



5 įŲ┤µā”
5.1 įŲ┤µā”īŹ└²Ęų╬÷
¼FėąĄ─įŲ┤µā”Ė³ČÓĄ─╩Ūę╗ĘNį┌ŠĆ▀h│╠éõĘ▌ŽĄĮyŻ¼HuĄ╚╚╦ßśī”╔Ž├µĄ─4ĘNįŲ┤µā”ŽĄĮy▀Mąą┴╦£yįćĪó▒╚▌^║═Ęų╬÷Ż¼«öīó8GBĄ─╬─╝■éõĘ▌ĄĮįŲ┤µā”ŽĄĮyųąĢrŻ¼ėąĄ─ŽĄĮyĄ─éõĘ▌Ģrķg│¼▀^┴╦30éĆąĪĢrŻ¼▀ĆėąĄ─ŽĄĮyį┌Įø▀^4╠ņĄ─Ģrķg▀Ć╬┤éõĘ▌═Ļ│╔Ż¼«ö╦¹éāīóöĄō■╝»£pąĪĄĮ2GBū¾ėęĢrŻ¼įŲéõĘ▌ŽĄĮy▓┼╗žÅ═ĄĮ╗∙▒Šš²│ŻĄ─╣żū„ĀŅæBĪŻ
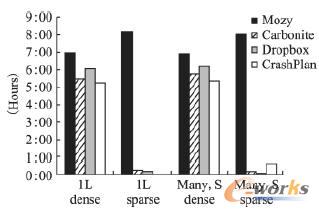
łD6 2.12GBöĄō■Ą─éõĘ▌Ģrķg
łD6▒Ē╩ŠHuĄ╚╚╦į┌╦─éĆ▓╗═¼Ą─įŲ┤µā”ŽĄĮyŽ┬éõĘ▌2.12GBöĄō■ĢrĄ─▀h│╠éõĘ▌ĢrķgŻ¼ŲõųąÖMū°ś╦Å─ū¾ĄĮėęĄ─╦─ĘNŪķørĘųäe▒Ē╩Šå╬éĆ2.12GBĄ─┤¾Ųš═©╬─╝■Īóå╬éĆ2.12GBĄ─┤¾ŽĪ╩Ķ╬─╝■Īó║▄ČÓąĪĄ─Ųš═©╬─╝■ĮM│╔2.12GBĄ─öĄō■╝»Īó║▄ČÓąĪĄ─ŽĪ╩Ķ╬─╝■ĮM│╔2.12GBĄ─öĄō■╝»Ż¼▀@└’Ą─ŽĪ╩Ķ╬─╝■▒Ē╩Šįō╬─╝■▓╗░³║¼ė├æ¶öĄō■Ż¼ę▓ø]ėąĘų┼õė├üĒ┤µā”ė├æ¶öĄō■Ą─┤┼▒P┐šķgŻ¼«ööĄō■▒╗īæ╚ļŽĪ╩Ķ╬─╝■ĢrŻ¼╬─╝■ŽĄĮy(└²╚ń:NTFS)▓┼ųØuĄž×ķŲõĘų┼õ┤┼▒P┐šķgŻ«┐╔ęį┐┤ĄĮī”ė┌š²│Ż2Ż¼12GBĄ─╬─╝■öĄō■╦─éĆŽĄĮyĄ─éõĘ▌ĢrķgČ╝│¼▀^┴╦5ąĪĢrŻ¼łD7▒Ē╩ŠŽÓæ¬Ą─╗ųÅ═ĢrķgŻ¼╗ųÅ═▒╚éõĘ▌ꬎÓī”ēK║▄ČÓŻ¼▀@ų„ę¬╩Ūė╔ė┌ŠWĮjĄ─╔Žąąµ£┬Ę║═Ž┬ąąµ£┬ĘĦīÆĄ─▓╗ī”ĘQįņ│╔Ą─Ż¼═©▀^┤¾┴┐Ą─£yįćĘų╬÷Ż¼HuĄ╚╚╦Ą├│÷┴╦ęįŽ┬ĮYšō:
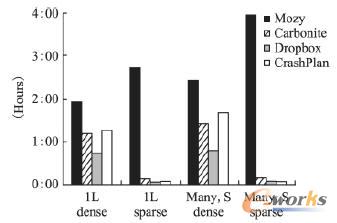
łD7 2.12GBöĄō■Ą─╗ųÅ═Ģrķg
1)įŲ┤µā”ŽĄĮy▒žĒÜī”ė┌ŠWĮj╩¦ą¦Š▀ėą╗žÅŚąįŻ¼═¼Ģr─▄ē“īŹ¼F┤¾╬─╝■Ą─į÷┴┐éõĘ▌;
2)įŲ┤µā”╠ß╣®╔╠į┌▀Mąą┤¾öĄō■Ą─ŠWĮjé„▌öĢr▀Ćę¬▀Mąą╝ė├▄Īóē║┐sĄ╚ŅA╠Ä└Ēęį▒▄├ŌŠWĮjčė▀t;
3)įŲ┤µā”ė├æ¶ąĶę¬╩ųäėÖz£yųžę¬Ą─╬─╝■╩ŪʱČ╝ęčĮø▀Mąą┴╦éõĘ▌;
4)įŲ┤µā”ė├æ¶æ¬įōīóįŲ┤µā”ŽĄĮyū„×ķ▒ŠĄžéõĘ▌ŽĄĮyĄ─ę╗ĘNča│õŻ¼Č°▓╗─▄īóŲõ«ö│╔ų„ꬥ─éõĘ▌▓▀┬įĪŻ
éĆ╚╦šJ×ķŻ¼¼FėąĄ─įŲ┤µā”æ¬ī”Ųš═©ė├æ¶ąĪöĄō■Ą─éõĘ▌┼c╗ųÅ═æ¬įōå¢Ņ}▓╗┤¾Ż¼Ą½╩ŪŲ¾śI╝ēė├æ¶┤¾öĄō■┴┐Ą─┤µā”┼c╗ųÅ═ätę¬╔„ųž┐╝æ]ĪŻ
5.2įŲ┤µā”ŽĄĮy├µ┼RĄ─╠¶æ
