž┬Ż¼╚ń╣¹─▄ē“▌^×ķ£╩┤_Ą─ŅA£yžō▌dĄ─ŪķørŻ¼▀Mąą║Ž▀mĄ─žō▌d▀węŲ║═┘Yį┤š{Č╚Ż¼┐╔ęį║▄┤¾│╠Č╚╔ŽĮŌøQ▀@éĆå¢Ņ}Ż«└²╚ńŻ¼ė╔ė┌Ģr▓ŅŻ¼ųąć°Ģrķgįń╔Ž9³cį┌ėóć°ät╩ŪŽ┬╬ń5³cŻ¼įŲŁhŠ│Ž┬Ż¼į┌ā╔éĆ▓╗═¼ć°╝ęĄ─ŠWĮjė├æ¶į┌▓╗═¼Ą─ĢrķgČ╬Ģ■▒Ē¼Fę╗ĘN═Ļ╚½▓╗═¼Ą─ąą×ķŻ¼┤╦ĢrŻ¼┐╔ęįīóėóć°Š│ā╚Ą─▓┐ĘųįŲ┘Yį┤š{Č╚Įoųąć°╩╣ė├Ż¼üĒĮŌøQį┌ųąć°│÷¼FĄ─öĄō■Ą─═╗░ląįįLå¢Ż¼ę▓┐╔ęįīóėóć°Ą─▓┐Ęųžō▌d▀węŲĄĮųąć°Š│ā╚Ą─įŲ┘Yį┤╔ŽŻ¼Å─Č°ūīį┌▌^ķLę╗Č╬Ģrķgā╚▓╗▒╗įLå¢Ą─▓┐Ęų┘Yį┤▐D╚ļĄ═─▄║─ĀŅæBęį╣Ø╩Ī─▄┴┐Ż¼ę“┤╦Ż¼║══©ė├Ą─ėŗ╦ŃÖCŽĄĮyĮYśŗ▓╗═¼Ą─╩ŪŻ¼įŲĄ─│╔╣”į┌║▄┤¾│╠Č╚╔ŽøQČ©ė┌įŲĄ─ęÄ─Żą¦æ¬Ż¼═¼ĢrŻ¼ę╗éĆįOėŗ┴╝║├Ą─įŲ╗∙ĄAįO╩®æ¬įō─▄ē“║Ž└ĒĄž░▓┼┼ėŗ╦ŃĪó┤µā”║═é„▌öŻ¼╩╣Ą├ŲõęÄ─Ż║═ąį─▄─▄ē“═¼▓ĮöUš╣Ż¼Ž┬├µ╬ęéāüĒ╠ĮėæįŲėŗ╦ŃĪóįŲ┤µā”ĪóįŲé„▌öĖ„ūį├µ┼RĄ─å¢Ņ}ęį╝░┐╔─▄Ą─ĮŌøQĘĮĘ©ĪŻ
4 įŲėŗ╦Ń
įŲėŗ╦ŃŽĄĮy▒╗šJ×ķ╩Ū┐╔ęį╠µ┤·│¼╝ēėŗ╦ŃÖC║═īŻė├Ą─ėŗ╦Ń╝»╚║Ż¼Č°ŪęĖ³┐╔┐┐Īó┐╔öUš╣Ż¼Ųõųąę╗éĆ║▄ųžę¬Ą─┘u³cŠ═╩Ūscaleby credit cardŻ¼Š═╩Ūšfį┌ĮøØ·įS┐╔Ą─ŪķørŽ┬Ż¼┐╔ęį┴ó╝┤▀MąąöUš╣╗“š▀▀Mąą┼RĢrĄ─öUš╣Ż¼┤╦═ŌŻ¼ŠWĖ±ėŗ╦ŃĄ─ę╗ĘN╗∙▒Š╣żū„─Ż╩Į╩Ūė├涎“ŠWĖ±╠ßĮ╗ū„śIŻ¼╚╗║¾ė╔š{Č╚Ų„į┌ŠWĖ±ŁhŠ│Ž┬īżšę║Ž▀mĄ─┘Yį┤üĒ╠Ä└ĒŽÓæ¬Ą─ū„śIŻ¼┤²ū„śI╠Ä└Ē═Ļ│╔ų«║¾į┘īóĮY╣¹ĘĄ▀ĆĮoė├æ¶Ż¼ŠWĖ±ŁhŠ│Ž┬Ą─ū„śI┐╔ęįĘų│╔ā╔ĘN:┼·╠Ä└ĒĄ─ū„śI║═Į╗╗ź╩Į╠Ä└ĒĄ─ū„śIŻ¼ŠWĖ±ŁhŠ│Ž┬Ą─ū„śI╠Ä└ĒĘĮ╩Į┐╔ęį▌^║├Ąžæ¬ī”┤¾ėŗ╦Ń┴┐Īó┼·╠Ä└ĒĄ─ū„śIŻ¼Ą½╩ŪŻ¼ī”ė┌Į╗╗ź╩ĮĄ─ū„śIģs’@Ą├ėąą®┴”▓╗Å─ą─Ż¼═¼ĢrŻ¼ŠWĖ±Ą─▀@ĘN╠Ä└Ē─Ż╩Įę▓║▄å╬ę╗Ż¼╚▒Ę”ņ`╗ŅąįŻ¼╚ń╣¹─▄ē“īóėŗ╦Ń┘Yį┤░┤ąĶĄžĘų┼õĮoė├æ¶Ż¼ė╔ė├æ¶ūįų„Ąž╣▄└Ē║═╩╣ė├┘Yį┤Ż¼ät┐╔ęįśO┤¾Ą─║å╗»ŽĄĮyĄ─╣▄└ĒŻ¼═¼Ģr┘xėĶė├æ¶śO┤¾Ąžņ`╗ŅąįŻ¼Ą½╩ŪŻ¼į┌ŠWĖ±ŁhŠ│Ž┬īŹ¼Fėŗ╦Ń┘Yį┤Ą─░┤ąĶĘų┼õę╗ų▒╩Ūę╗éĆą²Č°╬┤ĮŌĄ─å¢Ņ}Ż¼ī”ė┌įŲėŗ╦ŃČ°čįŻ¼ūŅĻPµIĄ─å¢Ņ}╩Ū╚ń║╬ī”ė├æ¶╔ĻšłĄ─ėŗ╦Ń┘Yį┤īŹąą░┤ąĶĘų┼õŻ¼▓ó─▄▀Mąąėąą¦Ą─öUš╣║═╣▄└ĒĪŻ
4.1 įŲėŗ╦ŃīŹ└²Ęų╬÷
Į³─ĻüĒŻ¼ė╔ė┌ėŗ╦ŃÖCė▓╝■ąį─▄Ą─┤¾Ę∙╠ß╔²(Ė∙ō■MooreČ©┬╔Ż¼CPUąį─▄║═ā╚┤µ╚▌┴┐├┐18éĆį┬Š═┐╔ĘŁę╗Ę¼)Ż¼╩╣Ą├╠ōöMÖC╝╝ąg½@Ą├┴╦┴╝║├Ą─░lš╣╗∙ĄA║═ÅVĘ║Ą─æ¬ė├Ū░Š░Ż¼╠ōöMÖC═©▀^▄ø╝■üĒ─ŻöMŠ▀ėą═Ļš¹ė▓╝■ŽĄĮy╣”─▄Ą─Īó▀\ąąį┌ę╗éĆ═Ļ╚½Ė¶ļxŁhŠ│ųąĄ─═Ļš¹ėŗ╦ŃÖCŽĄĮyŻ¼╠ōöMÖCŠ▀ėą║▄ČÓā׳c:
1)┐╔ęį│õĘų╣▓ŽĒėŗ╦ŃÖC┘Yį┤ęį╠ßĖ▀┘Yį┤Ą─└¹ė├┬╩Ż¼ČÓéĆ▓┘ū„ŽĄĮy┐╔ęį═¼Ģr┤µį┌║═▀\ąąė┌═¼ę╗┼_ėŗ╦ŃÖC╔Ž(į┌å╬éĆĘ■äšŲ„╔Žėą┐╔─▄═¼Ģr▀\ąąöĄ░┘éĆ╠ōöMÖCŲ„)Ż¼▓┘ū„ŽĄĮyĄ─▓┐╩ņ`╗ŅĘĮ▒ŃŻ¼▓óŪę─▄ē“ėąą¦Ė¶ļx▓┘ū„ŽĄĮy║═┘Yį┤;
2)╠ōöMÖCųąĄ─▓┘ū„ŽĄĮy▒└Øó║¾╗ųÅ═▒╚▌^╚▌ęūŻ¼▓ó▓╗Ģ■ī”═¼ę╗éĆ╬’└ĒŲĮ┼_╔ŽĄ─Ųõ╦³▓┘ū„ŽĄĮyįņ│╔ė░ĒæŻ¼Č°Ūę▒╚▌^╚▌ęūīŹ¼F▓┘ū„ŽĄĮyĄ─öĄō■ųžĘ┼║═╗žØLĪŻ