įŲ┤µā”ŽĄĮyųąų„ꬥ─┤µā”įOéõ┤┼▒P“īäėŲ„╩Ūę╗ĘNÖCļŖ╗ņ║ŽįOéõŻ¼▀@╩╣Ą├║═ėŗ╦ŃŽÓ▒╚Ż¼┤µā”ŽĄĮyŠ▀ėą┴╦║▄ČÓ▓╗═¼Ą─╠žąįŻ¼ė╔ė┌ą┼ŽóöĄūų╗»╦∙«a╔·Ą─│╩ųĖöĄ╝ēį÷ØqĄ─öĄō■ī”┤µā”ŽĄĮy╠ß│÷┴╦ć└Š■Ą─╠¶æŻ¼ļSų°╔ńĢ■ą┼Žó╗»│╠Č╚Ą─▓╗öÓ╠ßĖ▀Ż¼ī”öĄō■┤µā”Ą─╝▒äĪ╠ß╔²Ż¼ī¦ų┬┴╦ęį"ėŗ╦Ń"×ķųąą─ĄĮęį"öĄō■┤µā”"×ķųąą─Ą─ė^─ŅĖ’ą┬Ż¼į┌▀^╚źĄ─╩«ČÓ─ĻųąŻ¼┤┼▒PĄ─ģ^ė“├▄Č╚Īó▄ē├▄Č╚║═ŠĆ├▄Č╚Ęųäe½@Ą├┴╦100%Ż¼50%║═30%Ą─į÷ķLŻ¼į┌┤µā”ŅIė“ėąā╔éĆųžę¬Ą─╝╝ągī”┤µā”ŽĄĮyĄ─░lš╣║═┤µā”╚▌┴┐Ą─öUš╣«a╔·┴╦ųžę¬Ą─ė░ĒæŻ¼Ą┌ę╗éĆ╩Ū▓óąą┤µā”Ż¼▒╚╚ń┤┼▒PĻć┴ą╝╝ągŻ¼Ą┌Č■éĆŠ═╩ŪŠWĮj╝╝ągī”┤µā”ŽĄĮy¾wŽĄĮYśŗĄ─ė░ĒæŻ¼═©▀^īóŠWĮję²╚ļ┤µā”ŽĄĮyŻ¼Ė─ūāų„ÖC┼c═Ō▓┐┤µā”╣سcķgĄ─▀BĮė─Ż╩ĮŻ¼│÷¼F┴╦╚¶Ė╔ą┬ą═┤µā”¾wŽĄĮYśŗ:ĖĮŠW┤µā”(networkattached storageŻ¼NAS)║═┤µā”ģ^ė“ŠW(storage area networkŻ¼SAN)Ż¼ŠWĮj┤µā”╝╝ągī”ė┌ĮŌøQ┤µā”įOéõĄ─Ęų╔óąįĪóI/OĄ─▓óąąąįĪóģfūhĄ─Ė▀ą¦ąį╠ß╣®┴╦ę╗ĘN║▄║├Ą─╩ųČ╬Ż¼ŠWĮj┼c┤µā”įOéõ▓╗═¼Ą─ĮY║ŽĘĮ╩Į┐╔ęįą╬│╔▓╗═¼═žōõĮYśŗĄ─ŠWĮj┤µā”ŽĄĮyŻ¼▓╗═¼Ą─═žōõĮYśŗī”ė┌ŽĄĮyąį─▄Ą─ė░ĒæėųĖ„▓╗ŽÓ═¼Ż«Ą½ė╔ė┌ąį─▄ĪóārĖ±Īó┐╔öUš╣ąįĄ╚Ė„ĘĮ├µĄ─įŁę“Ż¼╦¹éāę▓▀Ć╩Ū▓╗ūŃęįæ¬ī”▒¼š©ąįĄ─öĄō■į÷ķLĪŻ
┤µā”ŽĄĮy▒žĒÜę¬Å─╔┘öĄĄ─┤µā”ę²ŪµŽ“▀Bį┌ŠWĮj╔ŽĄ─│╔Ū¦╔Ž╚fĄ─╔╠ė├╗»┤µā”įOéõ▀Mąą▐DūāŻ¼į┌▀^╚źĄ─╩«ČÓ─Ļųą╝»╚║ŠWĮjĄ─ųžę¬▀Mš╣ų«ę╗╩Ū┐╔ęįīó│╔Ū¦╔Ž╚fĄ─╣سc▀BŲüĒŻ¼═¼Ģr▒ŻūCĖ▀┐╔öUš╣ąį║═ŽÓī”▌^Ą═Ą─═©ėŹķ_õNŻ¼ę“┤╦Ż¼╬ęéāšJ×ķŻ¼▓╔ė├╔╠ė├╗»Ą─╝╝ągüĒśŗįņ┐╔öUš╣Ą─╝»╚║╩ŪįŲ┤µā”Ą─╗∙▒ŠĮM╝■Ż¼ę“×ķŻ¼╬ęéā┐╔ęįŽ±┤ŅĘe─ŠĄ─ą╬╩ĮüĒŠ█║Ž┤µā”ĮM╝■ęįśŗįņ┤¾ęÄ─ŻĄ─┤µā”ŽĄĮyŻ¼Ą½╩Ū¼FėąĄ─┤µā”ŽĄĮy▀MąąęÄ─ŻĄ─öUš╣ų«║¾▀Ć┤µį┌║▄ČÓ┤²ĮŌøQĄ─å¢Ņ}ĪŻ
5.2.1 ├¹ūų┐šķg
┤µā”Ų„┐šķgĄ─ĮM┐Ś║═Ęų┼õŻ¼öĄō■Ą─┤µā”Īó▒Żūo║═Öz╦„Č╝ę└┘ćė┌╬─╝■ŽĄĮyŻ¼╬─╝■ŽĄĮyė╔╬─╝■║═─┐õøĮM│╔Ż¼öĄō■░┤Ųõā╚╚▌ĪóĮYśŗ║═ė├═Š├³├¹│╔▓╗═¼Ą─╬─╝■Ż¼Č°─┐õøätśŗĮ©╬─╝■ŽĄĮyĄ─īė┤╬╗»ĮYśŗŻ¼¼F┤·Ą─╬─╝■ŽĄĮyę╗░ŃČ╝╩Ū░┤śõą╬Ą─īė┤╬╝▄śŗüĒĮM┐Ś╬─╝■║═─┐õøŻ¼╝»╚║╬─╝■ŽĄĮy═∙═∙ę▓▓╔ė├śõą╬╝▄śŗüĒśŗįņ├¹ūų┐šķgŻ¼╚╗Č°Ż¼«ööĄō■Ą─įLå¢Å─śõĖ∙ū▀Ž“śõ╚~Ą─Ģr║“Ż¼įLå¢Ą─čė▀tĢ■Ēææ¬Ą─į÷╝ėŻ¼┴Ē═ŌŻ¼▀Ćėąā╔éĆųžę¬Ą─ę“╦žī¦ų┬śõą╬╝▄śŗ▓╗▀m║Žė┌įŲ┤µā”ŁhŠ│Ż¼Ą┌ę╗Ż¼śõĖ∙▒Š╔ĒŠ═╩Ūę╗éĆå╬ę╗╩¦ą¦³cŻ¼Č°Ūę║▄╚▌ęūą╬│╔ŽĄĮyĄ─Ų┐ŅiŻ¼Ą┌Č■Ż¼śõą╬╝▄śŗ║▄ļyį┌Internet╔ŽöUš╣ĄĮĄž└Ē╔ŽĘų▓╝Ą─ęÄ─ŻŻ¼┴Ē═ŌŻ¼īė┤╬╗»ĮYśŗ╩╣Ą├╬─╝■Ą─įLå¢ą¦┬╩▓╗Ė▀Ż¼├┐ę╗īė─┐õøČ╝ļ[▓ž┴╦╦³╦∙░³║¼Ą─ūė─┐õø║═╬─╝■Ż¼ė├æ¶║▄ļyų¬Ą└ę╗éĆ─┐õøŽ┬├µĄĮĄūėą──ą®╬─╝■║═ūė─┐õøŻ¼ę“┤╦,ė├æ¶įLå¢─│éĆ╬─╝■ĢrŻ¼▒žĒÜ═©▀^īė┤╬ą═Ą──┐õøśõĮYśŗĄĮ▀_Ųõ▒Ż┤µ╬╗ų├Ż¼╚ń╣¹▓╗ų¬Ą└╬─╝■▒Ż┤µ╬╗ų├Ż¼▒žĒÜ▒ķÜvš¹éĆ─┐õøŻ¼ę“┤╦įŲ┤µā”ų╗ėą▓╔ė├ĘŪ╝»ųą╩ĮĄ─├¹ūų┐šķgüĒ▒▄├ŌØōį┌Ą─ąį─▄Ų┐Ņi║═å╬³c╩¦ą¦ĪŻ
5.2.2 į¬öĄō■ĮM┐Ś
į¬öĄō■╩Ū├Ķ╩÷öĄō■Ą─öĄō■Ż¼ų„ę¬ė├üĒĘ┤ė│ĄžųĘą┼Žó║═┐žųŲą┼ŽóŻ¼═©│Ż░³└©╬─╝■├¹Īó╬─╝■┤¾ąĪĪóĢrķg┤┴Īó╬─╝■ī┘ąįĄ╚Ą╚Ż«į¬öĄō■ų„ę¬╩Ūė├üĒ╣▄└ĒĄ─▓┘ū„öĄō■Ż¼čąŠ┐▒Ē├„Ż¼į┌╬─╝■ŽĄĮyĄ─▓┘ū„ųąŻ¼│¼▀^50%Ą─▓┘ū„╩Ūßśī”į¬öĄō■Ą─Ż¼┴ĒėąčąŠ┐ųĖ│÷Ż¼╩╣ė├NFS3Ż¼0ĢrŻ¼Ųõ┐═æ¶Č╦║═Ę■äšŲ„Č╦Į╗╗źĄ─ą┼Žóųą65%Ą─ą┼Žó╩Ū║═į¬öĄō■ŽÓĻPĄ─Ż¼į¬öĄō■ūŅųžę¬Ą─╠ž³c╩ŪŲõ═∙═∙╩ŪąĪĄ─ļSÖCšłŪ¾Ż¼ę╗░ŃüĒųvŻ¼į¬öĄō■Č╝╩Ū┤µā”į┌┤┼▒P╔ŽĄ─Ż¼╚╗Č°Ż¼║═┤┼▒P┤µā”╚▌┴┐Ą─į÷ķL▓╗═¼Ą─╩ŪŻ¼ė╔ė┌ÖCąĄĮM╝■╦∙ĦüĒĄ─čė▀tŻ¼┤┼▒PĄ─ŲĮŠ∙įLå¢Ģrķg├┐─ĻĄ─ĮĄĄ═▓╗ūŃ8%Ż«łD8▒Ē╩Š┴╦HitachiĄ─┤┼▒Pį┌▀^╚ź╩«─Ļ└’┤┼▒PįLå¢Ģrķg║═īżĄ└ĢrķgĄ─░lš╣┌ģä▌Ż¼ī”ė┌▀@ĘNė╔ąĪĄ─ļSÖCšłŪ¾╦∙ĮM│╔Ą─öĄō■įLå¢┴„ųąŻ¼┤┼▒PĄ─īżĄ└Ģrķg╩Ū┤┼▒PįLå¢čė▀tųąūŅĮMꬥ─▓┐ĘųŻ¼▀@╩Ūė╔ė┌┤┼Ņ^Ą─ĘĆČ©Ģrķgų„ī¦ų°┤┼▒PĄ─īżĄ└ĢrķgŻ¼Č°Ūę┤┼Ņ^Ą─ĘĆČ©ĢrķgöĄ─ĻüĒ╗∙▒Š╔Žø]ėą╠½┤¾Ą─ūā╗»Ż¼ę“┤╦Ż¼ī”ė┌┤¾ęÄ─ŻŽĄĮyüĒųvŻ¼į¬öĄō■Ą─įLå¢═∙═∙│╔×ķųŲ╝sš¹éĆŽĄĮyąį─▄Ą─Ų┐ŅiĪŻ
║▄ČÓĘų▓╝╩ĮĄ─┤µā”ŽĄĮyīóöĄō■įLå¢║═į¬öĄō■Ą─įLå¢Ęųļxķ_üĒŻ¼į┌▀@śėĄ─ŽĄĮyųąŻ¼┐═æ¶Č╦╩ūŽ╚║═į¬öĄō■Ę■äšŲ„═©ėŹüĒ½@╚Īį¬öĄō■░³└©╬─╝■├¹Īó╬─╝■╬╗ų├Ą╚ą┼ŽóŻ¼╚╗║¾Ż¼└¹ė├įōį¬öĄō■Ż¼┐═æ¶Č╦ų▒Įė║═öĄō■Ę■äšŲ„═©ėŹ╚źįL墎Óæ¬Ą─öĄō■Ż¼ę╗░ŃüĒųvŻ¼į¬öĄō■Ę■äšŲ„Ą─ā╚┤µ┐╔ęįØMūŃ┤¾▓┐ĘųĄ─ūxšłŪ¾Ż¼Ą½Ę■äšŲ„▓╗Ą├▓╗ų▄Ų┌ąįĄžįLå¢┤┼▒PüĒūx╚ĪąĶꬥ─öĄō■Ż¼▓óŪę╦∙ėąį¬öĄō■Ą─Ė³ą┬ę▓ę¬īæ╗žĄĮ┤┼▒PŻ¼┤µā”ŽĄĮy┐šķgĄ─į÷ķL┐╔ęį═©▀^į÷╝ėŅ~═ŌĄ─┤µā”Ę■äšŲ„üĒ▒ŻūCŻ¼╚╗Č°Ż¼ī”ė┌ę╗éĆ╣▄└ĒöĄęįā|ėŗĄ─öĄō■╬─╝■Ą─įŲ┤µā”ŽĄĮyŻ¼╚ń║╬▒ŻūCį¬öĄō■Ą─įLå¢ąį─▄║═┐╔öUš╣ąį?ī”ė┌Ž¾įŲ▀@śėĄ─ąĶę¬Ė▀┐╔öUš╣ąįĄ─ŁhŠ│Ż¼ī”į¬öĄō■Ą─ę└┘ćąįĮoŽĄĮyįOėŗĦüĒ┴╦Š▐┤¾Ą─╠¶æĪŻ