ė╔ė┌╠ōöMÖC╝╝ąg┐╔ęįį┌═¼ę╗éĆėŗ╦ŃÖCė▓╝■ŲĮ┼_╔Ž▀\ąąČÓéĆ▓┘ū„ŽĄĮy║═ŽÓæ¬Ą─æ¬ė├│╠ą“Ż¼▓óŪęėąą¦Ąž▒ŻūC▒╦┤╦ų«ķgĄ─Ė¶ļx║═░▓╚½Ż¼ę“┤╦Ż¼╚ń╣¹į┌═¼ę╗éĆė▓╝■ŲĮ┼_╔Ž▀\ąąČÓéĆ╠ōöMÖCŻ¼īó┐╔ęįśO┤¾Ąž╠ßĖ▀ė▓╝■┘Yį┤Ą─└¹ė├┬╩Ż¼└²╚ńŻ¼ę╗éĆĄõą═Ą─öĄō■ųąą─═∙═∙ėąÓ]╝■Ę■äšŲ„ĪóFTPĘ■äšŲ„ĪóöĄō■ÄņĘ■äšŲ„Ą╚Ż«×ķ┴╦▒ŻūCĘ■䚥─▀B└mąį║═Ė¶ļxå╬éĆĘ■äšŲ„Ą─╩¦ą¦ī”Ųõ╦³Ę■äšŲ„Ą─ė░ĒæŻ¼═©│Żīó├┐éĆæ¬ė├▀\ąąį┌ę╗éƬÜ┴óĄ─ėŗ╦ŃÖCŲĮ┼_╔ŽŻ«└¹ė├╠ōöMÖC╝╝ągŻ¼į┌ė▓╝■┘Yį┤įS┐╔Ą─Śl╝■Ž┬Ż¼═Ļ╚½┐╔ęįį┌═¼ę╗éĆŲĮ┼_╔Ž▀\ąąČÓéĆæ¬ė├Ż¼┴Ē═ŌĘŪ│Żųžę¬Ą─ę╗³c╩ŪŻ¼╠ōöMÖC╝╝ąg╠ß╣®┴╦░┤ąĶ╩╣ė├ėŗ╦Ń┘Yį┤Ą─ę╗ĘN╩ųČ╬║═ĘĮ╩ĮĪŻ
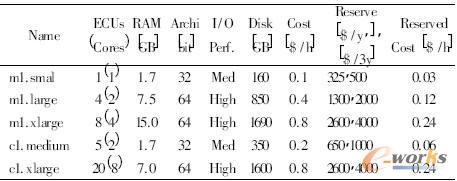
łD4 üå±R▀dĄ─EC2╠ß╣®Ą─5éĆīŹ└²
įŲėŗ╦ŃĘ■äš╔╠üå±R▀dĄ─EC2(Elastic Computing Cloud)Ż¼GoGridČ╝╩Ū═©▀^╠ōöMÖC╝╝ągüĒ╠ß╣®░┤ąĶėŗ╦ŃĘ■䚯¼ė├æ¶ų╗ąĶę¬Įo│÷Š▀¾wĄ─ģóöĄę¬Ū¾Ż¼įŲėŗ╦ŃŲĮ┼_Š═─▄Ęų┼õę╗éĆŽÓæ¬Ą─╠ōöMėŗ╦ŃÖCŻ¼łD4▒Ē╩Šüå±R▀dĄ─EC2╦∙╠ß╣®Ą─īŹ└²ŅÉą═Ż¼ŲõųąECU╩Ūüå±R▀dūį╝║Č©┴xĄ─ę╗éĆCPUĄ─ąį─▄å╬╬╗Ż¼ę╗éĆECUŽÓ«öė┌1Ż¼0-1Ż¼2 GHz 2007 Opteron or Xeon Ą─ąį─▄Ż¼ė├æ¶┐╔ęį╩╣ė├łD4ųą5éĆīŹ└²ųąĄ─╚╬║╬ę╗éĆüĒśŗįņūį╝║Ą─ŽĄĮyŻ¼═¼Ģrė├æ¶▀Ć┐╔ęįĖ∙ō■ąĶꬎ“ęčėąĄ─ŽĄĮyųąį÷╝ė╗“š▀äh£pīŹ└²Ż¼ęįīŹ¼FŽĄĮyĄ─ÅŚąįöUš╣ĪŻ
EC2ū„×ķūŅėą┤·▒ĒąįĄ─įŲėŗ╦ŃŲĮ┼_ų«ę╗Ż¼2008─ĻŻ¼WalkerĘųäe└¹ė├macrobenchmark║═microbenchmarkī”└¹ė├EC2śŗįņĄ─╠ōöM╝»╚║║═ęčėąĄ─Ė▀ąį─▄╝»╚║▀Mąą┴╦ąį─▄Ą─£yįć▒╚▌^ĪŻ