6 įŲé„▌ö
░┤ššNielsenĘ©ätŻ¼ĮKČ╦ė├æ¶Ą─ŠWĮjĦīÆęį├┐─Ļ50%Ą─╦┘Č╚į÷ķLŻ¼╚╗Č°Ż¼║═Šųė“ŠWą╬│╔§r├„ī”ššĄ─╩ŪŻ¼ÅVė“ŠWĄ─ąį─▄▓╗▒M╚╦ęŌŻ¼└²╚ńŻ¼ę╗ŚlT1ŠĆ┬ĘĄ─ĦīÆų╗ŽÓ«öė┌Ū¦šūŠWĄ─Ū¦Ęųų«ę╗Ż¼įSČÓļųą└^ŠĆ┬ĘĄ─ĦīÆų╗ėą256Kbits/├ļŻ¼Garfinkel═©▀^£y┴┐░l¼FÅ─├└ć°▓«┐╦└¹┤¾īWĄĮ╬„č┼łDĄ─ŲĮŠ∙ŠWĮjīæĦīÆ┤¾╝s╩Ū5to18Mbits/├ļŻ¼═©▀^╩╣ė├ŠWĮj£yįć╣żŠ▀iperfŻ¼▓╔ė├256éĆöĄō■┴„Ż¼╬ęéāĄ─£y┴┐öĄō■▒Ē├„į┌Ė±┴ų─ßų╬ś╦£╩ĢrķgŽ┬╬ń7³cĄĮ10³cŻ¼Å─ėóć°ä”ś“┤¾īWĄĮųąć°▒▒Š®Ą─ŲĮŠ∙ŠWĮjĦīÆ┤¾╝s╩Ū14Mbits/├ļĪŻ
╗∙ė┌ęį╔ŽĄ─£yįćöĄō■Ż¼╚ń╣¹╝┘įOŠWĮjĦīÆ×ķ20Mbits/├ļŻ¼ArmbrustetalŻ¼Ą╚╚╦ū„┴╦║åå╬Ą─ėŗ╦ŃŻ¼ėŗ╦ŃĮY╣¹▒Ē├„Å─├└ć°▓«┐╦└¹┤¾īWé„▌ö10TBöĄō■ĄĮ╬„č┼łDąĶę¬45╠ņĄ─Ģrķg(10×1012Bytes/(20×106bits/├ļ)=4Ż¼000Ż¼000├ļ=45╠ņ)Ż«╚ń╣¹═©▀^üå±R▀düĒ▀MąąįōöĄō■é„▌öŻ¼ąĶę¬┴Ē═ŌŽ“üå±R▀dų¦ĖČ1000├└ĮĄ─ŠWĮjé„▌ö┘Mė├Ż¼┴Ē═ŌŻ¼ė╔ė┌ÅVė“ŠW╬’└ĒŠÓļxĄ─įŁę“Ż¼▓╗┐╔▒▄├ŌĄ─Ģrčėę▓Ģ■ī”ĦīÆįņ│╔ė░ĒæŻ¼└²╚ńŻ¼ę╗éĆT3µ£┬Ę(44.736Mbits/├ļ)Ż¼«öĢrčė│¼▀^40msĢrŻ¼ŲõĦīÆ║▄┐ņŠ═Ž┬ĮĄĄĮ┼cT1µ£┬Ę(1.544Mbits/├ļ)ŽÓ«öĪŻ
╚ń╣¹╩Ū▀MąąįŲéõĘ▌Ż¼Ģrķg╔ŽĄ─ķ_õNŽÓī”▀Ć┐╔ęį╚╠╩▄Ż¼ę“×ķė├æ¶į┌▒ŠĄž▀Ćėąę╗éĆöĄō■┐ĮžÉ┐╔╣®╩╣ė├Ż¼Ą½╚ń╣¹╩ŪÅ─įŲ┤µā”ŽĄĮyųą╗ųÅ═öĄō■Ż¼▀@╩Ū¤oĘ©ūī╚╦Įė╩▄Ą─Ż¼╠žäe╩Ūī”ė┌─Ūą®ąĶę¬╠ß╣®24×7×365śIäš▀B└mąįĄ─Ų¾śI╝ēė├æ¶Ż¼×ķ┴╦ŠÅĮŌ▀@éĆå¢Ņ}Ż¼ī”ė┌įŲ┤µā”ŽĄĮyųą┤¾öĄō■┴┐Ą─╗ųÅ═Ż¼įŲ┤µā”╠ß╣®╔╠Mozy║═CrashPlan╠ß╣®┴╦ę╗éĆ▓╗Ą├ęčĄ─▀xō±Ż¼į┌ė├æ¶įS┐╔Ą─ŪķørŽ┬Ż¼īóöĄō■▐D┤µį┌DVD╗“š▀ė▓▒P╔ŽŻ¼╚╗║¾═©▀^╠ž┐ņīŻ▀fĄ─ą╬╩ĮĮ╗ĖČĮoė├æ¶ĪŻ
×ķ┴╦ā×╗»ÅVė“ŠWŁhŠ│Ž┬┤¾ęÄ─ŻöĄō■é„▌öĄ─ąį─▄Ż¼╬ęéāį°īóöĄō■į┌╠ūĮėūųīėŻ¼į┌░l╦═Č╦▀MąąĘųĖŅŻ¼╚╗║¾└¹ė├ČÓéĆ╠ūĮėūų┴„▀Mąą▓óąąé„▌öŻ¼ūŅ║¾į┌Įė╩šČ╦▀MąąöĄō■Ą─ųžĮM(╚ńłD10(c)╦∙╩Š)Ż¼└Ēšō╔ŽųvŻ¼ī”TCP╣▄Ą└Č°čįŻ¼ŲõūŅ┤¾Ą─═╠═┬┴┐×ķĦīÆčė▀t│╦ĘeŻ¼╝┤╚▌┴┐=ĦīÆףh╗žĢrķgŻ¼į┌é„▌ö┤░┐┌ę╗Č©Ą─ŪķørŽ┬(łD10ųą╝t╔½Ą─ĘĮą╬ģ^▒Ē╩Šé„▌ö┤░┐┌Ż¼╚▒╩Ī×ķ64Kūų╣Ø)Ż¼░┤═©│Ż100MbĄ─ŠWĮjĦīÆüĒėŗ╦ŃŻ¼é„ĮyĄ─å╬╠ūĮėūų┴„’@╚╗¤oĘ©╠ŅØMTCP╣▄Ą└(╚ńłD10(a)╦∙╩Š)Ż¼╩╣Ą├Ųõą¦┬╩śOĄ═Ż¼═©▀^╝ė┤¾é„▌ö┤░┐┌┐╔ęįį┌ę╗Č©│╠Č╚╔Ž╠ßĖ▀TCP╣▄Ą└Ą─└¹ė├┬╩(╚ńłD10(b)╦∙╩Š)Ż¼Ą½į┌üG░³Ą─ŪķørŽ┬Ż¼Ģ■ī¦ų┬├┐┤╬ųžé„Ą─öĄō■į÷╝ėŻ¼ę“┤╦Ż¼═©▀^ČÓéĆ╠ūĮėūų┴„üĒ▓óąąé„▌öĄ─ą¦╣¹▌^║├Ż¼┴Ē═ŌŻ¼ė╔ė┌▓╔ė├┴╦ČÓ┴„Ż¼▓╗═¼Ą─öĄō■┴„į┌▒žę¬Ą─ŪķørŽ┬┐╔ęįū▀▓╗═¼Ą─┬Ęė╔Ż¼ę▓─▄ē“▀Mę╗▓Įā×╗»ÅVė“ŠWĄ─ąį─▄ĪŻ
š²╚ńŪ░├µ╠ߥĮĄ─Ż¼įŲ╗∙ĄAįO╩®▒žĒÜ╩ŪĄž└Ē╔ŽĘų▓╝Ą─Ż¼ę“×ķįŲĄ─│╔╣”į┌║▄┤¾│╠Č╚╔ŽøQČ©ė┌ŲõęÄ─Żą¦æ¬Ż¼ėŗ╦Ń║═┤µā”ŽÓī”▒Ńę╦Ż¼╚╗Č°Ż¼ė╔ė┌ÅVė“ŠWŁhŠ│Ž┬Ą─Ą═ĦīÆĪóĖ▀čė▀t║═▌^Ė▀Ą─üG░³┬╩Ż¼╩╣Ą├ÅVė“ŠW│╔×ķįŲŁhŠ│Ž┬─ŪēKūŅČ╠Ą──Š░ÕŻ¼ę“┤╦Ż¼į┌Ąž└Ē╔ŽĘų▓╝Ą─įŲŁhŠ│Ž┬▀Mąą┤¾ęÄ─ŻĄ─öĄō■é„▌ö╩ŪĘŪ│Ż░║┘FĄ─Ż«łDņ`¬ä½@Ą├š▀JimGrayį┌2006─ĻŠ═ųĖ│÷į┌ÅVė“ŠW╔Ž╠Ä└Ē┤¾öĄō■╝»ĢrŻ¼æ¬įōīó│╠ą“é„ĮoöĄō■Ż¼Č°▓╗╩ŪīóöĄō■é„Įo│╠ą“Ż¼┴Ē═ŌŻ¼ę▓┐╔ęį═©▀^öĄō■ē║┐sĪóöĄō■Ą─╚źųžĄ╚ĘĮĘ©üĒ£p╔┘ŠWė“ŠW╔ŽĄ─öĄō■é„▌ö┴„┴┐Ż¼ĮĄĄ═ī”ŠWĮjĦīÆĄ─ąĶŪ¾Ż¼▀Ć┐╔ęį▓╔ė├äėæBŠÅ┤µĪóIP┴„┴┐╣▄└Ēęį╝░QoSĄ╚ĘĮĘ©üĒĮĄĄ═ÅVė“ŠWĄ─čė▀tŻ¼Ą½╩ŪŻ¼▀@ą®ĘĮĘ©ų╗─▄į┌ę╗Č©│╠Č╚╔ŽüĒŠÅĮŌŠWĮjŲ┐Ņiå¢Ņ}Ż¼▓╗─▄Å─Ė∙▒Š╔ŽĮŌøQå¢Ņ}Ż¼ę“┤╦Ż¼į┌įOėŗįŲ╝▄śŗĢrŻ¼▒žĒÜę¬┐╝æ]ÅVė“ŠWĄ─ĦīÆĪóčė▀t║═░³üG╩¦┬╩╦∙ĦüĒĄ─ė░ĒæĪŻ
7 ėæšō
įŲš²│╔×ķ«öŪ░īWągĮńėæšōĄ─¤ß³cå¢Ņ}Ż¼╣żśIĮńę▓╝Ŗ╝Ŗ═Ų▀Mūį╝║Ą─įŲ«aŲĘŻ¼└²╚ńŻ¼EMCĄ─įŲ┤µā”«aŲĘAtmosŻ¼üå±R▀dĄ─įŲėŗ╦Ń«aŲĘEC2ĪóįŲ┤µā”«aŲĘS3(Simple Storage Service)║═EBS(Elastic Block Store)Ż¼IBMĄ─įŲėŗ╦Ń«aŲĘBlueCloudŻ¼Google═Ų│÷Ą─į┌ŠĆ┤µā”Ę■äšGDriveŻ¼Microsoftę▓═Ų│÷WindowsAzureŻ¼Ė„ITśIŠ▐Ņ^ę▓╝Ŗ╝ŖīóįŲėŗ╦Ńū„×ķŲõæ┬įųŲĖ▀³c▓óį┌╩└ĮńĖ„ĄžĮ©┴ó²ŗ┤¾Ą─öĄō■ųąą─ĪŻ