╦¹└¹ė├NAS▓óąąBenchmark£yįć┴╦į┌▓╗═¼Ą─╝»╚║╔Ž▀\ąą┐ŲīWėŗ╦Ńæ¬ė├Ą─ąį─▄Ż¼ę▓└¹ė├┴╦mpptest microbenchmark£yįć┴╦į┌▓╗═¼Ą─╝»╚║╔Ž▀\ąąMPIĄ─ąį─▄Ż¼╦¹Ą─£yįćĮY╣¹▒Ē├„į┌é„ĮyĄ─Ė▀ąį─▄ėŗ╦Ń╝»╚║║═└¹ė├EC2śŗįņĄ─╝»╚║ų«ķg▀Ć┤µį┌ų°▌^┤¾Ą─ąį─▄▓ŅŠÓŻ¼ę“┤╦Ż¼╦¹šJ×ķ└¹ė├╔╠ė├╗»Ą─įŲėŗ╦ŃŲĮ┼_üĒśŗįņĖ▀ąį─▄Ą─╝»╚║ėŗ╦ŃŁhŠ│▀Ćėą║▄ķLĄ─┬ĘąĶę¬ū▀ĪŻ
2009─ĻŻ¼OstermannĄ╚╚╦į┘┤╬└¹ė├üå±R▀dĄ─EC2üĒ▀Mąą┴╦┐ŲīWėŗ╦ŃĘĮ├µĄ─£yįćŻ¼į┌└¹ė├Benchmark£yįć▀^│╠ųąŻ¼║├Äū┤╬ė╔ė┌üå±R▀dįŲėŗ╦ŃŲĮ┼_ĘĮ├µĄ─įŁę“ī¦ų┬£yįć╬┤─▄═Ļ│╔Ż¼▀@Ģrų╗─▄▀Mąą╩ų╣żĄ─Ė╔ŅAŻ¼╦¹éāĄ─£yįćĮY╣¹▒Ē├„į┌įŲėŗ╦ŃŲĮ┼_╔ŽüĒ▀Mąąėŗ╦Ń├▄╝»ą═Ą─┐ŲīWėŗ╦ŃŻ¼Ųõąį─▄║═┐╔┐┐ąįĘĮ├µČ╝▀Ćėą┤²▀Mę╗▓ĮĄž╠ßĖ▀Ż¼▒M╣▄įōŲĮ┼_×ķ┐ŲīW╝ę╠ß╣®┴╦ę╗ĘN┼RĢrĪóČ╠Ģrķgā╚Ą─ėŗ╦Ń┘Yį┤Ą─ĮŌøQĘĮ░ĖĪŻ
éĆ╚╦šJ×ķŻ¼¼FėąĄ─įŲėŗ╦ŃŲĮ┼_æ¬įō─▄ØMūŃéĆ╚╦ė├æ¶Ą─ąĶŪ¾Ż¼Ą½╩ŪŻ¼ī”ė┌┤¾ęÄ─ŻĄ─ėŗ╦Ń├▄╝»ą═Ą─æ¬ė├Ż¼▀Ćėą║▄ČÓå¢Ņ}ėą┤²ĮŌøQĪŻ
4.2 įŲėŗ╦ŃŽĄĮy├µ┼RĄ─╠¶æ
╠ōöMÖC╝╝ągę▓ĦüĒ┴╦ę╗ŽĄ┴ąĄ─å¢Ņ}Ż¼š²╚ńŪ░├µ╠ߥĮĄ─Ż¼╠ōöMÖC╝╝ągūŅ│§╩╣ė├į┌IBM360Ą─┤¾ą═ÖCųąŻ¼┤¾ą═ÖCųą═∙═∙▓╔ė├īŻķTĄ─═©Ą└üĒüĒ▒ŻūC═Ō▓┐įOéõĄ─įLå¢║═ąį─▄Ż¼Ą½╩ŪŻ¼īóįō╝╝ągęŲų▓ĄĮ╗∙ė┌╔╠ė├ĮM╝■Ą─X86ŁhŠ│Ž┬Ż¼ė╔ė┌╚▒Ę”īŻė├Ą─═©Ą└║══©Ą└╠Ä└ĒÖCüĒæ¬ī”I/OįLå¢Ż¼╠ōöMÖCŁhŠ│Ž┬Ą─I/Oå¢Ņ}ęčĮø│