Ą½╩ŪŻ¼š²╚ń╬ęéāį┌4.2╣Ø║═5.2╣Øųą╠ߥĮĄ─Ż¼įŲėŗ╦ŃŁhŠ│Ž┬╠ōöMÖCĄ─I/Oå¢Ņ}Ż¼įŲ┤µā”ŁhŠ│Ž┬Ą─į¬öĄō■ąį─▄å¢Ņ}▒žīó╩ŪįŲ╗∙ĄAįO╩®Ą─įOėŗš▀▓╗Ą├▓╗├µī”Ą─╠¶æŻ¼ķW┤µ(FlashMemory)╩Ūę╗ĘNĘŪęū╩¦ąį(į┌öÓļŖŪķørŽ┬╚į─▄▒Ż│ų╦∙┤µā”Ą─öĄō■ą┼Žó)Ą─┤µā”Ų„Ż¼╦³┐╔ęį▒╗ļŖ▓┴│²║═ųžŠÄ│╠Ż¼╦³Š▀ėą║▄ČÓā׳cŻ¼└²╚ń│▀┤ńąĪĪóø]ėąÖCąĄ▓┐╝■ĪóĄ═╣”║─ĪóĖ▀ąį─▄Ą╚Ż¼ķW┤µęčĮøį┌įĮüĒįĮČÓĄ─ł÷║Žķ_╩╝╚Ī┤·é„ĮyĄ─┤┼▒PŻ¼Ž┬ĒōłD11║═łD12Ęųäe▒╚▌^┴╦4ĘN▓╗═¼ąį─▄Ą─┤┼▒P║═ė╔ķW┤µĮM│╔Ą─╣╠æB▒PĄ─ĦīÆ║═įLå¢ĢrķgŻ¼┐╔ęį┐┤ĄĮ╣╠æB▒Pį┌ąį─▄ĘĮ├µŠ▀ėąĘŪ│Ż┤¾Ą─ā×ä▌Ż¼į┌šō╬─ųą╬ęéā▀Ć▀Mę╗▓Į▒╚▌^┴╦┤┼▒P║═╣╠æB▒PĄ─╣”║─Ż¼ĮY╣¹▒Ē├„╣╠æB▒Pę▓Š▀ėąŽÓ«öĄ─ā×ä▌Ż¼▀@▒Ē├„Ż¼Å─ąį─▄Ą─ĮŪČ╚Ż¼╣╠æB▒P┐╔ęįį┌ę╗Č©│╠Č╚╔ŽĮŌøQįŲėŗ╦Ń║═įŲ┤µā”╦∙├µ┼RĄ─I/Oå¢Ņ}Ż¼Ė³×ķįö╝ÜĄ─Ęų╬÷šłģó┐┤šō╬─ĪŻ
ķW┤µŠ▀ėą4éĆ╠ž³c:
1)öĄō■▓┴│²╩ŪęįēK×ķå╬╬╗Ż¼Ą½öĄō■īæ╩ŪęįĒō×ķå╬╬╗Ż¼ę╗éĆēK═∙═∙╩Ūė╔ČÓéĆĒōĮM│╔;
2)į┌Ž“─│ę╗éĆēKīæöĄō■ų«Ū░Ż¼įōēKųąĄ─öĄō■▒žĒÜę¬▓┴│²;
3)├┐ę╗éĆēKų╗─▄▒╗īæėąŽ▐Ą─┤╬öĄ;
4)į┌ę╗éĆēKā╚īæöĄō■▒žĒÜę¬Ēśą“▀MąąĪŻ
▀@ą®╠žąįī¦ų┬╣╠æB▒PĄ─īæąį─▄▒╚▌^╬ó├ŅŻ¼┴Ē═ŌŻ¼║═┤┼▒PĄ─ē█├³ŽÓ▒╚Ż¼╣╠æB▒PėąŽ▐Ą─īæ┤╬öĄę▓╩Ū▓╗Ą├▓╗┐╝æ]Ą─å¢Ņ}Ż¼į┘š▀Ż¼╣╠æB▒PĄ─ārĖ±║═╚▌┴┐─┐Ū░▀ƤoĘ©║═┤┼▒PĖéĀÄŻ¼ę“┤╦Ż¼į┌įćłD╩╣ė├╣╠æB▒PüĒŠÅĮŌI/Oå¢Ņ}ĢrŻ¼▀Ć▒žĒÜę¬═¼Ģr┐╝æ]ĄĮ┤┼▒PĄ─ā×ä▌Ż¼ā╔š▀ĮY║Ž╩╣ė├▓┼─▄░lō]Ė„ūį╦∙ķLĪŻ
═¼įŲėŗ╦Ń║═įŲ┤µā”ŽÓ▒╚Ż¼ī”ė┌įŲé„▌öĄ─ł¾Ą└ŽÓī”▌^╔┘Ż¼¼FėąĄ─╣żū„ų„ę¬╝»ųąį┌ī”ÅVė“ŠWŽ┬Ą─┤¾ęÄ─ŻöĄō■é„▌öĄ─ąį─▄▀Mąąā×╗»Ż¼EMCŠ═▓╔ė├SilvERPeak╣½╦ŠĄ─ÅVė“ŠWā×╗»«aŲĘüĒ╠ßĖ▀ÅVė“ŠWŁhŠ│Ž┬öĄō■Å═ųŲĄ─ąį─▄Īó┐╔öUš╣ąį║═░▓╚½ąįŻ¼═¼ĢrĮĄĄ═į┌▀Mąą▀h│╠Å═ųŲęįīŹ¼F×─ļy╗ųÅ═║═śIäš▀B└mąįĢrĄ─ÅVė“ŠWĄ─ĦīÆąĶŪ¾Ż¼Ciscoę▓╩š┘Å┴╦Actona╣½╦ŠüĒ╠ßĖ▀ŲõŠWĮjįOéõį┌ŠWė“ŠWŁhŠ│Ž┬Ą─ąį─▄å¢Ņ}Ż¼ų„ę¬įŁę“į┌ė┌Ż¼─┐Ū░ÅVĘ║╩╣ė├Ą─TCP/IPģfūh╩Ūį┌īŹ“×╩ęĄ═╦┘ŠWĮjŁhŠ│Ž┬šQ╔·Ą─Ż¼į┌įOėŗ│§Ų┌ų╗╩Ū×ķ┴╦▒ŻūCöĄō■į┌µ£┬Ę╔ŽĄ─┐╔┐┐é„▌öŻ¼ę“┤╦Ż¼╦³▓ó▓╗╩Ū×ķÅVė“ŠWČ°įOėŗĄ─ŠWĮjé„▌öģfūhŻ¼└²╚ńŻ¼TCP/IPģfūhĄ─╗¼äė┤░┐┌Ż¼ųžé„║═╗ųÅ═Ą╚ÖCųŲ╩╣Ą├ÅVė“ŠWĄ─é„▌öą¦┬╩╝▒äĪŽ┬ĮĄŻ¼┴Ē═ŌŻ¼TCPĄ─┤░┐┌│▀┤ńĪó┬²åóäėĄ╚ÖCųŲę▓¤oĘ©│õĘų└¹ė├ęčėąĄ─ŠWĮjĦīÆĪŻ
įŲé„▌öå¢Ņ}Ż¼į┌5Ż¼2╣Øųą╠ߥĮĄ─įŲ┤µŁhŠ│Ž┬Ą─├¹ūų┐šķgå¢Ņ}Ż¼Č╝┤┘╩╣╬ęéāę¬ųžą┬īÅęĢį┌┤¾ęÄ─ŻöĄō■┤µā”║═é„▌öĄ─ŪķørŽ┬Ą─ąį─▄ā×╗»ŽÓĻPĄ─ę╗ŽĄ┴ąå¢Ņ}ĪŻ
P2P╩Ūę╗ĘNĘų▓╝╩ĮŠWĮjŻ¼ŠWĮjĄ─ģó┼cš▀╣▓ŽĒ╦¹éā╦∙ōĒėąĄ─ę╗▓┐Ęų┘Yį┤(╚ń╠Ä└Ē─▄┴”Īó┤µā”─▄┴”ĪóöĄō■┘Yį┤Ą╚)Ż¼į┌┤╦ŠWĮjųąĄ─ģó┼cš▀╝╚╩Ū┘Yį┤╠ß╣®š▀(Server)Ż¼ėų╩Ū┘Yį┤Ą─½@╚Īš▀(Client)Ż¼P2PŠWĮjė╔ė┌ŲõĖ▀┐╔öUš╣ąįĄ├ĄĮ┴╦ÅVĘ║Ą─╩╣ė├ĪŻŲõųąĘų▓╝╩ĮŪęĮYśŗ╗»Ą─P2PŠWĮjė╚ŲõŠ▀ėąæ¬ė├Ū░Š░Ż¼▀@ĘNP2PŠWĮjųąĄ─ĻPµI╝╝ąg╩Ū╩╣ė├Ęų▓╝╩Į╣■ŽŻ▒Ē(DistributedHashTablesŻ¼DHT)üĒśŗįņĮYśŗ╗»═žōõŻ¼╚ń:meshĪóringĪód-dimensiontorus and butterflyĄ╚Ą╚Ż¼į┌▀@ĘNŠWĮjųąŻ¼├┐éĆ╣سcČ╝ėąę╗éĆIDŻ¼├┐éĆ╬─╝■ėąę╗éĆĻPµIūųKeyŻ¼«öą¹Ėµę╗éĆĻPµIūų×ķK1Ą─╬─╝■ĢrŻ¼Ž╚═©▀^╣■ŽŻė│╔õĄ├ĄĮī”æ¬Ą─K1→ID1Ż¼╚╗║¾īóįō╬─╝■┤µĄĮID╠¢×ķID1Ą─╣سcŻ¼╬─╝■Ą─┤µĘ┼▀^│╠ąĶę¬īó╬─╝■┬Ęė╔ĄĮįō╣سcID1Ż¼Ę┤▀^üĒŻ¼«ö▓ķšęę╗éĆĻPµIūų×ķK1Ą─╬─╝■ĢrŻ¼Ž╚▀Mąą╣■ŽŻė│╔õĄ├ĄĮK1→ID1Ż¼╚╗║¾īóįō╬─╝■Å─ID╠¢×ķID1Ą─╣سc╔Ž╚ĪĄĮįō╬─╝■Ż¼Å─įōŠWĮjųą╚Ī╬─╝■ąĶę¬īóšłŪ¾Ž¹Žó┬Ęė╔ĄĮID1╣سcŻ¼╚╗║¾╬─╝■Å─ID1╣سcįŁ┬ĘĘĄ╗žŻ¼Ųõā׳cį┌ė┌Ż¼į┌┘Yį┤╣▄└Ē▀^│╠ųą═¼ĢrōĒėąūįĮM┐Ś╠žąįĪóęÄ─ŻĄ─ÅŖ┐╔┐sĘ┼╠žąįęį╝░▓┐╩Ą─┴«ārąįĄ╚Ą╚Ż¼▀@×ķęÄ─Ż²ŗ┤¾Ą─┘Yį┤š¹║Ž╝░╣▓ŽĒ╠ß╣®┴╦┐╔─▄ąįŻ¼ŲõųąOceanStoreŻ¼PASTŻ¼FreeHeavenŻ¼╩ŪūŅŠ▀ėą┤·▒ĒąįĄ─ÄūéĆ┤¾ęÄ─ŻĄ─ĪóĮYśŗ╗»Ą─P2P┤µā”ŽĄĮyĄ─┤·▒ĒĪŻ
łD ĦīÆ▒╚▌^║═įLå¢Ģrķg▒╚▌^║═OceanStore Ą─¾wŽĄĮYśŗ
łD▒Ē╩Š┴╦OceanStoreĄ─¾wŽĄĮYśŗŻ¼ŲõųąūŅĻPµI╝╝ąg╩ŪīóČÓéĆ┘Yį┤│ž▀MąąĖ▀Č╚Ą─╗ź▀BŻ¼Å─Č°į╩įSöĄō■į┌Ė„éĆ▓╗═¼Ą─┘Yį┤│žųąūįė╔Ąž┴„äėŻ¼ė├ė┌┐╔ęįĖ∙ō■ąĶę¬▀BĮėĄĮę╗éĆ╗“š▀ČÓéĆ┘Yį┤│žŻ¼└²╚ńŻ¼╚ń╣¹ļxė├æ¶ūŅĮ³Ą─┘Yį┤│žųą┤µį┌Ųõ╦∙ąĶꬥ─öĄō■Ė▒▒ŠŻ¼ė├æ¶┐╔ęį▀BĮėĄĮįō┘Yį┤│žęįūŅ┤¾│╠Č╚ĄžĮĄĄ═ÅVė“ŠWī”Ųõąį─▄Ą─ė░ĒæŻ¼éĆ╚╦šJ×ķŻ¼▀@ĘNĮYśŗ╗»Ą─P2P╚ń╣¹─▄║═įŲ┤µā”ĮY║ŽŲüĒŻ¼ī”ė┌ŲõįŲ┤µā”├¹ūų┐šķgĄ─╣▄└ĒŻ¼ī”ė┌ÅVė“ŠWŁhŠ│Ž┬┤¾ęÄ─ŻöĄō■é„▌öĄ─ąį─▄ā×╗»Č╝Ģ■ĦüĒ║▄┤¾Ą─Ä═ų·ĪŻ