╔×ķ«öŪ░╠ōöMÖCŽĄĮyųą├µ┼RĄ─ūŅ┤¾å¢Ņ}Ż¼į┌é„ĮyĄ─ėŗ╦ŃÖCŽĄĮyųąŻ¼æ¬ė├│╠ą“═©▀^ŽĄĮyš{ė├«a╔·«É▓ĮI/O▓┘ū„║¾ų▒ĮėĘĄ╗žŻ¼┤²I/O▓┘ū„═Ļ│╔║¾Ģ■«a╔·ųąöÓĮo▓┘ū„ŽĄĮyŻ¼▓óīóI/O▓┘ū„«a╔·Ą─öĄō■Į╗Įoæ¬ė├│╠ą“Ż¼╚╗Č°į┌╠ōöMÖCŁhŠ│Ž┬Ż¼įō▀^│╠▒╗śO┤¾ĄžÅ═ļs╗»┴╦Ż¼ęįłD5×ķ└²Ż¼į┌Ą┌Č■éĆė“ųąĄ─æ¬ė├│╠ą“═©▀^ŽĄĮyš{ė├«a╔·«É▓ĮI/OŻ¼įōI/OųĖ┴ŅĢ■▀M╚ļ╠ōöMÖC╣▄└Ē│╠ą“(Hypervisor)Ż¼įō╣▄└Ē│╠ą“īóįōI/O▓┘ū„▐DĮoĄ┌┴ŃéĆė“Ż¼╚╗║¾ĘĄ╗žĄĮĄ┌Č■éĆė“Ą─▓┘ū„ŽĄĮy(ę“×ķ╩Ū«É▓ĮI/O)║═╔ŽīėĄ─æ¬ė├│╠ą“Ż¼┤╦ĢrĄ┌┴ŃéĆė“Ą─▓┘ū„ŽĄĮyīó▀MąąīŹļHĄ─I/O▓┘ū„Ż¼┤²I/O═Ļ│╔║¾Ż¼Ģ■«a╔·ę╗éĆ╠ōöMųąöÓĮoĄ┌┴ŃéĆė“Ą─▓┘ū„ŽĄĮyŻ¼įō▓┘ū„ŽĄĮyĮo╠ōöM╗»▄ø╝■░l│÷ŽÓæ¬Ą─╠ōöMųąöÓŻ¼┤²╠ōöM╗»▄ø╝■═Ļ│╔I/O║¾Ż¼Ģ■ĮoĄ┌┴ŃéĆė“Ą─▓┘ū„ŽĄĮyĘĄ╗žę╗éĆŽĄĮyš{ė├üĒåŠąčĄ┌Č■éĆė“Ą─▓┘ū„ŽĄĮyŻ¼╚╗║¾╠ōöMÖC╣▄└Ē│╠ą“īóI/O═Ļ│╔Ą─ųąöÓĮ╗ĮoĄ┌Č■éĆė“Ą─▓┘ū„ŽĄĮyŻ¼ūŅ║¾īóI/O▓┘ū„«a╔·Ą─öĄō■Į╗ĮoĄ┌Č■éĆė“ųąĄ─æ¬ė├│╠ą“Ż¼ė╔┤╦┐╔ęŖŻ¼į┌╠ōöMÖCŁhŠ│Ž┬Ą─I/O▓┘ū„▒žīó│╔×ķš¹éĆŽĄĮyĄ─Ų┐ŅiĪŻ
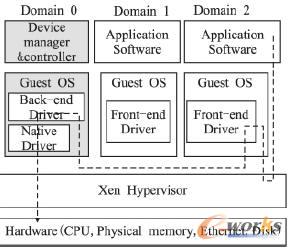
łD5 ╗∙ė┌XENĄ─ę╗éĆĄõą═Ą─╠ōöMÖCŁhŠ│
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║įŲ╗∙ĄAįO╩®Ž┬Ą─¾wŽĄĮYśŗĪó╠¶æ┼cÖCė÷(╔Ž)
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/1112156978.html






