8 ĮYšō
į┌įŲėŗ╦Ńų«Ū░Ż¼ŠWĖ±ėŗ╦Ńį┌īWągĮńį°▒╗ÅV×ķ═Ų│ń▓ó▀Mąą┴╦┤¾┴┐Ą─蹊┐Ż¼ŠWĖ±ėŗ╦Ńę└═ą╗ź┬ōŠWĮjŻ¼īóĄž└Ē╔ŽĘų▓╝Ą─Īó«ÉśŗĄ─Ė„ĘN▓╗═¼┘Yį┤ĮM┐ŚŲüĒŻ¼Įyę╗š{Č╚Ż¼ĮM│╔╠ōöMĄ─│¼╝ēėŗ╦ŃÖCŻ¼ęįģf═¼═Ļ│╔ąĶę¬┤¾┴┐ėŗ╦ŃÖC┘Yį┤Ą─╚╬䚯¼ŠWĖ±ėŗ╦ŃĄ─▀@ĘN╝▄śŗų„ę¬ė├ė┌┐ŲīWėŗ╦ŃĪó▓óąąėŗ╦ŃĄ╚å¢Ņ}Ż¼Ųõ═∙═∙═©▀^ū„śIĄ─ą╬╩ĮŽ“ŠWĖ±╠ßĮ╗╚╬䚯¼▓óĄ╚┤²╠Ä└ĒĮY╣¹Ą─═Ļ│╔Ż¼ę“┤╦Ż¼╚▒Ę”║═Ųš═©ė├æ¶Ą─Į╗╗źąįŻ¼ė╔ė┌Ųõ├µŽ“╠žČ©Ą─ėąŽ▐Ą─ė├æ¶Ż¼╬┤▒╗╣żśIĮńÅVĘ║═ŲÅVŻ¼┴Ē═ŌŻ¼┤¾▓┐ĘųĄ─ŠWĖ±ŁhŠ│║═ŲĮ┼_Č╝╩Ū╗∙ė┌GlobusüĒķ_░lĄ─Ż¼ļm╚╗Globus╩Ūę╗éĆĄõą═Ą─ŠWĖ±ėŗ╦ŃŲĮ┼_Ż¼Ą½╩ŪŲõśŗų■į┌é„ĮyĄ─▓┘ū„ŽĄĮyų«╔ŽŻ¼¼F┤·▄ø╝■═∙═∙▓╔ė├─ŻēK╗»Ą─ĘųīėįOėŗŻ¼╬’└Ē┘Yį┤Ą─ąį─▄Įø▀^├┐ę╗īė▄ø╝■Č╝Ģ■ī¦ų┬ąį─▄▓╗═¼│╠Č╚Ą─ĮĄĄ═Ż¼ę“┤╦Ż¼ė╔Globus▄ø╝■▒Š╔Ē╦∙ĦüĒĄ─ąį─▄ķ_õNį┌╝ė╔Ž▓┘ū„ŽĄĮyĄ─ąį─▄ķ_õN╦∙ī¦ų┬Ą─ŠWĖ±ŁhŠ│ąį─▄Ą─š¹¾wŽ┬ĮĄę╗ų▒╩ŪŠWĖ±čąŠ┐╔ńģ^└’Įø│ŻėæšōĄ─å¢Ņ}ĪŻ
▓╗═¼ė┌ŠWĖ±ėŗ╦ŃŻ¼įŲėŗ╦Ńęįė├æ¶ąĶŪ¾×ķī¦Ž“Ż¼└¹ė├╠ōöM╗»╝╝ągīó┤µā”┘Yį┤Īóėŗ╦Ń┘Yį┤Īó▄ø╝■┘Yį┤ĪóöĄō■┘Yį┤Ą╚śŗįņ│╔äėæB║═Īó┐╔╔ņ┐sĄ─╠ōöM┘Yį┤Ż¼▓ó═©▀^ŠWĮjęįĘ■䚥─ĘĮ╩ĮĮ╗ĖČĮoÅV┤¾ė├æ¶Ż¼ė╔ė┌ŲõęįŲš═©ė├æ¶×ķų„ī¦Ż¼▓óŠ▀ėąÅVĘ║Ą─╩ął÷Ū░Š░Ż¼╦∙ęįŻ¼ūŅķ_╩╝╩Ūė╔╣żśIĮńęį«aŲĘĄ─ą╬╩Į┤¾┴”═Ųäė▓óį┌Č╠Ģrķgā╚«a╔·ÅVĘ║Ą─ė░ĒæŻ¼įŲėŗ╦ŃōĒėąŠWĖ±ėŗ╦Ń╦∙▓╗Š▀éõĄ─┤¾┴┐Øōį┌Ą─Ųš═©ė├æ¶Ż¼Ą½╩ŪŻ¼įŲ╚ń╣¹ę¬▒▄├ŌŠWĖ±ėŗ╦ŃĄ─ųžĄĖĖ▓▐HŻ¼▒žĒÜę¬Å─¾wŽĄĮYśŗ▀Mąąę╗éĆ╚½ą┬Ą─ŅŹĖ▓ąįĄ─įOėŗŻ¼«ö╚╗Ż¼įŲūŅĮK─▄ʱ│╔╣”Ż¼▀Ć╩▄ĄĮŲõ╦³║▄ČÓę“╦žĄ─ė░Ēæ(└²╚ńŻ¼┤¾┴┐Ą─öĄō■┤µā”į┌įŲČ╦Ż¼╚ń║╬▒ŻūCöĄō■Ą─░▓╚½║═ė├æ¶ļ[╦Į)ĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║įŲ╗∙ĄAįO╩®Ž┬Ą─¾wŽĄĮYśŗĪó╠¶æ┼cÖCė÷(Ž┬)
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/1112156979.html






















